Microsoft Fabric의 파이프라인을 사용하여 데이터 수집
데이터 레이크하우스는 클라우드 규모 분석 솔루션을 위한 일반적인 분석 데이터 저장소입니다. 데이터 엔지니어의 핵심 작업 중 하나는 여러 작동 데이터 원본의 데이터를 레이크하우스로 수집하는 작업을 구현하고 관리하는 것입니다. Microsoft Fabric에서는 파이프라인 만들기를 통한 데이터 수집을 위해 ETL(추출, 변환 및 로드) 또는 ELT(추출, 로드 및 변환) 솔루션을 구현할 수 있습니다.
Fabric은 또한 Apache Spark를 지원하므로 코드를 작성하고 실행하여 대규모 데이터를 처리할 수 있습니다. Fabric에서 파이프라인과 Spark 기능을 결합하면, 외부 원본의 데이터를 레이크하우스가 기반으로 하는 OneLake 스토리지로 복사하는 복잡한 데이터 수집 논리를 구현한 다음 분석을 위해 테이블에 로드하기 전에 Spark 코드를 사용하여 사용자 지정 데이터 변환을 수행할 수 있습니다.
이 랩을 완료하는 데 약 45분이 걸립니다.
[!Note] 이 연습을 완료하려면 Microsoft Fabric 테넌트에 액세스해야 합니다.
작업 영역 만들기
패브릭에서 데이터를 사용하기 전에 패브릭 평가판을 사용하도록 설정된 작업 영역을 만듭니다.
- 브라우저에서 Microsoft Fabric 홈페이지(
https://app.fabric.microsoft.com/home?experience=fabric-developer)로 이동하고 Fabric 자격 증명을 사용해 로그인합니다. - 왼쪽 메뉴 모음에서 작업 영역을 선택합니다(아이콘은 와 유사함).
- 선택한 이름으로 새 작업 영역을 만들고 패브릭 용량(평가판, 프리미엄 또는 패브릭)이 포함된 고급 섹션에서 라이선스 모드를 선택합니다.
-
새 작업 영역이 열리면 비어 있어야 합니다.
레이크하우스 만들기
이제 작업 영역이 있으므로 데이터를 수집할 데이터 레이크하우스를 만들 차례입니다.
-
왼쪽 메뉴 모음에서 만들기를 선택합니다. 새 페이지의 데이터 엔지니어링 섹션에서 레이크하우스를 선택합니다. 원하는 고유한 이름.
참고: 만들기 옵션이 사이드바에 고정되지 않은 경우 먼저 줄임표(…) 옵션을 선택해야 합니다.
약 1분 정도 지나면 테이블 또는 파일이 없는 새 레이크하우스가 만들어집니다.
-
왼쪽의 탐색기 창에서 파일 노드의 … 메뉴로 가서 새 하위 폴더를 선택하고 new_data라는 하위 폴더를 만듭니다.
파이프라인을 만듭니다.
데이터를 수집하는 간단한 방법은 파이프라인에서 데이터 복사 작업을 사용하여 원본에서 데이터를 추출하고 레이크하우스의 파일에 복사하는 것입니다.
- 레이크하우스의 홈 페이지에서 데이터 가져오기를 선택한 다음 새 데이터 파이프라인을 선택하고 이름을
Ingest Sales Data(으)로 지정한 새 데이터 파이프라인을 만듭니다. - 데이터 복사 마법사가 자동으로 열리지 않으면 파이프라인 편집기 페이지에서 데이터 복사 > 복사 도우미 사용을 선택합니다.
-
데이터 복사 마법사의 데이터 원본 선택 페이지에서 검색창에 HTTP를 입력한 다음 새 소스 섹션에서 HTTP를 선택합니다.
