Criar um lakehouse do Microsoft Fabric
As soluções de análise de dados em grande escala têm sido tradicionalmente criadas em torno de um data warehouse, no qual os dados são armazenados em tabelas relacionais e consultados por meio do SQL. O crescimento do “Big Data” (caracterizado por grandes volumes, variedade e velocidade de novos ativos de dados) acompanhado da disponibilidade de armazenamento de baixo custo e tecnologias de computação distribuída em escala de nuvem levou a uma abordagem alternativa para o armazenamento de dados analíticos: o data lake. Em um data lake, os dados são armazenados como arquivos sem impor um esquema fixo para o armazenamento. Cada vez mais, os analistas e os engenheiros de dados buscam se beneficiar dos melhores recursos dessas duas abordagens combinando-as em um data lakehouse, nos quais os dados são armazenados em arquivos em um data lake e um esquema relacional é aplicado a eles como uma camada de metadados para que possam ser consultados por meio da semântica do SQL tradicional.
No Microsoft Fabric, um lakehouse fornece armazenamento de arquivos altamente escalonável em um armazenamento OneLake (criado no Azure Data Lake Store Gen2) com um metastore para objetos relacionais, como tabelas e exibições baseadas no formato de tabela Delta Lake de código aberto. O Delta Lake permite que você defina um esquema de tabelas no seu lakehouse que você pode consultar usando o SQL.
Este laboratório leva cerca de 30 minutos para ser concluído.
Observação: Você precisa de uma avaliação do Microsoft Fabric para concluir esse exercício.
Criar um workspace
Antes de trabalhar com os dados no Fabric, crie um workspace com a avaliação do Fabric habilitada.
- Navegue até a home page do Microsoft Fabric em
https://app.fabric.microsoft.com/home?experience=fabricem um navegador e entre com suas credenciais do Fabric. - Na barra de menus à esquerda, selecione Workspaces (o ícone é semelhante a 🗇).
