Implementação de LLMOps com o Azure Databricks
O Azure Databricks oferece uma plataforma unificada que simplifica o ciclo de vida da IA, desde a preparação de dados até o fornecimento e monitoramento de modelos, otimizando o desempenho e a eficiência dos sistemas de machine learning. Ele oferece suporte ao desenvolvimento de aplicativos da IA generativa, utilizando recursos como o Unity Catalog para governança de dados, o MLflow para acompanhamento de modelos e o Mosaic AI Model Serving para implantação de LLMs.
Este laboratório levará aproximadamente 20 minutos para ser concluído.
Antes de começar
É necessário ter uma assinatura do Azure com acesso de nível administrativo.
Provisionar um recurso de OpenAI do Azure
Se ainda não tiver um, provisione um recurso OpenAI do Azure na sua assinatura do Azure.
- Entre no portal do Azure em
https://portal.azure.com. - Crie um recurso do OpenAI do Azure com as seguintes configurações:
- Assinatura: Selecione uma assinatura do Azure que tenha sido aprovada para acesso ao serviço Azure OpenAI
- Grupo de recursos: escolher ou criar um grupo de recursos
- Região: faça uma escolha aleatória de uma das regiões a seguir*
- Leste dos EUA 2
- Centro-Norte dos EUA
- Suécia Central
- Oeste da Suíça
- Nome: um nome exclusivo de sua preferência
- Tipo de preço: Standard S0
* Os recursos do OpenAI do Azure são restritos por cotas regionais. As regiões listadas incluem a cota padrão para os tipos de modelos usados neste exercício. A escolha aleatória de uma região reduz o risco de uma só região atingir o limite de cota em cenários nos quais você compartilha uma assinatura com outros usuários. No caso de um limite de cota ser atingido mais adiante no exercício, há a possibilidade de você precisar criar outro recurso em uma região diferente.
-
Aguarde o fim da implantação. Em seguida, vá para o recurso OpenAI do Azure implantado no portal do Azure.
-
No painel esquerdo, em Gerenciamento de recursos, selecione Chaves e Ponto de Extremidade.
-
Copie o ponto de extremidade e uma das chaves disponíveis para usar posteriormente neste exercício.
Implantar o modelo necessário
O Azure fornece um portal baseado na Web chamado Estúdio de IA do Azure, que você pode usar para implantar, gerenciar e explorar modelos. Você iniciará sua exploração do OpenAI do Azure usando o Estúdio de IA do Azure para implantar um modelo.
Observação: À medida que você usa o Estúdio de IA do Azure, podem ser exibidas caixas de mensagens sugerindo tarefas para você executar. Você pode fechá-los e seguir as etapas desse exercício.
-
No portal do Azure, na página Visão geral do recurso OpenAI do Azure, role para baixo até a seção Introdução e clique no botão para abrir o Estúdio de IA do Azure.
-
No Estúdio de IA do Azure, no painel à esquerda, selecione a página Implantações e visualize as implantações de modelo existentes. Se você ainda não tiver uma implantação, crie uma nova implantação do modelo gpt-35-turbo com as seguintes configurações:
- Nome da implantação: gpt-35-turbo
- Modelo: gpt-35-turbo
- Versão do modelo: padrão
- Tipo de implantação: Padrão
- Limite de taxa de tokens por minuto: 5K*
- Filtro de conteúdo: Padrão
- Habilitar cota dinâmica: Desabilitado
* Um limite de taxa de 5.000 tokens por minuto é mais do que adequado para concluir este exercício, deixando capacidade para outras pessoas que usam a mesma assinatura.
Provisionar um workspace do Azure Databricks
Dica: Se você já tem um workspace do Azure Databricks, pode ignorar esse procedimento e usar o workspace existente.
- Entre no portal do Azure em
https://portal.azure.com. - Crie um recurso do Azure Databricks com as seguintes configurações:
- Assinatura: selecione a mesma assinatura do Azure usada para criar o recurso do OpenAI do Azure
- Grupo de recursos: o grupo de recursos em que você criou o recurso do OpenAI do Azure
- Região: a mesma região onde você criou seu recurso do OpenAI do Azure
- Nome: um nome exclusivo de sua preferência
- Tipo de preço: premium ou avaliação
- Selecione Revisar + criar e aguarde a conclusão da implantação. Em seguida, vá para o recurso e inicie o workspace.
Criar um cluster
O Azure Databricks é uma plataforma de processamento distribuído que usa clusters do Apache Spark para processar dados em paralelo em vários nós. Cada cluster consiste em um nó de driver para coordenar o trabalho e nós de trabalho para executar tarefas de processamento. Neste exercício, você criará um cluster de nó único para minimizar os recursos de computação usados no ambiente de laboratório (no qual os recursos podem ser restritos). Em um ambiente de produção, você normalmente criaria um cluster com vários nós de trabalho.
