Criar uma arquitetura de medalhão em um lakehouse do Microsoft Fabric
Neste exercício, você criará uma arquitetura de medalhão em um Fabric Lakehouse usando notebooks. Você criará um espaço de trabalho, criará um lakehouse, carregará dados na camada bronze, transformará os dados e os carregará na tabela Delta prata, transformará os dados ainda mais e os carregará nas tabelas Delta ouro e, em seguida, explorará o modelo semântico e criará relacionamentos.
Este exercício deve levar aproximadamente 45 minutos para ser concluído
[!Note] Para concluir este exercício, você precisa de um locatário do Microsoft Fabric.
Criar um workspace
Antes de trabalhar com os dados no Fabric, crie um workspace com a avaliação do Fabric habilitada.
- Navegue até a home page do Microsoft Fabric em
https://app.fabric.microsoft.com/home?experience=fabric-developerem um navegador e entre com suas credenciais do Fabric. - Na barra de menus à esquerda, selecione Workspaces (o ícone é semelhante a 🗇).
- Crie um workspace com um nome de sua escolha, selecionando um modo de licenciamento na seção Avançado que inclua a capacidade do Fabric (Avaliação, Premium ou Malha).
-
Quando o novo workspace for aberto, ele estará vazio.
-
Navegue até as configurações do workspace e verifique se o recurso de visualização Configurações do modelo de dados está habilitado. Isso permitirá que você crie relacionamentos entre tabelas em seu lakehouse usando um modelo semântico do Power BI.
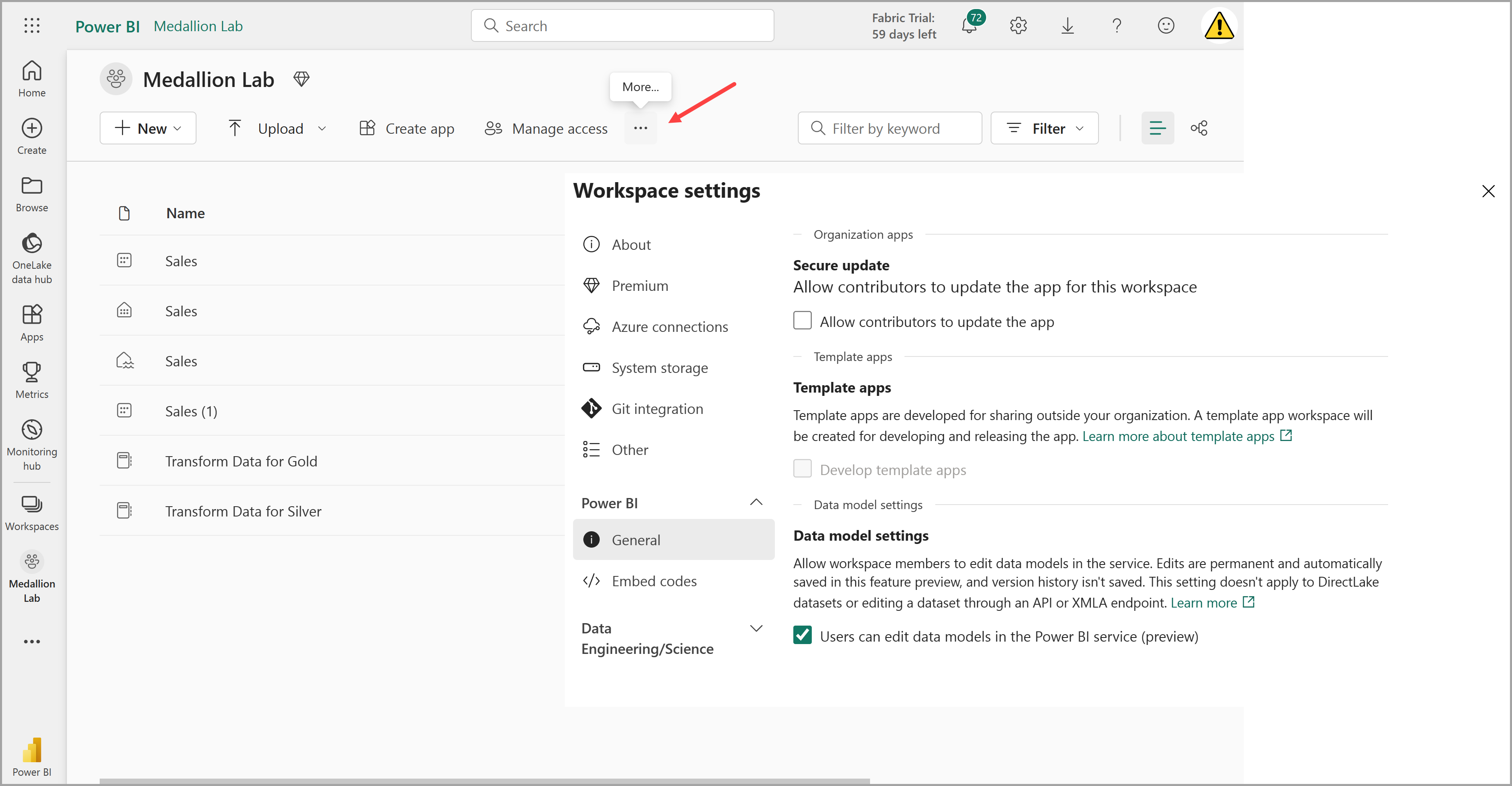
Observação: talvez seja necessário atualizar a guia do navegador depois de habilitar a versão prévia do recurso.
Criar um lakehouse e carregar dados na camada bronze
Agora que você tem um espaço de trabalho, é hora de criar um data lakehouse para os dados que serão analisados.
-
No espaço de trabalho que você acabou de criar, crie um novo Lakehouse com o nome Vendas, selecionando o botão + Novo item.
Após alguns minutos, um lakehouse vazio será criado. Em seguida, você precisará ingerir alguns dados no data lakehouse para análise. Há várias maneiras de fazer isso, mas neste exercício, você apenas baixará um arquivo de texto no computador local (ou na VM de laboratório, se aplicável) e o carregará no lakehouse.
