Microsoft Fabric レイクハウスでメダリオン アーキテクチャを作成する
この演習では、ノートブックを使用して Fabric レイクハウスにメダリオン アーキテクチャを構築します。 ワークスペースの作成、レイクハウスの作成、ブロンズ レイヤーへのデータのアップロード、データの変換とシルバー Delta テーブルへの読み込み、追加のデータ変換とゴールド Delta テーブルへの読み込み、セマンティック モデルの探索とリレーションシップの作成を行います。
この演習の完了に要する時間は約 45 分です
ワークスペースの作成
注: この演習を完了するには、Fabric の有料版または試用版の容量にアクセスできることが必要です。 無料の Fabric 試用版の詳細については、Fabric 試用版に関するページを参照してください。
- ブラウザーで Microsoft Fabric ホーム ページ (
https://app.fabric.microsoft.com/home?experience=fabric-developer) に移動し、Fabric 資格情報でサインインします。 - 左側のメニュー バーで、 [ワークスペース] を選択します (アイコンは 🗇 に似ています)。
- 新しいワークスペースを任意の名前で作成し、 [詳細] セクションで、Fabric 容量を含むライセンス モード (“試用版“、Premium、または Fabric) を選択します。
-
開いた新しいワークスペースは空のはずです。
レイクハウスを作成し、ブロンズ レイヤーにデータをアップロードする
ワークスペースが作成されたので、次に分析するデータ用のデータ レイクハウスを作成します。
-
作成したワークスペースで [+ 新しい項目] ボタンを選択して、[Sales] という名前の新しい [レイクハウス] を作成します。 [レイクハウス スキーマ] チェック ボックスはオンにしたままにします。
1 分ほどすると、新しい空のレイクハウスが作成されます。 次に、分析のために、データ レイクハウスにいくつかのデータを取り込みます。 これを行うには複数の方法がありますが、この演習では、テキスト ファイルをローカル コンピューター (または、該当する場合はラボ VM) にダウンロードし、レイクハウスにアップロードするだけです。
-
https://github.com/MicrosoftLearning/dp-data/blob/main/orders.zipからこの演習用のデータ ファイルをダウンロードして抽出します。 ファイルを抽出し、元の名前でローカル コンピューター (または該当する場合はラボ VM) に保存します。 3 年間の売上データを含む 3 つのファイル (2019.csv、2020.csv、2021.csv) が含まれているはずです。 -
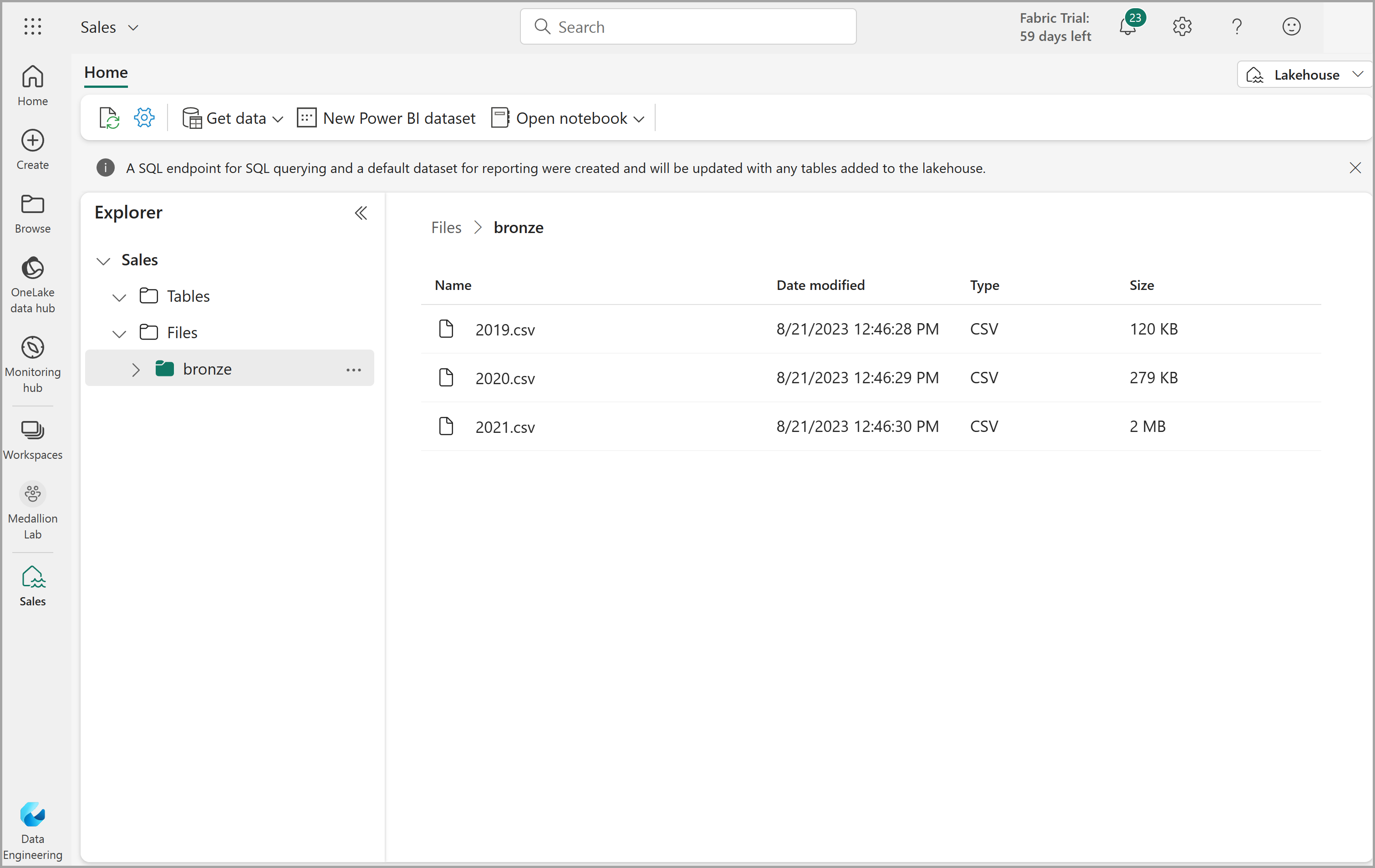
レイクハウスの Web ブラウザー タブに戻り、エクスプローラー ペインの Files フォルダーの […] メニューで、 [新しいサブフォルダー] を選択し、bronze という名前のフォルダーを作成します。
