Microsoft Fabric で Data Wrangler を使用してデータを前処理する
このラボでは、Microsoft Fabric で Data Wrangler を使用してデータを前処理し、一般的なデータ サイエンス操作のライブラリを使用してコードを生成する方法について説明します。
このラボは完了するまで、約 30 分かかります。
注:この演習を完了するには、Microsoft Fabric 試用版が必要です。
ワークスペースの作成
Fabric でデータを操作する前に、Fabric 試用版を有効にしてワークスペースを作成してください。
- ブラウザーで Microsoft Fabric ホーム ページ (
https://app.fabric.microsoft.com/home?experience=fabric) に移動し、Fabric 資格情報でサインインします。 - 左側のメニュー バーで、 [ワークスペース] を選択します (アイコンは 🗇 に似ています)。
- 任意の名前で新しいワークスペースを作成し、Fabric 容量を含むライセンス モード (“試用版”、Premium、または Fabric) を選択します。**
-
開いた新しいワークスペースは空のはずです。
ノートブックを作成する
モデルをトレーニングするために、’‘ノートブック’’ を作成できます。 ノートブックでは、’‘実験’’ として (複数の言語で) コードを記述して実行できる対話型環境が提供されます。**
-
左側のメニュー バーで、[作成] を選択します。 [新規] ページの [Data Science] セクションで、[ノートブック] を選択します。 任意の一意の名前を設定します。
注: [作成] オプションがサイド バーにピン留めされていない場合は、最初に省略記号 (…) オプションを選択する必要があります。
数秒後に、1 つの ‘‘セル’’ を含む新しいノートブックが開きます。** ノートブックは、’‘コード’’ または ‘‘マークダウン’’ (書式設定されたテキスト) を含むことができる 1 つまたは複数のセルで構成されます。** **
-
最初のセル (現在は ‘‘コード’’ セル) を選択し、右上の動的ツール バーで [M↓] ボタンを使用してセルを ‘‘マークダウン’’ セルに変換します。** **
セルがマークダウン セルに変わると、それに含まれるテキストがレンダリングされます。
-
必要に応じて、[🖉] (編集) ボタンを使用してセルを編集モードに切り替えた後、その内容を削除して次のテキストを入力します。
# Perform data exploration for data science Use the code in this notebook to perform data exploration for data science.
データフレームにデータを読み込む
これで、データを取得するコードを実行する準備ができました。 Azure Open Datasets から OJ Sales データセットを操作します。 データを読み込んだ後、データを Pandas データフレームに変換します。これは、Data Wrangler でサポートされている構造です。
-
ノートブックで、最新のセルの下にある [+ コード] アイコンを使用して、新しいコード セルをノートブックに追加します。
ヒント: [+ コード] アイコンを表示するには、マウスを現在のセルの出力のすぐ左下に移動します。 別の方法として、メニュー バーの [編集] タブで、[+ コード セルの追加] を選択します。
-
データセットをデータフレームに読み込むには、次のコードを入力します。
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "ojsales-simulatedcontainer" blob_relative_path = "oj_sales_data" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark reads csv df = spark.read.csv(wasbs_path, header=True) -
セルの左側にある [▷] (セルの実行) ボタンを使用して実行します。 または、キーボードで
SHIFT+ENTERキーを押してセルを実行できます。注: このセッション内で Spark コードを実行したのはこれが最初であるため、Spark プールを起動する必要があります。 これは、セッション内での最初の実行が完了するまで 1 分ほどかかる場合があることを意味します。 それ以降は、短時間で実行できます。
-
セル出力の下にある [+ コード] アイコンを使用して、ノートブックに新しいコード セルを追加し、次のコードを入力します。
import pandas as pd df = df.toPandas() df = df.sample(n=500, random_state=1) df['WeekStarting'] = pd.to_datetime(df['WeekStarting']) df['Quantity'] = df['Quantity'].astype('int') df['Advert'] = df['Advert'].astype('int') df['Price'] = df['Price'].astype('float') df['Revenue'] = df['Revenue'].astype('float') df = df.reset_index(drop=True) df.head(4) -
