Azure SQL Database 用に geo レプリケーションを構成する
この演習では、Azure SQL Database の geo レプリケーションを有効にして、セカンダリ リージョンへのフェールオーバーを実行する方法について説明します。 これには、データベースのレプリカの作成、セカンダリ データベース用の新しいサーバーの設定、強制フェールオーバーの開始が含まれます。 また、デプロイの状態をチェックし、Azure SQL Database 管理における geo セカンダリまたは geo レプリカの役割を理解する方法についても説明します。 最後に、Azure portal を使用して、データベースを別のリージョンに手動でフェールオーバーします。 この演習では、Azure SQL Database の管理と回復性の確保に関する重要な側面について実践的なエクスペリエンスを提供します。
この演習は約 30 分かかります。
注: この演習を完了するには、Azure サブスクリプションにアクセスして、Azure リソースを作成する必要があります。 Azure サブスクリプションをお持ちでない場合は、始める前に無料アカウントを作成してください。
開始する前に
この演習を完了するには、多くのリソースとツールを使用します。 それぞれを詳しく見ていきましょう。
| 説明 | |
|---|---|
| プライマリ サーバー | このラボで設定する Azure SQL Database サーバー。 |
| プライマリ データベース | セカンダリ サーバー上に作成された AdventureWorksLT サンプル データベース。 |
| セカンダリ サーバー | このラボで設定する追加の Azure SQL Database サーバー。 |
| セカンダリ データベース | これはセカンダリ サーバー上のデータベースのレプリカです。 |
| SQL Server Management Studio | 最新バージョンの SQL Server Management Studio をダウンロードしてインストールします。 |
Azure SQL Database リソースをプロビジョニングする
2 つの手順で Azure SQL Database リソースを作成しましょう。 まず、プライマリ サーバーとデータベースを確立します。 次に、プロセスを繰り返して、別の名前でセカンダリ サーバーを設定します。 これにより、2 つの Azure SQL サーバーが作成され、それぞれに独自のファイアウォール ルールが設定されます。 ただし、データベースを持つのはプライマリ サーバーだけです。
-
Azure portal に移動し、Azure アカウント資格情報を使用してサインインします。
-
右上のメニュー バーで Cloud Shell オプションを選択します (シェル プロンプト
>_のようになります)。 -
ウィンドウが下から上にスライドして、好みのシェルの種類を選択するように求められます。 [Bash] を選択します。
-
Cloud Shell を初めて開く場合は、ストレージ アカウントを作成するように求められます (セッション間でデータを保持するために使用されます)。 プロンプトに従ってストレージ アカウントを作成します。
-
シェルが開始されると、Azure portal 内にコマンド ライン インターフェイスが用意され、そこでスクリプト コマンドを入力できます。
-
{} を選択してエディターを開き、以下のスクリプトをコピーして貼り付けます。
注: スクリプトのプレースホルダーの値は、実行する前に実際の値に置き換えてください。 スクリプトを編集する必要がある場合は、Cloud Shell に
codeを入力して組み込みのテキスト エディターを使用します。subscription="<Your subscription>" resourceGroup="<Your resource group>" location="<Your region, same as your resource group>" serverName="<Your SQL server name>" adminLogin="sqladmin" password="<password>" databaseName="AdventureWorksLT" az account set --subscription $subscription az sql server create --name $serverName --resource-group $resourceGroup --location $location --admin-user $adminLogin --admin-password $password az sql db create --resource-group $resourceGroup --server $serverName --name $databaseName --sample-name AdventureWorksLT --service-objective Basicこの Azure CLI スクリプトは、アクティブな Azure サブスクリプションを設定し、新しい Azure SQL サーバーを作成してから、AdventureWorksLT サンプル データが設定された新しい Azure SQL Database を作成します。
-
エディター ページ上で右クリックして、[保存] を選択します。
-
ファイルの名前を指定します。 ファイル名拡張子は .ps1 である必要があります。
-
Cloud Shell ターミナルで、コマンドを入力して実行します。
chmod +x <script_name>.ps1*
