Trabalhar com dados em um eventhouse do Microsoft Fabric
No Microsoft Fabric, um eventhouse é usado para armazenar dados em tempo real relacionados a eventos; geralmente capturados de uma fonte de dados de streaming por um eventstream.
Em um eventhouse, os dados são armazenados em um ou mais bancos de dados KQL, cada um contendo tabelas e outros objetos que você pode consultar usando a KQL (Linguagem de Consulta Kusto) ou um subconjunto da SQL (Linguagem SQL).
Neste exercício, você criará e preencherá um eventhouse com alguns dados de exemplo relacionados a corridas de táxi e, em seguida, consultará os dados usando KQL e SQL.
Este exercício levará aproximadamente 25 minutos para ser concluído.
Criar um workspace
Antes de trabalhar com os dados no Fabric, crie um espaço de trabalho com a capacidade do Fabric habilitada.
- Navegue até a home page do Microsoft Fabric em
https://app.fabric.microsoft.com/home?experience=fabricem um navegador e entre com suas credenciais do Fabric. - Na barra de menus à esquerda, selecione Workspaces (o ícone é semelhante a 🗇).
- Crie um workspace com um nome de sua escolha selecionando um modo de licenciamento que inclua a capacidade do Fabric (Avaliação, Premium ou Malha).
-
Quando o novo workspace for aberto, ele estará vazio.
Criar um Eventhouse
Agora que você tem um espaço de trabalho com suporte para uma capacidade do Fabric, pode criar um eventhouse nele.
- Na barra de menus à esquerda, selecione Cargas de trabalho. Em seguida, selecione o bloco Inteligência em tempo real.
