Microsoft Fabric Eventhouse에서 데이터 작업
Microsoft Fabric에서는 이벤트와 관련된 실시간 데이터를 저장하는 데 Eventhouse가 사용되며, 종종 스트리밍 데이터 원본에서 Eventstream으로 캡처합니다.
Eventhouse 내에서 데이터는 하나 이상의 KQL 데이터베이스에 저장되며, 각 데이터베이스에는 KQL(Kusto 쿼리 언어) 또는 SQL(구조적 쿼리 언어) 하위 집합을 사용하여 쿼리할 수 있는 테이블 및 기타 개체가 포함됩니다.
이 연습에서는 택시 승차와 관련된 몇 가지 샘플 데이터로 Eventhouse를 만들고 채운 다음 KQL 및 SQL을 사용하여 데이터를 쿼리합니다.
이 연습을 완료하는 데 약 25분이 소요됩니다.
작업 영역 만들기
Fabric에서 데이터를 작업하기 전에 Fabric 용량이 활성화된 작업 영역을 만듭니다.
- Microsoft Fabric 홈페이지(
https://app.fabric.microsoft.com/home?experience=fabric)에서 실시간 인텔리전스를 선택합니다. - 왼쪽 메뉴 모음에서 작업 영역을 선택합니다(아이콘은 와 유사함).
- Fabric 용량이 포함된 라이선스 모드(평가판, 프리미엄 또는 Fabric)를 선택하여 원하는 이름으로 새 작업 영역을 만듭니다.
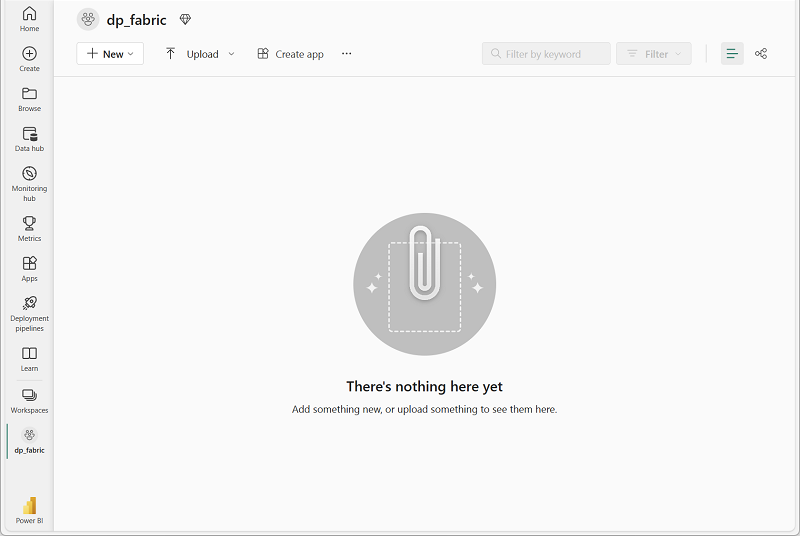
-
새 작업 영역이 열리면 비어 있어야 합니다.
Eventhouse 만들기
이제 Fabric 용량을 지원하는 작업 영역이 있으므로 Eventhouse를 만들 수 있습니다.
-
실시간 인텔리전스 홈페이지에서 선택한 이름으로 새 Eventhouse를 만듭니다. 이벤트 하우스가 만들어지면 이벤트 하우스 페이지가 표시될 때까지 표시되는 프롬프트 또는 팁을 닫습니다.
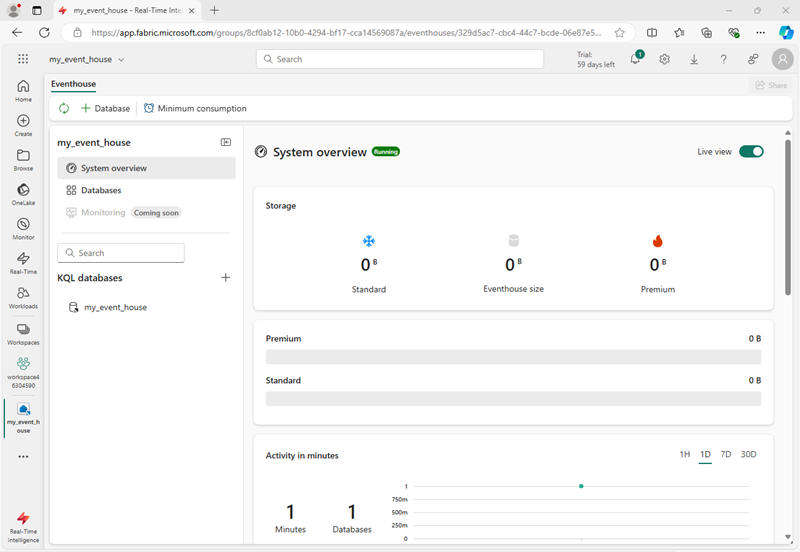
- 왼쪽 창에서 이벤트 하우스에는 이벤트 하우스와 이름이 같은 KQL 데이터베이스가 포함되어 있습니다.
