T-SQL을 사용하여 웨어하우스에 데이터 로드
Microsoft Fabric에서 데이터 웨어하우스는 대규모 분석을 위한 관계형 데이터베이스를 제공합니다. 레이크하우스에 정의된 테이블에 대한 기본 읽기 전용 SQL 엔드포인트와 달리 데이터 웨어하우스는 전체 SQL 의미 체계를 제공합니다. 여기에 테이블에 데이터를 삽입, 업데이트 및 삭제하는 기능이 포함됩니다.
이 랩을 완료하는 데 약 30분이 걸립니다.
참고: 이 연습을 완료하려면 Microsoft Fabric 평가판이 필요합니다.
작업 영역 만들기
패브릭에서 데이터를 사용하기 전에 패브릭 평가판을 사용하도록 설정된 작업 영역을 만듭니다.
- 브라우저에서 Microsoft Fabric 홈페이지(
https://app.fabric.microsoft.com/home?experience=fabric)로 이동하고 Fabric 자격 증명을 사용해 로그인합니다. - 왼쪽 메뉴 모음에서 작업 영역을 선택합니다(아이콘은 와 유사함).
- Fabric 용량이 포함된 라이선스 모드(평가판, 프리미엄 또는 Fabric)를 선택하여 원하는 이름으로 새 작업 영역을 만듭니다.
-
새 작업 영역이 열리면 비어 있어야 합니다.
레이크하우스 만들기 및 파일 업로드
시나리오에서는 사용 가능한 데이터가 없으므로 웨어하우스를 로드하는 데 사용할 데이터를 수집해야 합니다. 웨어하우스를 로드하는 데 사용할 데이터 파일에 대한 데이터 레이크하우스를 만듭니다.
-
+ 새 항목을 선택하고 선택한 이름으로 새 레이크하우스를 만듭니다.
1분 정도 지나면 빈 레이크하우스가 새로 만들어집니다. 분석을 위해 일부 데이터를 데이터 레이크하우스에 수집해야 합니다. 이를 수행하는 방법은 여러 가지가 있지만 이 연습에서는 CSV 파일을 로컬 컴퓨터(또는 해당하는 경우 랩 VM)에 다운로드한 다음 이를 레이크하우스에 업로드합니다.
-
https://github.com/MicrosoftLearning/dp-data/raw/main/sales.csv에서 이 연습용 파일을 다운로드합니다. -