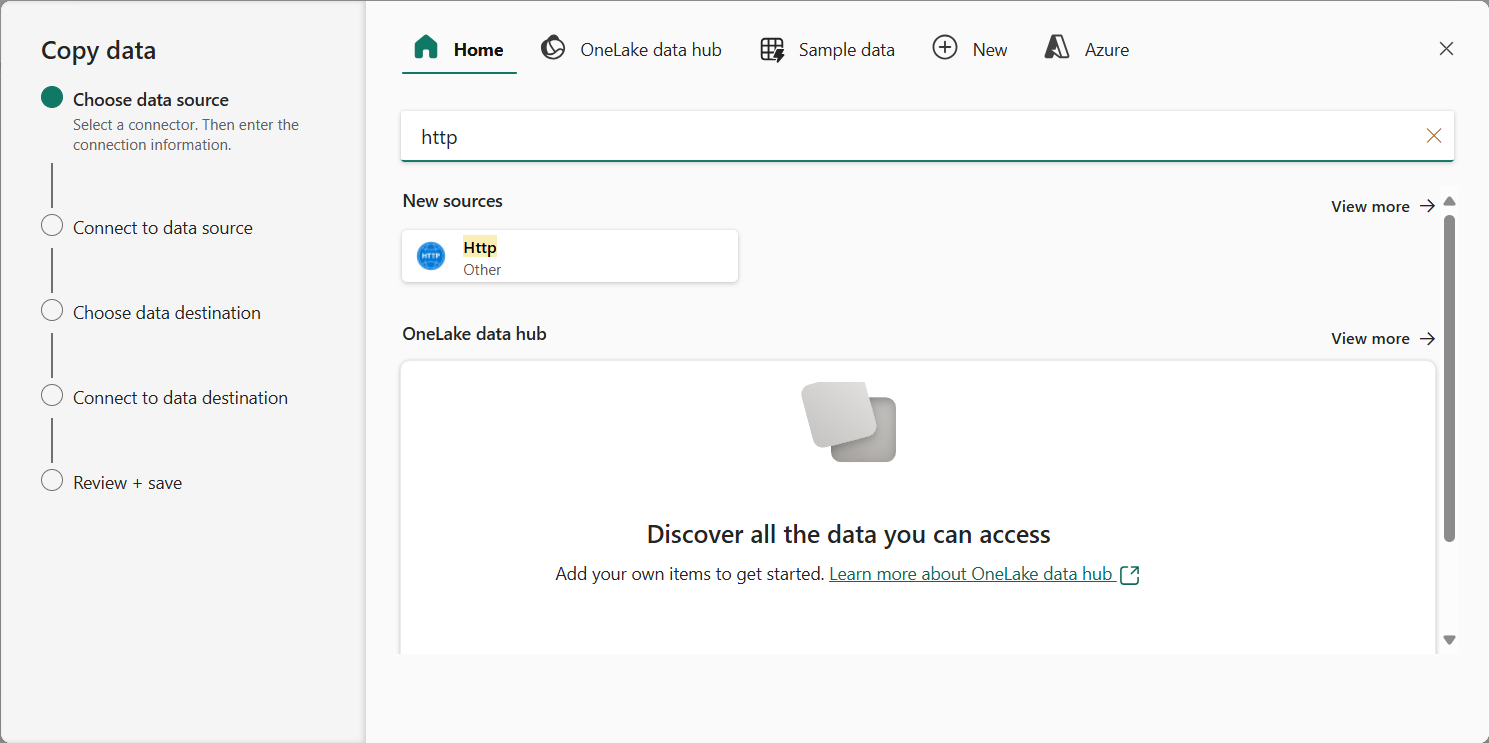
- 데이터 원본에 연결 창에서 데이터 원본 연결에 대해 다음 설정을 입력합니다.
- URL:
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv - 연결: 새 연결 만들기
- 연결 이름: 고유 이름 지정
- 데이터 게이트웨이:(없음)
- 인증 종류: 익명
- URL:
- 다음을 선택합니다. 그리고 다음 설정이 선택되어 있는지 확인합니다.
- 상대 URL: 비워 둡니다.
- 요청 메서드: GET
- 추가 헤더: 비워 둡니다.
- 이진 복사: 선택 취소
- 요청 시간 초과: 비워 둡니다.
- 최대 동시 연결 수: 비워 둡니다.
- 다음을 선택하고 데이터가 샘플링될 때까지 기다린 후 다음 설정이 선택되었는지 확인합니다.