-
Baixe o arquivo de dados para este exercício em
https://github.com/MicrosoftLearning/dp-data/blob/main/orders.zip. Extraia os arquivos e salve-os com seus nomes originais em seu computador local (ou VM de laboratório, se aplicável). Deve haver três arquivos contendo dados de vendas por três anos: 2019.csv, 2020.csv e 2021.csv. -
Volte à guia do navegador da Web que contém o lakehouse e, no menu … da pasta Arquivos no painel do Explorer, selecione Nova subpasta e crie uma pasta chamada bronze.
-
No menu … da pasta bronze, selecione Carregar e Carregar arquivos e carregue os três arquivos (2019.csv, 2020.csv e 2021.csv) do computador local (ou da VM de laboratório, se aplicável) para o lakehouse. Use a tecla shift para carregar todos os três arquivos ao mesmo tempo.
-
Depois que os arquivos forem carregados, expanda a pasta bronze e verifique se os arquivos foram carregados, conforme mostrado aqui:
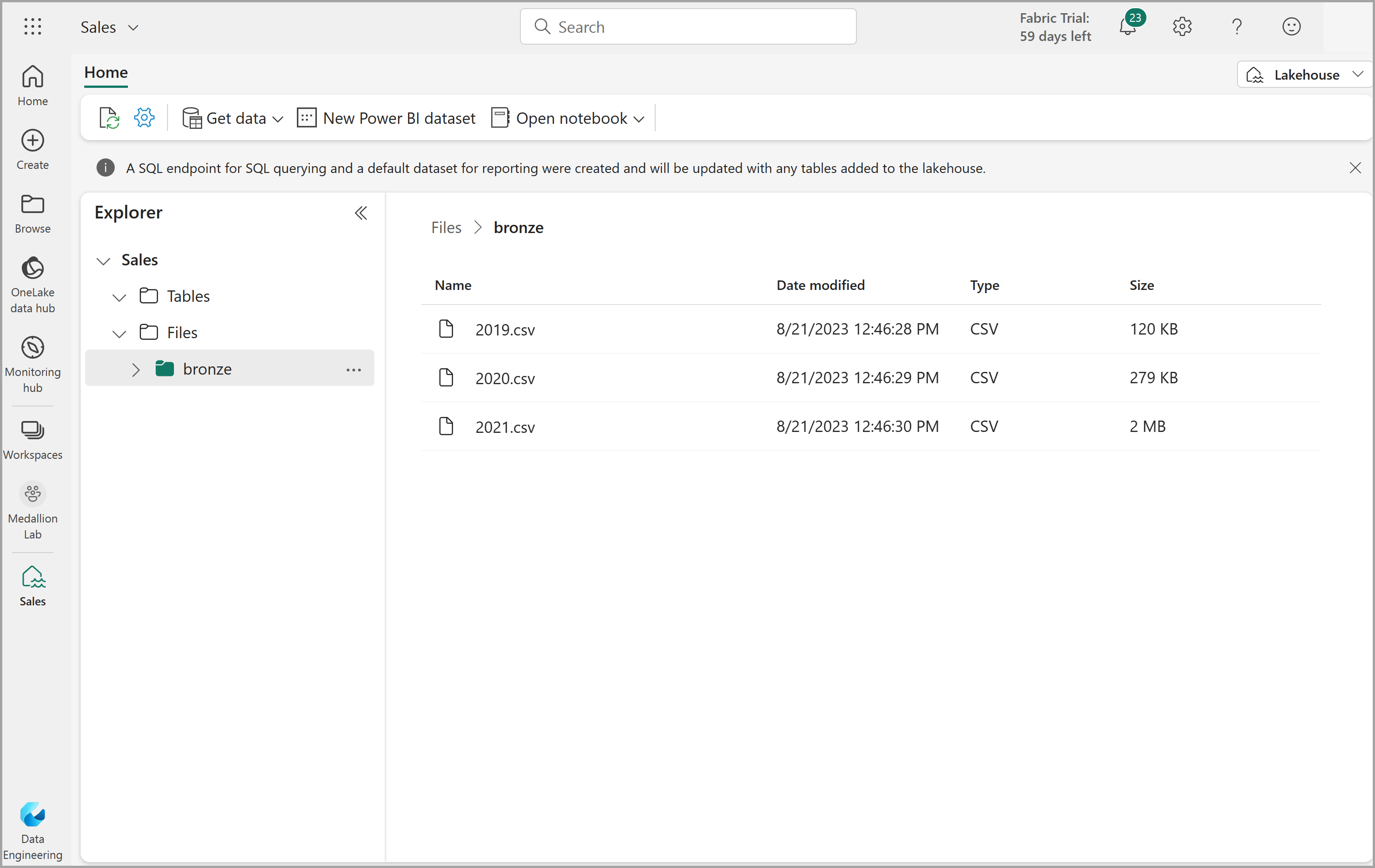
Transformar dados e carregar na tabela Delta silver
Agora que você tem alguns dados na camada bronze do lakehouse, pode usar um notebook para transformar os dados e carregá-los em uma tabela delta na camada silver.
-
Na Home page, ao exibir o conteúdo da pasta bronze no data lake, no menu Abrir notebook, selecione Novo notebook.
Após alguns segundos, um novo notebook que contém uma só célula será aberto. Os notebooks são compostos por uma ou mais células que podem conter um código ou um markdown (texto formatado).