セル コマンドが完了したら、セルの下にある出力を確認します。これは次のようになるはずです。
WeekStarting ストア ブランド Quantity Advert 価格 Revenue 0 1991-10-17 947 minute.maid 13306 1 2.42 32200.52 1 1992-03-26 1293 dominicks 18596 1 1.94 36076.24 2 1991-08-15 2278 dominicks 17457 1 2.14 37357.98 3 1992-09-03 2175 tropicana 9652 1 2.07 19979.64 … … … … … … … … 出力には、OJ Sales データセットの最初の 4 行が表示されます。
概要の統計情報を表示する
データを読み込んだので、次の手順では Data Wrangler を使用して前処理をします。 前処理は、あらゆる機械学習ワークフローの重要なステップです。 これには、データのクリーニングと、機械学習モデルに取り込むことができる形式への変換が含まれます。
-
ノートブック リボンの [データ ] を選択し、[Data Wrangler の起動] ドロップダウンを選択します。
-
dfデータセットを選択します。 Data Wrangler が起動すると、データフレームの詳細な概要が [概要] パネルに生成されます。 -
[Revenue] 特徴量を選択し、この特徴量のデータ分布を確認します。
-
[概要] サイド パネルの詳細を確認し、統計情報の値を確認します。
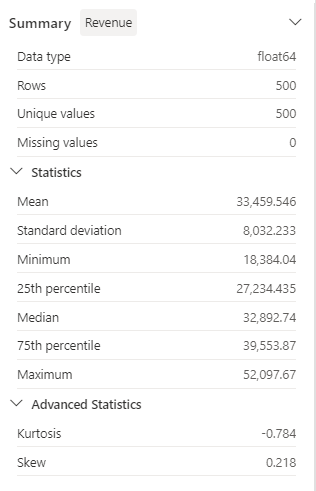
そこから引き出せる分析情報の一部には何がありますか? 平均収益は約 $33,459.54 で、標準偏差は $8,032.23 です。 これは、収益値が平均を中心に約 $8,032.23 の範囲に分散していることを示唆しています。
テキスト データの書式設定
次に、いくつかの変換を Brand という特徴に適用してみましょう。
-
Data Wrangler ダッシュボードで、グリッド上の
Brand特徴量を選択します。 -
[操作] パネルに移動し、[検索と置換] を展開してから、[検索と置換] を選択します。
-
[検索と置換] パネルで、以下のプロパティを変更します。
- 元の値: “
.” - 新しい値: “
操作の結果は、表示グリッドに自動的にプレビュー表示されます。
- 元の値: “
-
適用を選択します。
-
[操作] パネルに戻り、 [書式設定] を展開します。
-
[Capitalize first character](先頭文字を大文字にする) を選択します。 [Capitalize all words](すべての単語を大文字にする) トグルをオンに切り替えてから、[適用] を選択します。
-
[Add code to notebook] (ノートブックにコードを追加する) を選択します。 さらに、コードをコピーして、変換したデータセットを CSV ファイルとして保存することもできます。
注: コードはノートブック セルに自動的にコピーされ、使用できる状態になっています。
-
Data Wrangler で生成されたコードは元のデータフレームを上書きしないため、10 行目と 11 行目をコード
df = clean_data(df)で置き換えます。 最終的なコード ブロックは、次のようになります。def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() return df df = clean_data(df) -
コード セルを実行し、
Brand変数をチェックします。df['Brand'].unique()結果には、値 Minute Maid、Dominicks、Tropicana が表示されます。
テキスト データをグラフィカルに操作し、Data Wrangler を使用してコードを簡単に生成する方法を説明しました。
One Hot エンコード変換を適用する
次に、前処理手順の一環として、One Hot エンコード変換をデータに適用するコードを生成してみましょう。 シナリオをより実用的にするために、まずサンプル データを生成します。 これにより、実際の状況をシミュレートし、実用的な特徴量を得ることができます。
-
dfデータフレームの上部メニューで Data Wrangler を起動します。 -
グリッド上の
Brand特徴量を選択します。 -
[操作] パネルで [数式] を展開してから、[One-hot エンコード] を選択します。
-
[One-hot エンコード] パネルで、[適用] を選択します。
Data Wrangler 表示グリッドの末尾に移動します。 それによって 3 つの新しい特徴量 (
Brand_Dominicks、Brand_Minute Maid、Brand_Tropicana) が追加され、Brand特徴量が削除されたことに注意してください。 -
コードを生成せずに Data Wrangler を終了します。
並べ替えとフィルター処理の操作
特定の店舗の収益データを確認し、商品価格を並べ替える必要がある場合を考えてみましょう。 次の手順では、Data Wrangler を使用して df データフレームのフィルター処理と分析を行います。
-
dfデータフレームで Data Wrangler を起動します。 -
[操作] パネルで、[並べ替えとフィルター] を展開します。