- 파일 형식: DelimitedText
- 열 구분 기호: 쉼표(,)
- 행 구분 기호: 줄 바꿈(\n)
- 첫 번째 행을 머리글로: 선택됨
- 압축 형식: 없음
- 수집될 데이터의 샘플을 보려면 데이터 미리 보기를 선택합니다. 그런 다음 데이터 미리 보기를 닫고 다음을 선택합니다.
- 데이터 대상에 연결 페이지에서 다음 데이터 대상 옵션을 설정한 후 다음을 선택합니다.
- 루트 폴더: 파일
- 폴더 경로 이름: new_data
- 파일 이름: sales.csv
- 복사 동작: 없음
- 다음 파일 형식 옵션을 설정하고 다음을 선택합니다.
- 파일 형식: DelimitedText
- 열 구분 기호: 쉼표(,)
- 행 구분 기호: 줄 바꿈(\n)
- 파일에 헤더 추가: 선택됨
- 압축 형식: 없음
-
복사 요약 페이지에서 복사 작업의 세부 정보를 검토한 다음 저장 + 실행을 선택합니다.
다음과 같이 데이터 복사 작업이 포함된 새 파이프라인이 만들어집니다.
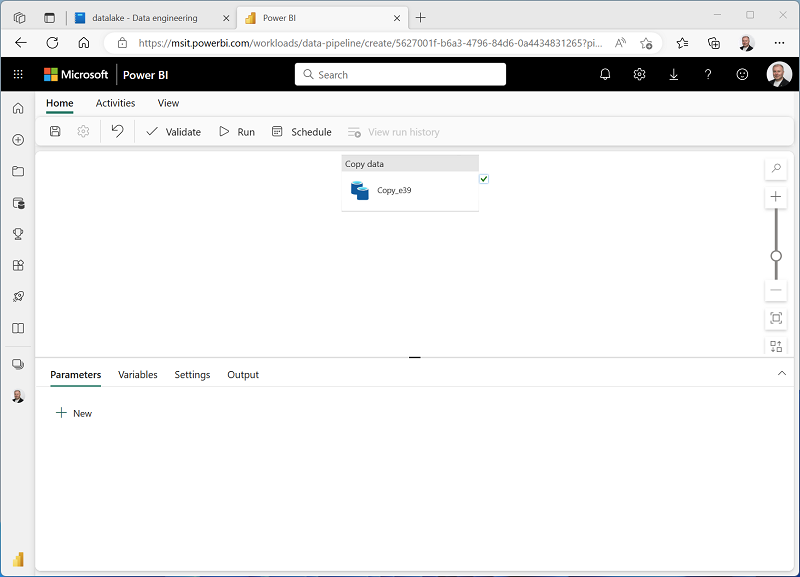
- 파이프라인 실행이 시작되면 파이프라인 디자이너 아래의 출력 창에서 해당 상태를 모니터링할 수 있습니다. ↻(새로 고침) 아이콘을 사용하여 상태를 새로 고치고, 성공할 때까지 기다립니다.
- 왼쪽 메뉴 모음에서 레이크하우스를 선택합니다.
- 홈 페이지의 탐색기 창에서 파일을 확장하고 new_data 폴더를 선택하여 sales.csv 파일이 복사되었는지 확인합니다.
Notebook 만들기
-
레이크하우스의 홈 페이지에 있는 Notebook 열기 메뉴에서 새 노트를 선택합니다.
몇 초 후에 단일 셀이 포함된 새 Notebook이 열립니다. Notebook은 코드 또는 markdown(서식이 지정된 텍스트)을 포함할 수 있는 하나 이상의 셀로 구성됩니다.