-
Quando o notebook abrir, renomeie-o como
Transform data for Silverselecionando o texto Notebook xxxx na parte superior esquerda do notebook e inserindo o novo nome.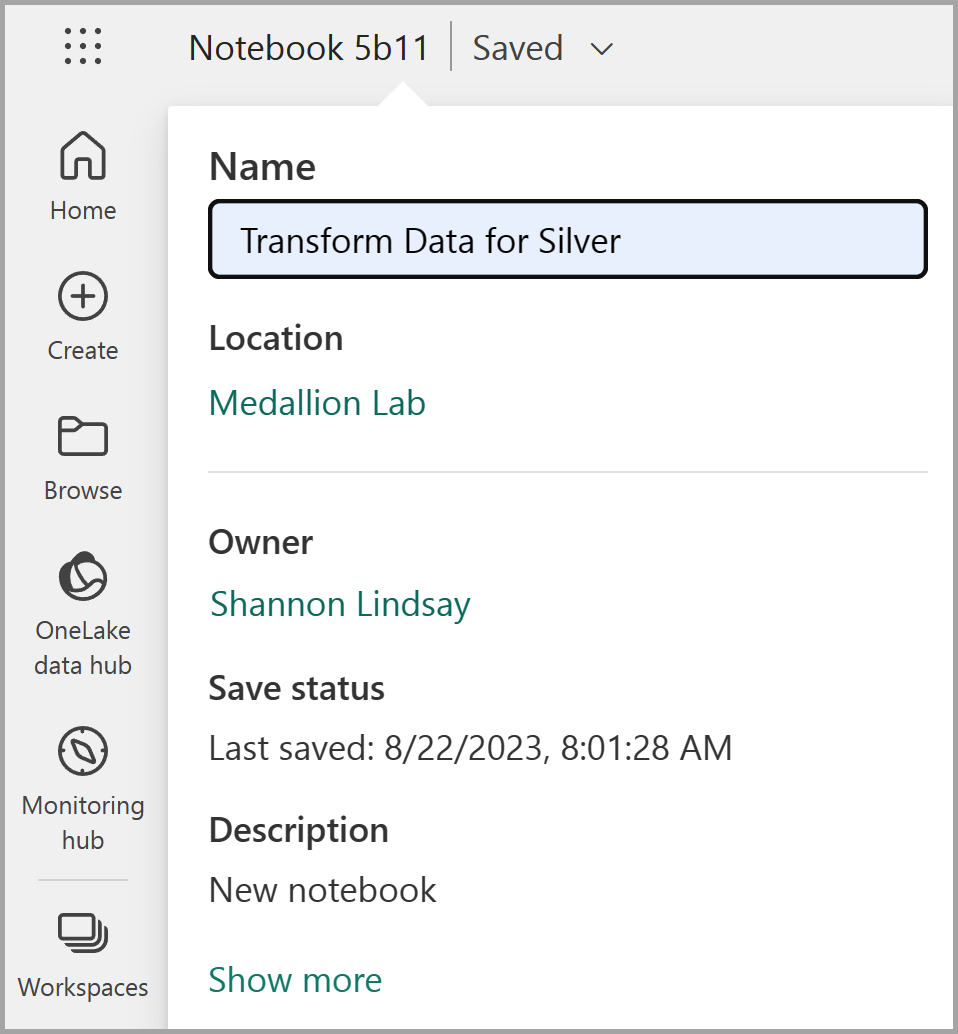
-
Selecione a célula existente no notebook, que contém um código simples com comentários. Realce e exclua essas duas linhas – você não precisará desse código.
Observação: os notebooks permitem que você execute código em uma variedade de linguagens, incluindo Python, Scala e SQL. Neste exercício, você usará o PySpark e o SQL. Você também pode adicionar células de markdown para fornecer texto formatado e imagens para documentar seu código.
-
Cole o seguinte código na célula:
from pyspark.sql.types import * # Create the schema for the table orderSchema = StructType([ StructField("SalesOrderNumber", StringType()), StructField("SalesOrderLineNumber", IntegerType()), StructField("OrderDate", DateType()), StructField("CustomerName", StringType()), StructField("Email", StringType()), StructField("Item", StringType()), StructField("Quantity", IntegerType()), StructField("UnitPrice", FloatType()), StructField("Tax", FloatType()) ]) # Import all files from bronze folder of lakehouse df = spark.read.format("csv").option("header", "true").schema(orderSchema).load("Files/bronze/*.csv") # Display the first 10 rows of the dataframe to preview your data display(df.head(10)) -
Use o botão **▷ (Executar célula) à esquerda da célula para executar o código.
Observação: como esta é a primeira vez que você executa qualquer código Spark neste notebook, uma sessão do Spark precisa ser iniciada. Isso significa que a primeira execução pode levar alguns minutos para ser concluída. As execuções seguintes serão mais rápidas.
-
Quando o comando de célula for concluído, analise a saída abaixo da célula, que deve ser semelhante a essa:
Índice SalesOrderNumber SalesOrderLineNumber OrderDate CustomerName Email Item Quantidade UnitPrice Imposto 1 SO49172 1 01/01/2021 Brian Howard brian23@adventure-works.com Road-250 Red, 52 1 2443.35 195.468 2 SO49173 1 01/01/2021 Linda Alvarez linda19@adventure-works.com Mountain-200 Silver, 38 1 2071.4197 165.7136 … … … … … … … … … … O código que você executou carregou os dados dos arquivos CSV na pasta bronze em um dataframe do Spark e, em seguida, exibiu as primeiras linhas do dataframe.
Observação: você pode limpar, ocultar e redimensionar automaticamente o conteúdo da saída da célula selecionando o menu … na parte superior esquerda do painel de saída.
-
Agora você adicionará colunas para validação e limpeza de dados, usando um dataframe do PySpark para adicionar colunas e atualizar os valores de algumas das colunas existentes. Use o botão + Código para adicionar um novo bloco de código e adicione o seguinte código à célula:
from pyspark.sql.functions import when, lit, col, current_timestamp, input_file_name # Add columns IsFlagged, CreatedTS and ModifiedTS df = df.withColumn("FileName", input_file_name()) \ .withColumn("IsFlagged", when(col("OrderDate") < '2019-08-01',True).otherwise(False)) \ .withColumn("CreatedTS", current_timestamp()).withColumn("ModifiedTS", current_timestamp()) # Update CustomerName to "Unknown" if CustomerName null or empty df = df.withColumn("CustomerName", when((col("CustomerName").isNull() | (col("CustomerName")=="")),lit("Unknown")).otherwise(col("CustomerName")))A primeira linha do código que você executou importa as funções necessárias do PySpark. Em seguida, você está adicionando novas colunas ao dataframe para que possa acompanhar o nome do arquivo de origem, se o pedido foi sinalizado como sendo de antes do ano fiscal de interesse e quando a linha foi criada e modificada.
Por fim, você está atualizando a coluna CustomerName para “Desconhecido” se ela for nula ou vazia.
-
Execute a célula para executar o código usando o botão **▷ (Executar célula).
