Ingest real-time data with Eventstream in Microsoft Fabric
Eventstream is a feature in Microsoft Fabric that captures, transforms, and routes real-time events to various destinations. You can add event data sources, destinations, and transformations to the eventstream.
In this exercise, you’ll ingest data from a sample data source that emits a stream of events related to observations of bicycle collection points in a bike-share system in which people can rent bikes within a city.
This lab takes approximately 30 minutes to complete.
Create a workspace
Note: You need access to a Fabric paid or trial capacity to complete this exercise. For information about the free Fabric trial, see Fabric trial.
- Navigate to the Microsoft Fabric home page at
https://app.fabric.microsoft.com/home?experience=fabricin a browser and sign in with your Fabric credentials. - In the menu bar on the left, select Workspaces (the icon looks similar to 🗇).
- Create a new workspace with a name of your choice, selecting a licensing mode that includes Fabric capacity (Trial, Premium, or Fabric).
-
When your new workspace opens, it should be empty.
Create an eventhouse
Now that you have a workspace, you can start creating the Fabric items you’ll need for your real-time intelligence solution. we’ll start by creating an eventhouse.
- In the workspace you just created, select + New item. In the New item pane, select Eventhouse, giving it a unique name of your choice.
-
Close any tips or prompts that are displayed until you see your new empty eventhouse.

- In the pane on the left, note that your eventhouse contains a KQL database with the same name as the eventhouse.
-
Select the KQL database to view it.
Currently there are no tables in the database. In the rest of this exercise you’ll use an eventstream to load data from a real-time source into a table.
Create an Eventstream
- In the main page of your KQL database, select Get data.
-
For the data source, select Eventstream > New eventstream. Name the Eventstream
Bicycle-data.The creation of your new event stream in the workspace will be completed in just a few moments. Once established, you will be automatically redirected to the primary editor, ready to begin integrating sources into your event stream.
Add a source
- In the Eventstream canvas, select Use sample data.
-
Name the source
Bicycles, and select the Bicycles sample data.Your stream will be mapped and you will be automatically displayed on the eventstream canvas.
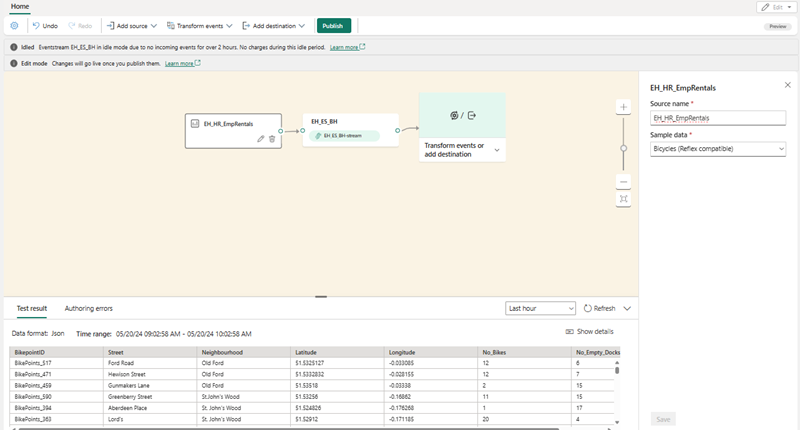
Add a destination
- Select the Transform events or add destination tile and search for Eventhouse.
- In the Eventhouse pane, configure the following setup options.