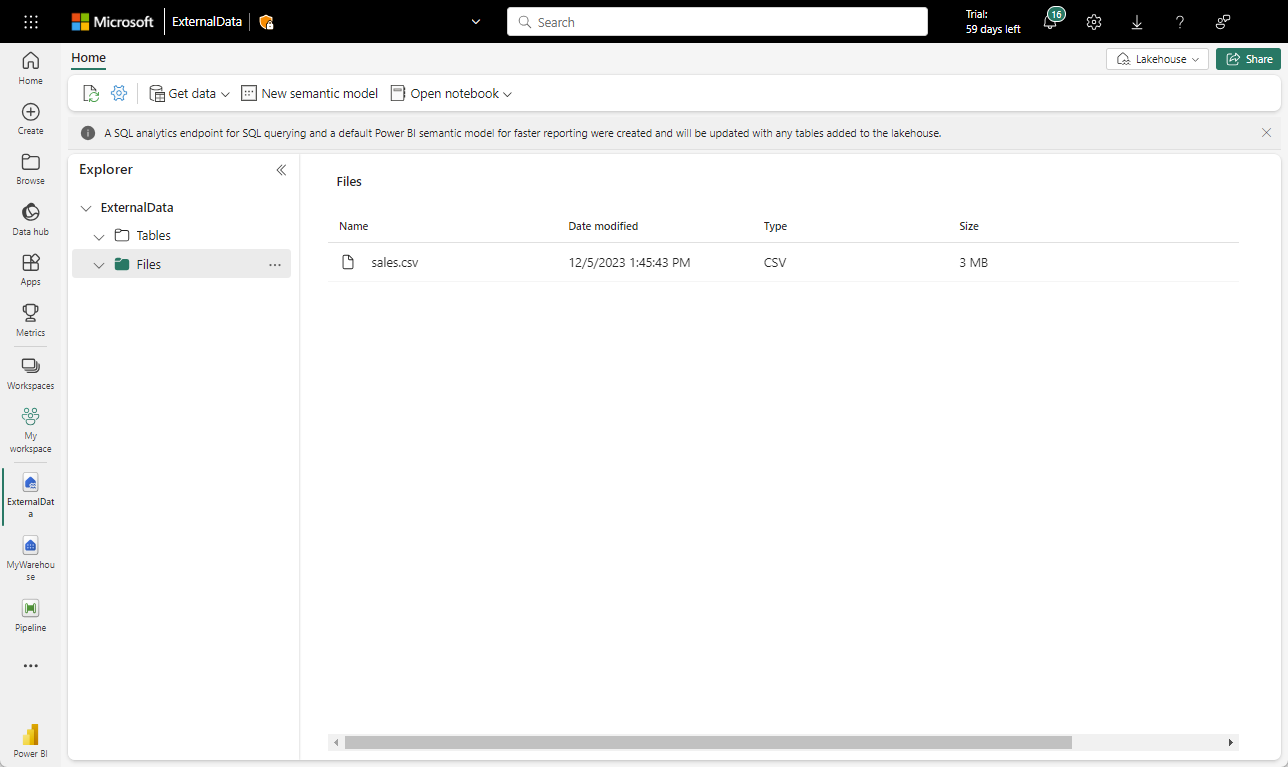
레이크하우스가 포함된 웹 브라우저 탭으로 돌아가서 탐색기 창에 있는 파일 폴더의 … 메뉴에서 업로드 및 파일 업로드를 선택한 다음 로컬 컴퓨터(또는 해당하는 경우 랩 VM)에서 sales.csv 파일을 레이크하우스에 업로드합니다.
-
파일이 업로드된 후 파일을 선택합니다. 다음과 같이 CSV 파일이 업로드되었는지 확인합니다.
레이크하우스에 테이블 만들기
-
탐색기 창에 있는 sales.csv 파일의 … 메뉴에서 테이블에 로드를 선택한 다음 새 테이블을 선택합니다.
-
새 테이블에 파일 로드 대화 상자에 다음 정보를 제공합니다.
- 새 테이블 이름: stage_sales
- 열 이름에 헤더 사용: 선택됨
- 구분 기호: ,
- 로드를 선택합니다.
창고 만들기
이제 필요한 데이터가 포함된 작업 영역, 레이크하우스, 판매 테이블이 있으므로 데이터 웨어하우스를 만들 차례입니다.
-
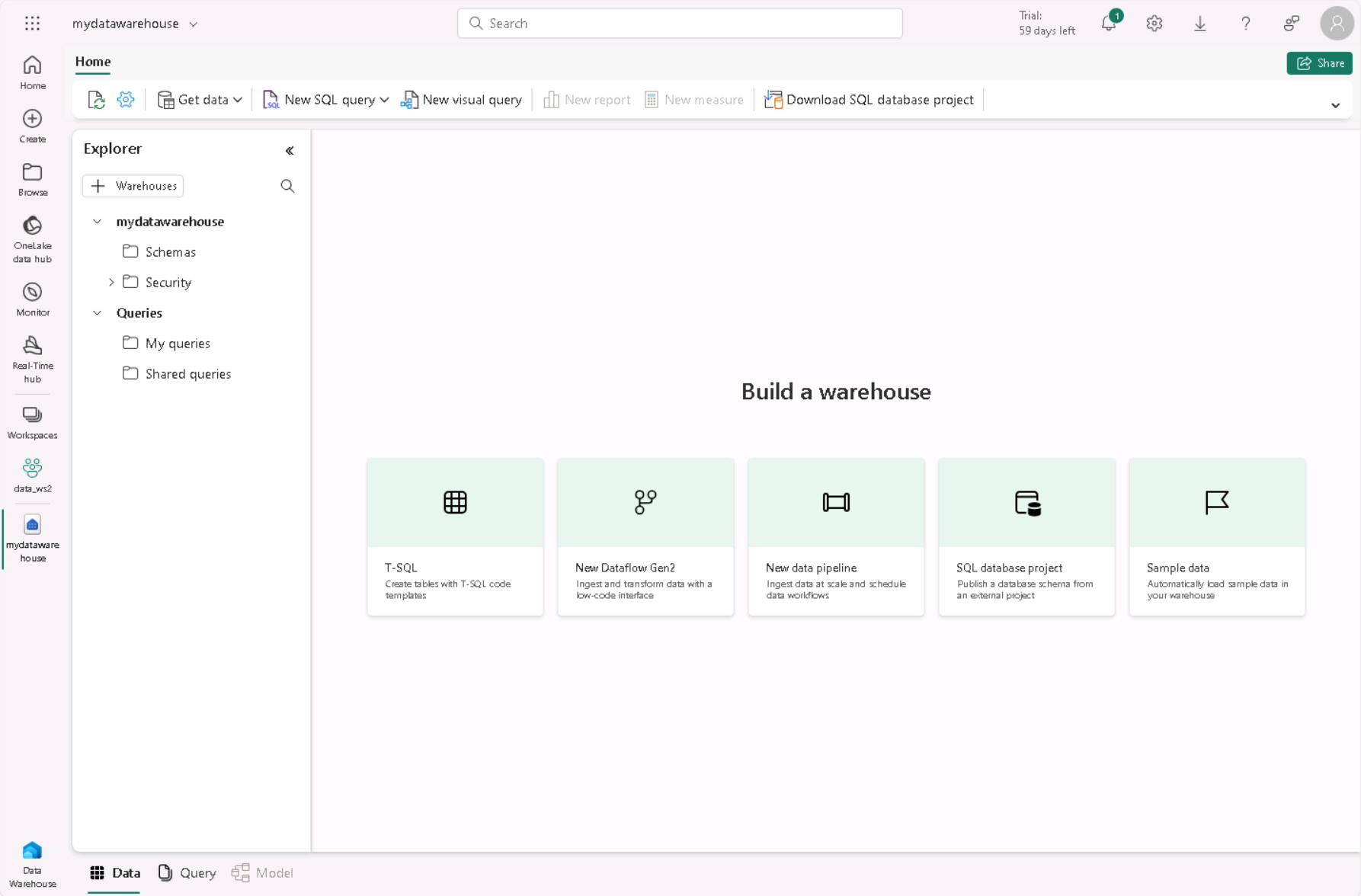
왼쪽 메뉴 모음에서 만들기를 선택합니다. 새 페이지의 데이터 웨어하우스 섹션에서 웨어하우스를 선택합니다. 원하는 고유한 이름.
참고: 만들기 옵션이 사이드바에 고정되지 않은 경우 먼저 줄임표(…) 옵션을 선택해야 합니다.
1분 정도 지나면 새 웨어하우스가 만들어집니다.
팩트 테이블, 차원 및 뷰 만들기
판매 데이터에 대한 팩트 테이블과 차원을 만들어 보겠습니다. 또한 레이크하우스를 가리키는 뷰를 만들 것입니다. 이는 로드하는 데 사용할 저장 프로시저의 코드를 간소화합니다.
-
작업 영역에서 만든 웨어하우스를 선택합니다.
-
웨어하우스 도구 모음 에서 새 SQL 쿼리를 선택한 후 다음 쿼리를 복사하여 실행합니다.