-
Em seguida, você definirá o esquema para a tabela sales_silver no banco de dados de vendas usando o formato Delta Lake. Crie um novo bloco de código e adicione o seguinte código à célula:
# Define the schema for the sales_silver table from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.sales_silver") \ .addColumn("SalesOrderNumber", StringType()) \ .addColumn("SalesOrderLineNumber", IntegerType()) \ .addColumn("OrderDate", DateType()) \ .addColumn("CustomerName", StringType()) \ .addColumn("Email", StringType()) \ .addColumn("Item", StringType()) \ .addColumn("Quantity", IntegerType()) \ .addColumn("UnitPrice", FloatType()) \ .addColumn("Tax", FloatType()) \ .addColumn("FileName", StringType()) \ .addColumn("IsFlagged", BooleanType()) \ .addColumn("CreatedTS", DateType()) \ .addColumn("ModifiedTS", DateType()) \ .execute() -
Execute a célula para executar o código usando o botão **▷ (Executar célula).
-
Selecione … na seção Tabelas do painel do Explorador e selecione Atualizar. Agora você deve ver a nova tabela sales_silver listada. O ▲ (ícone de triângulo) indica que se trata de uma tabela Delta.
Observação: se não vir a nova tabela, aguarde alguns segundos e selecione Atualizar novamente ou atualize toda a guia do navegador.
-
Agora você deve executar uma operação upsert em uma tabela Delta, atualizando os registros existentes com base em condições específicas e inserindo novos registros quando nenhuma correspondência for encontrada. Adicione um novo bloco de código e cole o seguinte código:
# Update existing records and insert new ones based on a condition defined by the columns SalesOrderNumber, OrderDate, CustomerName, and Item. from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/sales_silver') dfUpdates = df deltaTable.alias('silver') \ .merge( dfUpdates.alias('updates'), 'silver.SalesOrderNumber = updates.SalesOrderNumber and silver.OrderDate = updates.OrderDate and silver.CustomerName = updates.CustomerName and silver.Item = updates.Item' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "SalesOrderNumber": "updates.SalesOrderNumber", "SalesOrderLineNumber": "updates.SalesOrderLineNumber", "OrderDate": "updates.OrderDate", "CustomerName": "updates.CustomerName", "Email": "updates.Email", "Item": "updates.Item", "Quantity": "updates.Quantity", "UnitPrice": "updates.UnitPrice", "Tax": "updates.Tax", "FileName": "updates.FileName", "IsFlagged": "updates.IsFlagged", "CreatedTS": "updates.CreatedTS", "ModifiedTS": "updates.ModifiedTS" } ) \ .execute() -
Execute a célula para executar o código usando o botão **▷ (Executar célula).
Essa operação é importante porque permite que você atualize os registros existentes na tabela com base nos valores de colunas específicas e insira novos registros quando nenhuma correspondência for encontrada. Esse é um requisito comum quando você está carregando dados de um sistema de origem que pode conter atualizações para registros existentes e novos registros.
Agora você tem dados em sua tabela delta silver que estão prontos para transformação e modelagem adicionais.
-
Depois de executar a última célula, selecione a guia Executar acima da faixa de opções e selecione Parar sessão para interromper o recurso de computação que está sendo usado pelo notebook.
Explorar dados na camada silver usando o ponto de extremidade SQL
Agora que você tem dados em sua camada prata, você pode usar o ponto de extremidade de análise de SQL para explorar os dados e executar algumas análises básicas. Isso é útil se você estiver familiarizado com o SQL e quiser fazer alguma exploração básica de seus dados. Nesse exercício, estamos usando a exibição de ponto de extremidade SQL no Fabric, mas você também pode usar outras ferramentas, como o SSMS (SQL Server Management Studio) e o Azure Data Explorer.
-
Navegue de volta para o espaço de trabalho e observe que agora você tem vários itens listados. Selecione o Ponto de extremidade de análise de SQL de vendas para abrir o lakehouse na exibição do ponto de extremidade da análise de SQL.
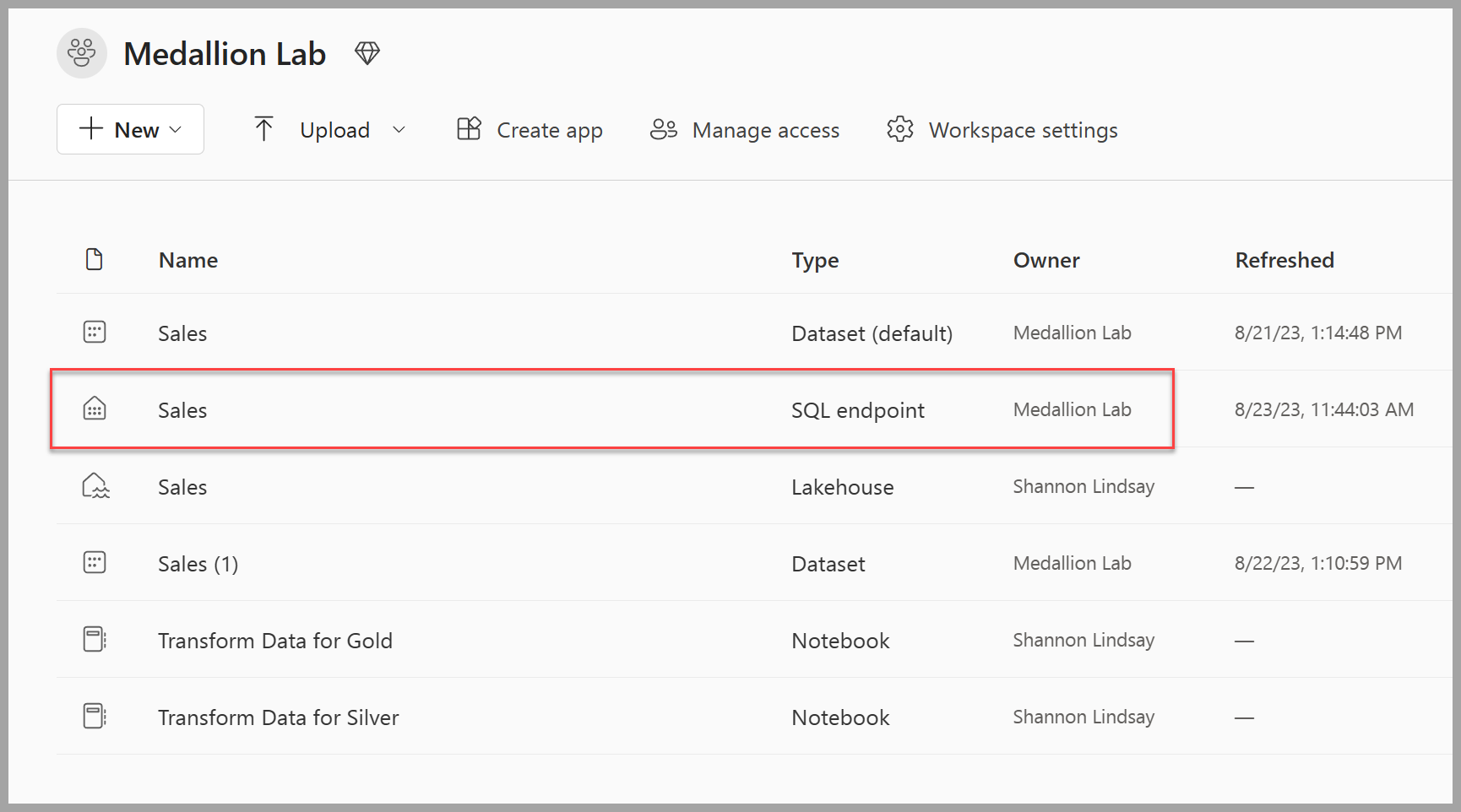
-
Selecione Nova consulta SQL na faixa de opções, que abrirá um editor de consultas SQL. Observe que você pode renomear sua consulta usando o item de menu … ao lado do nome de consulta existente no painel do Explorador.
