Configure a replicação geográfica para o Banco de Dados SQL do Azure
Neste exercício, você aprenderá a habilitar a replicação geográfica para um Banco de Dados SQL do Azure e a executar um failover para uma região secundária. Isso envolve a criação de uma réplica do banco de dados, a configuração de um novo servidor para o banco de dados secundário e a inicialização de um failover forçado. Você também aprenderá a verificar o status de suas implantações e a entender a função das áreas geográficas secundárias ou réplicas geográficas no gerenciamento do Banco de Dados SQL do Azure. Por fim, você executará um failover manual a partir do banco de dados para outra região usando o portal do Azure. Através deste exercício, você obterá experiência prática nos principais aspectos do gerenciamento e na garantia da resiliência dos seus Bancos de Dados SQL do Azure.
Este exercício levará aproximadamente 30 minutos.
Observação: para realizar este exercício, será necessário ter acesso a uma assinatura do Azure para criar recursos do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Antes de começar
Para concluir este exercício, usaremos muitos recursos e ferramentas. Vamos examinar cada um com mais detalhes:
| Descrição | |
|---|---|
| Servidor primário | Um servidor do Banco de Dados SQL do Azure que configuraremos neste laboratório. |
| Banco de dados primário | O banco de dados de exemplo AdventureWorksLT criado no servidor secundário. |
| Servidor secundário | Um servidor extra do Banco de Dados SQL do Azure que configuraremos neste laboratório. |
| Banco de dados secundário | Esta é a nossa réplica de banco de dados no servidor secundário. |
| SQL Server Management Studio | Baixe e instale a última versão do SQL Server Management Studio em um computador de sua escolha. |
Provisione os recursos do Banco de Dados SQL do Azure
Vamos criar os recursos do Banco de Dados SQL do Azure em duas etapas. Primeiro, estabeleceremos o servidor primário e o banco de dados. Em seguida, repetiremos o processo para configurar o servidor secundário com um nome diferente. Isso resultará em dois servidores SQL do Azure, cada um com suas próprias regras de firewall. No entanto, somente o servidor primário possuirá um banco de dados.
-
Navegue até o portal do Azure e entre com as credenciais da sua conta do Azure.
-
Selecione a opção Cloud Shell na barra de menus no canto superior direito (ela se parece com um prompt de shell
>_). -
Um painel deslizará de baixo para cima solicitando que você escolha seu tipo de shell preferido. Selecione Bash.
-
Se esta for a primeira vez que você estiver abrindo o Cloud Shell, você será solicitado a criar uma conta de armazenamento (usada para que haja persistência dos seus dados entre sessões). Siga as instruções para criar uma conta.
-
Depois que o shell for iniciado, você terá uma interface de linha de comando diretamente no portal do Azure, onde poderá inserir seus comandos de script.
-
Selecione {} para abrir o editor e copie e cole o script abaixo.
Observação: lembre-se de substituir os valores dos espaços reservados no script por seus valores reais antes de executá-lo. Se você precisar editar o script, digite
codeno Cloud Shell para usar o editor de texto interno.subscription="<Your subscription>" resourceGroup="<Your resource group>" location="<Your region, same as your resource group>" serverName="<Your SQL server name>" adminLogin="sqladmin" password="<password>" databaseName="AdventureWorksLT" az account set --subscription $subscription az sql server create --name $serverName --resource-group $resourceGroup --location $location --admin-user $adminLogin --admin-password $password az sql db create --resource-group $resourceGroup --server $serverName --name $databaseName --sample-name AdventureWorksLT --service-objective BasicEste script da CLI do Azure define a assinatura ativa do Azure, cria um novo SQL Server do Azure e cria um novo Banco de Dados SQL do Azure preenchido com os dados de amostra do AdventureWorksLT.
-
Clique com o botão direito do mouse na página do editor e selecione Salvar.
-
Forneça um nome para o arquivo. A extensão do arquivo deve ser .ps1.
-
No terminal do Cloud Shell, digite e execute o comando.
chmod +x <script_name>.ps1Substitua *
* para refletir o nome fornecido para o script. Esse comando altera as permissões do arquivo criado para torná-lo executável. -
Execute o script.
./<script_name>.ps1 -
Quando o processo estiver concluído, navegue até o SQL Server do Azure recém-criado acessando o portal do Azure e navegando até a página do seu SQL Server.
-
Na página principal do SQL Server do Azure, selecione Rede à esquerda.
-
Na guia Acesso público, selecione Todas as redes.
-
Na seção Regras de firewall, selecione + Adicionar endereço IPv4 do cliente. Digite seu endereço IP e selecione Salvar.