- Data ingestion mode:: Event processing before ingestion
- Destination name:
bikes-table - Workspace: Select the workspace you created at the beginning of this exercise
- Eventhouse: Select your eventhouse
- KQL database: Select your KQL database
- KQL Destination table: Under the text box, select Create new (do not type directly into the text box — if you do, the Save button will remain greyed out). In the Create new table box that appears, enter the table name
bikesand select Done. - Input data format: JSON
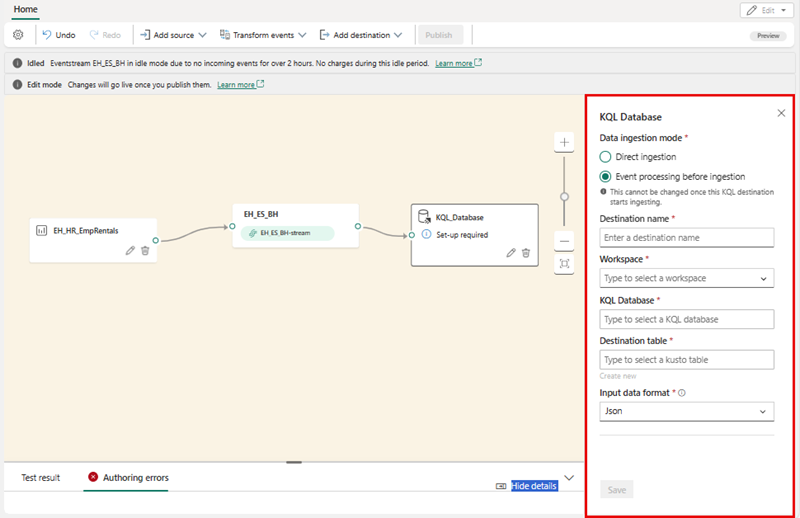
- In the Eventhouse pane, select Save.
- On the toolbar, select Publish.
-
Wait a minute or so for the data destination to become active. Then select the bikes-table node in the design canvas and view the Data preview pane underneath to see the latest data that has been ingested:
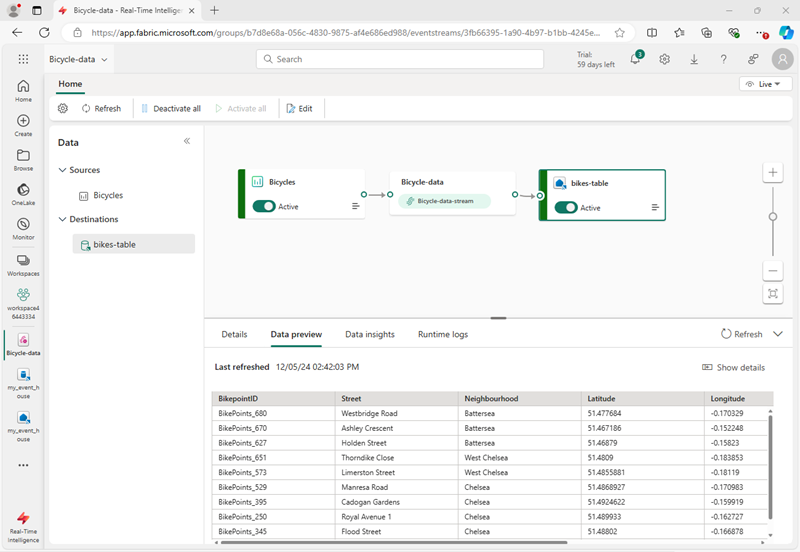
- Wait a few minutes and then use the Refresh button to refresh the Data preview pane. The stream is running perpetually, so new data may have been added to the table.
- Beneath the eventstream design canvas, view the Data insights tab to see details of the data events that have been captured.
Query captured data
The eventstream you have created takes data from the sample source of bicycle data and loads it into the database in your eventhouse. You can analyze the captured data by querying the table in the database.
- In the menu bar on the left, select your KQL database.
-
On the database tab, in the toolbar for your KQL database, use the Refresh button to refresh the view until you see the bikes table under the database. Then select the bikes table.