CREATE SCHEMA [Sales] GO IF OBJECT_ID('Sales.Fact_Sales', 'U') IS NULL CREATE TABLE Sales.Fact_Sales ( CustomerID VARCHAR(255) NOT NULL, ItemID VARCHAR(255) NOT NULL, SalesOrderNumber VARCHAR(30), SalesOrderLineNumber INT, OrderDate DATE, Quantity INT, TaxAmount FLOAT, UnitPrice FLOAT ); IF OBJECT_ID('Sales.Dim_Customer', 'U') IS NULL CREATE TABLE Sales.Dim_Customer ( CustomerID VARCHAR(255) NOT NULL, CustomerName VARCHAR(255) NOT NULL, EmailAddress VARCHAR(255) NOT NULL ); ALTER TABLE Sales.Dim_Customer add CONSTRAINT PK_Dim_Customer PRIMARY KEY NONCLUSTERED (CustomerID) NOT ENFORCED GO IF OBJECT_ID('Sales.Dim_Item', 'U') IS NULL CREATE TABLE Sales.Dim_Item ( ItemID VARCHAR(255) NOT NULL, ItemName VARCHAR(255) NOT NULL ); ALTER TABLE Sales.Dim_Item add CONSTRAINT PK_Dim_Item PRIMARY KEY NONCLUSTERED (ItemID) NOT ENFORCED GO중요: 데이터 웨어하우스에서는 테이블 수준에서 외래 키 제약 조건이 항상 필요한 것은 아닙니다. 외래 키 제약 조건은 데이터 무결성을 보장하는 데 도움이 될 수 있지만 ETL(추출, 변환, 로드) 프로세스에 오버헤드를 추가하고 데이터 로드 속도를 늦출 수도 있습니다. 데이터 웨어하우스에서 외래 키 제약 조건을 사용하기로 결정하려면 데이터 무결성과 성능 간의 균형을 신중하게 고려해야 합니다.