Em seguida, você executará duas consultas sql para explorar os dados.
-
Cole o snippet a seguir no editor de consultas e clique em Executar:
SELECT YEAR(OrderDate) AS Year , CAST (SUM(Quantity * (UnitPrice + Tax)) AS DECIMAL(12, 2)) AS TotalSales FROM sales_silver GROUP BY YEAR(OrderDate) ORDER BY YEAR(OrderDate)Essa consulta calcula o total de vendas de cada ano na tabela sales_silver. Seus resultados devem ter esta aparência:
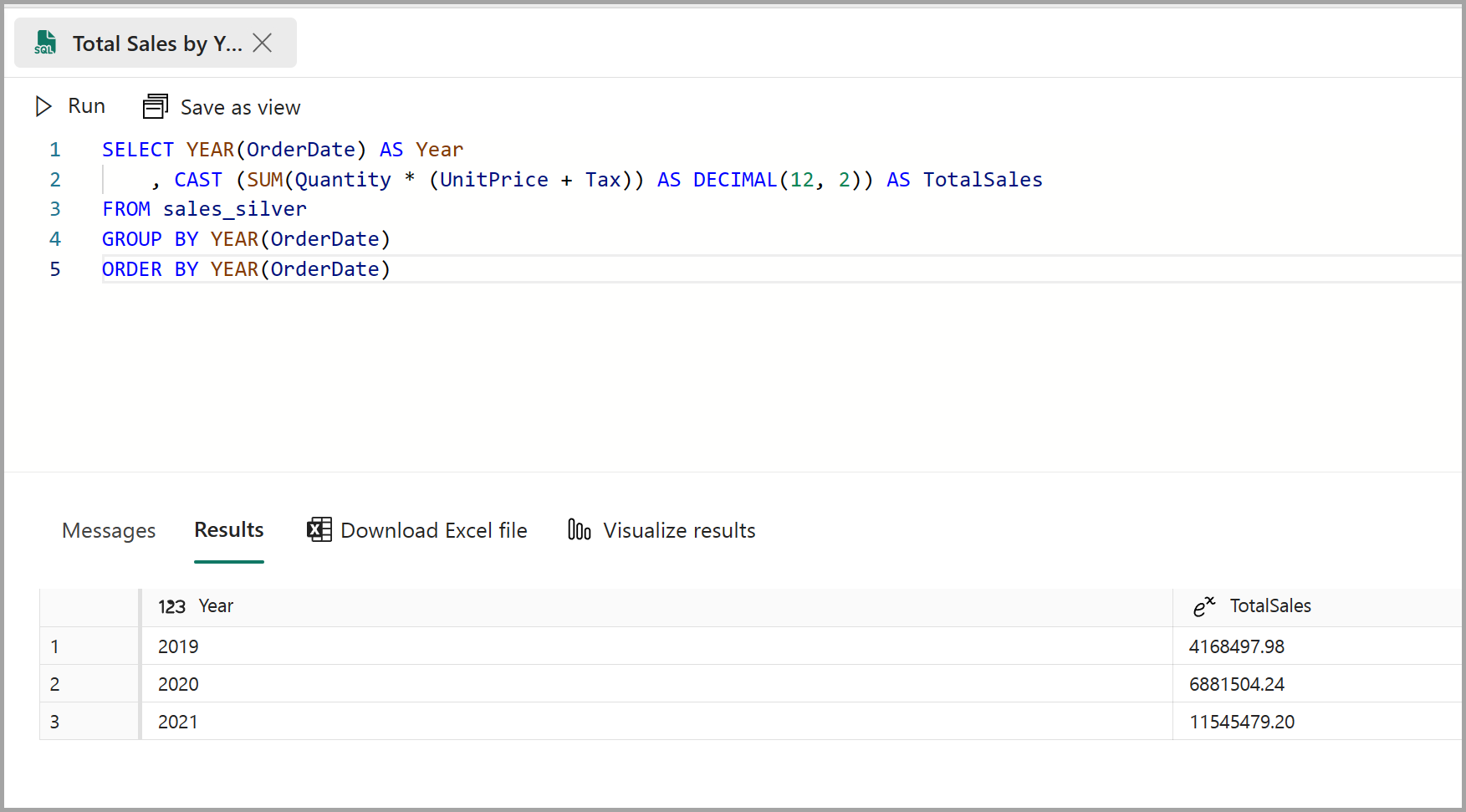
-
Agora, você analisará quais clientes estão comprando mais (em termos de quantidade). Cole o snippet a seguir no editor de consultas e clique em Executar:
SELECT TOP 10 CustomerName, SUM(Quantity) AS TotalQuantity FROM sales_silver GROUP BY CustomerName ORDER BY TotalQuantity DESCEssa consulta calcula a quantidade total de itens comprados por cada cliente na tabela sales_silver e retorna os 10 principais clientes em termos de quantidade.
