Executar o pré-processamento de dados com Data Wrangler no Microsoft Fabric
Neste laboratório, você aprenderá a usar o Data Wrangler no Microsoft Fabric para pré-processar dados e gerar código usando uma biblioteca de operações comuns de ciência de dados.
Este laboratório levará aproximadamente 30 minutos para ser concluído.
Observação: Você precisará uma avaliação gratuita do Microsoft Fabric para concluir esse exercício.
Criar um workspace
Antes de trabalhar com os dados no Fabric, crie um workspace com a avaliação do Fabric habilitada.
- Navegue até a home page do Microsoft Fabric em
https://app.fabric.microsoft.com/home?experience=fabricem um navegador e entre com suas credenciais do Fabric. - Na barra de menus à esquerda, selecione Workspaces (o ícone é semelhante a 🗇).
- Crie um workspace com um nome de sua escolha selecionando um modo de licenciamento que inclua a capacidade do Fabric (Avaliação, Premium ou Malha).
-
Quando o novo workspace for aberto, ele estará vazio.
Criar um notebook
Para treinar um modelo, você pode criar um notebook. Os notebooks fornecem um ambiente interativo no qual você pode escrever e executar um código (em várias linguagens) como experimentos.
-
Na barra de menus à esquerda, selecione Criar. Na página Novo, na seção Ciência de Dados, selecione Notebook. Dê um nome exclusivo de sua preferência.
Observação: se a opção Criar não estiver fixada na barra lateral, você precisará selecionar a opção de reticências (…) primeiro.
Após alguns segundos, um novo notebook que contém uma só célula será aberto. Os notebooks são compostos por uma ou mais células que podem conter um código ou um markdown (texto formatado).
-
Selecione a primeira célula (que atualmente é uma célula de código) e na barra de ferramentas dinâmica no canto superior direito, use o botão M↓ para converter a célula em uma célula markdown.
Quando a célula for alterada para uma célula markdown, o texto que ela contém será renderizado.
-
Se necessário, use o botão 🖉 (Editar) para alternar a célula para o modo de edição e, em seguida, exclua o conteúdo e insira o texto a seguir:
# Perform data exploration for data science Use the code in this notebook to perform data exploration for data science.
Carregar dados em um dataframe
Agora você está pronto para executar o código para obter dados. Você trabalhará com o conjunto de dados Vendas de suco de laranja do Azure Open Datasets. Depois de carregar os dados, você converterá os dados em um dataframe do Pandas, que é a estrutura com suporte do Data Wrangler.
-
No seu notebook, utilize o ícone + Código abaixo da última célula para adicionar uma nova célula de código ao notebook.
Dica: Para ver o ícone + Código, posicione o mouse um pouco abaixo e à esquerda da saída da célula atual. Como alternativa, na barra de menus, na guia Editar, selecione + Adicionar célula de código.
-
Insira o código a seguir para carregar o conjunto de dados em um dataframe.
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "ojsales-simulatedcontainer" blob_relative_path = "oj_sales_data" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark reads csv df = spark.read.csv(wasbs_path, header=True) -
Use o botão ▷ Executar célula à esquerda da célula para executá-la. Alternativamente, você pode pressionar
SHIFT+ENTERno teclado para executar uma célula.Observação: como esta é a primeira vez que você executa qualquer código Spark nesta sessão, o Pool do Spark precisa ser iniciado. Isso significa que a primeira execução na sessão pode levar um minuto para ser concluída. As execuções seguintes serão mais rápidas.
-
Use o ícone + Código abaixo da saída da célula para adicionar uma nova célula de código ao notebook e insira o seguinte código nela:
import pandas as pd df = df.toPandas() df = df.sample(n=500, random_state=1) df['WeekStarting'] = pd.to_datetime(df['WeekStarting']) df['Quantity'] = df['Quantity'].astype('int') df['Advert'] = df['Advert'].astype('int') df['Price'] = df['Price'].astype('float') df['Revenue'] = df['Revenue'].astype('float') df = df.reset_index(drop=True) df.head(4) -
Quando o comando de célula for concluído, analise a saída abaixo da célula, que deve ser semelhante a essa:
WeekStarting Repositório Marca Quantidade Anúncio Preço Receita 0 1991-10-17 947 minute.maid 13306 1 2,42 32200:52 1 1992-03-26 1293 dominicks 18596 1 1,94 36076:24 2 1991-08-15 2278 dominicks 17457 1 2.14 37357:98 3 1992-09-03 2175 tropicana 9652 1 2:07 19979:64 … … … … … … … … A saída mostra as quatro primeiras linhas do conjunto de dados OJ Sales.