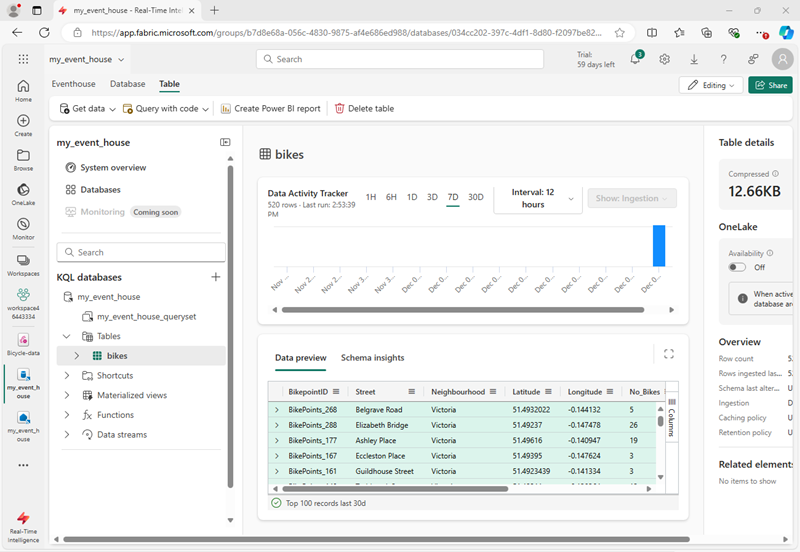
- In the … menu for the bikes table, select Query table > Records ingested in the last 24 hours.
-
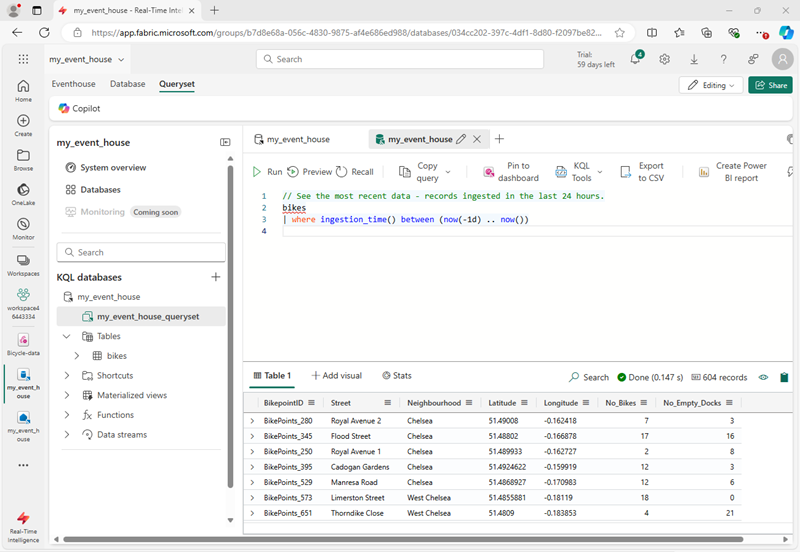
In the query pane, note that the following query has been generated and run, with the results shown beneath:
// See the most recent data - records ingested in the last 24 hours. bikes | where ingestion_time() between (now(-1d) .. now()) -
Select the query code and run it to see 24 hours of data from the table.
Transform event data
The data you’ve captured is unaltered from the source. In many scenarios, you may want to transform the data in the event stream before loading it into a destination.
- In the menu bar on the left, select the Bicycle-data eventstream.
- On the toolbar, select Edit to edit the eventstream.
- In the Transform events menu, select Group by to add a new Group by node to the eventstream.
-
Drag a connection from the output of the Bicycle-data node to the input of the new Group by node Then use the pencil icon in the Group by node to edit it.