Dica: Se você já tiver um cluster com uma versão de runtime 13.3 LTS ML ou superior em seu workspace do Azure Databricks, poderá usá-lo para concluir este exercício e ignorar este procedimento.
- No portal do Azure, navegue até o grupo de recursos em que o workspace do Azure Databricks foi criado.
- Clique no recurso de serviço do Azure Databricks.
- Na página Visão geral do seu workspace, use o botão Iniciar workspace para abrir seu workspace do Azure Databricks em uma nova guia do navegador, fazendo o logon se solicitado.
Dica: ao usar o portal do workspace do Databricks, várias dicas e notificações podem ser exibidas. Dispense-as e siga as instruções fornecidas para concluir as tarefas neste exercício.
- Na barra lateral à esquerda, selecione a tarefa (+) Novo e, em seguida, selecione Cluster.
- Na página Novo Cluster, crie um novo cluster com as seguintes configurações:
- Nome do cluster: cluster Nome do Usuário (o nome do cluster padrão)
- Política: Sem restrições
- Modo de cluster: Nó Único
- Modo de acesso: Usuário único (com sua conta de usuário selecionada)
- Versão do runtime do Databricks: Selecione a edição do ML da última versão não beta do runtime (Não uma versão de runtime Standard) que:
- Não usa uma GPU
- Inclui o Scala > 2.11
- Inclui o Spark > 3.4
- Usa a Aceleração do Photon: Não selecionado
- Tipo de nó: Standard_D4ds_v5
- Encerra após 20 minutos de inatividade
- Aguarde a criação do cluster. Isso pode levar alguns minutos.
Observação: se o cluster não for iniciado, sua assinatura pode ter cota insuficiente na região onde seu workspace do Azure Databricks está provisionado. Consulte Limite de núcleo da CPU impede a criação do cluster para obter detalhes. Se isso acontecer, você pode tentar excluir seu workspace e criar um novo workspace em uma região diferente.
Instalar as bibliotecas necessárias
-
No workspace do Databricks, vá para a seção Espaço de trabalho.
-
Selecione Criar e, em seguida, selecione Notebook.
-
Dê um nome ao notebook e selecione
Pythoncomo a linguagem. -
Na primeira célula de código, insira e execute o seguinte código para instalar a biblioteca do OpenAI:
%pip install openai -
Após a conclusão da instalação, reinicie o kernel em uma nova célula:
%restart_python
Registrar o LLM usando o MLflow
Os recursos de rastreamento do LLM do MLflow permitem que você registre parâmetros, métricas, previsões e artefatos. Os parâmetros incluem pares de chave-valor que detalham as configurações de entrada, enquanto as métricas fornecem medidas quantitativas de desempenho. As previsões abrangem os prompts de entrada e as respostas do modelo, armazenados como artefatos para facilitar a recuperação. Esse registro estruturado ajuda a manter um registro detalhado de cada interação, facilitando uma melhor análise e otimização dos LLMs.
-
Em uma nova célula, execute o seguinte código com as informações de acesso copiadas no início deste exercício para atribuir variáveis de ambiente persistentes para autenticação ao usar recursos do OpenAI do Azure:
import os os.environ["AZURE_OPENAI_API_KEY"] = "your_openai_api_key" os.environ["AZURE_OPENAI_ENDPOINT"] = "your_openai_endpoint" os.environ["AZURE_OPENAI_API_VERSION"] = "2023-03-15-preview" -
Em uma nova célula, execute o seguinte código para inicializar seu cliente do OpenAI do Azure:
import os from openai import AzureOpenAI client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"), api_key = os.getenv("AZURE_OPENAI_API_KEY"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) -
Em uma nova célula, execute o seguinte código para inicializar o rastreamento do MLflow e registrar o modelo:
import mlflow from openai import AzureOpenAI system_prompt = "Assistant is a large language model trained by OpenAI." mlflow.openai.autolog() with mlflow.start_run(): response = client.chat.completions.create( model="gpt-35-turbo", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "Tell me a joke about animals."}, ], ) print(response.choices[0].message.content) mlflow.log_param("completion_tokens", response.usage.completion_tokens) mlflow.end_run()
A célula acima iniciará um experimento em seu workspace e registrará os indícios de cada iteração de conclusão de chat, rastreando as entradas, saídas e metadados de cada execução.