-
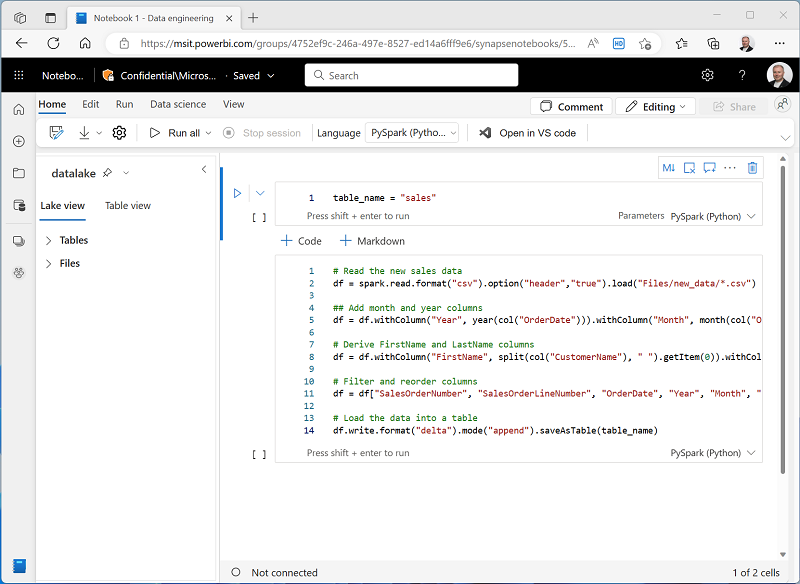
간단한 코드가 포함된 Notebook의 기존 셀을 선택한 후 기본 코드를 다음 변수 선언으로 바꿉니다.
table_name = "sales" -
셀의 … 메뉴(오른쪽 상단)에서 매개 변수 셀 전환을 선택합니다. 이는 파이프라인에서 Notebook을 실행할 때 선언된 변수가 매개 변수로 처리되도록 셀을 구성합니다.
-
매개 변수 셀 아래에서 + 코드 단추를 사용하여 새 코드 셀을 추가합니다. 그런 다음, 다음 코드를 추가합니다.
from pyspark.sql.functions import * # Read the new sales data df = spark.read.format("csv").option("header","true").load("Files/new_data/*.csv") ## Add month and year columns df = df.withColumn("Year", year(col("OrderDate"))).withColumn("Month", month(col("OrderDate"))) # Derive FirstName and LastName columns df = df.withColumn("FirstName", split(col("CustomerName"), " ").getItem(0)).withColumn("LastName", split(col("CustomerName"), " ").getItem(1)) # Filter and reorder columns df = df["SalesOrderNumber", "SalesOrderLineNumber", "OrderDate", "Year", "Month", "FirstName", "LastName", "EmailAddress", "Item", "Quantity", "UnitPrice", "TaxAmount"] # Load the data into a table df.write.format("delta").mode("append").saveAsTable(table_name)이 코드는 데이터 복사 작업으로 수집된 sales.csv 파일에서 데이터를 로드하고, 일부 변환 논리를 적용하고, 변환된 데이터를 테이블로 저장합니다. 테이블이 이미 있는 경우 데이터를 추가합니다.
-
Notebooks가 이와 유사한지 확인한 후 ▷ 포함된 모든 셀을 실행하려면 도구 모음의 모두 실행 단추를 클릭합니다.
참고: 이 세션에서 Spark 코드를 실행한 것은 이번이 처음이기 때문에 Spark 풀이 시작되어야 합니다. 이는 첫 번째 셀이 완료되는 데 1분 정도 걸릴 수 있음을 의미합니다.
- Notebook 실행이 완료되면 왼쪽의 탐색기 창에 있는 테이블에 대한 … 메뉴에서 새로 고침을 선택하고 sales 테이블이 만들어졌는지 확인합니다.
- 전자 필기장 메뉴 모음에서 ⚙️ 설정 아이콘을 사용하여 전자 필기장 설정을 봅니다. 그런 다음 Notebook의 이름을
Load Sales(으)로 설정하고 설정 창을 닫습니다. - 왼쪽의 허브 메뉴 모음에서 레이크하우스를 선택합니다.
- 탐색기 창에서 보기를 새로 고칩니다. 그런 다음 테이블을 확장하고 판매 테이블을 선택하여 포함된 데이터의 미리 보기를 확인합니다.
파이프라인 수정
이제 데이터를 변환하고 테이블에 로드하는 Notebook을 구현했으므로 Notebook을 파이프라인에 통합하여 재사용 가능한 ETL 프로세스를 만들 수 있습니다.
- 왼쪽 허브 메뉴 모음에서 이전에 만든 판매 데이터 수집 파이프라인을 선택합니다.