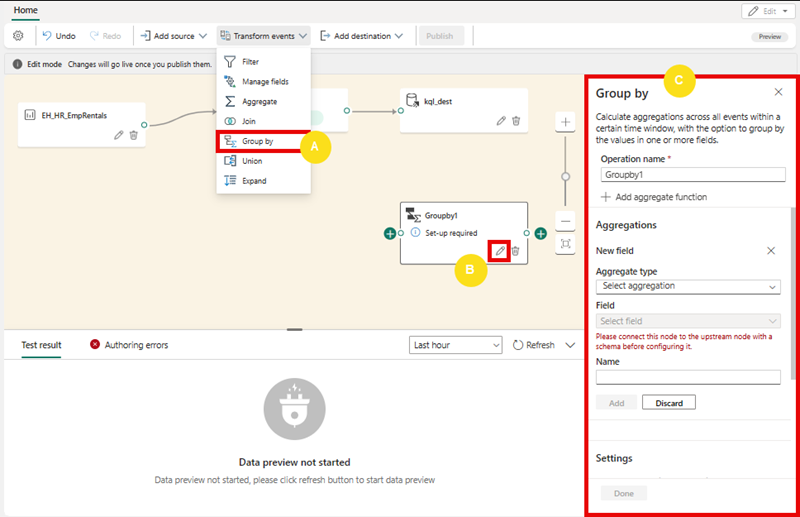
- Configure out the properties of the Group by settings section:
- Operation name: GroupByStreet
- Aggregate type: Select Sum
- Field: select No_Bikes. Then select Add to create the function SUM of No_Bikes
- Group aggregations by (optional): Street
- Time window: Tumbling
- Duration: 5 seconds
- Offset: 0 seconds
Note: This configuration will cause the eventstream to calculate the total number of bicycles in each street every 5 seconds.
-
Save the configuration and return to the eventstream canvas, where an error is indicated (because you need to store the output from the transformation somewhere!).
- Use the + icon to the right of the GroupByStreet node to add a new Eventhouse node.
- Configure the new eventhouse node with the following options:
- Data ingestion mode:: Event processing before ingestion
- Destination name:
bikes-by-street-table - Workspace: Select the workspace you created at the beginning of this exercise
- Eventhouse: Select your eventhouse
- KQL database: Select your KQL database
- Destination table: Create a new table named
bikes-by-street - Input data format: JSON
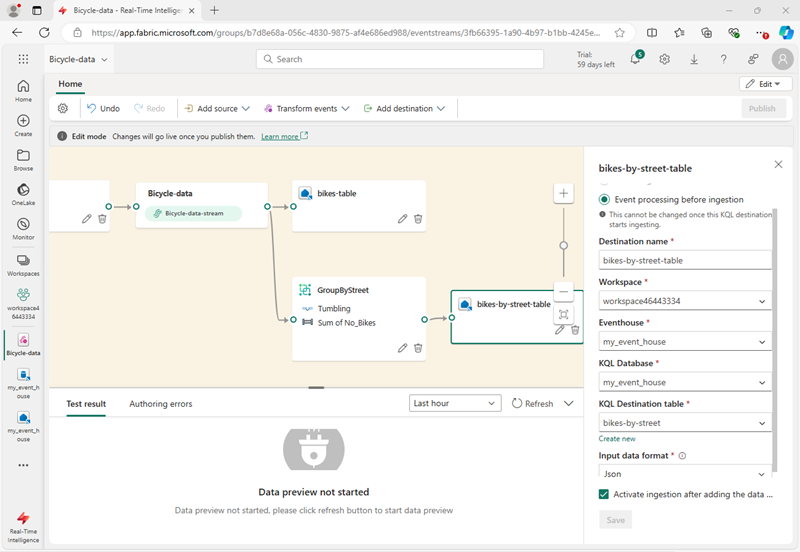
- In the Eventhouse pane, select Save.
- On the toolbar, select Publish.
- Wait a minute or so for the changes to become active.
-
In the design canvas, select the bikes-by-street-table node, and view the data preview pane beneath the canvas.