A exploração de dados na camada silver é útil para análise básica, mas você precisará transformar ainda mais os dados e modelá-los em um esquema star para habilitar análises e relatórios mais avançados. Você fará isso na próxima seção.
Transformar dados para a camada ouro
Você extraiu com êxito os dados da camada bronze, transformou-os e carregou-os em uma tabela Delta silver. Agora você usará um novo notebook para transformar ainda mais os dados, modelá-los em um esquema em estrela e carregá-los em tabelas Delta gold.
Você poderia ter feito tudo isso em um único notebook, mas para este exercício você está usando notebooks separados para demonstrar o processo de transformação de dados de bronze para prata e, em seguida, de prata para ouro. Isso pode ajudar na depuração, solução de problemas e reutilização.
-
Retorne à home page do espaço de trabalho e crie um novo notebook com o nome
Transform data for Gold. -
No painel do Explorador, adicione seu lakehouse de Vendas selecionando Adicionar itens de dados e, em seguida, selecionando o lakehouse de Vendas que você criou anteriormente. Você deverá ver a tabela sales_silver listada na seção Tabelas do painel explorer.
-
No bloco de códigos existente, remova o texto comentado e adicione o seguinte código para carregar dados em seu dataframe e começar a criar seu esquema em estrela e, em seguida, execute-o:
# Load data to the dataframe as a starting point to create the gold layer df = spark.read.table("Sales.sales_silver")Observação: Se você se deparar com um erro
[TooManyRequestsForCapacity]ao executar a primeira célula, verifique se interrompeu a sessão anteriormente em execução no primeiro notebook. -
Adicione um novo bloco de código e cole o código a seguir para criar sua tabela de dimensões de data e executá-la:
from pyspark.sql.types import * from delta.tables import* # Define the schema for the dimdate_gold table DeltaTable.createIfNotExists(spark) \ .tableName("sales.dimdate_gold") \ .addColumn("OrderDate", DateType()) \ .addColumn("Day", IntegerType()) \ .addColumn("Month", IntegerType()) \ .addColumn("Year", IntegerType()) \ .addColumn("mmmyyyy", StringType()) \ .addColumn("yyyymm", StringType()) \ .execute()Observação: você pode executar o comando
display(df)a qualquer momento para verificar o progresso do seu trabalho. Nesse caso, você executaria “display(dfdimDate_gold)” para ver o conteúdo do dataframe dimDate_gold. -
Em um novo bloco de código, adicione e execute o seguinte código para criar um dataframe para sua dimensão de data, dimdate_gold:
from pyspark.sql.functions import col, dayofmonth, month, year, date_format # Create dataframe for dimDate_gold dfdimDate_gold = df.dropDuplicates(["OrderDate"]).select(col("OrderDate"), \ dayofmonth("OrderDate").alias("Day"), \ month("OrderDate").alias("Month"), \ year("OrderDate").alias("Year"), \ date_format(col("OrderDate"), "MMM-yyyy").alias("mmmyyyy"), \ date_format(col("OrderDate"), "yyyyMM").alias("yyyymm"), \ ).orderBy("OrderDate") # Display the first 10 rows of the dataframe to preview your data display(dfdimDate_gold.head(10)) -
Você está separando o código em novos blocos de código para que possa entender e observar o que está acontecendo no notebook à medida que os dados são transformados. Em outro novo bloco de código, adicione e execute o seguinte código para atualizar a dimensão de data à medida que novos dados forem recebidos:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dimdate_gold') dfUpdates = dfdimDate_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.OrderDate = updates.OrderDate' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "OrderDate": "updates.OrderDate", "Day": "updates.Day", "Month": "updates.Month", "Year": "updates.Year", "mmmyyyy": "updates.mmmyyyy", "yyyymm": "updates.yyyymm" } ) \ .execute()A dimensão de data agora está configurada. Agora você criará sua dimensão de cliente.
-
Para criar a tabela de dimensões do cliente, adicione um novo bloco de código, cole e execute o código a seguir:
from pyspark.sql.types import * from delta.tables import * # Create customer_gold dimension delta table DeltaTable.createIfNotExists(spark) \ .tableName("sales.dimcustomer_gold") \ .addColumn("CustomerName", StringType()) \ .addColumn("Email", StringType()) \ .addColumn("First", StringType()) \ .addColumn("Last", StringType()) \ .addColumn("CustomerID", LongType()) \ .execute() -
Em um novo bloco de código, adicione e execute o seguinte código para remover clientes duplicados, selecionar colunas específicas e dividir a coluna “CustomerName” para criar as colunas “Primeiro” e “Último” nome:
from pyspark.sql.functions import col, split # Create customer_silver dataframe dfdimCustomer_silver = df.dropDuplicates(["CustomerName","Email"]).select(col("CustomerName"),col("Email")) \ .withColumn("First",split(col("CustomerName"), " ").getItem(0)) \ .withColumn("Last",split(col("CustomerName"), " ").getItem(1)) # Display the first 10 rows of the dataframe to preview your data display(dfdimCustomer_silver.head(10))Aqui, você criou um novo DataFrame dfdimCustomer_silver executando várias transformações, como descartar duplicatas, selecionar colunas específicas e dividir a coluna “CustomerName” para criar colunas de nome “Primeiro” e “Último”. O resultado é um DataFrame com dados de cliente limpos e estruturados, incluindo colunas de nome “First” e “Last” separadas extraídas da coluna “CustomerName”.
-
Em seguida, criaremos a coluna ID para nossos clientes. Em um novo bloco de código, cole e execute o seguinte:
from pyspark.sql.functions import monotonically_increasing_id, col, when, coalesce, max, lit dfdimCustomer_temp = spark.read.table("Sales.dimCustomer_gold") MAXCustomerID = dfdimCustomer_temp.select(coalesce(max(col("CustomerID")),lit(0)).alias("MAXCustomerID")).first()[0] dfdimCustomer_gold = dfdimCustomer_silver.join(dfdimCustomer_temp,(dfdimCustomer_silver.CustomerName == dfdimCustomer_temp.CustomerName) & (dfdimCustomer_silver.Email == dfdimCustomer_temp.Email), "left_anti") dfdimCustomer_gold = dfdimCustomer_gold.withColumn("CustomerID",monotonically_increasing_id() + MAXCustomerID + 1) # Display the first 10 rows of the dataframe to preview your data display(dfdimCustomer_gold.head(10))Aqui você está limpando e transformando dados do cliente (dfdimCustomer_silver) executando uma antijunção esquerda para excluir duplicatas que já existem na tabela dimCustomer_gold e, em seguida, gerando valores customerID exclusivos usando a função monotonically_increasing_id().
