Explorar o Azure Databricks
O Azure Databricks é uma versão baseada no Microsoft Azure da popular plataforma de código aberto Databricks.
Um workspace do Azure Databricks fornece um ponto central para gerenciar clusters, dados e recursos do Databricks no Azure.
Neste exercício, você provisionará um workspace do Azure Databricks e explorará alguns de seus principais recursos.
Este exercício deve levar aproximadamente 20 minutos para ser concluído.
Observação: a interface do usuário do Azure Databricks está sujeita a melhorias contínuas. A interface do usuário pode ter sido alterada desde que as instruções neste exercício foram escritas.
Provisionar um workspace do Azure Databricks
Dica: Se você já tem um workspace do Azure Databricks, pode ignorar esse procedimento e usar o workspace existente.
- Entre no portal do Azure em
https://portal.azure.com. -
Use o botão [>_] à direita da barra de pesquisa na parte superior da página para criar um Cloud Shell no portal do Azure selecionando um ambiente do PowerShell. O Cloud Shell fornece uma interface de linha de comando em um painel na parte inferior do portal do Azure, conforme mostrado aqui:
Observação: se você já criou um Cloud Shell que usa um ambiente Bash, alterne-o para o PowerShell.
-
Você pode redimensionar o Cloud Shell arrastando a barra de separação na parte superior do painel ou usando os ícones —, ⤢ e X no canto superior direito do painel para minimizar, maximizar e fechar o painel. Para obter mais informações de como usar o Azure Cloud Shell, confira a documentação do Azure Cloud Shell.
-
No painel do PowerShell, insira os seguintes comandos para clonar esse repositório:
rm -r mslearn-databricks -f git clone https://github.com/MicrosoftLearning/mslearn-databricks -
Depois que o repositório tiver sido clonado, insira o seguinte comando para executar setup.ps1 do script, que provisiona um workspace do Azure Databricks em uma região disponível:
./mslearn-databricks/setup.ps1 - Se solicitado, escolha qual assinatura você deseja usar (isso só acontecerá se você tiver acesso a várias assinaturas do Azure).
- Aguarde a conclusão do script – isso normalmente leva cerca de 5 minutos, mas em alguns casos pode levar mais tempo. Enquanto espera, revise o artigo Análise exploratória de dados no Azure Databricks na documentação do Azure Databricks.
Criar um cluster
O Azure Databricks é uma plataforma de processamento distribuído que usa clusters do Apache Spark para processar dados em paralelo em vários nós. Cada cluster consiste em um nó de driver para coordenar o trabalho e nós de trabalho para executar tarefas de processamento. Neste exercício, você criará um cluster de nó único para minimizar os recursos de computação usados no ambiente de laboratório (no qual os recursos podem ser restritos). Em um ambiente de produção, você normalmente criaria um cluster com vários nós de trabalho.
Dica: Se você já tiver um cluster com uma versão 13.3 LTS de runtime ou superior em seu workspace do Azure Databricks, poderá usá-lo para concluir este exercício e ignorar este procedimento.
- No portal do Azure, navegue até o grupo de recursos msl-xxxxxxx (ou o grupo de recursos que contém o workspace do Azure Databricks existente) e selecione o recurso do Serviço do Azure Databricks.
-
Na página Visão geral do seu workspace, use o botão Iniciar workspace para abrir seu workspace do Azure Databricks em uma nova guia do navegador, fazendo o logon se solicitado.
Dica: ao usar o portal do workspace do Databricks, várias dicas e notificações podem ser exibidas. Dispense-as e siga as instruções fornecidas para concluir as tarefas neste exercício.
- Na barra lateral à esquerda, selecione a tarefa (+) Novo e, em seguida, selecione Cluster (talvez você precise procurar no submenu Mais).
- Na página Novo cluster, crie um novo cluster com as seguintes configurações:
- Nome do cluster: cluster Nome do Usuário (o nome do cluster padrão)
- Política: Sem restrições
- Modo de cluster: Nó Único
- Modo de acesso: Usuário único (com sua conta de usuário selecionada)
- Versão do runtime do Databricks: 13.3 LTS (Spark 3.4.1, Scala 2.12) ou posterior
- Usar Aceleração do Photon: Selecionado
- Tipo de nó: Standard_D4ds_v5
- Encerra após 20 minutos de inatividade
- Aguarde a criação do cluster. Isso pode levar alguns minutos.