-
bronze フォルダーの […] メニューで、 [アップロード] 、 [ファイルのアップロード] の順に選択し、3 つのファイル (2019.csv、2020.csv、2021.csv) をローカル コンピューター (または、該当する場合はラボ VM) からレイクハウスにアップロードします。 3 つのファイルすべてを一度にアップロードするには Shift キーを使用します。
-
ファイルがアップロードされたら、bronze フォルダーを選びます。そして、次に示すように、ファイルがアップロードされていることを確認します。
データを変換し、シルバー Delta テーブルに読み込む
これで、レイクハウスのブロンズ レイヤーにいくつかのデータが作成されたので、ノートブックを使用してデータを変換し、シルバー レイヤーのデルタ テーブルに読み込むことができます。
-
データレイクの bronze フォルダーの内容を表示したまま、 [ホーム] ページの [ノートブックを開く] メニューで、 [新しいノートブック] を選択します。
数秒後に、1 つの ‘‘セル’’ を含む新しいノートブックが開きます。** ノートブックは、’‘コード’’ または ‘‘マークダウン’’ (書式設定されたテキスト) を含むことができる 1 つ以上のセルで構成されます。** **
-
ノートブックが開いたら、ノートブックの左上にある [Notebook xxxx] テキストを選択して新しい名前を入力することで、ノートブックの名前を
Transform data for Silverに変更します。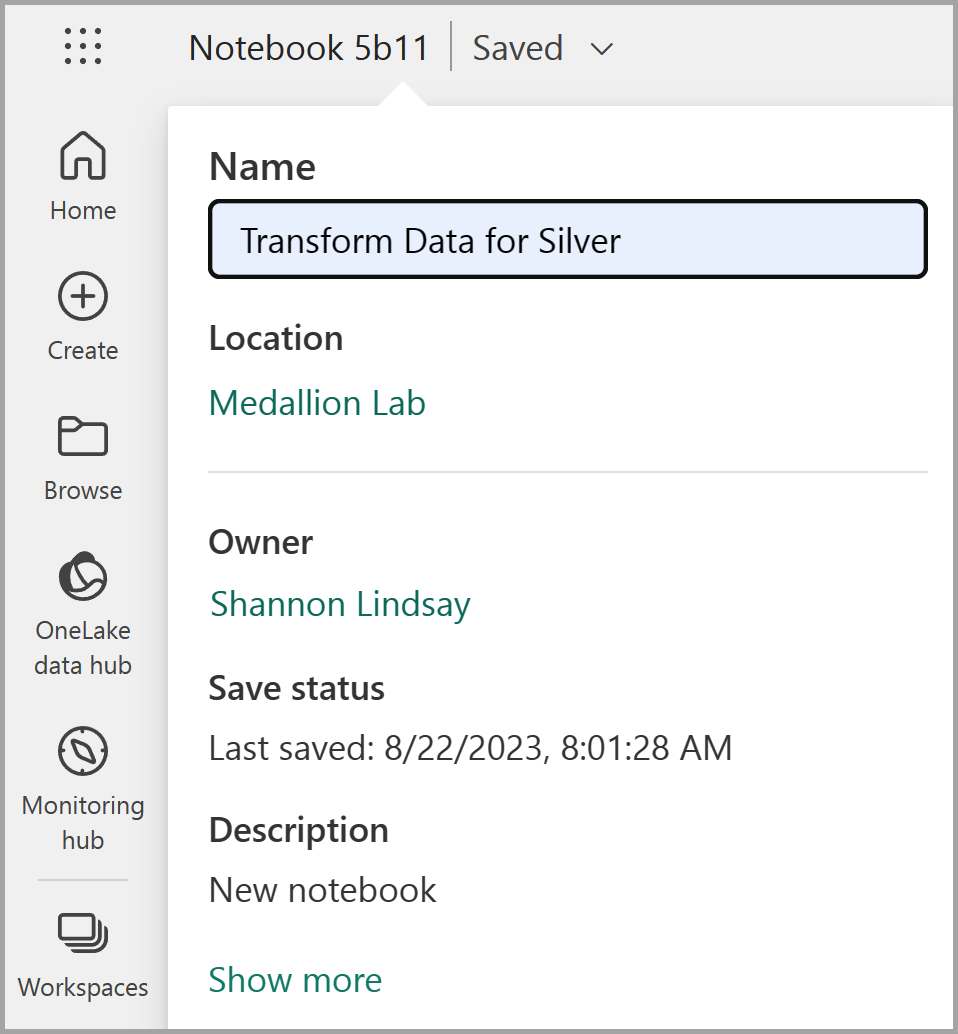
-
ノートブック内の既存のセルを選択します。このセルには、いくつかの単純なコメントアウト コードが含まれています。 これら 2 つの行を強調表示して削除します。このコードは必要ありません。
注: ノートブックを使用すると、Python、Scala、SQL など、さまざまな言語でコードを実行できます。 この演習では、PySpark と SQL を使用します。 マークダウン セルを追加して、コードを文書化するための書式設定されたテキストと画像を指定することもできます。
-
次のコードをセルに貼り付けます。
from pyspark.sql.types import * # Create the schema for the table orderSchema = StructType([ StructField("SalesOrderNumber", StringType()), StructField("SalesOrderLineNumber", IntegerType()), StructField("OrderDate", DateType()), StructField("CustomerName", StringType()), StructField("Email", StringType()), StructField("Item", StringType()), StructField("Quantity", IntegerType()), StructField("UnitPrice", FloatType()), StructField("Tax", FloatType()) ]) # Import