Exibir estatísticas resumidas
Agora que carregamos os dados, a próxima etapa é pré-processar os dados usando o Data Wrangler. O pré-processamento é uma etapa crucial em qualquer fluxo de trabalho de aprendizado de máquina. Ele envolve limpar os dados e transformá-los em um formato que pode ser alimentado em um modelo de machine learning.
-
Selecione Dados na faixa de opções do notebook e, em seguida, selecione a lista suspensa Iniciar Data Wrangler.
-
Selecione o conjunto de dados
df. Quando o Data Wrangler é iniciado, ele gera uma visão geral descritiva do dataframe no painel Resumo. -
Selecione o recurso Receita e observe a distribuição de dados desse recurso.
-
Examine os detalhes do painel lateral Resumo e observe os valores das estatísticas.
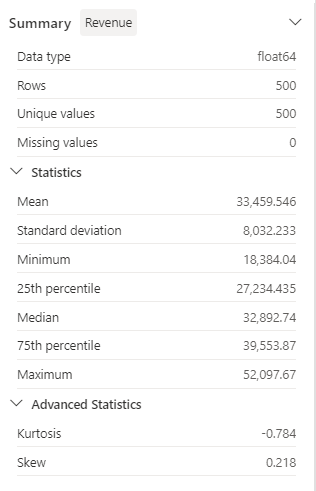
Quais são alguns dos insights que você pode extrair dele? A receita média é de aproximadamente US$ 33.459,54, com um desvio padrão de US$ 8.032,23. Isso sugere que os valores de receita estão distribuídos em um intervalo de cerca de US$ 8.032,23 em torno da média.
Formatar dados de texto
Agora, vamos aplicar algumas transformações ao recurso Marca.
-
No painel de controle do Data Wrangler, selecione o recurso
Brandna grade. -
Navegue até o painel Operações, expanda Localizar e substituir e selecione Localizar e substituir.
-
No painel Localizar e substituir, altere as seguintes propriedades:
- Valor antigo: “
.” - Valor novo: “ ` `” (caractere de espaço)
É possível ver os resultados da operação visualizadas automaticamente na grade de exibição.
- Valor antigo: “
-
Escolha Aplicar.
-
Volte ao painel Operações, expanda Formatar.
-
Selecione Colocar o primeiro caractere em maiúscula. Ative o botão de alternância Colocar todas as palavras em maiúsculas e, em seguida, selecione Aplicar.
-
Selecione Adicionar código ao notebook. Além disso, você também pode copiar o código e salvar o conjunto de dados transformado como um arquivo CSV.
Observação: o código é copiado automaticamente para a célula do notebook e está pronto para uso.
-
Substitua as linhas 10 e 11 pelo código
df = clean_data(df), pois o código gerado no Data Wrangler não substitui o dataframe original. O bloco de código final deve ser assim:def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() return df df = clean_data(df) -
Execute a célula de código e verifique a variável
Brand.df['Brand'].unique()O resultado deve mostrar os valores Minute Maid, Dominicks e Tropicana.
Você aprendeu a manipular graficamente dados de texto e a gerar código facilmente usando o Data Wrangler.
Aplicar transformação de codificação one-hot
Agora, vamos gerar o código para aplicar a transformação de codificação one-hot aos nossos dados como parte de nossas etapas de pré-processamento. Para tornar nosso cenário mais prático, começamos gerando alguns dados de exemplo. Isso nos permite simular uma situação do mundo real e nos fornece um recurso viável.
-
Inicie o Data Wrangler no menu superior do dataframe
df. -
Selecione o recurso
Brandna grade. -
No painel Operações, expanda Fórmulas e, a seguir, selecione Codificação one-hot.
-
No painel Codificação one-hot, selecione Aplicar.
Navegue até o final da grade de exibição do Data Wrangler. Observe que ele adicionou três novos recursos (
Brand_Dominicks,Brand_Minute MaideBrand_Tropicana) e removeu o recursoBrand. -
Saia do Data Wrangler sem gerar o código.
Operações de classificação e filtro
Imagine que precisamos examinar os dados de receita de um repositório específico e classificar os preços dos produtos. Nas etapas a seguir, usamos o Data Wrangler para filtrar e analisar o dataframe df.