-
Na home page de Inteligência em Tempo Real, selecione o bloco Explorar amostra de inteligência em tempo real. Um eventhouse chamado RTISample será criado automaticamente:
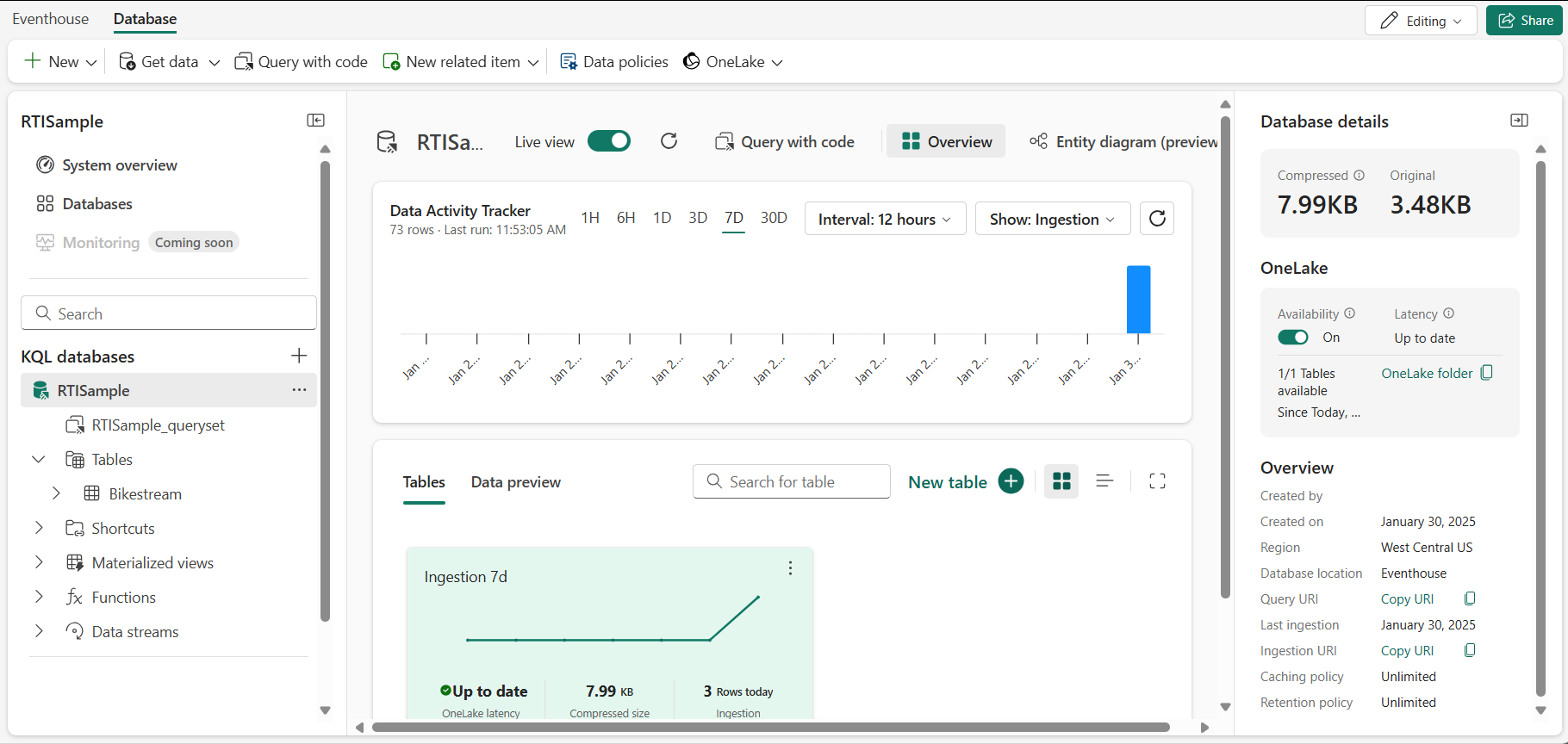
- No painel à esquerda, o eventhouse contém um banco de dados KQL com o mesmo nome do eventhouse.
- Verifique se uma tabela Bikestream também foi criada.
Consultar dados usando o KQL
O KQL (Linguagem de Consulta Kusto) é uma linguagem intuitiva e abrangente que você pode usar para consultar um banco de dados KQL.
Recuperar dados de uma tabela com o KQL
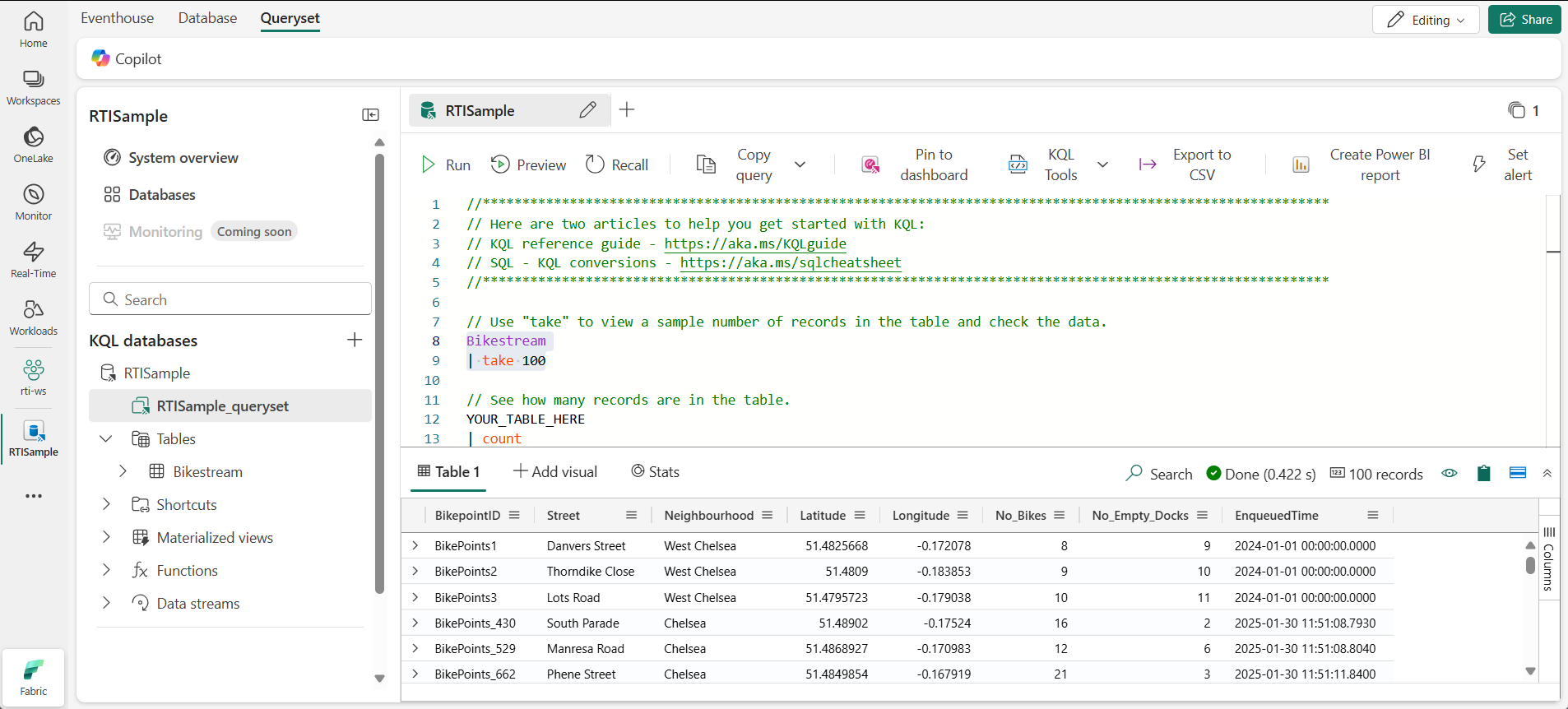
- No painel esquerdo da janela do eventhouse, no banco de dados KQL, selecione o arquivo de conjunto de dados padrão. Este arquivo contém alguns exemplos de consultas KQL para você começar.
-
Modifique a primeira consulta de exemplo da seguinte maneira.
Bikestream | take 100OBSERVAÇÃO: o caractere de barra vertical ( ) é usado para duas finalidades no KQL, incluindo a utilização de operadores de consulta separados em uma instrução de expressão tabular. Ele também é usado como um operador OR lógico dentro de colchetes ou colchetes redondos para indicar que você pode especificar um dos itens separados pelo caractere de pipe. -
Selecione o código de consulta e execute-o para retornar 100 linhas da tabela.
Podemos ser mais precisos adicionando atributos específicos que gostaríamos de consultar usando a palavra-chave
projecte, em seguida, usando a palavra-chavetakepara informar ao mecanismo quantos registros retornar. -