all files from bronze folder of lakehouse df = spark.read.format("csv").option("header", "false").schema(orderSchema).load("Files/bronze/*.csv") # Display the first 10 rows of the dataframe to preview your data display(df.head(10)) -
セルの左側にある **▷ ( [セルの実行] )** ボタンを使ってコードを実行します。
注: このノートブック内で Spark コードを実行したのはこれが最初であるため、Spark セッションを起動する必要があります。 これは、最初の実行が完了するまで 1 分ほどかかる場合があることを意味します。 それ以降は、短時間で実行できます。
-
セル コマンドが完了したら、セルの下にある出力を確認します。これは次のようになるはずです。
Index SalesOrderNumber SalesOrderLineNumber OrderDate CustomerName Email Item Quantity UnitPrice 税 1 SO49172 1 2021-01-01 Brian Howard brian23@adventure-works.com Road-250 Red, 52 1 2443.35 195.468 2 SO49173 1 2021-01-01 Linda Alvarez linda19@adventure-works.com Mountain-200 Silver, 38 1 2071.4197 165.7136 … … … … … … … … … … 実行したコードは、bronze フォルダー内の CSV ファイルから Spark データフレームにデータを読み込み、データフレームの最初の数行を表示しました。
注: 出力ウィンドウの左上にある […] メニューを選択すると、セル出力の内容をクリア、非表示、自動サイズ変更できます。
-
次に、PySpark データフレームを使用して列を追加し、既存の列の一部の値を更新して、データ検証とクリーンアップ用の列を追加します。 [+ コード] ボタンを使用して新しいコード ブロックを追加し、次のコードをセルに追加します。