- Crie um workspace com um nome de sua escolha, selecionando um modo de licenciamento na seção Avançado que inclua a capacidade do Fabric (Avaliação, Premium ou Malha).
-
Quando o novo workspace for aberto, ele estará vazio.
Criar um lakehouse
Agora que você tem um espaço de trabalho, é hora de criar um data lakehouse para seus arquivos de dados.
-
Na barra de menus à esquerda, selecione Criar. Na página Novo, na seção Engenharia de Dados, selecione Lakehouse. Dê um nome exclusivo de sua preferência.
Observação: se a opção Criar não estiver fixada na barra lateral, você precisará selecionar a opção de reticências (…) primeiro.
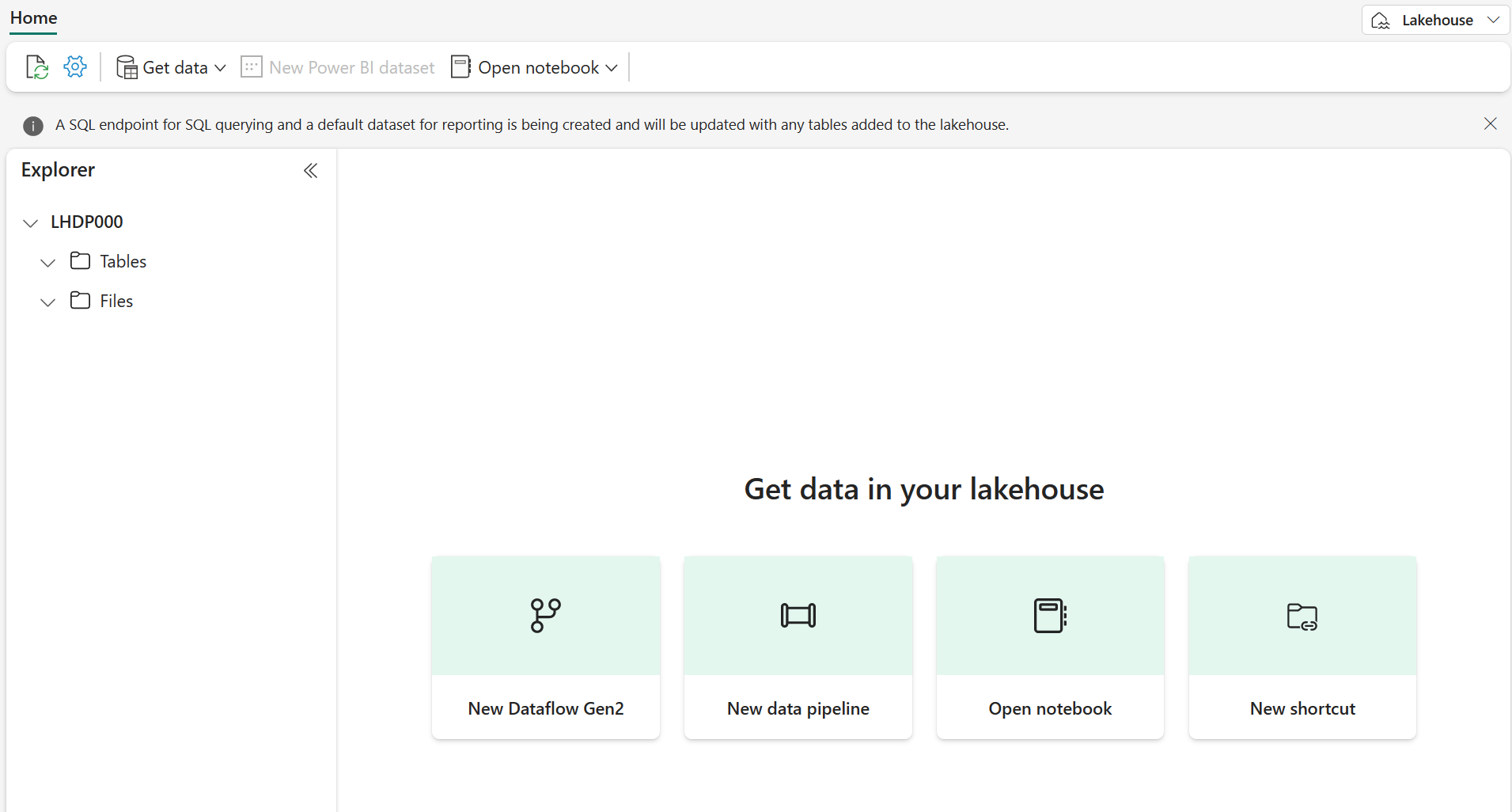
Após alguns minutos, um lakehouse será criado:
-
Veja o novo lakehouse e observe que o painel do Lakehouse Explorer à esquerda permite que você navegue pelas tabelas e pelos arquivos no lakehouse:
- A pasta Tabelas contém as tabelas que você pode consultar usando a semântica do SQL. As tabelas de um lakehouse do Microsoft Fabric são baseadas no formato de arquivo Delta Lake de código aberto, comumente usado no Apache Spark.
- A pasta Arquivos contém arquivos de dados no armazenamento OneLake para o lakehouse que não estão associados às tabelas delta gerenciadas. Você também pode criar atalhos nessa pasta para referenciar os dados armazenados externamente.
Atualmente, não há tabelas nem arquivos no lakehouse.
Fazer upload de um arquivo
O Fabric fornece várias maneiras de carregar dados no lakehouse, incluindo suporte interno para pipelines que copiam dados de fontes externas e fluxos de dados (Gen2) que você pode definir por meio de ferramentas visuais baseadas no Power Query. No entanto, uma das maneiras mais simples de ingerir pequenos volumes de dados é carregar arquivos ou pastas do computador local (ou da VM de laboratório, se aplicável).