-
KQL 데이터베이스를 선택하여 확인합니다.
현재 데이터베이스에는 테이블이 없습니다. 이 연습의 나머지 부분에서는 Eventstream을 사용하여 실시간 원본에서 테이블로 데이터를 로드합니다.
-
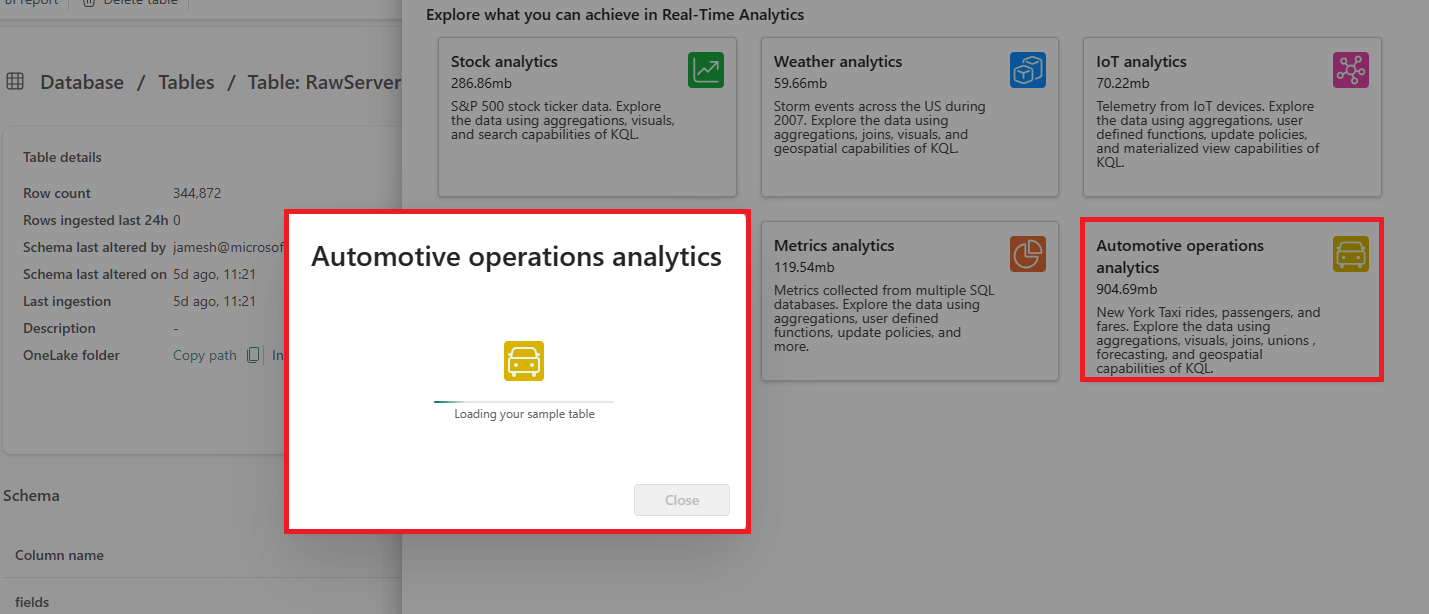
KQL 데이터베이스 페이지에서 데이터 가져오기 > 샘플을 선택합니다. 그런 다음 Automotive operations analytics 샘플 데이터를 선택합니다.
-
데이터 로드가 완료된 후(다소 시간이 걸릴 수 있음) Automotive 테이블이 생성되었는지 확인합니다.
KQL을 사용하여 데이터 쿼리하기
KQL(Kusto 쿼리 언어)은 KQL 데이터베이스를 쿼리하는 데 사용할 수 있는 직관적이고 포괄적인 언어입니다.