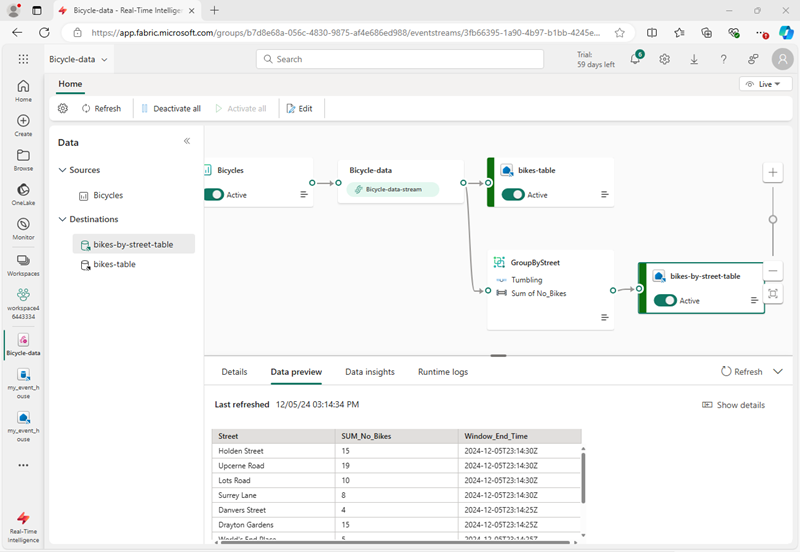
Note that the trasformed data includes the grouping field you specified (Street), the aggregation you specified (SUM_no_Bikes), and a timestamp field indicating the end of the 5 second tumbling window in which the event occurred (Window_End_Time).
Query the transformed data
Now you can query the bicycle data that has been transformed and loaded into a table by your eventstream
- In the menu bar on the left, select your KQL database.
-
- On the database tab, in the toolbar for your KQL database, use the Refresh button to refresh the view until you see the bikes-by-street table under the database.
- In the … menu for the bikes-by-street table, select Query data > Show any 100 records.
-
In the query pane, note that the following query is generated and run:
['bikes-by-street'] | take 100 -
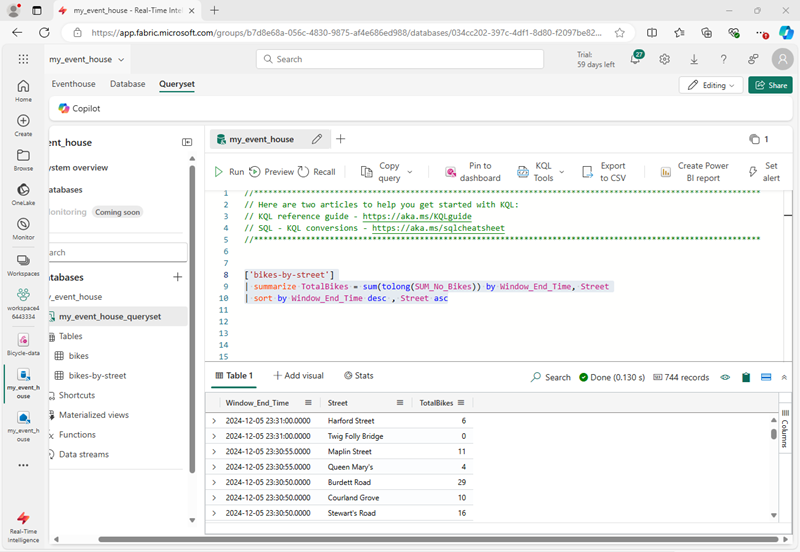
Modify the KQL query to retrieve the total number of bikes per street within each 5 second window:
['bikes-by-street'] | summarize TotalBikes = sum(tolong(SUM_No_Bikes)) by Window_End_Time, Street | sort by Window_End_Time desc , Street asc -
Select the modified query and run it.
The results show the number of bikes observed in each street within each 5 second time period.
Clean up resources
In this exercise, you have created an eventhouse and pipulated tables in its database by using an eventstream.
When you’ve finished exploring your KQL database, you can delete the workspace you created for this exercise.
- In the bar on the left, select the icon for your workspace.
- In the toolbar, select Workspace settings.
- In the General section, select Remove this workspace. .