Spark と Microsoft Fabric ノートブックを使用してデータを取り込む
このラボでは、Microsoft Fabric ノートブックを作成し、PySpark を使用して Azure Blob Storage パスに接続し、書き込み最適化を使用してレイクハウスにデータを読み込みます。
このラボは完了するまで、約 30 分かかります。
このエクスペリエンスでは、複数のノートブックのコード セルにわたってコードをビルドします。これは、お使いの環境内での方法を反映したものではないかもしれませんが、デバッグに役立つ可能性があります。
サンプル データセットを使用していることもあり、この最適化は大規模な運用環境で目にする可能性があるものを反映したものではありません。しかし、改善が確認できることに違いはなく、ミリ秒が重要となる場面では、最適化が鍵となります。
注:この演習を完了するには、 Microsoft Fabric 試用版が必要です。
ワークスペースの作成
Fabric でデータを操作する前に、Fabric 試用版を有効にしてワークスペースを作成してください。
- ブラウザーで Microsoft Fabric ホーム ページ (
https://app.fabric.microsoft.com/home?experience=fabric) に移動し、Fabric 資格情報でサインインします。 - 左側のメニュー バーで、 [ワークスペース] を選択します (アイコンは 🗇 に似ています)。
- 任意の名前で新しいワークスペースを作成し、Fabric 容量を含むライセンス モード (“試用版”、Premium、または Fabric) を選択します。**
-
開いた新しいワークスペースは空のはずです。
ワークスペースとレイクハウスの宛先を作成する
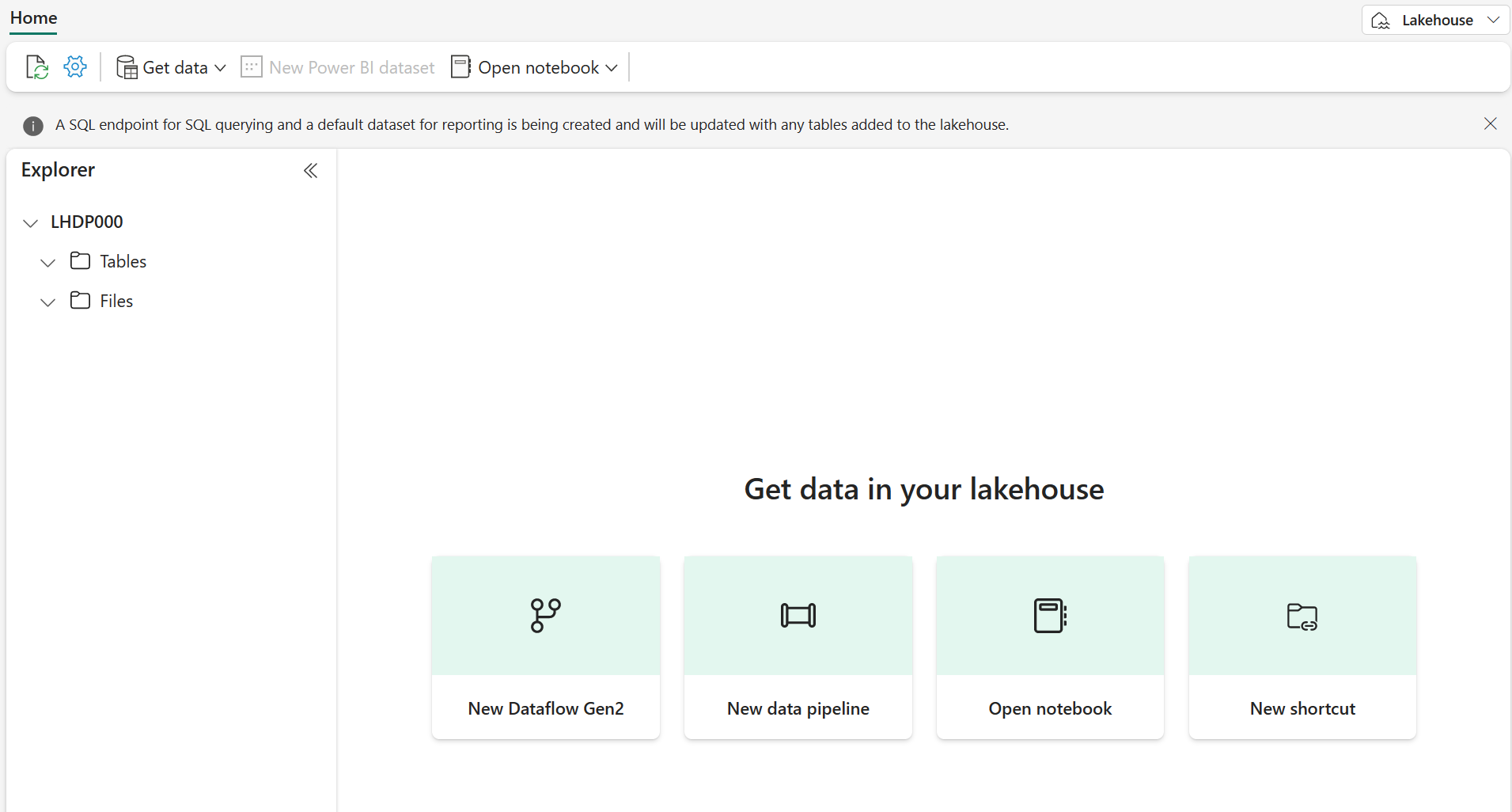
まず、新しいレイクハウスと、レイクハウス内の宛先フォルダーを作成します。
-
ワークスペースから [+ 新しい項目]、[レイクハウス] の順に選択し、名前を指定して、[作成] を選択します。
注: テーブルやファイルがない新しいレイクハウスを作成するには数分かかる場合があります。
-
[ファイル] から […] を選択して RawData という名前の新しいサブフォルダーを作成します。
-
レイクハウス内のレイクハウス エクスプローラーから、[RawData] > […] > [プロパティ] を選択します。
-
後で使用するために、 [RawData] フォルダーの ABFS パスを空のメモ帳にコピーします。これは次のようになります。
abfss://{workspace_name}@onelake.dfs.fabric.microsoft.com/{lakehouse_name}.Lakehouse/Files/{folder_name}/{file_name}
これで、レイクハウスと [RawData] 宛先フォルダーを含むワークスペースが作成されました。
Fabric ノートブックを作成して外部データを読み込む
新しい Fabric ノートブックを作成し、PySpark を使用して外部データ ソースに接続します。
-
レイクハウスの上部のメニューから、 [ノートブックを開く] > [新しいノートブック] を選択します。これは、作成後に開きます。
ヒント: レイクハウス エクスプローラーにはこのノートブック内からアクセスできます。また、この演習を完了した時に更新を行い進行状況を確認できます。
-
既定のセルで、コードが PySpark (Python) に設定されていることに注目してください。
- 次のコードをコード セルに挿入します。次を行います。
- 接続文字列のパラメーターを宣言する
- 接続文字列をビルドする
- DataFrame にデータを読み取る