KQL로 테이블에서 데이터 검색하기
- 이벤트 하우스 창의 왼쪽 창에서 KQL 데이터베이스 아래에서 기본 쿼리 세트 파일을 선택합니다. 이 파일에는 시작하기 위한 몇 가지 샘플 KQL 쿼리가 포함되어 있습니다.
-
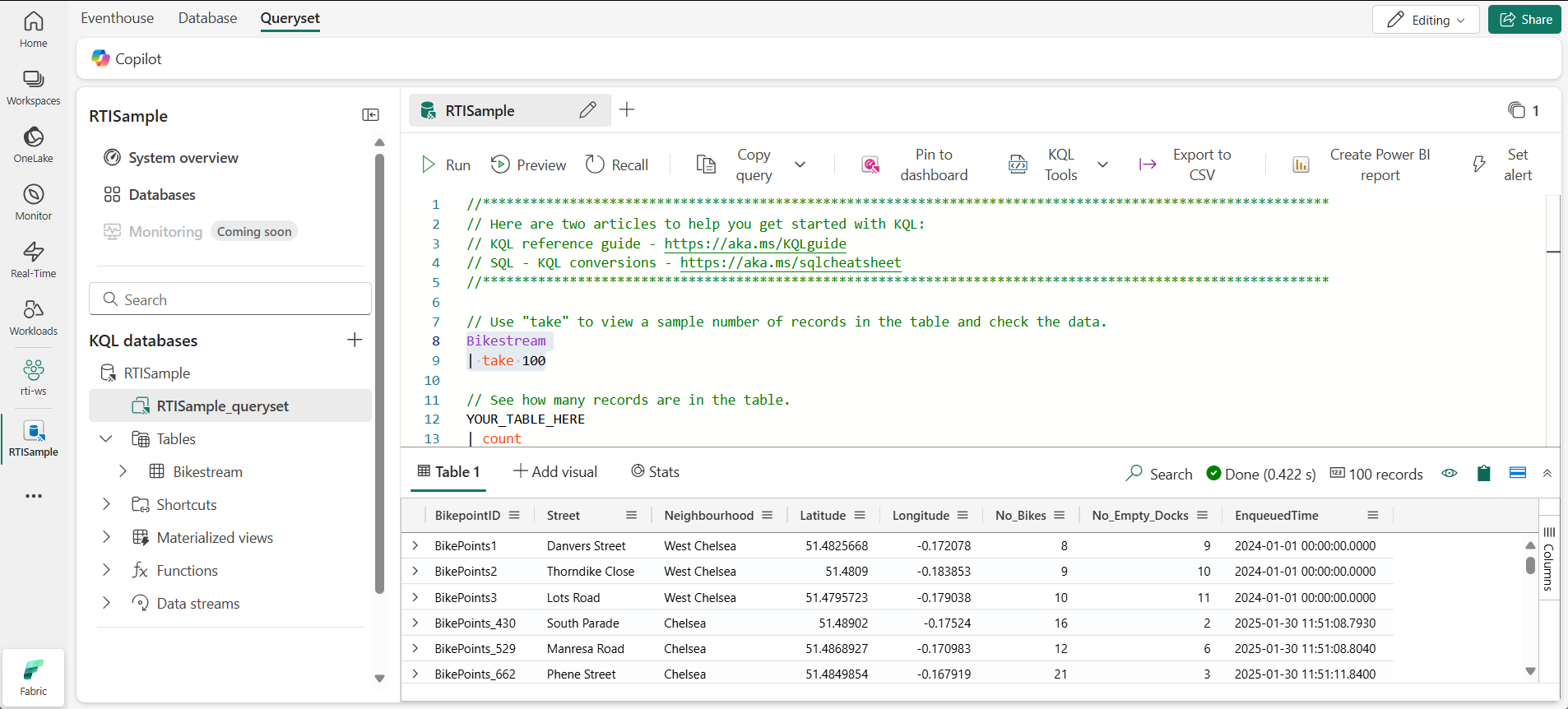
다음과 같이 첫 번째 예제 쿼리를 수정합니다.