-
Agora você garantirá que sua tabela de clientes permaneça atualizada à medida que novos dados forem fornecidos. Em um novo bloco de código, cole e execute o seguinte:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dimcustomer_gold') dfUpdates = dfdimCustomer_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.CustomerName = updates.CustomerName AND gold.Email = updates.Email' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "CustomerName": "updates.CustomerName", "Email": "updates.Email", "First": "updates.First", "Last": "updates.Last", "CustomerID": "updates.CustomerID" } ) \ .execute() -
Agora você repetirá essas etapas para criar sua dimensão de produto. Em um novo bloco de código, cole e execute o seguinte:
from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.dimproduct_gold") \ .addColumn("ItemName", StringType()) \ .addColumn("ItemID", LongType()) \ .addColumn("ItemInfo", StringType()) \ .execute() -
Adicionar outro bloco de código para criar o dataframe product_silver.
from pyspark.sql.functions import col, split, lit, when # Create product_silver dataframe dfdimProduct_silver = df.dropDuplicates(["Item"]).select(col("Item")) \ .withColumn("ItemName",split(col("Item"), ", ").getItem(0)) \ .withColumn("ItemInfo",when((split(col("Item"), ", ").getItem(1).isNull() | (split(col("Item"), ", ").getItem(1)=="")),lit("")).otherwise(split(col("Item"), ", ").getItem(1))) # Display the first 10 rows of the dataframe to preview your data display(dfdimProduct_silver.head(10)) -
Agora você criará IDs para sua tabela dimProduct_gold. Adicione a sintaxe a seguir em um novo bloco de código e execute-a:
from pyspark.sql.functions import monotonically_increasing_id, col, lit, max, coalesce #dfdimProduct_temp = dfdimProduct_silver dfdimProduct_temp = spark.read.table("Sales.dimProduct_gold") MAXProductID = dfdimProduct_temp.select(coalesce(max(col("ItemID")),lit(0)).alias("MAXItemID")).first()[0] dfdimProduct_gold = dfdimProduct_silver.join(dfdimProduct_temp,(dfdimProduct_silver.ItemName == dfdimProduct_temp.ItemName) & (dfdimProduct_silver.ItemInfo == dfdimProduct_temp.ItemInfo), "left_anti") dfdimProduct_gold = dfdimProduct_gold.withColumn("ItemID",monotonically_increasing_id() + MAXProductID + 1) # Display the first 10 rows of the dataframe to preview your data display(dfdimProduct_gold.head(10))Isso calcula a próxima ID de produto disponível com base nos dados atuais da tabela, atribui essas novas IDs aos produtos e, em seguida, exibe as informações atualizadas do produto.
-
Semelhante ao que você fez com suas outras dimensões, você precisa garantir que sua tabela de produtos permaneça atualizada à medida que novos dados forem fornecidos. Em um novo bloco de código, cole e execute o seguinte:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dimproduct_gold') dfUpdates = dfdimProduct_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.ItemName = updates.ItemName AND gold.ItemInfo = updates.ItemInfo' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "ItemName": "updates.ItemName", "ItemInfo": "updates.ItemInfo", "ItemID": "updates.ItemID" } ) \ .execute()Agora que você criou suas dimensões, a etapa final é criar a tabela de fatos.
-
Em um novo bloco de código, cole e execute o seguinte código para criar a tabela de fatos:
from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.factsales_gold") \ .addColumn("CustomerID", LongType()) \ .addColumn("ItemID", LongType()) \ .addColumn("OrderDate", DateType()) \ .addColumn("Quantity", IntegerType()) \ .addColumn("UnitPrice", FloatType()) \ .addColumn("Tax", FloatType()) \ .execute() -
Em um novo bloco de código, cole e execute o seguinte código para criar um novo dataframe para combinar dados de vendas com informações de clientes e produtos, incluindo ID do cliente, ID do item, data do pedido, quantidade, preço unitário e imposto:
from pyspark.sql.functions import col dfdimCustomer_temp = spark.read.table("Sales.dimCustomer_gold") dfdimProduct_temp = spark.read.table("Sales.dimProduct_gold") df = df.withColumn("ItemName",split(col("Item"), ", ").getItem(0)) \ .withColumn("ItemInfo",when((split(col("Item"), ", ").getItem(1).isNull() | (split(col("Item"), ", ").getItem(1)=="")),lit("")).otherwise(split(col("Item"), ", ").getItem(1))) \ # Create Sales_gold dataframe dffactSales_gold = df.alias("df1").join(dfdimCustomer_temp.alias("df2"),(df.CustomerName == dfdimCustomer_temp.CustomerName) & (df.Email == dfdimCustomer_temp.Email), "left") \ .join(dfdimProduct_temp.alias("df3"),(df.ItemName == dfdimProduct_temp.ItemName) & (df.ItemInfo == dfdimProduct_temp.ItemInfo), "left") \ .select(col("df2.CustomerID") \ , col("df3.ItemID") \ , col("df1.OrderDate") \ , col("df1.Quantity") \ , col("df1.UnitPrice") \ , col("df1.Tax") \ ).orderBy(col("df1.OrderDate"), col("df2.CustomerID"), col("df3.ItemID")) # Display the first 10 rows of the dataframe to preview your data display(dffactSales_gold.head(10)) -
Agora, você garantirá que os dados de vendas permaneçam atualizados executando o seguinte código em um novo bloco de código:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/factsales_gold') dfUpdates = dffactSales_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.OrderDate = updates.OrderDate AND gold.CustomerID = updates.CustomerID AND gold.ItemID = updates.ItemID' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "CustomerID": "updates.CustomerID", "ItemID": "updates.ItemID", "OrderDate": "updates.OrderDate", "Quantity": "updates.Quantity", "UnitPrice": "updates.UnitPrice", "Tax": "updates.Tax" } ) \ .execute()Aqui você está usando a operação de mesclagem do Delta Lake para sincronizar e atualizar a tabela factsales_gold com novos dados de vendas (dffactSales_gold). A operação compara a data do pedido, a ID do cliente e a ID do item entre os dados existentes (tabela silver) e os novos dados (atualiza o DataFrame), atualizando registros correspondentes e inserindo novos registros conforme necessário.