Digite, selecione e execute a seguinte consulta:
// Use 'project' and 'take' to view a sample number of records in the table and check the data. Bikestream | project Street, No_Bikes | take 10OBSERVAÇÃO: o uso de // denota um comentário.
Outra prática comum na análise é renomear colunas em nosso conjunto de consultas para torná-las mais amigáveis.
-
Experimente a seguinte consulta:
Bikestream | project Street, ["Number of Empty Docks"] = No_Empty_Docks | take 10
Resumir os dados usando KQL
Você pode usar a palavra-chave resumir com uma função para agregar e manipular dados.
-
Tente a seguinte consulta, que usa a função de soma para resumir os dados do aluguel a fim de ver quantas bicicletas estão disponíveis no total:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes)Você pode agrupar os dados resumidos por uma coluna ou expressão especificada.
-
Execute a seguinte consulta para agrupar o número de bicicletas por bairro para determinar a quantidade de bicicletas disponíveis em cada bairro:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood, ["Total Number of Bikes"]Se qualquer um dos pontos de bicicleta tiver uma entrada nula ou vazia para vizinhança, os resultados do resumo incluirão um valor em branco, o que nunca é bom para análise.
-
Modifique a consulta conforme mostrado aqui para usar a função case junto com as funções isempty e isnull para agrupar todas as viagens para as quais o bairro é desconhecido em uma categoria Não identificado para acompanhamento.