Monitorar o modelo
-
Na barra lateral à esquerda, selecione Experimentos e selecione o experimento associado ao notebook usado para este exercício. Selecione a execução mais recente e verifique na página Visão geral se há um parâmetro registrado:
completion_tokens. O comandomlflow.openai.autolog()registrará os rastreamentos de cada execução por padrão, mas você também pode registrar parâmetros adicionais commlflow.log_param()que podem ser usados posteriormente para monitorar o modelo. -
Selecione a guia Rastreamentos e, em seguida, selecione o último criado. Verifique se o parâmetro
completion_tokensfaz parte da saída do rastreamento: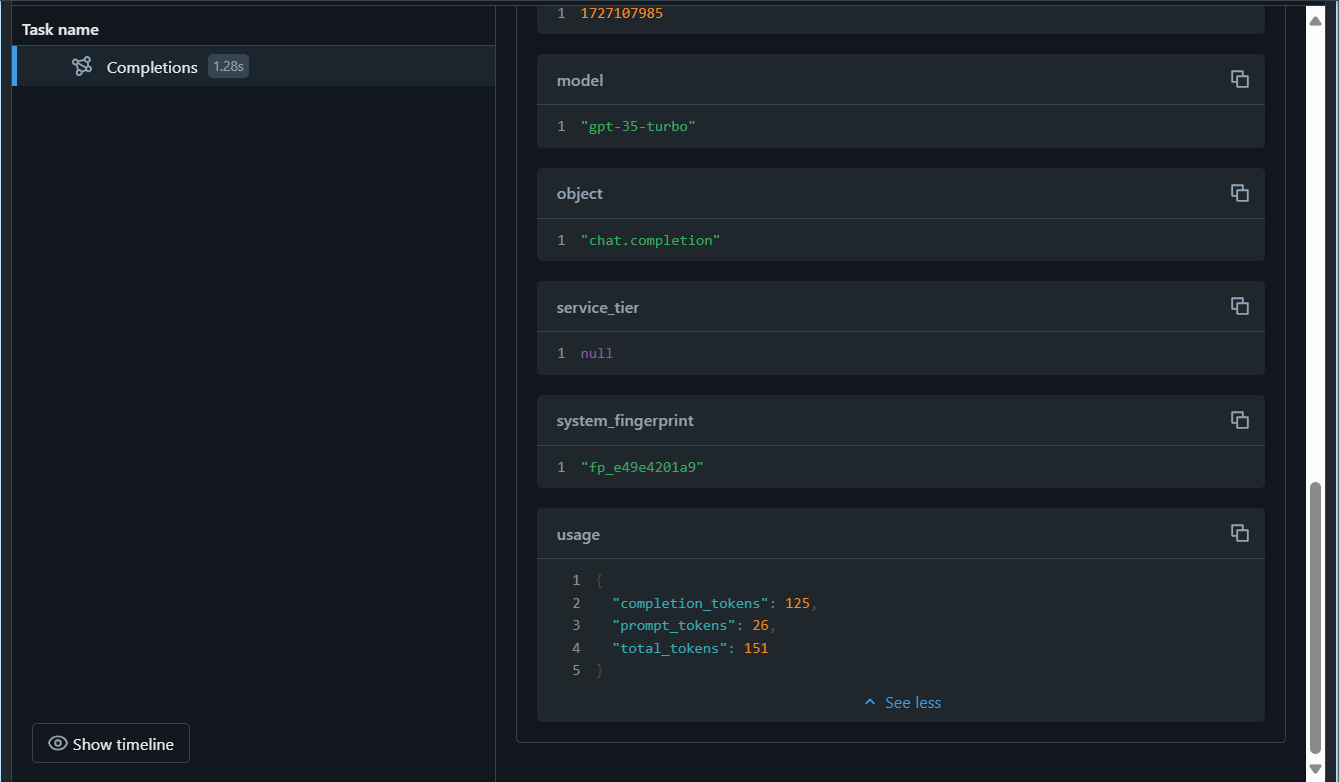
Depois de começar a monitorar o modelo, você pode comparar os rastreamentos de diferentes execuções para detectar descompassos de dados. Procure alterações significativas nas distribuições de dados de entrada, previsões de modelo ou métricas de desempenho ao longo do tempo. Você pode usar testes estatísticos ou ferramentas de visualização para auxiliar nessa análise.
Limpar
Quando terminar o recurso do OpenAI do Azure, lembre-se de excluir a implantação ou todo o recurso no portal do Azure em https://portal.azure.com.
No portal do Azure Databricks, na página Computação, selecione seu cluster e selecione ■ Terminar para encerrar o processo.
Se você tiver terminado de explorar o Azure Databricks, poderá excluir os recursos que criou para evitar custos desnecessários do Azure e liberar capacidade em sua assinatura.