Ingerir dados com um pipeline no Microsoft Fabric
Um data lakehouse é um armazenamento de dados analíticos comum para soluções de análise em escala de nuvem. Uma das principais tarefas de um engenheiro de dados é implementar e gerenciar a ingestão de dados de várias fontes de dados operacionais no lakehouse. No Microsoft Fabric, você pode implementar soluções de ETL (extração, transformação e carregamento) ou ELT (extração, carregamento e transformação) para a ingestão de dados por meio da criação de pipelines.
O Fabric também dá suporte ao Apache Spark, permitindo que você escreva e execute um código para processar dados em escala. Combinando as funcionalidades de pipeline e do Spark no Fabric, você pode implementar uma lógica de ingestão de dados complexa que copia dados de fontes externas para o armazenamento OneLake no qual o lakehouse se baseia e usa o código Spark para executar transformações de dados personalizadas antes de carregá-los em tabelas para análise.
Este laboratório levará aproximadamente 45 minutos para ser concluído.
[!Note] Para concluir este exercício, você precisa de um locatário do Microsoft Fabric.
Criar um workspace
Antes de trabalhar com os dados no Fabric, crie um workspace com a avaliação do Fabric habilitada.
- Navegue até a home page do Microsoft Fabric em
https://app.fabric.microsoft.com/home?experience=fabric-developerem um navegador e entre com suas credenciais do Fabric. - Na barra de menus à esquerda, selecione Workspaces (o ícone é semelhante a 🗇).
- Crie um workspace com um nome de sua escolha, selecionando um modo de licenciamento na seção Avançado que inclua a capacidade do Fabric (Avaliação, Premium ou Malha).
-
Quando o novo workspace for aberto, ele estará vazio.
Criar um lakehouse
Agora que você tem um espaço de trabalho, é hora de criar um data lakehouse no qual os dados serão ingeridos.
-
Na barra de menus à esquerda, selecione Criar. Na página Novo, na seção Engenharia de Dados, selecione Lakehouse. Dê um nome exclusivo de sua preferência.
Observação: se a opção Criar não estiver fixada na barra lateral, você precisará selecionar a opção de reticências (…) primeiro.
Após alguns minutos, um lakehouse sem Tabelas nem Arquivos será criado.
-
No painel Explorador à esquerda, no menu … do nó Arquivos, clique em Nova subpasta e crie uma subpasta chamada new_data.