-
작업 탭의 모든 작업 목록에서 데이터 삭제를 선택합니다. 그런 다음 새 데이터 삭제 작업을 데이터 복사 작업 왼쪽에 배치하고 다음과 같이 완료 시 출력을 데이터 복사 작업에 연결합니다.
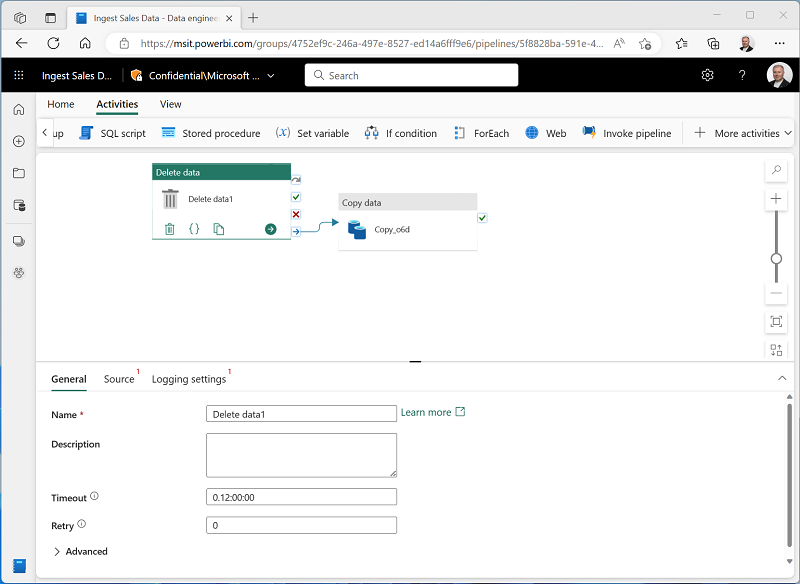
- 데이터 삭제 작업을 선택하고 디자인 캔버스 아래 창에서 다음 속성을 설정합니다.
- 일반:
- 이름:
Delete old files
- 이름:
- Source
- 연결: 레이크하우스
- 파일 경로 형식: 와일드카드 파일 경로
- 폴더 경로: 파일 / new_data
- 와일드카드 파일 이름:
*.csv - 재귀적으로: 선택
- 로깅 설정:
- 로깅 사용: 선택 안 함
이러한 설정을 사용하면 sales.csv 파일을 복사하기 전에 기존 .csv 파일이 모두 삭제됩니다.
- 일반:
- 파이프라인 디자이너의 작업 탭에서 Notebook을 선택하여 파이프라인에 Notebook 작업을 추가합니다.
-
데이터 복사 작업을 선택한 다음 여기에 표시된 대로 해당 완료 시 출력을 Notebook 작업에 연결합니다.
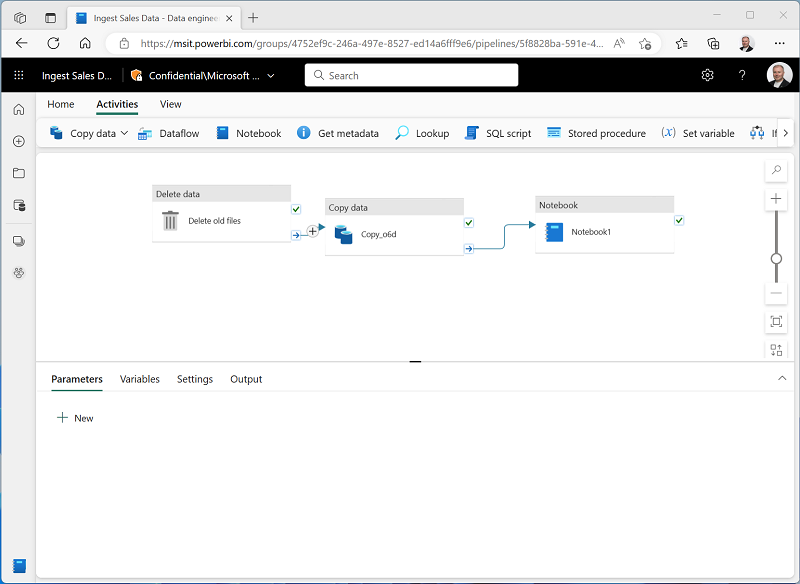
- Notebook 작업을 선택한 후 디자인 캔버스 아래 창에서 다음 속성을 설정합니다.