Agora você tem uma camada ouro modelada e com curadoria que pode ser utilizada para relatar e analisar.
Criar um modelo semântico
No workspace, agora você pode usar a camada gold para criar um relatório e analisar os dados. Você pode acessar o modelo semântico diretamente no seu espaço de trabalho para criar relacionamentos e medidas para relatórios.
Observe que não é possível usar o modelo semântico padrão que é criado automaticamente quando você cria um lakehouse. Você deve criar um novo modelo semântico que inclua as tabelas Gold que criou neste exercício, com base no Explorador.
- Em seu workspace, navegue até o lakehouse de vendas.
- Selecione Novo modelo semântico na faixa de opções do modo de exibição do Explorador.
- Atribua o nome Sales_Gold ao seu novo modelo semântico.
- Selecione suas tabelas de ouro transformadas para incluir no seu modelo semântico e selecione Confirmar.
- dimdate_gold
- dimcustomer_gold
- dimproduct_gold
- factsales_gold
Isso abrirá o modelo semântico no Fabric, no qual você poderá criar relacionamentos e medidas, conforme mostrado aqui:
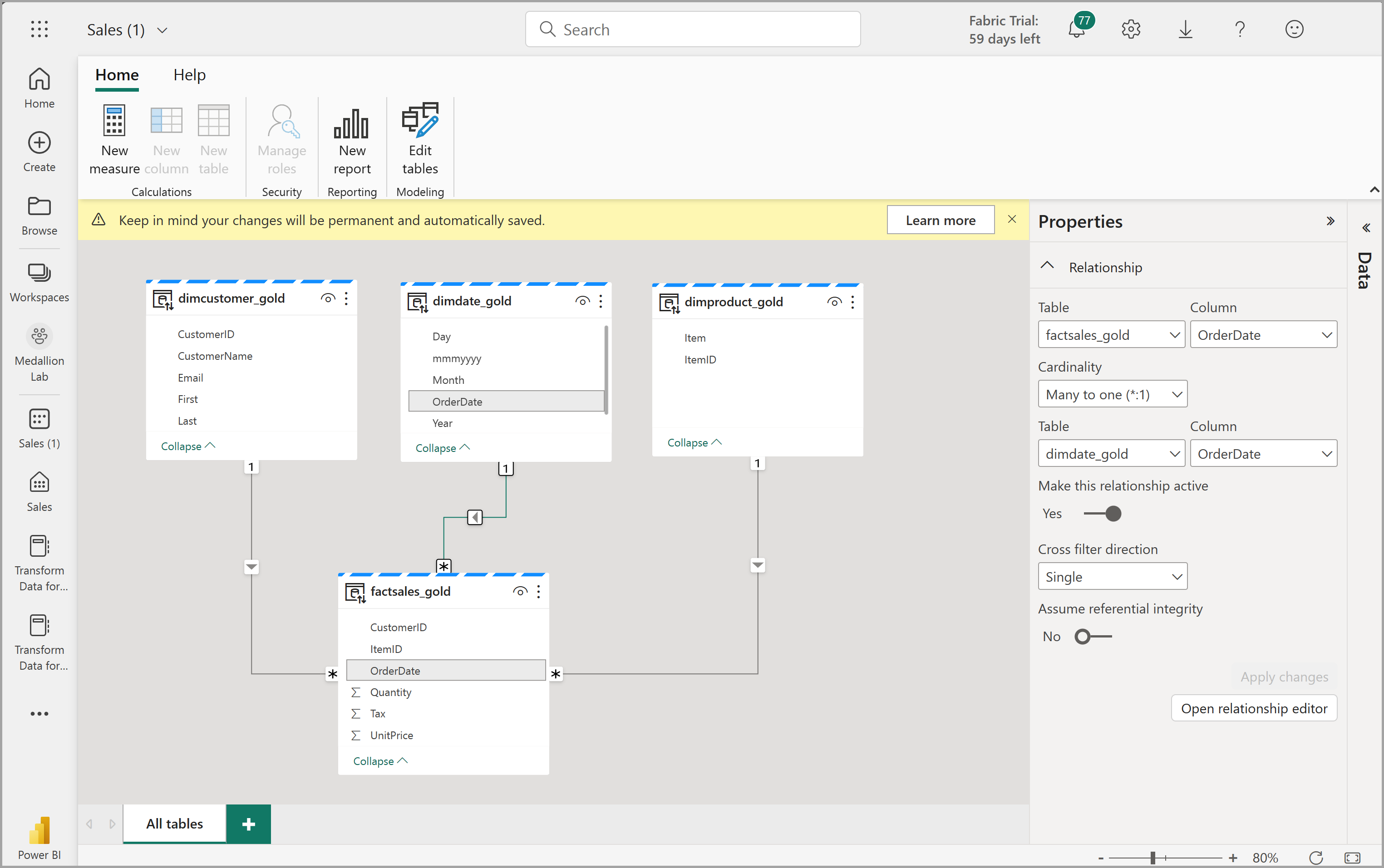
A partir daqui, você ou outros membros da sua equipe de dados podem criar relatórios e dashboards com base nos dados em seu lakehouse. Esses relatórios serão conectados diretamente à camada gold do seu lakehouse, para que eles sempre reflitam os dados mais recentes.
Limpar os recursos
Neste exercício, você aprendeu a criar uma arquitetura de medalhão em um lakehouse do Microsoft Fabric.
Se você tiver terminado de explorar seu lakehouse, exclua o workspace criado para este exercício.
- Na barra à esquerda, selecione o ícone do workspace para ver todos os itens que ele contém.
- No menu … da barra de ferramentas, selecione Configurações do workspace.
- Na seção Geral, selecione Remover este espaço de trabalho.