Observação: se o cluster não for iniciado, sua assinatura pode ter cota insuficiente na região onde seu workspace do Azure Databricks está provisionado. Consulte Limite de núcleo da CPU impede a criação do cluster para obter detalhes. Se isso acontecer, você pode tentar excluir seu workspace e criar um novo workspace em uma região diferente.
Usar o Spark para analisar dados
Como em muitos ambientes do Spark, o Databricks oferece suporte ao uso de notebooks para combinar anotações e células de código interativo que você pode usar para explorar dados.
- Faça o download do arquivo products.csv de
https://raw.githubusercontent.com/MicrosoftLearning/mslearn-databricks/main/data/products.csvpara o computador local, salvando-o como products.csv. - Na barra lateral, no menu de link (+) Novo, selecione Adicionar ou carregar dados.
- Selecione Criar ou modificar tabela e faça o upload do arquivo products.csv que você baixou para o seu computador.
- Na página Criar ou modificar a tabela do upload de arquivo, verifique se o cluster está selecionado na parte superior direita da página. Em seguida, escolha o catálogo hive_metastore e seu esquema padrão para criar uma nova tabela chamada produtos.
- Na página Explorador de catálogo, quando a tabela produtos for criada, no menu de botão Criar, selecione Notebook para criar um notebook.
-
No notebook, confirme se ele está conectado ao cluster e revise o código que foi adicionado automaticamente à primeira célula; que deve ser semelhante a este:
%sql SELECT * FROM `hive_metastore`.`default`.`products`; - Use a opção de menu ▸ Executar célula à esquerda da célula para executá-la, iniciando e anexando o cluster, se solicitado.
- Aguarde até que o trabalho do Spark executado pelo código seja concluído. O código recupera dados da tabela que foi criada com base no arquivo que você carregou.
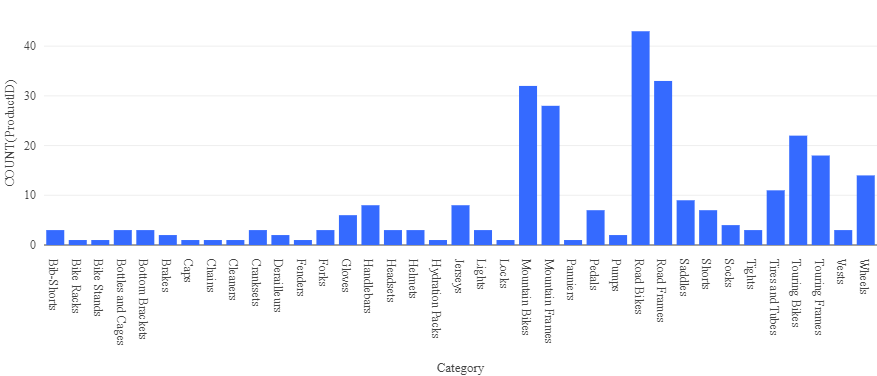
- Acima da tabela de resultados, selecione + e, em seguida, selecione Visualização para exibir o editor de visualização e aplique as seguintes opções:
- Tipo de visualização: Barra
- Coluna X: Categoria
- Coluna Y: Adicione uma nova coluna e selecioneProductID. Aplique a agregaçãoContagem**.
Salve a visualização e observe se ela é exibida no notebook, assim:
Analisar dados com um dataframe
Embora a maioria dos analistas de dados se sinta confortável usando código SQL, conforme usado no exemplo anterior, alguns analistas e cientistas de dados podem usar objetos Spark nativos, como um dataframe em linguagens de programação como PySpark (uma versão do Python otimizada para Spark) para trabalhar com os dados de forma eficiente.
-
No notebook, abaixo do gráfico resultante da célula de código executada anteriormente, use o ícone + Código para adicionar uma nova célula.
Dica: talvez seja necessário passar o mouse sob a célula de saída para fazer o ícone + Código aparecer.
-
Entre e insira o seguinte código na nova célula:
df = spark.sql("SELECT * FROM products") df = df.filter("Category == 'Road Bikes'") display(df) -
Execute a nova célula, que retorna produtos na categoria Bicicletas de estrada.
Limpar
No portal do Azure Databricks, na página Computação, selecione seu cluster e selecione ■ Terminar para encerrar o processo.
Se você tiver terminado de explorar o Azure Databricks, poderá excluir os recursos que criou para evitar custos desnecessários do Azure e liberar capacidade em sua assinatura.