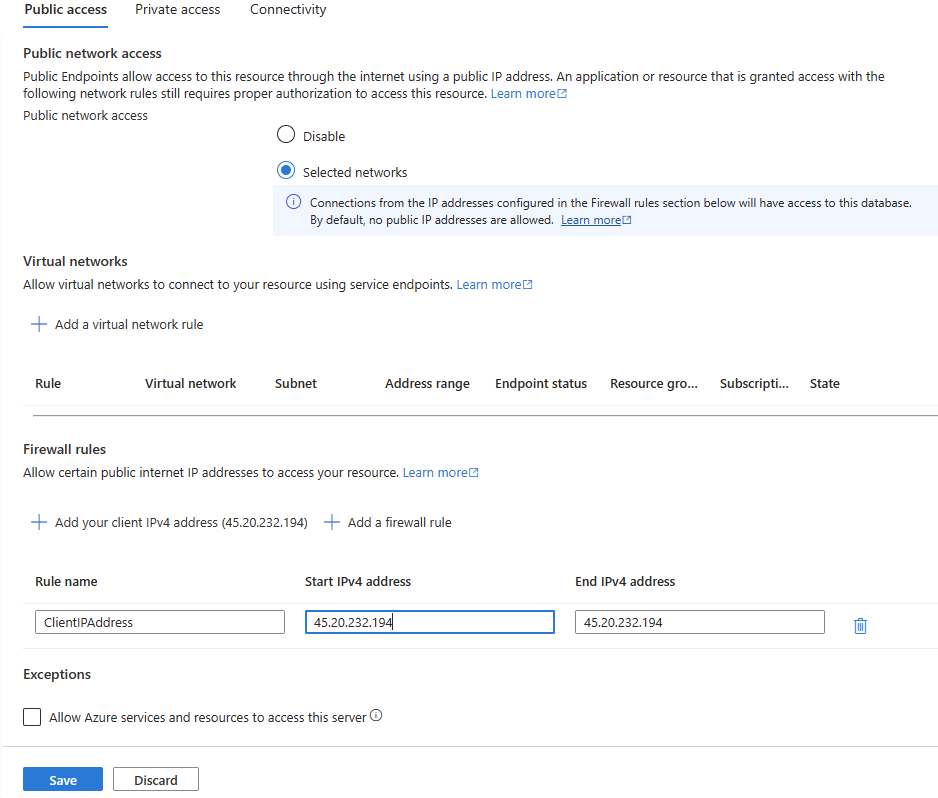
Neste ponto, você poderá se conectar ao banco de dados do
AdventureWorksLTprimário através de uma ferramenta de cliente como o SQL Management Studio. -
Agora, criaremos um SQL Server do Azure secundário. Repita as etapas anteriores (da 6 até a 14), mas não esqueça de usar um
serverNameelocationdiferentes. Além disso, transforme o comandoaz sql db createem comentário para pular o código que cria o banco de dados. Isso resultará em um novo servidor em uma região diferente, sem o banco de dados de exemplo.
Habilitar a replicação geográfica
Agora, criaremos a réplica secundária para nossos recursos SQL do Azure.
-
No portal do Azure, navegue de volta para o banco de dados pesquisando por bancos de dados SQL.
-
Selecione o banco de dados SQL AdventureWorksLT.
-
Na página principal do banco de dados SQL do Azure, selecione Réplicas, abaixo de Gerenciamento de dados, à esquerda.
-
Selecione + Criar réplica.
-
Na página Criar Banco de Dados SQL – Réplica geográfica e, em Servidor, selecione o novo SQL Server secundário criado anteriormente.
-
Selecione Examinar + Criar e Criar. O banco de dados secundário será criados agora e propagado. Para verificar o status, cheque o ícone de notificações na parte superior do portal do Azure.
-
Se a criação tiver ocorrido com sucesso, ele mudará de Implantação em andamento para Implantação bem-sucedida.
-
Conecte-se ao seu SQL Server do Azure secundário usando o SQL Management Studio.
Execute um failover em um banco de dados SQL para uma região secundária.
Imagine um cenário em que o Banco de Dados SQL do Azure primário esteja enfrentando problemas devido a uma interrupção regional. Para garantir a continuidade de seus serviços e minimizar o tempo de inatividade, será preciso executar um failover forçado.
Um failover forçado alterna as funções entre seu banco de dados primário e secundário. O banco de dados secundário assume como o banco de dados primário e o banco de dados primário original torna-se o banco de dados secundário. Isso permite que seus aplicativos continuem operando usando a réplica secundária, enquanto os problemas com o banco de dados primário original estão sendo resolvidos.
Vamos aprender como iniciar um failover forçado em resposta a uma interrupção na região.
-
Navegue até a página dos SQL Servers e selecione o servidor secundário.
-
Na seção Configurações, à esquerda, selecione Bancos de dados SQL.
-
Na página principal do banco de dados SQL do Azure, selecione Réplicas, abaixo de Gerenciamento de dados, à esquerda. O link de replicação geográfica está estabelecido agora.
-
Selecione o menu … do servidor secundário e selecione Failover forçado.
Observação: o failover forçado alternará o banco de dados secundário para a função do banco de dados primário. Todas as sessões são desconectadas durante esta operação.
-
Quando solicitado pela mensagem de aviso, selecione Sim.
-
O status da réplica primária será alternado para Pendente, e o status da secundária para Failover.
Observação: essa operação poderá levar alguns minutos. Quando concluído, as funções serão invertidas: o servidor secundário se tornará o novo servidor primário e vice-versa.
Considere quais as vantagens de colocar seu SQL Server primário e secundário na mesma região e quando pode ser benéfico escolher regiões diferentes.
Você aprendeu a habilitar réplicas geográficas para o Banco de Dados SQL do Azure e a executar um failover manualmente para outra região usando o portal do Azure.
Limpar
Quando você está trabalhando em sua própria assinatura, é uma boa ideia identificar, no final de um projeto, se você ainda precisa dos recursos criados.
Deixar os recursos funcionando desnecessariamente pode resultar em custos extras. É possível excluir os recursos individualmente ou excluir todo o conjunto de recursos no portal do Azure.
Mais informações
Para mais informações sobre replicações geográficas para Bancos de Dados SQL do Azure, veja Replicação geográfica ativa.