Preprocess data with Data Wrangler in Microsoft Fabric
In this lab, you’ll learn how to use Data Wrangler in Microsoft Fabric to preprocess data, and generate code using a library of common data science operations.
This lab will take approximately 30 minutes to complete.
Create a workspace
Note: You need access to a Fabric paid or trial capacity to complete this exercise. For information about the free Fabric trial, see Fabric trial.
- Navigate to the Microsoft Fabric home page at
https://app.fabric.microsoft.com/home?experience=fabricin a browser and sign in with your Fabric credentials. - In the menu bar on the left, select Workspaces (the icon looks similar to 🗇).
- Create a new workspace with a name of your choice, selecting a licensing mode that includes Fabric capacity (Trial, Premium, or Fabric).
-
When your new workspace opens, it should be empty.
Create a notebook
To train a model, you can create a notebook. Notebooks provide an interactive environment in which you can write and run code (in multiple languages) as experiments.
-
In the menu bar on the left, select Create. In the New page, under the Data Science section, select Notebook. Give it a unique name of your choice.
Note: If the Create option is not pinned to the sidebar, you need to select the ellipsis (…) option first.
After a few seconds, a new notebook containing a single cell will open. Notebooks are made up of one or more cells that can contain code or markdown (formatted text).
-
Select the first cell (which is currently a code cell), and then in the dynamic tool bar at its top-right, use the M↓ button to convert the cell to a markdown cell.
When the cell changes to a markdown cell, the text it contains is rendered.
-
If necessary, use the 🖉 (Edit) button to switch the cell to editing mode, then delete the content and enter the following text:
# Perform data exploration for data science Use the code in this notebook to perform data exploration for data science.
Load data into a dataframe
Now you’re ready to run code to get data. You’ll work with the OJ Sales dataset from the Azure Open Datasets. After loading the data, you’ll convert the data to a Pandas dataframe, which is the structure supported by Data Wrangler.
-
In your notebook, use the + Code icon below the latest cell to add a new code cell to the notebook.
Tip: To see the + Code icon, move the mouse to just below and to the left of the output from the current cell. Alternatively, in the menu bar, on the Edit tab, select + Add code cell.
-
Enter the following code to load the dataset into a dataframe.
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "ojsales-simulatedcontainer" blob_relative_path = "oj_sales_data" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark reads csv df = spark.read.csv(wasbs_path, header=True) -
Use the ▷ Run cell button on the left of the cell to run it. Alternatively, you can press
SHIFT+ENTERon your keyboard to run a cell.Note: Since this is the first time you’ve run any Spark code in this session, the Spark pool must be started. This means that the first run in the session can take a minute or so to complete. Subsequent runs will be quicker.
-
Use the + Code icon below the cell output to add a new code cell to the notebook, and enter the following code in it:
import pandas as pd df = df.toPandas() df = df.sample(n=500, random_state=1) df['WeekStarting'] = pd.to_datetime(df['WeekStarting']) df['Quantity'] = df['Quantity'].astype('int') df['Advert'] = df['Advert'].astype('int') df['Price'] = df['Price'].astype('float') df['Revenue'] = df['Revenue'].astype('float') df = df.reset_index(drop=True) df.head(4) -
When the cell command has completed, review the output below the cell, which should look similar to this:
WeekStarting Store Brand Quantity Advert Price Revenue 0 1991-10-17 947 minute.maid 13306 1 2.42 32200.52 1 1992-03-26 1293 dominicks 18596 1 1.94 36076.24 2 1991-08-15 2278 dominicks 17457 1 2.14 37357.98 3 1992-09-03 2175 tropicana 9652 1 2.07 19979.64 … … … … … … … … The output shows the first four rows of the OJ Sales dataset.
View summary statistics
Now that we have loaded the data, the next step is to preprocess it using Data Wrangler. Preprocessing is a crucial step in any machine learning workflow. It involves cleaning the data and transforming it into a format that can be fed into a machine learning model.
-
Select Data in the notebook ribbon, and then select Launch Data Wrangler dropdown.
-
Select the
dfdataset. When Data Wrangler launches, it generates a descriptive overview of the dataframe in the Summary panel. -
Select the Revenue feature, and observe the data distribution of this feature.
-
Review the Summary side panel details, and observe the statistics values.
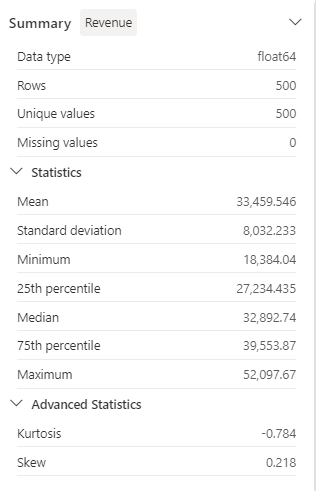
What are some of the insights you can draw from it? The mean revenue is approximately $33,459.54, with a standard deviation of $8,032.23. This suggests that the revenue values are spread out over a range of about $8,032.23 around the mean.
Format text data
Now let’s apply a few transformations to the Brand feature.
-
In the Data Wrangler dashboard, select the
Brandfeature on the grid. -
Navigate to the Operations panel, expand Find and replace, and then select Find and replace.
-
In the Find and replace panel, change the following properties:
- Old value: “
.” - New value: “
You can see the results of the operation automatically previewed in the display grid.