Automotive | take 100참고: 파이프 ( ) 문자는 KQL에서 두 가지 목적으로 사용되며, 그 중 하나는 테이블 표현식 문에서 쿼리 연산자를 구분하는 것입니다. 또한 파이프 문자로 구분된 항목 중 하나를 지정할 수 있음을 나타내기 위해 대괄호 또는 둥근 괄호 안에 논리적 OR 연산자로 사용됩니다. -
쿼리 코드를 선택하고 실행하여 테이블에서 100개의 행을 반환합니다.
project키워드를 사용하여 쿼리하려는 특정 특성을 추가한 다음take키워드를 사용하여 반환할 레코드 수를 엔진에 알려 주면 더 정확해질 수 있습니다. -
다음 쿼리를 입력하고 선택한 후 실행합니다.
// Use 'project' and 'take' to view a sample number of records in the table and check the data. Automotive | project vendor_id, trip_distance | take 10참고: //는 주석을 나타냅니다.
분석의 또 다른 일반적인 방법은 쿼리 세트의 열 이름을 사용자에게 친숙하도록 바꾸는 것입니다.
-
다음 쿼리를 시도해 봅니다.
Automotive | project vendor_id, ["Trip Distance"] = trip_distance | take 10
KQL을 사용하여 데이터 요약하기
summarize 키워드를 함수와 함께 사용하여 데이터를 집계하거나 조작할 수 있습니다.
-
sum 함수를 사용하여 여 데이터를 요약하여 총 이동한 마일 수를 확인하는 다음 쿼리를 시도합니다.
Automotive | summarize ["Total Trip Distance"] = sum(trip_distance)요약된 데이터를 지정된 열 또는 식을 기준으로 그룹화할 수 있습니다.
-
다음 쿼리를 실행하여 뉴욕 택시 시스템 내에서 이동 거리를 자치구별로 그룹화하여 각 자치구에서 이동한 총 거리를 확인합니다.
Automotive | summarize ["Total Trip Distance"] = sum(trip_distance) by pickup_boroname | project Borough = pickup_boroname, ["Total Trip Distance"]결과에는 분석에 적합하지 않은 빈 값이 포함됩니다.
-
여기에 표시된 대로 쿼리를 수정하여 case 함수를 isempty 및 isnull 함수와 함께 사용하여 자치구를 알 수 없는 모든 여행을 후속 작업을 위해 Unidentified 범주로 그룹화합니다.
Automotive | summarize ["Total Trip Distance"] = sum(trip_distance) by pickup_boroname | project Borough = case(isempty(pickup_boroname) or isnull(pickup_boroname), "Unidentified", pickup_boroname), ["Total Trip Distance"]
KQL을 사용하여 데이터 정렬
데이터를 더 잘 이해하기 위해 일반적으로 열을 기준으로 데이터를 정렬합니다. 이 프로세스는 KQL에서 sort by *또는 *order by 연산자를 사용하여 수행되며 이 둘은 동일한 방식으로 작동합니다.
-
다음 쿼리를 시도해 봅니다.
Automotive | summarize ["Total Trip Distance"] = sum(trip_distance) by pickup_boroname | project Borough = case(isempty(pickup_boroname) or isnull(pickup_boroname), "Unidentified", pickup_boroname), ["Total Trip Distance"] | sort by Borough asc -
쿼리를 다음과 같이 수정하고 다시 실행합니다. order by 연산자가 sort by와 동일하게 작동한다는 점에 유의합니다.
Automotive | summarize ["Total Trip Distance"] = sum(trip_distance) by pickup_boroname | project Borough = case(isempty(pickup_boroname) or isnull(pickup_boroname), "Unidentified", pickup_boroname), ["Total Trip Distance"] | order by Borough asc
KQL을 사용하여 데이터 필터링
KQL 에서 where 절은 데이터를 필터링하는 데 사용됩니다. where 절에서는 and와 or 논리 연산자를 사용하여 조건을 결합할 수 있습니다.
-
다음 쿼리를 실행하여 Manhatten에서 시작된 여행만 포함하도록 여행 데이터를 필터링합니다.