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]Observação: como esse conjunto de dados de amostra é bem mantido, talvez você não tenha um campo Não identificado no resultado da consulta.
Classificar dados usando KQL
Para dar mais sentido aos nossos dados, normalmente os ordenamos por uma coluna, e esse processo é feito no KQL com um operador classificar por ou ordernar por (eles agem da mesma maneira).
-
Experimente a seguinte consulta:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | sort by Neighbourhood asc -
Modifique a consulta da seguinte maneira e execute-a novamente, e observe que o operador ordenar por funciona da mesma forma que classificar por:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | order by Neighbourhood asc
Filtrar dados usando KQL
No KQL, a cláusula where é usada para filtrar dados. Você pode combinar condições em uma cláusula where usando operadores lógicos and e or.
-
Execute a seguinte consulta para filtrar os dados da bicicleta para incluir apenas pontos de bicicleta no bairro de Chelsea:
Bikestream | where Neighbourhood == "Chelsea" | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | sort by Neighbourhood asc
Consultar dados usando Transact-SQL
O Banco de Dados KQL não dá suporte ao Transact-SQL nativamente, mas fornece um ponto de extremidade T-SQL que emula o Microsoft SQL Server e permite que você execute consultas T-SQL em seus dados. O ponto de extremidade T-SQL tem algumas limitações e diferenças em relação ao SQL Server nativo. Por exemplo, ele não dá suporte à criação, alteração ou remoção de tabelas ou à inserção, atualização ou exclusão de dados. Ele também não dá suporte a algumas funções T-SQL e sintaxe que não são compatíveis com KQL. Ele foi criado para permitir que sistemas que não dão suporte à KQL usem o T-SQL para consultar os dados em um Banco de Dados KQL. Portanto, é recomendável usar o KQL como a linguagem de consulta primária para o Banco de Dados KQL, pois ele oferece mais recursos e desempenho do que o T-SQL. Você também pode usar algumas funções SQL compatíveis com KQL, como count, sum, avg, min, max, entre outras.
Recuperar dados de uma tabela usando o Transact-SQL
-
Em seu conjunto de consultas, adicione e execute a seguinte consulta Transact-SQL:
SELECT TOP 100 * from Bikestream -
Modifique a consulta da seguinte maneira para recuperar colunas específicas
SELECT TOP 10 Street, No_Bikes FROM Bikestream -
Modifique a consulta para atribuir um alias que renomeie No_Empty_Docks para um nome mais simples.
SELECT TOP 10 Street, No_Empty_Docks as [Number of Empty Docks] from Bikestream
Resumir dados usando o Transact-SQL
-
Execute a seguinte consulta para encontrar o número total de bicicletas disponíveis:
SELECT sum(No_Bikes) AS [Total Number of Bikes] FROM Bikestream -
Modifique a consulta para agrupar o número total de bicicletas por bairro:
SELECT Neighbourhood, Sum(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY Neighbourhood -
Modifique ainda mais a consulta para usar uma instrução CASE para agrupar pontos de bicicleta com origem desconhecida em uma categoria Não Identificada para acompanhamento.
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END;
Classificar dados usando o Transact-SQL
-
Execute a consulta a seguir para ordenar os resultados agrupados por bairro:
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END ORDER BY Neighbourhood ASC;
Filtrar dados usando Transact-SQL
-
Execute a consulta a seguir para filtrar os dados agrupados para que apenas as linhas com um bairro de “Chelsea” sejam incluídas nos resultados
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END HAVING Neighbourhood = 'Chelsea' ORDER BY Neighbourhood ASC;
Limpar os recursos
Neste exercício, você criou um eventhouse e consultou dados usando KQL e SQL.
Depois de explorar o banco de dados KQL, exclua o workspace criado para este exercício.
- Na barra à esquerda, selecione o ícone do seu workspace.
- Na barra de ferramentas, selecione Configurações do espaço de trabalho.
- Na seção Geral, selecione Remover este espaço de trabalho.