from pyspark.sql.functions import when, lit, col, current_timestamp, input_file_name # Add columns IsFlagged, CreatedTS and ModifiedTS df = df.withColumn("FileName", input_file_name()) \ .withColumn("IsFlagged", when(col("OrderDate") < '2019-08-01',True).otherwise(False)) \ .withColumn("CreatedTS", current_timestamp()).withColumn("ModifiedTS", current_timestamp()) # Update CustomerName to "Unknown" if CustomerName null or empty df = df.withColumn("CustomerName", when((col("CustomerName").isNull() | (col("CustomerName")=="")),lit("Unknown")).otherwise(col("CustomerName")))コードの最初の行により、PySpark から必要な関数がインポートされます。 次に、データフレームに新しい列を追加して、ソース ファイル名、注文が該当の会計年度の前にフラグが付けられたかどうか、行がいつ作成および変更されたかを追跡できるようにします。
最後に、CustomerName 列が null 値または空の場合は、”Unknown” に更新します。
-
セルを実行し、**▷ ( [セルの実行] )** ボタンを使用してコードを実行します。
-
次に、Delta Lake 形式を使用して、販売データベースの sales_silver テーブルのスキーマを定義します。 新しいコード ブロックを作成し、セルに次のコードを追加します。
# Define the schema for the sales_silver table from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.dbo.sales_silver") \ .addColumn("SalesOrderNumber", StringType()) \ .addColumn("SalesOrderLineNumber", IntegerType()) \ .addColumn("OrderDate", DateType()) \ .addColumn("CustomerName", StringType()) \ .addColumn("Email", StringType()) \ .addColumn("Item", StringType()) \ .addColumn("Quantity", IntegerType()) \ .addColumn("UnitPrice", FloatType()) \ .addColumn("Tax", FloatType()) \ .addColumn("FileName", StringType()) \ .addColumn("IsFlagged", BooleanType()) \ .addColumn("CreatedTS", DateType()) \ .addColumn("ModifiedTS", DateType()) \ .execute() -
セルを実行し、**▷ ( [セルの実行] )** ボタンを使用してコードを実行します。