-
フィルターを選択します。
-
[フィルター] パネルで、次の条件を追加します。
- ターゲット列::
Store - 操作:
Equal to - 値:
1227 - アクション:
Keep matching rows
- ターゲット列::
-
[適用] を選択し、Data Wrangler の表示グリッドの変化に注意してください。
-
[Revenue] 特徴量を選択し、[概要] サイド パネルの詳細を確認します。
そこから引き出せる分析情報の一部には何がありますか? 歪度は -0.751 で、わずかな左スキュー (負のスキュー) を示しています。 これは、分布の左端が右端よりも少し長いことを意味します。 つまり、収益が平均を大幅に下回る期間が多数存在します。
-
[操作] パネルに戻り、 [並べ替えとフィルター] を展開します。
-
[値の並べ替え] を選択します。
-
[Sort values](値の並べ替え) パネルで、次のプロパティを選択します。
- 列の名前:
Price - 並べ替え順序:
Descending
- 列の名前:
-
適用を選択します。
店舗 1227 の最も高い商品価格は $2.68 です。 レコードの数が少ない場合、最も高い商品価格を特定することは簡単ですが、何千件もの結果を処理する場合の複雑さを考えてみてください。
ステップを参照して削除する
間違いがあったために前のステップで作成した並べ替えを削除する必要があるとします。 削除するには、次の手順に従います。
-
[クリーニング ステップ] パネルに移動します。
-
[値の並べ替え] ステップを 選択します。
-
それを、削除アイコンを選択して削除します。
![[検索と置換] パネルを示す [Data Wrangler] ページのスクリーンショット。](/mslearn-fabric.ja-jp/Instructions/Labs/Images/data-wrangler-delete.png)
重要: グリッド ビューと概要は、現在のステップに限定されています。
変更が前のステップ (フィルター ステップ) まで戻されていることに注意してください。
-
コードを生成せずに Data Wrangler を終了します。
集計データ
各ブランドによって生成された平均収益を理解する必要があるとします。 以下の手順では、Data Wrangler を使用して、df データフレームに対してグループ化操作を実行します。
-
dfデータフレームで Data Wrangler を起動します。 -
[操作] パネルに戻り、 [Group by and aggregate] (グループ化と集計) を選択します。
-
[Columns to group by](グループ化する列) プロパティで、
Brand特徴量を選択します。 -
[集計の追加] を選択します。
-
[集計する列] プロパティで、
Revenueという特徴を選択します。 -
[集計の種類] プロパティでは
Meanを選択します。 -
適用を選択します。
-
[コードをクリップボードにコピーします] を選択します。
-
コードを生成せずに Data Wrangler を終了します。
-
Brand変数の変換のコードと、clean_data(df)関数の集計ステップによって生成されたコードを組み合わせます。 最終的なコード ブロックは、次のようになります。def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() # Performed 1 aggregation grouped on column: 'Brand' df = df.groupby(['Brand']).agg(Revenue_mean=('Revenue', 'mean')).reset_index() return df df = clean_data(df) -
セル コードを実行します。
-
データフレーム内のデータを確認します。
print(df)結果:
ブランド Revenue_mean 0 Dominicks 33206.330958 1 Minute Maid 33532.999632 2 Tropicana 33637.863412
いくつかの前処理操作用のコードを生成し、そのコードを関数としてノートブックにコピーしました。今後、必要に応じてこれを実行、再利用、または変更できます。
ノートブックを保存して Spark セッションを終了する
モデリングのためのデータの前処理が済んだので、わかりやすい名前でノートブックを保存し、Spark セッションを終了できます。
- ノートブックのメニュー バーで、[⚙️] (設定) アイコンを使用してノートブックの設定を表示します。
- ノートブックの [名前] を「Data Wrangler でデータを前処理する」に設定して、設定ペインを閉じます。
- ノートブック メニューで、 [セッションの停止] を選択して Spark セッションを終了します。
リソースをクリーンアップする
この演習では、ノートブックを作成し、Data Wrangler を使用して機械学習モデルのデータを探索し、前処理しました。
前処理ステップの探索が終了したら、この演習用に作成したワークスペースを削除できます。
- 左側のバーで、ワークスペースのアイコンを選択して、それに含まれるすべての項目を表示します。
- ツール バーの […] メニューで、 [ワークスペースの設定] を選択してください。
- [全般] セクションで、[このワークスペースの削除] を選択します。