- 일반:
- 이름:
Load Sales notebook
- 이름:
- 설정:
- Notebook: 판매 로드
-
기본 매개 변수: 다음 속성을 가진 새 매개 변수를 추가합니다.
속성 형식 값 table_name String new_sales
table_name 매개 변수는 Notebook에 전달되며 매개 변수 셀의 table_name 변수에 할당된 기본값을 재정의합니다.
- 일반:
-
홈 탭에서 🖫(저장) 아이콘을 사용하여 파이프라인을 저장합니다. 그런 다음 ▷ 실행 단추를 눌러 파이프라인을 실행하고 모든 작업이 완료될 때까지 기다립니다.
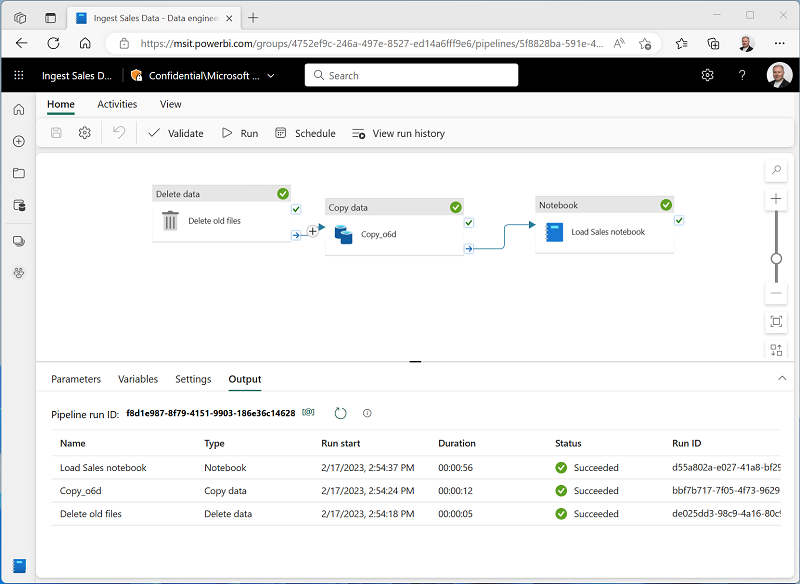
참고: 오류 메시지가 표시되는 경우 Spark SQL 쿼리는 레이크하우스 컨텍스트에서만 가능합니다. 계속하려면 레이크하우스를 연결하세요.: Notebook을 열고 왼쪽 창에서 만든 레이크하우스를 선택한 다음 모든 레이크하우스 제거를 선택한 다음 다시 추가합니다. 파이프라인 디자이너로 돌아가서 ▷ 실행을 선택합니다.
- 포털 왼쪽 가장자리에 있는 허브 메뉴 모음에서 레이크하우스를 선택합니다.
- 탐색기 창에서 테이블을 확장하고 new_sales 테이블을 선택하여 포함된 데이터의 미리 보기를 확인합니다. 이 테이블은 파이프라인에서 실행될 때 Notebook에 의해 만들어졌습니다.
이 연습에서는 파이프라인을 사용하여 외부 원본에서 레이크하우스로 데이터를 복사한 다음 Spark Notebook을 사용하여 데이터를 변환하고 테이블에 로드하는 데이터 수집 솔루션을 구현했습니다.
리소스 정리
이 연습에서는 Microsoft Fabric에서 파이프라인을 구현하는 방법을 알아보았습니다.
레이크하우스 탐색을 마쳤으면 이 연습을 위해 만든 작업 영역을 삭제할 수 있습니다.
- 왼쪽 막대에서 작업 영역의 아이콘을 선택하여 포함된 모든 항목을 봅니다.
- 작업 영역 설정을 선택하고 일반 섹션에서 아래로 스크롤하여 이 작업 영역 제거를 선택합니다.
- 삭제를 선택하여 작업 영역을 삭제합니다.