# Azure Blob Storage access info blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" # Construct connection path wasbs_path = f'wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}' print(wasbs_path) # Read parquet data from Azure Blob Storage path blob_df = spark.read.parquet(wasbs_path) -
コード セルの横にある ▷ [セルの実行] を選択して、DataFrame に接続してデータを読み取ります。
予想される結果: コマンドは成功し、
wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellowと印刷されます注: Spark セッションは最初のコード実行で開始されるため、完了までに時間がかかる場合があります。
-
ファイルにデータを書き込むには、 [RawData] フォルダーの ABFS パスが必要になります。
-
新しいコード セルに次のコードを挿入します。
# Declare file name file_name = "yellow_taxi" # Construct destination path output_parquet_path = f"**InsertABFSPathHere**/{file_name}" print(output_parquet_path) # Load the first 1000 rows as a Parquet file blob_df.limit(1000).write.mode("overwrite").parquet(output_parquet_path) -
RawData ABFS パスを追加し、 [▷ セルの実行] を選択して、yellow_taxi.parquet ファイルに 1000 行を書き込みます。
-
output_parquet_path は次のようになります。
abfss://Spark@onelake.dfs.fabric.microsoft.com/DPDemo.Lakehouse/Files/RawData/yellow_taxi - レイクハウス エクスプローラーからのデータの読み込みを確認するには、 [ファイル] > […] > [最新の情報に更新] を選択します。
これで、新しいフォルダー [RawData] に yellow_taxi.parquet “ファイル” が表示されます。- “これは、パーティション ファイルが含まれるフォルダーとして表示されます”。**
データをデルタ テーブルに変換して読み込む
データ インジェストのタスクは、ファイルの読み込みだけで終わらない可能性があります。 レイクハウス内にデルタ テーブルがあると、スケーラブルで柔軟なクエリとストレージが可能になるため、ここで作成しましょう。
-
新しいコード セルを作成し、次のコードを挿入します。
from pyspark.sql.functions import col, to_timestamp, current_timestamp, year, month # Read the parquet data from the specified path raw_df = spark.read.parquet(output_parquet_path) # Add dataload_datetime column with current timestamp filtered_df = raw_df.withColumn("dataload_datetime", current_timestamp()) # Filter