-
Baixe o arquivo sales.csv de
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv, salvando-o como sales.csv no computador local (ou na VM do laboratório, se aplicável).Observação: para baixar o arquivo, abra uma nova guia no navegador e cole a URL. Clique com o botão direito do mouse em qualquer lugar da página que contém os dados e selecione Salvar como para salvar a página como um arquivo CSV.
- Volte à guia do navegador da Web que contém o lakehouse e, no menu … da pasta Arquivos no painel do Lakehouse Explorer, selecione Nova subpasta e crie uma subpasta chamada data.
- No menu … da nova pasta dados, clique em Carregar e Carregar arquivos e faça o upload do arquivo sales.csv do computador local (ou da VM do laboratório, se aplicável).
-
Depois que o arquivo for carregado, selecione a pasta Arquivos/dados e verifique se o arquivo sales.csv foi carregado, conforme mostrado aqui:
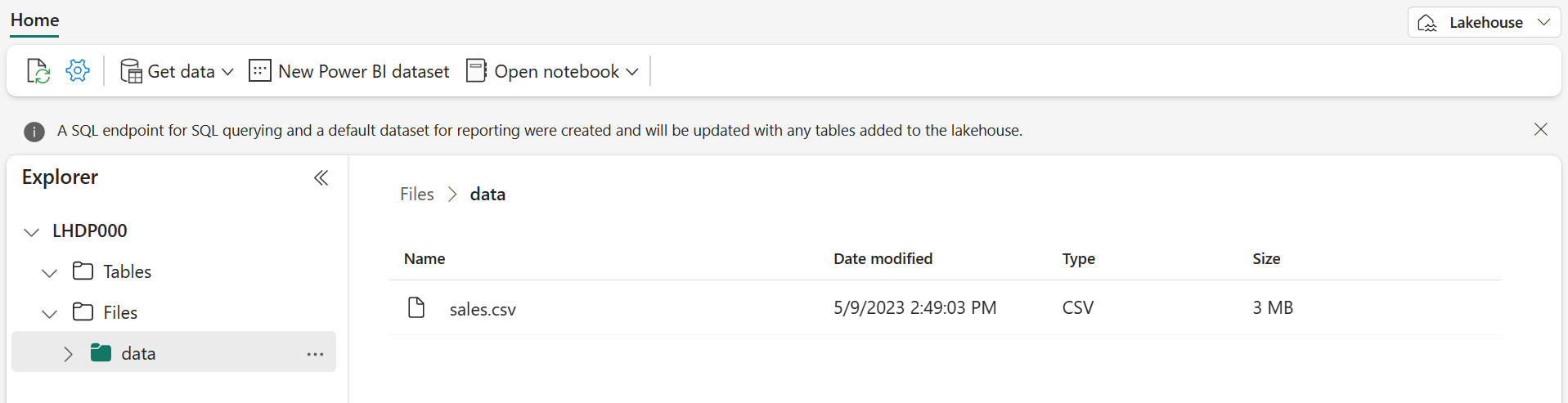
- Selecione o arquivo sales.csv para ver uma visualização do conteúdo dele.
Explorar atalhos
Em muitos cenários, os dados com os quais você precisa trabalhar no lakehouse podem ser armazenados em algum outro local. Embora haja várias maneiras de ingerir dados no armazenamento OneLake para seu lakehouse, outra opção é criar um atalho. Os atalhos permitem que você inclua dados de origem externa na sua solução de análise sem a sobrecarga e o risco de inconsistência de dados associados à cópia deles.
- No menu … da pasta Arquivos, selecione Novo atalho.
- Veja os tipos de fontes de dados disponíveis para os atalhos. Em seguida, feche a caixa de diálogo Novo atalho sem criar um atalho.
Carregar dados de arquivo em uma tabela
Os dados de vendas carregados estão em um arquivo, com o qual os analistas e os engenheiros de dados podem trabalhar diretamente usando o código do Apache Spark. No entanto, em muitos cenários, o ideal é carregar os dados do arquivo em uma tabela para que você possa consultá-los usando o SQL.
