Treinar e acompanhar modelos de machine learning com o MLflow no Microsoft Fabric
Neste laboratório, você treinará um modelo de machine learning para prever uma medida quantitativa do diabetes. Você treinará um modelo de regressão com o scikit-learn e acompanhará e comparará seus modelos com o MLflow.
Ao concluir este laboratório, você ganhará experiência prática em machine learning e acompanhamento de modelos e aprenderá a usar o Microsoft Fabric para trabalhar com notebooks, experimentos e modelos no Microsoft Fabric.
Este laboratório levará aproximadamente 25 minutos para ser concluído.
Observação: Você precisará de uma avaliação do Microsoft Fabric para concluir esse exercício.
Criar um workspace
Antes de trabalhar com os dados no Fabric, crie um workspace com a avaliação do Fabric habilitada.
- Navegue até a home page do Microsoft Fabric em
https://app.fabric.microsoft.com/home?experience=fabricem um navegador e entre com suas credenciais do Fabric. - Na barra de menus à esquerda, selecione Workspaces (o ícone é semelhante a 🗇).
- Crie um workspace com um nome de sua escolha selecionando um modo de licenciamento que inclua a capacidade do Fabric (Avaliação, Premium ou Malha).
-
Quando o novo workspace for aberto, ele estará vazio.
Criar um notebook
Para treinar um modelo, você pode criar um notebook. Os notebooks fornecem um ambiente interativo no qual você pode escrever e executar código (em várias linguagens).
-
Na barra de menus à esquerda, selecione Criar. Na página Novo, na seção Ciência de Dados, selecione Notebook. Dê um nome exclusivo de sua preferência.
Observação: se a opção Criar não estiver fixada na barra lateral, você precisará selecionar a opção de reticências (…) primeiro.
Após alguns segundos, um novo notebook que contém uma só célula será aberto. Os notebooks são compostos por uma ou mais células que podem conter um código ou um markdown (texto formatado).
-
Selecione a primeira célula (que atualmente é uma célula de código) e na barra de ferramentas dinâmica no canto superior direito, use o botão M↓ para converter a célula em uma célula markdown.
Quando a célula for alterada para uma célula markdown, o texto que ela contém será renderizado.
-
Se necessário, use o botão 🖉 (Editar) para alternar a célula para o modo de edição e, em seguida, exclua o conteúdo e insira o texto a seguir:
# Train a machine learning model and track with MLflow
Carregar dados em um dataframe
Agora você está pronto para executar o código para obter dados e treinar um modelo. Você trabalhará com o conjunto de dados de diabetes do Azure Open Datasets. Após carregar os dados, você os converterá em um dataframe do Pandas: uma estrutura comum para trabalhar com dados em linhas e colunas.
-
No seu notebook, utilize o ícone + Código abaixo da última célula para adicionar uma nova célula de código ao notebook.
Dica: Para ver o ícone + Código, posicione o mouse um pouco abaixo e à esquerda da saída da célula atual. Como alternativa, na barra de menus, na guia Editar, selecione + Adicionar célula de código.
-
Insira o seguinte código nele:
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "mlsamples" blob_relative_path = "diabetes" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark read parquet, note that it won't load any data yet by now df = spark.read.parquet(wasbs_path) -
Use o botão ▷ Executar célula à esquerda da célula para executá-la. Como alternativa, você pode pressionar SHIFT + ENTER no teclado para executar uma célula.
Observação: como esta é a primeira vez que você executa qualquer código Spark nesta sessão, o Pool do Spark precisa ser iniciado. Isso significa que a primeira execução na sessão pode levar um minuto para ser concluída. As execuções seguintes serão mais rápidas.
-
Use o ícone + Código abaixo da saída da célula para adicionar uma nova célula de código ao notebook e insira o seguinte código nela:
display(df) -
Quando o comando de célula for concluído, analise a saída abaixo da célula, que deve ser semelhante a essa:
IDADE SEXO BMI BP S1 S2 S3 S4 S5 S6 Y 59 2 32,1 101.0 157 93,2 38.0 4,0 4,8598 87 151 48 1 21,6 87,0 183 103,2 70.0 3.0 3,8918 69 75 72 2 30,5 93.0 156 93,6 41,0 4,0 4,6728 85 141 24 1 25,3 84.0 198 131,4 49.0 5,0 4,8903 89 206 50 1 23,0 101.0 192 125,4 52,0 4,0 4,2905 80 135 … … … … … … … … … … … A saída mostra as linhas e colunas do conjunto de dados do diabetes.