columns to exclude any NULL values in storeAndFwdFlag filtered_df = filtered_df.filter(col("storeAndFwdFlag").isNotNull()) # Load the filtered data into a Delta table table_name = "yellow_taxi" filtered_df.write.format("delta").mode("append").saveAsTable(table_name) # Display results display(filtered_df.limit(1)) -
コード セルの横にある ▷ [セルの実行] を選択します。
- これにより、データがデルタ テーブルに読み込まれたときにログするタイムスタンプ列 dataload_datetime が追加されます
- storeAndFwdFlag で NULL 値をフィルター処理します
- フィルター処理されたデータをデルタ テーブルに読み込みます
- 検証のために 1 つの行を表示します
-
次の図のような、表示された結果をレビューして確認します。

これで、外部データへの接続、parquet ファイルへの書き込み、データの DataFrame への読み込み、データの変換、デルタ テーブルへの読み込みが完了しました。
SQL クエリを使用してデルタ テーブルのデータを分析する
このラボでは、”抽出、変換、読み込み” プロセスについて実際に説明するデータ インジェストに焦点を当てていますが、データをプレビューすることも重要です。**
-
新しいコード セルを作成し、下記のコードを挿入します。
# Load table into df delta_table_name = "yellow_taxi" table_df = spark.read.format("delta").table(delta_table_name) # Create temp SQL table table_df.createOrReplaceTempView("yellow_taxi_temp") # SQL Query table_df = spark.sql('SELECT * FROM yellow_taxi_temp') # Display 10 results display(table_df.limit(10)) -
コード セルの横にある ▷ [セルの実行] を選択します。
多くのデータ アナリストは SQL 構文に慣れています。 Spark SQL は、Spark の SQL 言語 API であり、SQL ステートメントの実行だけではなく、リレーショナル テーブル内でのデータの永続化にも使用できます。
先ほど実行したコードでは、データフレームのデータのリレーショナル “ビュー” が作成された後、spark.sql ライブラリを使って Python コード内に Spark SQL 構文が埋め込まれ、ビューに対してクエリが実行され、結果がデータフレームとして返されます。
リソースをクリーンアップする
この演習では、Fabric の PySpark でノートブックを使用してデータを読み込み、それを Parquet に保存しました。 その後、その Parquet ファイルを使用して、データをさらに変換しました。 最後に、SQL を使用して Delta テーブルのクエリを実行しました。
探索が完了したら、この演習用に作成したワークスペースを削除できます。
- 左側のバーで、ワークスペースのアイコンを選択して、それに含まれるすべての項目を表示します。
- [ワークスペースの設定] を選択し、[全般] セクションで下にスクロールし、[このワークスペースを削除する] を選択します。
- [削除] を選択して、ワークスペースを削除します。