-
탐색기에서 스키마 » 판매 » 테이블로 이동합니다. 방금 만든 Fact_Sales, Dim_Customer 및 Dim_Item 테이블을 확인합니다.
참고: 새 스키마가 표시되지 않으면 Explorer 창에서 테이블의 … 메뉴를 연 다음 새로 고침을 선택합니다.
-
새로운 새 SQL 쿼리 편집기를 열고 다음 쿼리를 복사하여 실행합니다. 만든 레이크하우스로 *
* 을 업데이트합니다. CREATE VIEW Sales.Staging_Sales AS SELECT * FROM [<your lakehouse name>].[dbo].[staging_sales]; -
탐색기에서 스키마 » 판매 » 보기로 이동합니다. 만든 Staging_Sales 뷰를 확인합니다.
웨어하우스에 데이터 로드
이제 팩트 테이블과 차원 테이블이 만들어졌으므로 레이크하우스의 데이터를 웨어하우스로 로드하는 저장 프로시저를 만들어 보겠습니다. 레이크하우스를 만들 때 자동 SQL 엔드포인트가 만들어지므로 T-SQL 및 데이터베이스 간 쿼리를 사용하여 웨어하우스에서 레이크하우스의 데이터에 직접 액세스할 수 있습니다.
이 사례 연구에서는 단순화를 위해 고객 이름과 항목 이름을 기본 키로 사용합니다.
-
새로운 새 SQL 쿼리 편집기를 만든 후 다음 쿼리를 복사하여 실행합니다.
CREATE OR ALTER PROCEDURE Sales.LoadDataFromStaging (@OrderYear INT) AS BEGIN -- Load data into the Customer dimension table INSERT INTO Sales.Dim_Customer (CustomerID, CustomerName, EmailAddress) SELECT DISTINCT CustomerName, CustomerName, EmailAddress FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear AND NOT EXISTS ( SELECT 1 FROM Sales.Dim_Customer WHERE Sales.Dim_Customer.CustomerName = Sales.Staging_Sales.CustomerName AND Sales.Dim_Customer.EmailAddress = Sales.Staging_Sales.EmailAddress ); -- Load data into the Item dimension table INSERT INTO Sales.Dim_Item (ItemID, ItemName) SELECT DISTINCT Item, Item FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear AND NOT EXISTS ( SELECT 1 FROM Sales.Dim_Item WHERE Sales.Dim_Item.ItemName = Sales.Staging_Sales.Item ); -- Load data into the Sales fact table INSERT INTO Sales.Fact_Sales (CustomerID, ItemID, SalesOrderNumber, SalesOrderLineNumber, OrderDate, Quantity, TaxAmount, UnitPrice) SELECT CustomerName, Item, SalesOrderNumber, CAST(SalesOrderLineNumber AS INT), CAST(OrderDate AS DATE), CAST(Quantity AS INT), CAST(TaxAmount AS FLOAT), CAST(UnitPrice AS FLOAT) FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear; END -
새로운 새 SQL 쿼리 편집기를 만든 후 다음 쿼리를 복사하여 실행합니다.
EXEC Sales.LoadDataFromStaging 2021참고: 이 경우에는 2021년의 데이터만 로드하고 있습니다. 그러나 이전 연도의 데이터를 로드하도록 수정할 수 있는 옵션이 있습니다.