Automotive | where pickup_boroname == "Manhattan" | summarize ["Total Trip Distance"] = sum(trip_distance) by pickup_boroname | project Borough = case(isempty(pickup_boroname) or isnull(pickup_boroname), "Unidentified", pickup_boroname), ["Total Trip Distance"] | sort by Borough asc
Transact-SQL을 사용하여 데이터 쿼리
KQL 데이터베이스는 기본적으로 Transact-SQL을 지원하지 않지만, Microsoft SQL Server를 에뮬레이트하고 데이터에 대해 T-SQL 쿼리를 실행할 수 있도록 하는 T-SQL 엔드포인트를 제공합니다. 그러나 T-SQL 엔드포인트에는 네이티브 SQL Server에 비해 몇 가지 제한 사항 및 차이점이 있습니다. 예를 들어, 테이블 만들기, 변경, 삭제 또는 데이터 삽입, 업데이트, 삭제를 지원하지 않습니다. 또한 KQL과 호환되지 않는 일부 T-SQL 함수 및 구문을 지원하지 않습니다. KQL을 지원하지 않는 시스템에서 T-SQL을 사용하여 KQL 데이터베이스 내의 데이터를 쿼리할 수 있도록 만들어졌습니다. 따라서 KQL 데이터베이스의 기본 쿼리 언어로 KQL을 사용하는 것이 좋습니다. KQL은 T-SQL보다 더 많은 기능과 성능을 제공하기 때문입니다. count, sum, avg, min, max 등과 같이 KQL에서 지원하는 일부 SQL 함수를 사용할 수도 있습니다.
Transact-SQL을 사용하여 테이블에서 데이터 검색
-
쿼리 세트에서 다음 Transact-SQL 쿼리를 추가하고 실행합니다.
SELECT TOP 100 * from Automotive -
쿼리를 다음과 같이 수정하여 특정 열을 검색합니다.
SELECT TOP 10 vendor_id, trip_distance FROM Automotive -
trip_distance 이름을 더 친숙한 이름으로 바꾸는 별칭을 할당하도록 쿼리를 수정합니다.
SELECT TOP 10 vendor_id, trip_distance as [Trip Distance] from Automotive
Transact-SQL을 사용하여 데이터 요약
-
다음 쿼리를 실행하여 이동한 총 거리를 찾습니다.
SELECT sum(trip_distance) AS [Total Trip Distance] FROM Automotive -
총 거리를 픽업 자치구별로 그룹화하도록 쿼리를 수정합니다.
SELECT pickup_boroname AS Borough, Sum(trip_distance) AS [Total Trip Distance] FROM Automotive GROUP BY pickup_boroname -
CASE 문을 사용하여 쿼리를 추가로 수정하여 후속 작업을 위해 출발지를 알 수 없는 여행을 Unidentified 범주로 그룹화합니다.
SELECT CASE WHEN pickup_boroname IS NULL OR pickup_boroname = '' THEN 'Unidentified' ELSE pickup_boroname END AS Borough, SUM(trip_distance) AS [Total Trip Distance] FROM Automotive GROUP BY CASE WHEN pickup_boroname IS NULL OR pickup_boroname = '' THEN 'Unidentified' ELSE pickup_boroname END;
Transact-SQL을 사용하여 데이터 정렬
-
다음 쿼리를 실행하여 자치구별로 그룹화된 결과를 정렬합니다.
SELECT CASE WHEN pickup_boroname IS NULL OR pickup_boroname = '' THEN 'unidentified' ELSE pickup_boroname END AS Borough, SUM(trip_distance) AS [Total Trip Distance] FROM Automotive GROUP BY CASE WHEN pickup_boroname IS NULL OR pickup_boroname = '' THEN 'unidentified' ELSE pickup_boroname END ORDER BY Borough ASC;
Transact-SQL을 사용하여 데이터 필터링
-
다음 쿼리를 실행하여 자치구가 “Manhattan” 자치구가 있는 행만 결과에 포함되도록 그룹화된 데이터를 필터링합니다.
SELECT CASE WHEN pickup_boroname IS NULL OR pickup_boroname = '' THEN 'unidentified' ELSE pickup_boroname END AS Borough, SUM(trip_distance) AS [Total Trip Distance] FROM Automotive GROUP BY CASE WHEN pickup_boroname IS NULL OR pickup_boroname = '' THEN 'unidentified' ELSE pickup_boroname END HAVING Borough = 'Manhattan' ORDER BY Borough ASC;
리소스 정리
이 연습에서는 이벤트 하우스를 만들고 KQL 및 SQL을 사용하여 데이터를 쿼리했습니다.
KQL 데이터베이스 탐색을 마쳤으면 이 연습을 위해 만든 작업 영역을 삭제할 수 있습니다.
- 왼쪽 막대에서 작업 영역의 아이콘을 선택합니다.
- 도구 모음에서 작업 영역 설정을 선택합니다.
- 일반 섹션에서 이 작업 영역 제거를 선택합니다.