-
[エクスプローラー] ペインの Tables セクションで […] を選択し、[更新] を選択します。 新しい sales_silver テーブルが一覧表示されます。 ▲ (三角形のアイコン) は、これが Delta テーブルであることを示します。
注: 新しいテーブルが表示されない場合は、数秒待ってからもう一度 [更新] を選択するか、ブラウザー タブ全体を更新してください。
-
次に、Delta テーブルに対してアップサート操作を実行し、特定の条件に基づいて既存のレコードを更新し、一致するものが見つからない場合は新しいレコードを挿入します。 新しいコード ブロックを追加し、次のコードを貼り付けます。
# Update existing records and insert new ones based on a condition defined by the columns SalesOrderNumber, OrderDate, CustomerName, and Item. from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dbo/sales_silver') dfUpdates = df deltaTable.alias('silver') \ .merge( dfUpdates.alias('updates'), 'silver.SalesOrderNumber = updates.SalesOrderNumber and silver.OrderDate = updates.OrderDate and silver.CustomerName = updates.CustomerName and silver.Item = updates.Item' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "SalesOrderNumber": "updates.SalesOrderNumber", "SalesOrderLineNumber": "updates.SalesOrderLineNumber", "OrderDate": "updates.OrderDate", "CustomerName": "updates.CustomerName", "Email": "updates.Email", "Item": "updates.Item", "Quantity": "updates.Quantity", "UnitPrice": "updates.UnitPrice", "Tax": "updates.Tax", "FileName": "updates.FileName", "IsFlagged": "updates.IsFlagged", "CreatedTS": "updates.CreatedTS", "ModifiedTS": "updates.ModifiedTS" } ) \ .execute() -
セルを実行し、**▷ ( [セルの実行] )** ボタンを使用してコードを実行します。