Criar um pipeline
Uma forma simples de ingerir dados é usar uma atividade Copiar Dados em um pipeline para extrair os dados de uma fonte e copiá-los para um arquivo no lakehouse.
- Na Home page do lakehouse, selecione Obter dados e, em seguida, Novo pipeline de dados e crie um novo pipeline de dados com o nome
Ingest Sales Data. - Se o assistente Copiar Dados não abrir automaticamente, selecione Copiar Dados > Usar assistente de cópia na página do editor de pipeline.
-
No assistenteCopiar Dados, na página Escolher fonte de dados, digite HTTP na barra de pesquisa e selecione HTTP na seção Novas fontes.
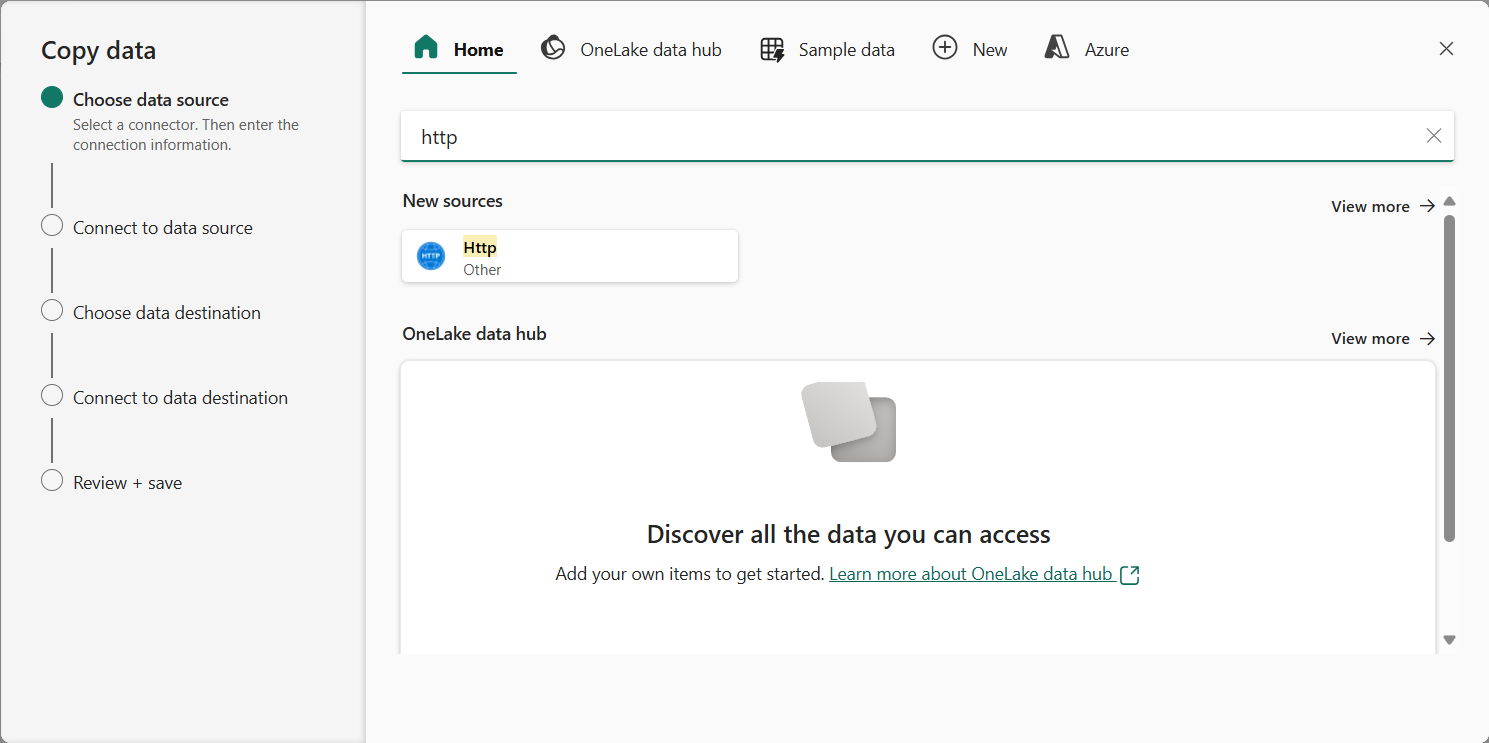
- No painel Conectar-se à fonte de dados, insira as seguintes configurações para a conexão com sua fonte de dados:
- URL:
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv - Conexão: crie uma conexão
- Nome da conexão: especifique um nome exclusivo
- Gateway de dados: (nenhum)
- Tipo de autenticação: Anônimo
- URL:
- Selecione Avançar. Em seguida, verifique se as seguintes configurações estão selecionadas:
- URL Relativa: Deixar em branco
- Método de solicitação: GET
- Cabeçalhos adicionais: Deixar em branco
- Cópia binária: Desmarcada
- Tempo limite de solicitação: Deixar em branco
- Máximo de conexões simultâneas: Deixar em branco
- Selecione Avançar, aguarde a amostragem dos dados e verifique se as seguintes configurações estão selecionadas:
- Formato de arquivo: DelimitedText
- Delimitador de colunas: Vírgula (,)
- Delimitador de linha: Alimentação de linha (\n)
- Primeira linha como cabeçalho: Selecionada
- Tipo de compactação: Nenhum
- Selecione Visualizar dados para ver um exemplo dos dados que serão ingeridos. Em seguida, feche a visualização de dados e selecione Avançar.
- Na página Conectar-se ao destino de dados, defina as seguintes opções de destino de dados e clique em Avançar:
- Pasta raiz: Arquivos
- Nome do caminho da pasta: new_data
- Nome do arquivo: sales.csv
- Comportamento da cópia: Nenhum
- Defina as seguintes opções de formato de arquivo e selecione Avançar:
- Formato de arquivo: DelimitedText
- Delimitador de colunas: Vírgula (,)
- Delimitador de linha: Alimentação de linha (\n)
- Adicionar cabeçalho ao arquivo: Selecionado
- Tipo de compactação: Nenhum
-
Na página Copiar resumo, analise os detalhes da operação de cópia e selecione Salvar + Executar.