- Na home page, selecione a pasta Arquivos/Dados para que você possa ver o arquivo sales.csv que ela contém.
- No menu … do arquivo sales.csv, clique em Carregar em tabelas > Nova tabela.
-
Na caixa de diálogo Carregar na tabela, defina o nome da tabela como sales e confirme a operação de carregamento. Em seguida, aguarde até que a tabela seja criada e carregada.
Dica: se a tabela sales não for exibida automaticamente, no menu … da pasta Tabelas, selecione Atualizar.
-
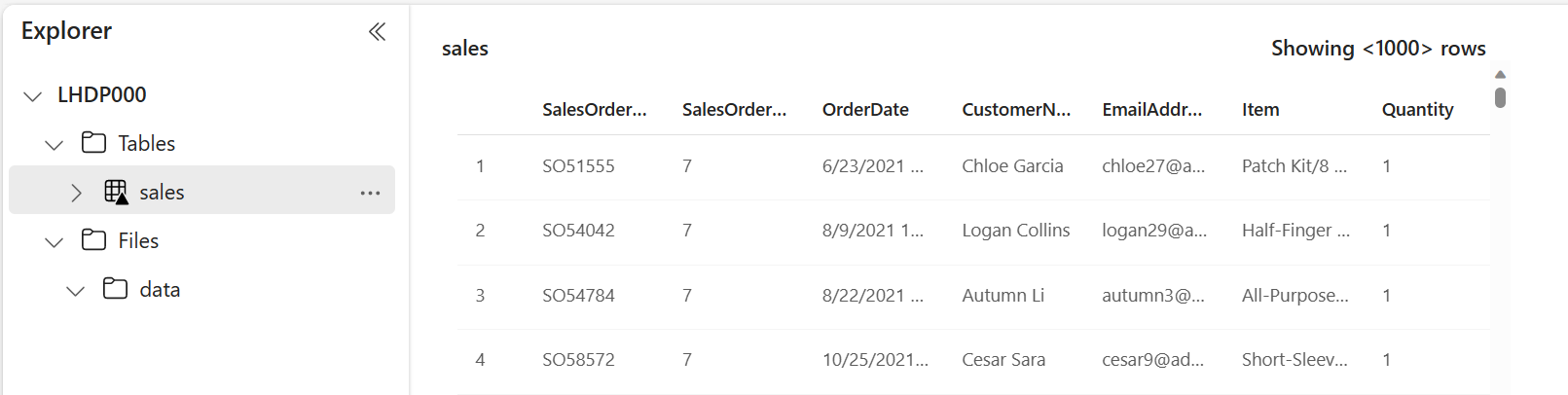
No painel do Lakehouse Explorer, selecione a tabela sales criada para ver os dados.