- Old value: “
-
Select Apply.
-
Back to the Operations panel, expand Format.
-
Select Capitalize first character. Switch the Capitalize all words toggle on, and then select Apply.
-
Select Add code to notebook. Additionally, you can also copy the code and save the transformed dataset as a CSV file.
Note: The code is automatically copied to the notebook cell, and is ready for use.
-
Replace the lines 10 and 11 with the code
df = clean_data(df), as the code generated in Data Wrangler doesn’t overwrite the original dataframe. The final code block should look like this:def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() return df df = clean_data(df) -
Run the code cell, and check the
Brandvariable.df['Brand'].unique()The result should show the values Minute Maid, Dominicks, and Tropicana.
You’ve learned how to graphically manipulate text data, and easily generate code using Data Wrangler.
Apply one-hot encoding transformation
Now, let’s generate the code to apply the one-hot encoding transformation to our data as part of our preprocessing steps. To make our scenario more practical, we begin by generating some sample data. This allows us to simulate a real-world situation and provides us with a workable feature.
-
Launch Data Wrangler at the top menu for the
dfdataframe. -
Select the
Brandfeature on the grid. -
In the Operations panel, expand Formulas, and then select One-hot encode.
-
In the One-hot encode panel, select Apply.
Navigate to the end of the Data Wrangler display grid. Notice that it added three new features (
Brand_Dominicks,Brand_Minute Maid, andBrand_Tropicana), and removed theBrandfeature. -
Exit the Data Wrangler without generating the code.
Sort and filter operations
Imagine we need to review the revenue data for a specific store, and then sort the product prices. In the following steps, we use Data Wrangler to filter and analyze the df dataframe.
-
Launch Data Wrangler for the
dfdataframe. -
In the Operations panel, expand Sort and filter.
-
Select Filter.
-
In the Filter panel, add the following condition:
- Target colunm:
Store - Operation:
Equal to - Value:
1227 - Action:
Keep matching rows
- Target colunm:
-
Select Apply, and notice the changes in the Data Wrangler display grid.
-
Select the Revenue feature, and then review the Summary side panel details.
What are some of the insights you can draw from it? The skewness is -0.751, indicating a slight left skew (negative skew). This means that the left tail of the distribution is slightly longer than the right tail. In other words, there are a number of periods with revenues significantly below the mean.
-
Back to the Operations panel, expand Sort and filter.
-
Select Sort values.
-
In the Sort values panel, select the following properties:
- Column name:
Price - Sort order:
Descending
- Column name:
-
Select Apply.
The highest product price for store 1227 is $2.68. With only a few records it’s easier to identify the highest product price, but consider the complexity when dealing with thousands of results.
Browse and remove steps
Suppose you made a mistake and need to remove the sort you created in the previous step. Follow these steps to remove it:
-
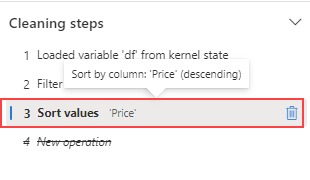
Navigate to the Cleaning steps panel.
-
Select the Sort values step.
-
Select the delete icon to have it removed.
Important: the grid view and summary are limited to the current step.
Notice that the changes are reverted to the previous step, which is the Filter step.
-
Exit the Data Wrangler without generating the code.
Aggregate data
Suppose we need to understand the average revenue generated by each brand. In the following steps, we use Data Wrangler to perform a group by operation on the df dataframe.
-
Launch Data Wrangler for the
dfdataframe. -
Back to the Operations panel, select Group by and aggregate.
-
In the Columns to group by panel, select the
Brandfeature. -
Select Add aggregation.
-
On the Column to aggregate property, select the
Revenuefeature. -
Select
Meanfor the Aggregation type property. -
Select Apply.
-
Select Copy code to clipboard.
-
Exit the Data Wrangler without generating the code.
-
Combine the code from the
Brandvariable transformation with the code generated by the aggregation step in theclean_data(df)function. The final code block should look like this:def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() # Performed 1 aggregation grouped on column: 'Brand' df = df.groupby(['Brand']).agg(Revenue_mean=('Revenue', 'mean')).reset_index() return df df = clean_data(df) -
Run the cell code.
-
Check the data in dataframe.
print(df)Results:
Brand Revenue_mean 0 Dominicks 33206.330958 1 Minute Maid 33532.999632 2 Tropicana 33637.863412
You generated the code for some of the preprocessing operations, and copied the code back to the notebook as a function, which you can then run, reuse or modify as needed.
Save the notebook and end the Spark session
Now that you’ve finished preprocessing your data for modeling, you can save the notebook with a meaningful name and end the Spark session.
- In the notebook menu bar, use the ⚙️ Settings icon to view the notebook settings.
- Set the Name of the notebook to Preprocess data with Data Wrangler, and then close the settings pane.
- On the notebook menu, select Stop session to end the Spark session.
Clean up resources
In this exercise, you’ve created a notebook and used Data Wrangler to explore and preprocess data for a machine learning model.
If you’ve finished exploring the preprocess steps, you can delete the workspace you created for this exercise.
- In the bar on the left, select the icon for your workspace to view all of the items it contains.
- In the … menu on the toolbar, select Workspace settings.
- In the General section, select Remove this workspace .