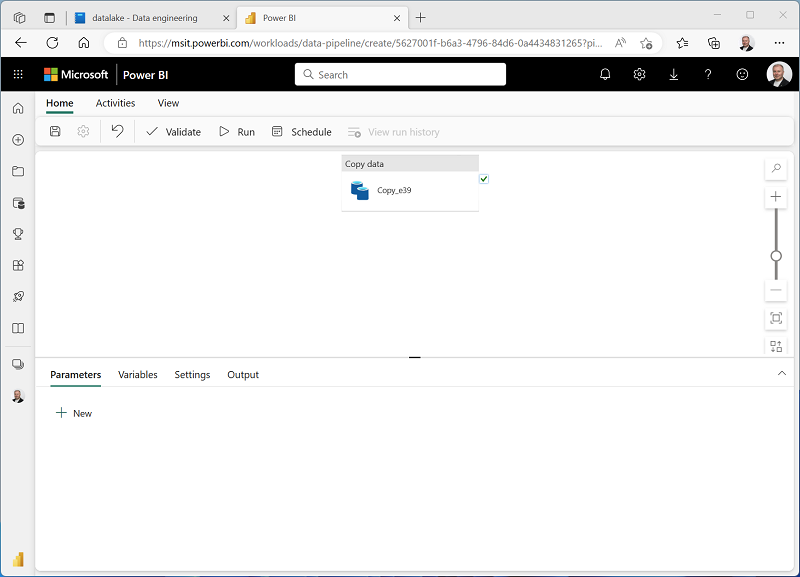
Um pipeline que contém uma atividade Copiar Dados será criado, conforme mostrado aqui:
- Quando o pipeline começar a ser executado, você poderá monitorar o status dele no painel Saída no designer de pipeline. Use o ícone ↻ (Atualizar) para atualizar o status e aguarde até que ele tenha sido concluído com sucesso.
- Na barra de menus à esquerda, selecione o lakehouse.
- Na Home page, no painel do Explorador, expanda Arquivos e selecione a pasta new_data para verificar se o arquivo sales.csv foi copiado.
Criar um notebook
-
Na Home page do lakehouse, no menu Abrir notebook, selecione Novo notebook.
Após alguns segundos, um novo notebook que contém uma só célula será aberto. Os notebooks são compostos por uma ou mais células que podem conter um código ou um markdown (texto formatado).
-
Selecione a célula existente no notebook, que contém um código simples e substitua o código padrão pela declaração de variável a seguir.
table_name = "sales" -
No menu … da célula (no canto superior direito), selecione Alternar célula de parâmetro. Isso configura a célula para que as variáveis declaradas nela sejam tratadas como parâmetros ao executar o notebook por meio de um pipeline.
-
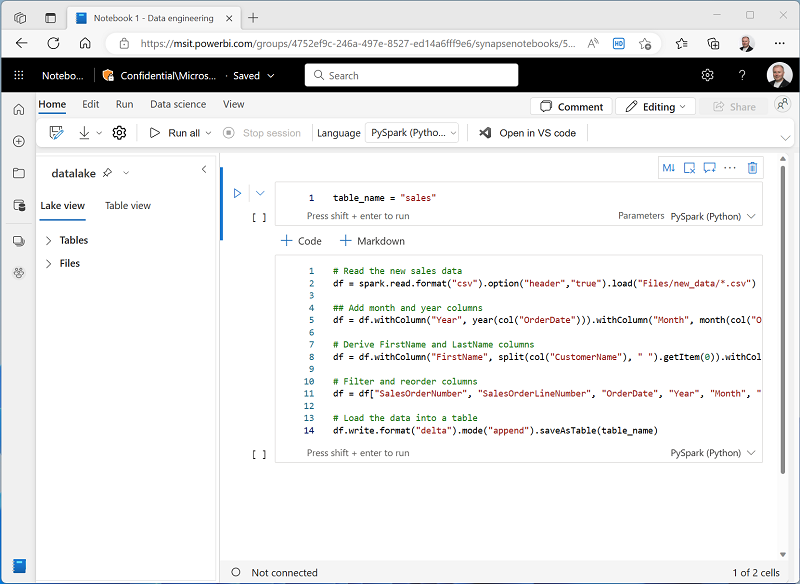
Na célula de parâmetros, use o botão + Código para adicionar uma nova célula de código. Em seguida, adicione o seguinte código a ela:
from pyspark.sql.functions import * # Read the new sales data df = spark.read.format("csv").option("header","true").load("Files/new_data/*.csv") ## Add month and year columns df = df.withColumn("Year", year(col("OrderDate"))).withColumn("Month", month(col("OrderDate"))) # Derive FirstName and LastName columns df = df.withColumn("FirstName", split(col("CustomerName"), " ").getItem(0)).withColumn("LastName", split(col("CustomerName"), " ").getItem(1)) # Filter and reorder columns df = df["SalesOrderNumber", "SalesOrderLineNumber", "OrderDate", "Year", "Month", "FirstName", "LastName", "EmailAddress", "Item", "Quantity", "UnitPrice", "TaxAmount"] # Load the data into a table df.write.format("delta").mode("append").saveAsTable(table_name)Esse código carrega os dados do arquivo sales.csv que foi ingerido pela atividade Copiar Dados, aplica uma lógica de transformação e salva os dados transformados como uma tabela, acrescentando os dados caso a tabela já exista.