* を置き換えて、スクリプトに指定した名前を反映します。 このコマンドは、作成したファイルのアクセス許可を変更して実行可能にします。 -
スクリプトを実行します。
./<script_name>.ps1 -
プロセスが完了したら、Azure portal に移動し、SQL サーバーのページに移動して、新しく作成された Azure SQL サーバーに移動します。
-
Azure SQL Server のメイン ページで、左側にある [ネットワーク] を選択します。
-
[パブリック アクセス] タブで、[選択されたネットワーク] を選択します。
-
[ファイアウォール規則] セクションで、[+ クライアント IPv4 アドレスの追加] を選択します。 IP アドレスを入力し、[保存] を選択します。
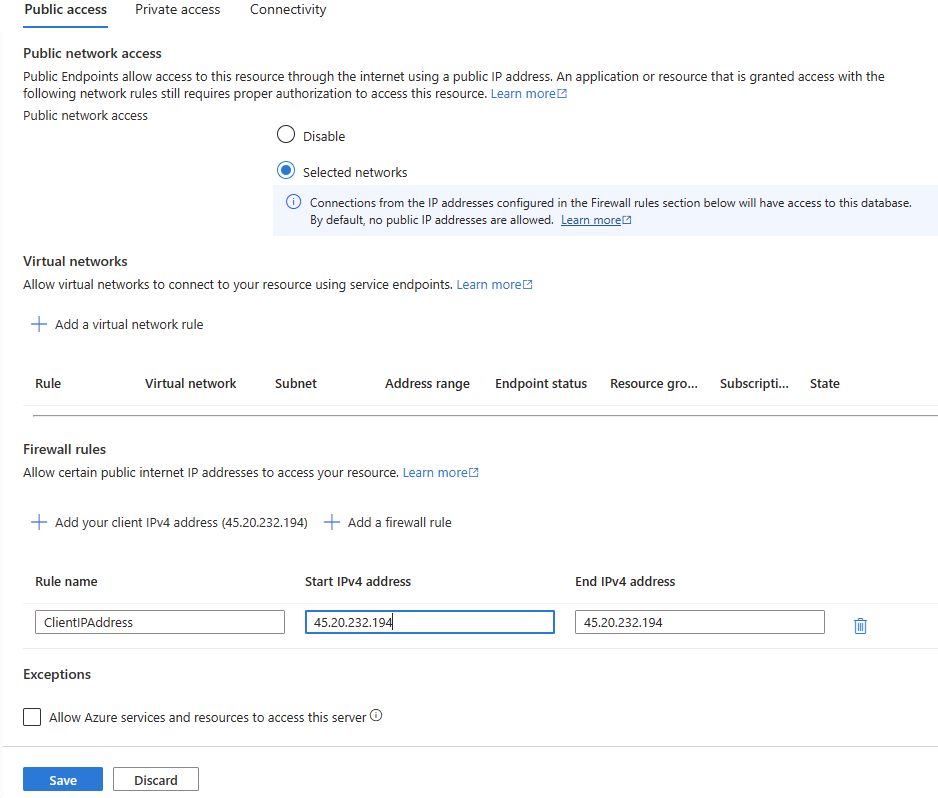
この時点で、SQL Management Studio などのクライアント ツールを使用してプライマリ
AdventureWorksLTデータベースに接続できるようになります。 -
次に、セカンダリ Azure SQL Server を作成しましょう。 前の手順 (6 から 14) を繰り返しますが、必ず別の
serverNameとlocationを使用してください。 また、az sql db createコマンドをコメント アウトしてデータベースを作成するコードをスキップします。 これにより、サンプル データベースのない別のリージョンに新しいサーバーが作成されます。
geo レプリケーションを有効にする
次に、Azure SQL リソースのセカンダリ レプリカを作成しましょう。
-
Azure portal 内で、「SQL データベース」を検索して、自分のデータベースに移動します。
-
SQL データベース AdventureWorksLT を選択します。
-
Azure SQL データベースのメイン ページで、左側の [データ管理] の下にある [レプリカ] を選択します。
-
[+ レプリカの作成] を選択します。
-
[SQL Database - geo レプリカの作成] ページの [サーバー] で、前に作成した新しいセカンダリ SQL サーバーを選択します。
-
[確認および作成] を選択し、次に [作成] を選択します。 これで、セカンダリ サーバーが作成されシードされます。 状態を確認するには、Azure portal 上部の通知アイコンの下を確認します。
-
成功すると、状態が [デプロイが進行中です] から [デプロイが成功しました] に変化します。
-
SQL Server Management Studio を使用して、セカンダリ Azure SQL Server に接続します。
SQL データベースをセカンダリ リージョンにフェールオーバーする
リージョンの障害が原因でプライマリ Azure SQL Database で問題が発生しているシナリオを想像してください。 サービスの継続性を確保し、ダウンタイムを最小限に抑えるには、強制フェールオーバーを実行する必要があります。
強制フェースオーバーは、プライマリ データベースとセカンダリ データベースの役割を切り替えます。 セカンダリ データベースがプライマリ データベースとして引き継がれ、元のプライマリ データベースがセカンダリ データベースになります。 これにより、元のプライマリ データベースに関する問題が解決されている間、アプリケーションはセカンダリ レプリカを使用して動作を続けられます。
リージョンの停止に対応して強制フェールオーバーを開始する方法について説明します。
-
[SQL サーバー] ページに移動し、セカンダリ サーバーを選択します。
-
左側の [設定] セクションで、[SQL データベース] を選択します。
-
Azure SQL データベースのメイン ページで、左側の [データ管理] の下にある [レプリカ] を選択します。 これで geo レプリケーション リンクが確立されました。
-
セカンダリ サーバーの […] メニューを選択し、[強制フェールオーバー] を選択します。
注: 強制フェールオーバーにより、セカンダリ データベースがプライマリ ロールに切り替わります。 この操作中は、すべてのセッションが切断されます。
-
警告メッセージが表示されたら、 [はい] を選択します。
-
プライマリ レプリカの状態が [保留中] に切り替わり、セカンダリは [フェールオーバー] に切り替わります。
注:この操作には数分かかる場合があります。 完了すると、役割が反転します。セカンダリ サーバーが新しいプライマリ サーバーになり、元のプライマリ サーバーがセカンダリ サーバーになります。
プライマリ SQL サーバーとセカンダリ SQL サーバーを同じリージョンに配置する理由と、異なるリージョンを選択すると役に立つ場合について検討してください。
これで、Azure SQL Database の geo レプリカを有効にする方法と、Azure portal を使用して手動で別のリージョンにフェールオーバーする方法を確認しました。
クリーンアップ
独自のサブスクリプションを使用している場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認してください。
リソースを不必要に実行したままにしておくと、追加コストが発生する可能性があります。 Azure portal でリソースを個別に削除することも、リソースのセット全体を削除することもできます。
詳細
Azure SQL Database の geo レプリケーションの詳細については、アクティブな geo レプリケーションを参照してください。