-
No menu … da tabela sales, selecione Exibir arquivos para ver os arquivos subjacentes dessa tabela
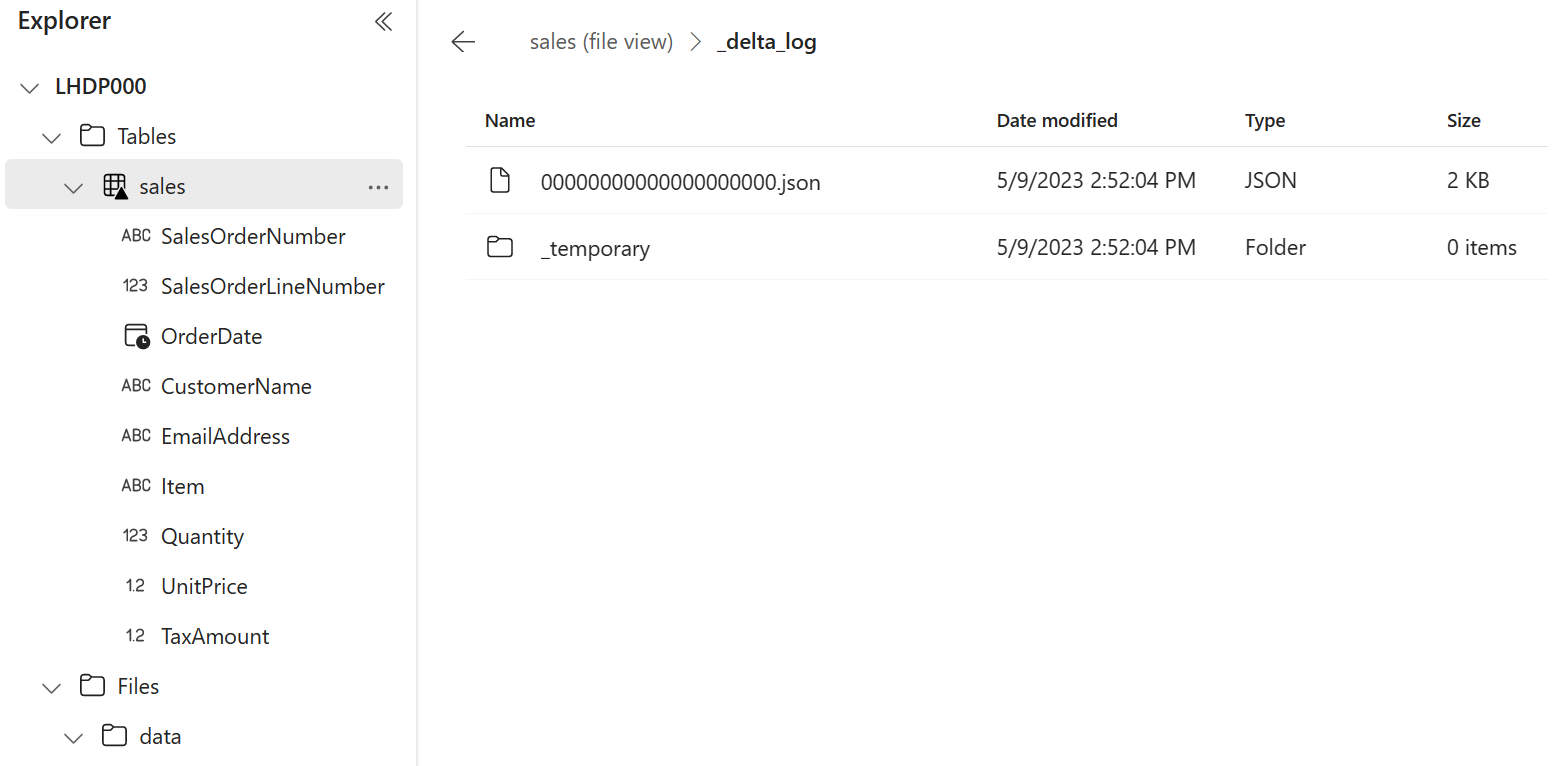
Os arquivos de uma tabela delta são armazenados no formato Parquet e incluem uma subpasta chamada _delta_log, na qual os detalhes das transações aplicadas à tabela são registrados.
Usar o SQL para consultar tabelas
Quando você cria um lakehouse e define tabelas nele, um ponto de extremidade SQL é criado automaticamente por meio do qual as tabelas podem ser consultadas usando instruções SQL SELECT.
-
No canto superior direito da página do Lakehouse, alterne do Lakehouse para o Ponto de extremidade de análise do SQL. Em seguida, aguarde um curto período até que o ponto de extremidade de análise SQL do lakehouse seja aberto em uma interface visual na qual você poderá consultar as tabelas.