この操作は、特定の列の値に基づいてテーブル内の既存のレコードを更新し、一致するものが見つからない場合に新しいレコードを挿入できるようにするため、重要です。 これは、既存のレコードの更新と新しいレコードを含む可能性があるデータをソース システムから読み込む場合の一般的な要件です。
これで、データがシルバー Delta テーブルに追加され、追加の変換とモデリングを行う準備ができました。
-
最後のセルを実行した後、リボンの上にある [実行] タブを選択し、[セッションの停止] を選択して、ノートブックで使用されているコンピューティング リソースを停止します。
SQL エンドポイントを使用してシルバー レイヤー内のデータを探索する
シルバー レイヤーにデータが用意されたので、SQL 分析エンドポイントを使用して、データを探索したり、基本的な分析を実行したりできます。 これは、SQL に精通しているユーザーがデータの基本的な探索を行いたい場合に便利です。 この演習では、Fabric の SQL エンドポイント ビューを使用していますが、SQL Server Management Studio (SSMS) や Azure Data Explorer などの他のツールも使用できます。
-
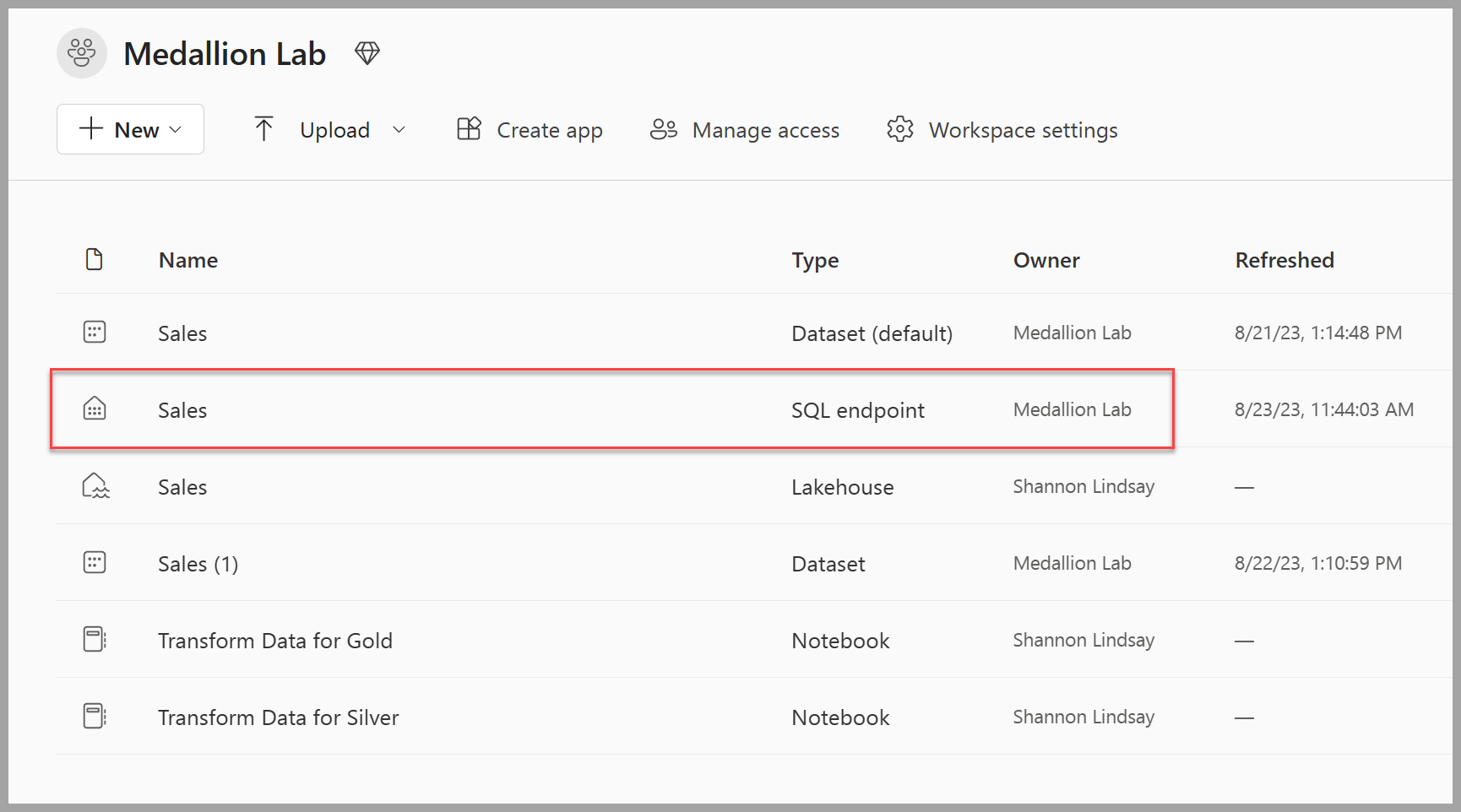
ワークスペースに戻り、いくつかのアイテムが一覧に入っていることを確認します。 [売上 SQL 分析エンドポイント] を選択して、SQL 分析エンドポイント ビューでレイクハウスを開きます。
-
リボンから [新しい SQL クエリ] を選択すると、SQL クエリ エディターが開きます。 [エクスプローラー] ペインの既存のクエリ名の横にある […] メニュー項目を使用して、クエリの名前を変更することができます。
次に、2 つの SQL クエリを実行してデータを探索します。
-
次のクエリをクエリ エディターに貼り付けて、 [実行] を選択します。
SELECT YEAR(OrderDate) AS Year , CAST (SUM(Quantity * (UnitPrice + Tax)) AS DECIMAL(12, 2)) AS TotalSales FROM dbo.sales_silver GROUP BY YEAR(OrderDate) ORDER BY YEAR(OrderDate)このクエリでは、sales_silver テーブルの各年の売上合計が計算されます。 結果は次のようになります。
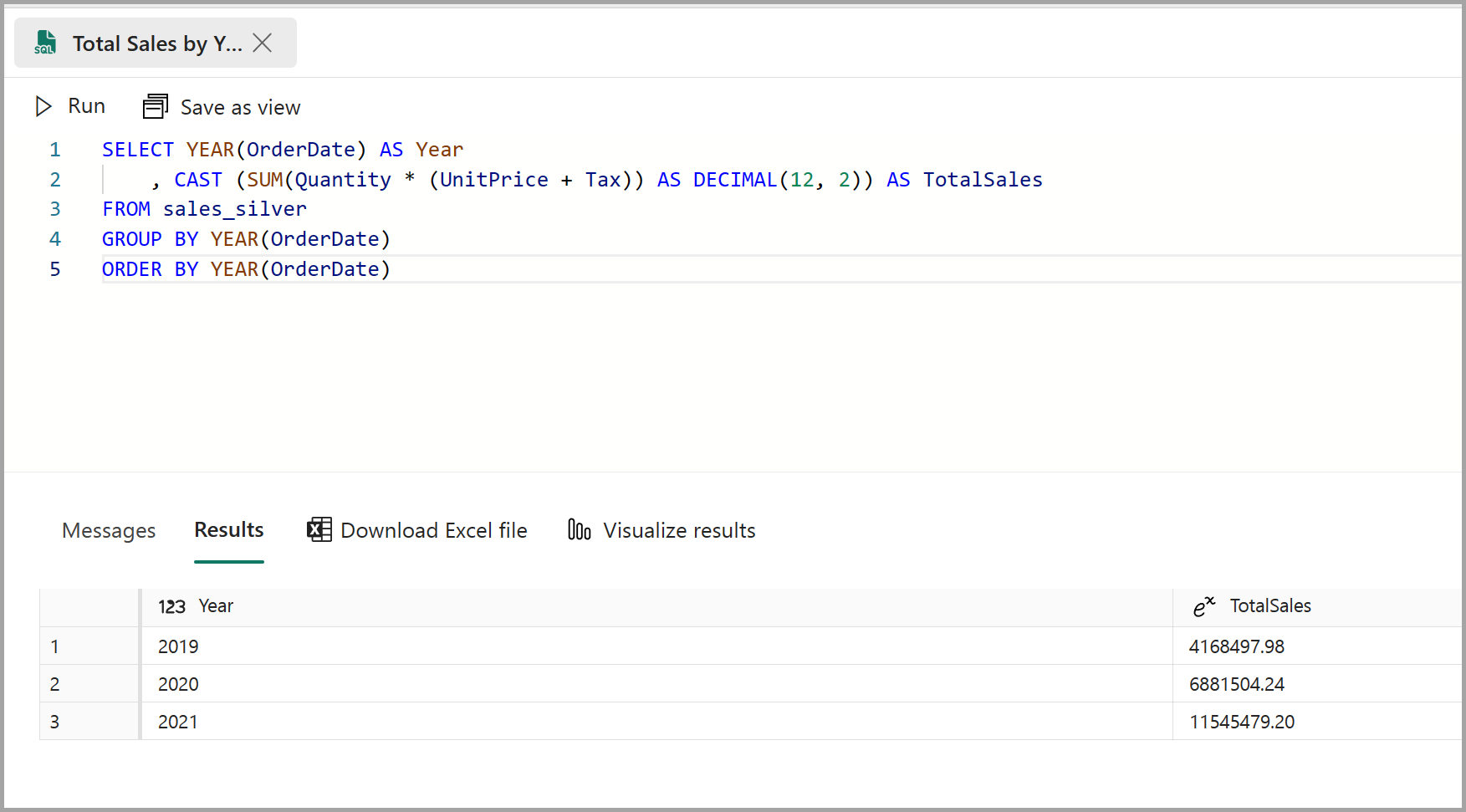
-
次に、(数量の観点から) 最も多く購入している顧客を確認します。 次のクエリをクエリ エディターに貼り付けて、 [実行] を選択します。