분석 쿼리 실행
웨어하우스에 있는 데이터의 유효성을 검사하기 위해 몇 가지 분석 쿼리를 실행해 보겠습니다.
-
상단 메뉴에서 새 SQL 쿼리를 선택한 후 다음 쿼리를 복사하여 실행합니다.
SELECT c.CustomerName, SUM(s.UnitPrice * s.Quantity) AS TotalSales FROM Sales.Fact_Sales s JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID WHERE YEAR(s.OrderDate) = 2021 GROUP BY c.CustomerName ORDER BY TotalSales DESC;참고: 이 쿼리는 2021년의 총 판매를 기준으로 고객을 보여 줍니다. 지정된 연도에 총 판매가 가장 높은 고객은 Jordan Turner이며 총 판매는 14686.69입니다.
-
상단 메뉴에서 새 SQL 쿼리를 선택하거나 동일한 편집기를 재사용한 후 다음 쿼리를 복사하여 실행합니다.
SELECT i.ItemName, SUM(s.UnitPrice * s.Quantity) AS TotalSales FROM Sales.Fact_Sales s JOIN Sales.Dim_Item i ON s.ItemID = i.ItemID WHERE YEAR(s.OrderDate) = 2021 GROUP BY i.ItemName ORDER BY TotalSales DESC;참고: 이 쿼리는 2021년 총 판매 기준으로 가장 많이 팔린 항목을 표시합니다. 이러한 결과는 검은색과 은색의 Mountain-200 bike 모델이 2021년 고객 사이에서 가장 자주 사용되는 항목임을 시사합니다.
-
상단 메뉴에서 새 SQL 쿼리를 선택하거나 동일한 편집기를 재사용한 후 다음 쿼리를 복사하여 실행합니다.
WITH CategorizedSales AS ( SELECT CASE WHEN i.ItemName LIKE '%Helmet%' THEN 'Helmet' WHEN i.ItemName LIKE '%Bike%' THEN 'Bike' WHEN i.ItemName LIKE '%Gloves%' THEN 'Gloves' ELSE 'Other' END AS Category, c.CustomerName, s.UnitPrice * s.Quantity AS Sales FROM Sales.Fact_Sales s JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID JOIN Sales.Dim_Item i ON s.ItemID = i.ItemID WHERE YEAR(s.OrderDate) = 2021 ), RankedSales AS ( SELECT Category, CustomerName, SUM(Sales) AS TotalSales, ROW_NUMBER() OVER (PARTITION BY Category ORDER BY SUM(Sales) DESC) AS SalesRank FROM CategorizedSales WHERE Category IN ('Helmet', 'Bike', 'Gloves') GROUP BY Category, CustomerName ) SELECT Category, CustomerName, TotalSales FROM RankedSales WHERE SalesRank = 1 ORDER BY TotalSales DESC;참고: 이 쿼리의 결과는 각 범주의 상위 고객을 보여 줍니다. 자전거, 헬멧, 장갑 총 판매 기준. 예를 들어, Joan Coleman이 장갑 범주의 최고 고객입니다.
차원 테이블에는 별도의 범주 열이 없으므로 문자열 조작을 사용하여
ItemName열에서 범주 정보를 추출했습니다. 이 방식에서는 항목 이름이 일관된 명명 규칙을 따른다고 가정합니다. 항목 이름이 일관된 명명 규칙을 따르지 않으면 결과에 각 항목의 실제 범주가 정확하게 반영되지 않을 수 있습니다.
이 연습에서는 여러 테이블이 있는 레이크하우스와 데이터 웨어하우스를 만들었습니다. 데이터를 수집하고 데이터베이스 간 쿼리를 사용하여 레이크하우스에서 웨어하우스로 데이터를 로드했습니다. 또한 쿼리 도구를 사용하여 분석 쿼리를 수행했습니다.
리소스 정리
데이터 웨어하우스 탐색을 마쳤으면 이 연습을 위해 만든 작업 영역을 삭제할 수 있습니다.
- 왼쪽 막대에서 작업 영역의 아이콘을 선택하여 포함된 모든 항목을 봅니다.
- 작업 영역 설정을 선택하고 일반 섹션에서 아래로 스크롤하여 이 작업 영역 제거를 선택합니다.
- 삭제를 선택하여 작업 영역을 삭제합니다.