-
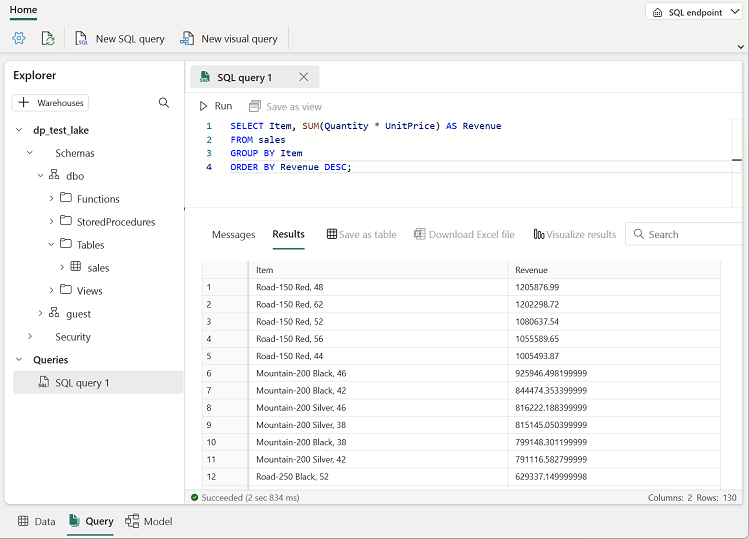
Use o botão Nova consulta SQL para abrir um novo editor de consultas e insira a seguinte consulta SQL:
SELECT Item, SUM(Quantity * UnitPrice) AS Revenue FROM sales GROUP BY Item ORDER BY Revenue DESC;Observação: Se você estiver em uma VM de laboratório e tiver problemas ao inserir a consulta SQL, poderá baixar o arquivo 01-Snippets.txt de
https://github.com/MicrosoftLearning/mslearn-fabric/raw/main/Allfiles/Labs/01/Assets/01-Snippets.txt, salvando-o na VM. Em seguida, você pode copiar a consulta do arquivo de texto. -
Use o botão ▷ Executar para executar a consulta e ver os resultados, que mostrarão a receita total de cada produto.
Criar uma consulta visual
Embora muitos profissionais de dados estejam familiarizados com o SQL, os analistas de dados com a experiência do Power BI podem aplicar as habilidades do Power Query para criar consultas visuais.
- Na barra de ferramentas, expanda a opção Nova consulta SQL e clique em Nova consulta visual.
-
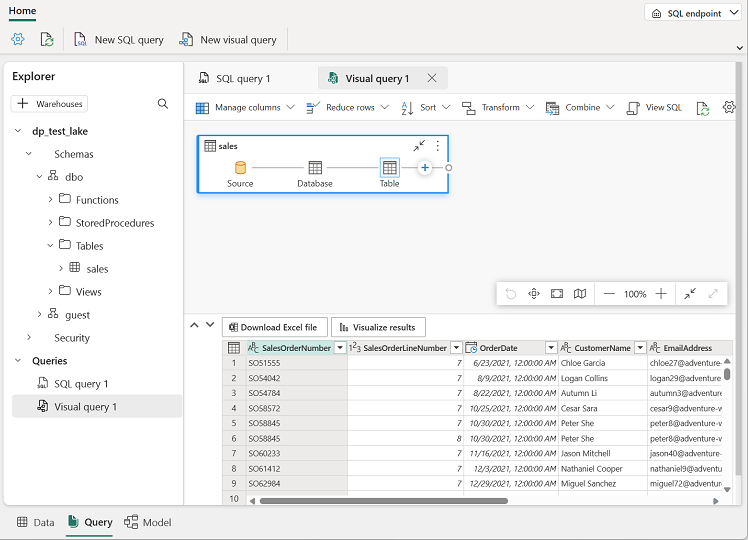
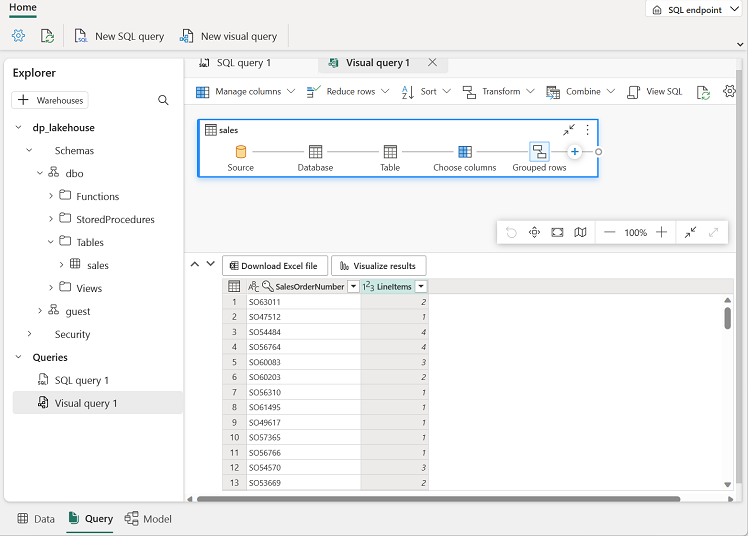
Arraste a tabela sales para o novo painel do editor de consultas visuais que será aberto para criar uma Power Query, conforme mostrado aqui:
-
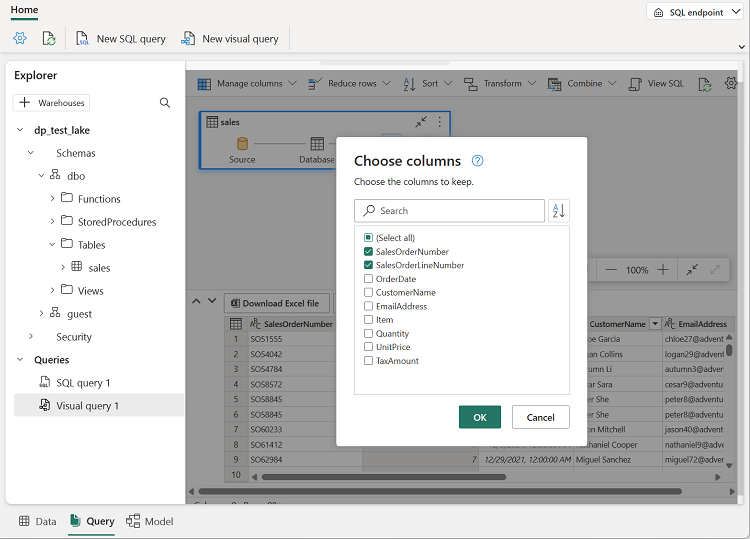
No menu Gerenciar colunas, selecione Escolher colunas. Em seguida, selecione apenas as colunas SalesOrderNumber e SalesOrderLineNumber.
-
No menu Transformar, selecione Agrupar por. Em seguida, agrupe os dados usando as seguintes configurações Básicas:
- Agrupar por: SalesOrderNumber
- Novo nome de coluna: LineItems
- Operação: Contar valores distintos
- Coluna: SalesOrderLineNumber
Quando você terminar, o painel de resultados abaixo da consulta visual mostrará o número de itens de linha para cada pedido de vendas.
Limpar os recursos
Neste exercício, você criou um lakehouse e importou dados para ele. Você viu como um lakehouse consiste em arquivos e tabelas armazenados em um armazenamento de dados OneLake. As tabelas gerenciadas podem ser consultadas por meio do SQL e incluídas em um modelo semântico padrão para dar suporte a visualizações de dados.
Se você tiver terminado de explorar seu lakehouse, exclua o workspace criado para este exercício.
- Na barra à esquerda, selecione o ícone do workspace para ver todos os itens que ele contém.
- Na barra de ferramentas, clique em Configurações do workspace.
- Na seção Geral, selecione Remover este espaço de trabalho.