-
Inicie o Data Wrangler para o dataframe
df. -
No painel Operações, expanda Classificar e filtrar.
-
Selecione Filtro.
-
No painel Filtro, adicione a seguinte condição:
- Coluna de destino:
Store - Operação:
Equal to - Valor:
1227 - Ação:
Keep matching rows
- Coluna de destino:
-
Selecione Aplicar e observe as alterações na grade de exibição do Data Wrangler.
-
Selecione o recurso Receita e examine os detalhes do painel lateral Resumo.
Quais são alguns dos insights que você pode extrair dele? A assimetria é -0,751, indicando uma pequena distorção para a esquerda (distorção negativa). Isso significa que a parte esquerda da distribuição é um pouco maior que a direita. Em outras palavras, há vários períodos com receitas significativamente abaixo da média.
-
Volte ao painel Operações, expanda Classificar e filtrar.
-
Selecione Classificar valores.
-
No painel Classificar valores, selecione as seguintes propriedades:
- Nome da coluna:
Price - Ordem de classificação:
Descending
- Nome da coluna:
-
Escolha Aplicar.
O preço mais alto do produto para a loja 1227 é de US$ 2,68. Com apenas alguns registros, é mais fácil identificar o preço mais alto do produto, mas considere a complexidade ao lidar com milhares de resultados.
Procurar e remover etapas
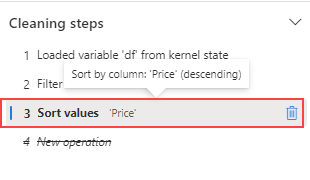
Suponha que você tenha cometido um erro e precise remover a classificação criada na etapa anterior. Siga estas etapas para removê-lo:
-
Navegue até o painel Etapas de limpeza.
-
Selecione a etapa Classificar valores.
-
Selecione o ícone excluir para que ele seja removido.
Importante: a exibição e o resumo da grade são limitados à etapa atual.
Observe que as alterações são revertidas para a etapa anterior, que é a etapa Filtrar.
-
Saia do Data Wrangler sem gerar o código.
Agregação de dados
Suponha que precisamos entender a receita média gerada por cada marca. Nas etapas a seguir, usamos o Data Wrangler para executar um grupo por operação no dataframe df.
-
Inicie o Data Wrangler para o dataframe
df. -
Volte ao painel Operações, selecione Agrupar por e agregar.
-
No painel Colunas a serem agrupadas por, selecione o recurso
Brand. -
Selecione Adicionar agregação.
-
Na propriedade Coluna a ser agregada, selecione o recurso
Revenue. -
Selecione
Meanpara a propriedade Tipo de Agregação. -
Escolha Aplicar.
-
Selecione Copiar código para a área de transferência.
-
Saia do Data Wrangler sem gerar o código.
-
Combine o código da transformação de variável
Brandcom o código gerado pela etapa de agregação na funçãoclean_data(df). O bloco de código final deve ser assim:def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() # Performed 1 aggregation grouped on column: 'Brand' df = df.groupby(['Brand']).agg(Revenue_mean=('Revenue', 'mean')).reset_index() return df df = clean_data(df) -
Execute o código da célula.
-
Verifique os dados no dataframe.
print(df)Resultados:
Marca Revenue_mean 0 Dominicks 33206.330958 1 Minute Maid 33532.999632 2 Tropicana 33637.863412
Você gerou o código para algumas das operações de pré-processamento e copiou o código novamente no notebook como uma função, que, a seguir, você poderá executar, reutilizar ou modificar conforme necessário.
Salvar o notebook e encerrar a sessão do Spark
Agora que terminou de pré-processar os dados para modelar, salve o notebook com um nome significativo e encerre a sessão do Spark.
- Na barra de menus do notebook, use o ícone ⚙️ de Configurações para ver as configurações do notebook.
- Defina o Nome do notebook como Pré-processar dados com o Data Wrangler e feche o painel de configurações.
- No menu do notebook, selecione Parar sessão para encerrar a sessão do Spark.
Limpar os recursos
Neste exercício, você criou um notebook e usou o Data Wrangler para explorar e pré-processar dados para um modelo de machine learning.
Caso terminou de explorar as etapas de pré-processamento, exclua o workspace criado para este exercício.
- Na barra à esquerda, selecione o ícone do workspace para ver todos os itens que ele contém.
- No menu … da barra de ferramentas, selecione Configurações do workspace.
- Na seção Geral, selecione Remover este espaço de trabalho.