-
Os dados são carregados como um DataFrame do Spark. O Scikit-learn esperará que o conjunto de dados de entrada seja um dataframe do Pandas. Execute o código abaixo para converter seu conjunto de dados em um dataframe do Pandas:
import pandas as pd df = df.toPandas() df.head()
Treinar um modelo de machine learning
Agora que carregou os dados, você poderá usá-los para treinar um modelo de machine learning e prever uma medida quantitativa do diabetes. Você treinará um modelo de regressão usando a biblioteca do scikit-learn e acompanhará o modelo com o MLflow.
-
Execute o código a seguir para dividir os dados em um conjunto de dados de treinamento e teste e separar os recursos do rótulo que você deseja prever:
from sklearn.model_selection import train_test_split X, y = df[['AGE','SEX','BMI','BP','S1','S2','S3','S4','S5','S6']].values, df['Y'].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0) -
Adicione outra nova célula de código ao notebook e insira o seguinte código nela, executando-a:
import mlflow experiment_name = "experiment-diabetes" mlflow.set_experiment(experiment_name)O código cria um experimento do MLflow chamado experiment-diabetes. Seus modelos serão rastreados neste experimento.
-
Adicione outra nova célula de código ao notebook e insira o seguinte código nela, executando-a:
from sklearn.linear_model import LinearRegression with mlflow.start_run(): mlflow.autolog() model = LinearRegression() model.fit(X_train, y_train) mlflow.log_param("estimator", "LinearRegression")O código treina um modelo de regressão usando Regressão Linear. Os parâmetros, as métricas e os artefatos são registrados em log automaticamente no MLflow. Além disso, você está registrando um parâmetro chamado estimador com o valor LinearRegression.
-
Adicione outra nova célula de código ao notebook e insira o seguinte código nela, executando-a:
from sklearn.tree import DecisionTreeRegressor with mlflow.start_run(): mlflow.autolog() model = DecisionTreeRegressor(max_depth=5) model.fit(X_train, y_train) mlflow.log_param("estimator", "DecisionTreeRegressor")O código treina um modelo de regressão usando o Regressor de Árvore de Decisão. Os parâmetros, as métricas e os artefatos são registrados em log automaticamente no MLflow. Além disso, você está registrando um parâmetro chamado estimador com o valor DecisionTreeRegressor.
Usar o MLflow para pesquisar e ver seus experimentos
Ao treinar e acompanhar modelos com o MLflow, você pode usar a biblioteca do MLflow para recuperar seus experimentos e os detalhes.
-
Para listar todos os experimentos, use o seguinte código:
import mlflow experiments = mlflow.search_experiments() for exp in experiments: print(exp.name) -
Para recuperar um experimento específico, você pode obtê-lo pelo nome:
experiment_name = "experiment-diabetes" exp = mlflow.get_experiment_by_name(experiment_name) print(exp) -
Usando um nome de experimento, recupere todos os trabalhos desse experimento:
mlflow.search_runs(exp.experiment_id) -
Para comparar com mais facilidade as execuções e as saídas do trabalho, configure a pesquisa para ordenar os resultados. Por exemplo, a célula a seguir ordena os resultados por start_time e mostra apenas um máximo de 2 resultados:
mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=2) -
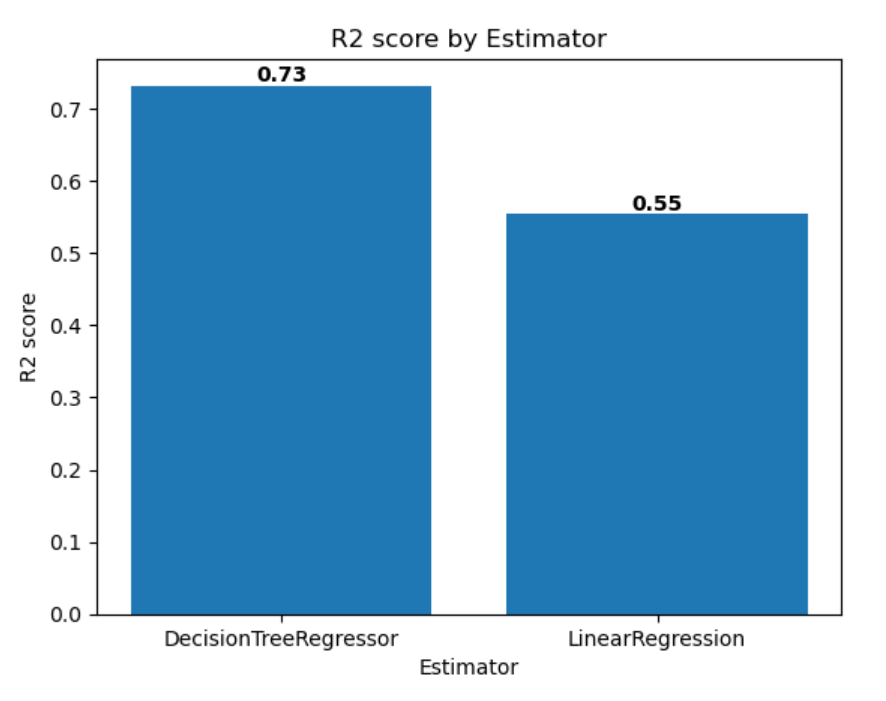
Por fim, você pode plotar as métricas de avaliação de vários modelos um ao lado do outro para comparar os modelos com facilidade:
import matplotlib.pyplot as plt df_results = mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=2)[["metrics.training_r2_score", "params.estimator"]] fig, ax = plt.subplots() ax.bar(df_results["params.estimator"], df_results["metrics.training_r2_score"]) ax.set_xlabel("Estimator") ax.set_ylabel("R2 score") ax.set_title("R2 score by Estimator") for i, v in enumerate(df_results["metrics.training_r2_score"]): ax.text(i, v, str(round(v, 2)), ha='center', va='bottom', fontweight='bold') plt.show()A saída será parecida com a seguinte imagem:
Explorar seus experimentos
O Microsoft Fabric acompanhará todos os seus experimentos e permitirá que você os explore visualmente.
- Navegue até o seu espaço de trabalho na barra de menu do hub à esquerda.
-
Selecione o experimento experiment-diabetes para abri-lo.
Dica: caso não veja nenhuma execução de experimento registrada em log, atualize a página.
- Selecione a guia Exibir.
- Selecione Executar lista.
-
Selecione as duas execuções mais recentes marcando cada caixa.
Como resultado, as duas últimas execuções serão comparadas entre si no painel Comparação de métricas. Por padrão, as métricas são plotadas por nome de execução.
- Selecione o botão 🖉 (Editar) do grafo visualizando o erro médio absoluto de cada execução.
- Altere o tipo de visualização para barra.
- Altere o eixo X para avaliador.
- Selecione Substituir e explore o novo grafo.
- Opcionalmente, você pode repetir essas etapas para os outros grafos no painel Comparação de métricas.
Ao plotar as métricas de desempenho por avaliador registrado em log, você pode analisar qual algoritmo resultou em um modelo melhor.
Salvar o modelo
Depois de comparar os modelos de machine learning que você treinou em execuções de experimentos, você poderá escolher o modelo de melhor desempenho. Para usar o modelo de melhor desempenho, salve o modelo e use-o para gerar previsões.
- Na visão geral do experimento, verifique se a guia Exibir está selecionada.
- Selecione Executar detalhes.
- Selecione a corrida com a maior pontuação de R2 de treinamento.
- Selecione Salvar na caixa Salvar execução como modelo (talvez seja necessário rolar a tela para a direita para ver isso).
- Selecione Criar um modelo na janela pop-up recém-aberta.
- Selecione a pasta do modelo.
- Dê ao modelo o nome
model-diabetese selecione Salvar. - Selecione Exibir modelo de ML na notificação que aparece no canto superior direito da tela quando o modelo é criado. Você também pode atualizar a janela. O modelo salvo está vinculado em Versões do modelo.
Observe que o modelo, o experimento e a execução do experimento estão vinculados, permitindo que você analise como o modelo é treinado.
Salvar o notebook e encerrar a sessão do Spark
Agora que você concluiu o treinamento e a avaliação dos modelos, salve o notebook com um nome significativo e encerre a sessão do Spark.
- Volte ao notebook e, na barra de menus do notebook, utilize o ícone ⚙️ Configurações para exibir as configurações do notebook.
- Defina o Nome do notebook como Treinar e comparar modelos e feche o painel de configurações.
- No menu do notebook, selecione Parar sessão para encerrar a sessão do Spark.
Limpar os recursos
Neste exercício, você criou um notebook e treinou um modelo de machine learning. Você usou o scikit-learn para treinar o modelo e o MLflow para acompanhar o desempenho dele.
Se você tiver terminado de explorar o modelo e os experimentos, exclua o workspace criado para este exercício.
- Na barra à esquerda, selecione o ícone do workspace para ver todos os itens que ele contém.
- No menu … da barra de ferramentas, selecione Configurações do workspace.
- Na seção Geral, selecione Remover este espaço de trabalho.