-
Verifique se os notebooks são semelhantes a este e use o botão ▷ Executar tudo na barra de ferramentas para executar todas as células que ele contém.
Observação: como esta é a primeira vez que você executa qualquer código Spark nesta sessão, o Pool do Spark precisa ser iniciado. Isso significa que a primeira célula pode levar alguns minutos para ser concluída.
- Quando a execução do notebook terminar, no painel do Explorador à esquerda, no menu … referente a Tabelas, selecione Atualizar e verifique se uma tabela de vendas foi criada.
- Na barra de menus do notebook, use o ícone ⚙️ de Configurações para ver as configurações do notebook. Em seguida, defina o Nome do notebook como
Load Salese feche o painel de configurações. - Na barra de menus do hub à esquerda, selecione o lakehouse.
- No painel do Explorer, atualize a exibição. Em seguida, expanda Tabelas e selecione a tabela sales para ver uma visualização dos dados que ela contém.
Modificar o pipeline
Agora que você implementou um notebook para transformar dados e carregá-los em uma tabela, incorpore o notebook em um pipeline para criar um processo de ETL reutilizável.
- Na barra de menus do hub à esquerda, selecione o pipeline Ingerir Dados de Vendas criado anteriormente.
-
Na guia Atividades, na lista Todas as atividades, clique em Excluir dados. Em seguida, posicione a nova atividade Excluir dados à esquerda da atividade Copiar dados e conecte a saída Ao concluir à atividade Copiar dados, conforme mostrado aqui:
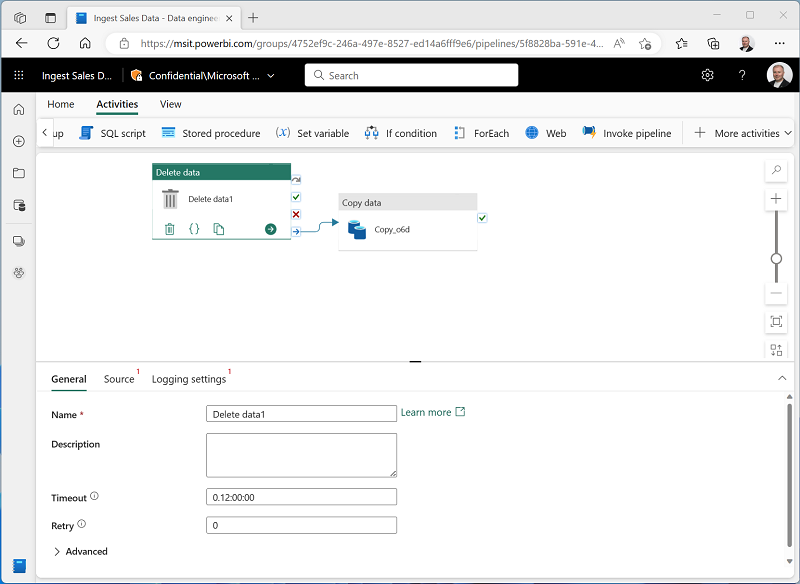
- Selecione a atividade Excluir dados e, no painel abaixo da tela de design, defina as seguintes propriedades:
- Geral:
- Nome:
Delete old files
- Nome:
- Origem
- Conexão: Seu lakehouse
- Tipo de caminho de arquivo: caminho do arquivo curinga
- Caminho da pasta: Arquivos/new_data
- Nome do arquivo curinga:
*.csv - Recursivamente: Selecionado
- Configurações de log:
- Habilitar log: Desmarcado
Essas configurações garantirão que todos os arquivos .csv existentes sejam excluídos antes da cópia do arquivo sales.csv.
- Geral:
- No designer de pipeline, na guia Atividades, selecione Notebook para adicionar uma atividade Notebook ao pipeline.
-
Selecione a atividade Copiar dados e conecte a saída Ao concluir à atividade Notebook, conforme mostrado aqui:
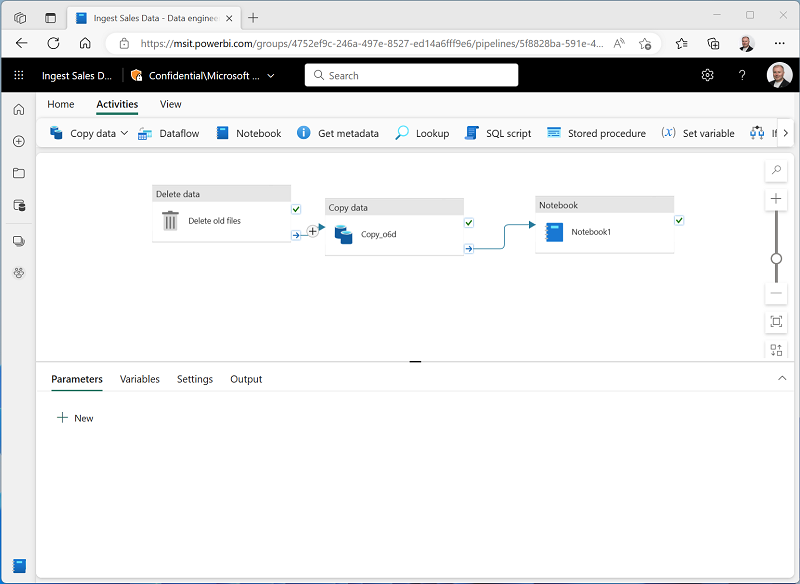
- Selecione a atividade Notebook e, no painel abaixo da tela de design, defina as seguintes propriedades:
- Geral:
- Nome:
Load Sales notebook
- Nome:
- Configurações:
- Notebook: Carregar Vendas
-
Parâmetros base: adicione um novo parâmetro com as seguintes propriedades:
Nome Type Valor table_name String new_sales
O parâmetro table_name será transmitido para o notebook e substituirá o valor padrão atribuído à variável table_name na célula de parâmetros.
- Geral:
-
Na guia Página Inicial, use o ícone 🖫 (Salvar) para salvar o pipeline. Em seguida, use o botão ▷ Executar para executar o pipeline e aguarde a conclusão de todas as atividades.
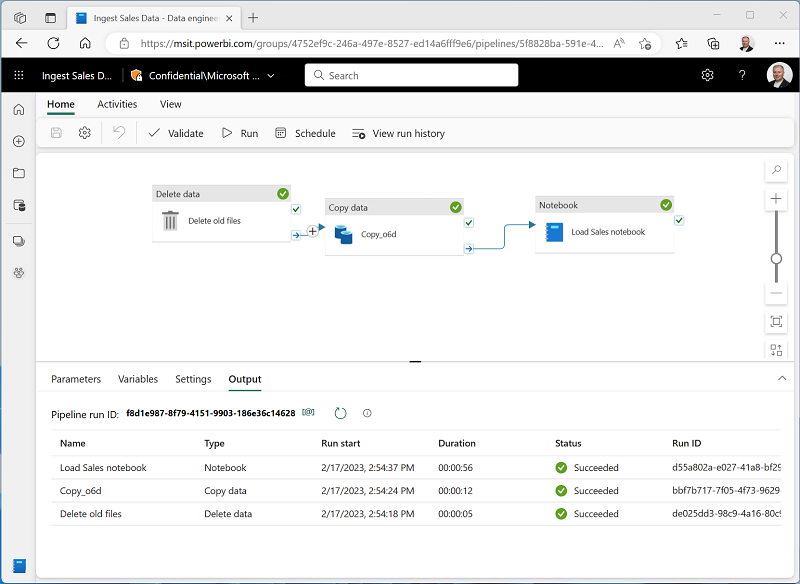
Observação: Caso você receba a mensagem de erro As consultas Spark SQL só são possíveis no contexto de uma lakehouse. Anexe uma casa do lago para prosseguir: Abra seu notebook, selecione a casa do lago que você criou no painel esquerdo, selecione Remover todas as casas do lago e adicione-a novamente. Volte para o designer de pipeline e selecione ▷ Execute.
- Na barra de menus do hub na borda esquerda do portal, selecione o lakehouse.
- No painel do Explorer, expanda Tabelas e selecione a tabela new_sales para ver uma visualização dos dados que ela contém. Essa tabela foi criada pelo notebook quando foi executada pelo pipeline.
Neste exercício, você implementou uma solução de ingestão de dados que usa um pipeline para copiar dados para o lakehouse de uma fonte externa e, depois, usa um notebook do Spark para transformar os dados e carregá-los em uma tabela.
Limpar os recursos
Neste exercício, você aprendeu a implementar um pipeline no Microsoft Fabric.
Se você tiver terminado de explorar seu lakehouse, exclua o workspace criado para este exercício.
- Na barra à esquerda, selecione o ícone do workspace para ver todos os itens que ele contém.
- Clique em Configurações do espaço de trabalho e, na seção Geral, role para baixo e selecione Remover este espaço de trabalho.
- Clique em Excluir para excluir o espaço de trabalho.