SELECT CustomerName, SUM(Quantity) AS TotalQuantity FROM dbo.sales_silver GROUP BY CustomerName ORDER BY TotalQuantity DESC LIMIT 10このクエリでは、sales_silver テーブルで各顧客が購入した品目の合計数量を計算し、数量の観点から上位 10 人の顧客を返します。
シルバー レイヤーでのデータ探索は基本的な分析に役立ちますが、データをさらに変換し、それをスター スキーマにモデル化して、より高度な分析とレポートを可能にする必要があります。 これは、次のセクションで行います。
ゴールド レイヤー向けにデータを変換する
ブロンズ レイヤーからデータを取得し、変換し、シルバー Delta テーブルに読み込みました。 次に、新しいノートブックを使用してデータをさらに変換し、それをスター スキーマにモデル化し、ゴールド Delta テーブルに読み込みます。
このすべてを 1 つのノートブックで行うことができたのですが、この演習では、データをブロンズからシルバーに変換し、さらにシルバーからゴールドに変換するプロセスを示すために、別々のノートブックを使用しています。 これは、デバッグ、トラブルシューティング、再利用に役立ちます。
-
ワークスペースのホーム ページに戻り、
Transform data for Goldという名前の新しいノートブックを作成します。 -
[エクスプローラー] ペインで [データ項目の追加] を選択して前の手順で作成した [Sales] レイクハウスを選択することで、[Sales] レイクハウスを追加します。 エクスプローラー ウィンドウの [テーブル] セクションに sales_silver テーブルが表示されます。
-
既存のコード ブロックで、コメントのテキストを削除し、データをデータフレームに読み込んでスター スキーマの構築を開始する次のコードを追加して、そのコードを実行します。
# Load data to the dataframe as a starting point to create the gold layer df = spark.read.table("Sales.dbo.sales_silver")注:最初のセルの実行時に
[TooManyRequestsForCapacity]エラーが発生した場合は、最初のノートブックで以前に実行されていたセッションを停止したことを確認します。 -
新しいコード ブロックを追加し、日付ディメンション テーブルを作成するための次のコードを貼り付けて、それを実行します。
from pyspark.sql.types import * from delta.tables import* # Define the schema for the dimdate_gold table DeltaTable.createIfNotExists(spark) \ .tableName("sales.dbo.dimdate_gold") \ .addColumn("OrderDate", DateType()) \ .addColumn("Day", IntegerType()) \ .addColumn("Month", IntegerType()) \ .addColumn("Year", IntegerType()) \ .addColumn("mmmyyyy", StringType()) \ .addColumn("yyyymm", StringType()) \ .execute()注:
display(df)コマンドはいつでも実行して、作業の進行状況をチェックできます。 この場合は、’display(dfdimDate_gold)’ を実行して、dimDate_gold データフレームの内容を表示します。 -
新しいコード ブロックで、日付ディメンション (dimdate_gold) のデータフレームを作成するための次のコードを追加して実行します。
from pyspark.sql.functions import col, dayofmonth, month, year, date_format # Create dataframe for dimDate_gold dfdimDate_gold = df.dropDuplicates(["OrderDate"]).select(col("OrderDate"), \ dayofmonth("OrderDate").alias("Day"), \ month("OrderDate").alias("Month"), \ year("OrderDate").alias("Year"), \ date_format(col("OrderDate"), "MMM-yyyy").alias("mmmyyyy"), \ date_format(col("OrderDate"), "yyyyMM").alias("yyyymm"), \ ).orderBy("OrderDate") # Display the first 10 rows of the dataframe to preview your data display(dfdimDate_gold.head(10)) -
データを変換するときにノートブックで何が起こっているかを理解して観察できるように、コードを新しいコード ブロックに分割します。 別の新しいコード ブロックで、新しいデータが入ってきたら日付ディメンションを更新するための次のコードを追加して実行します。
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dbo/dimdate_gold') dfUpdates = dfdimDate_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.OrderDate = updates.OrderDate' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "OrderDate": "updates.OrderDate", "Day": "updates.Day", "Month": "updates.Month", "Year": "updates.Year", "mmmyyyy": "updates.mmmyyyy", "yyyymm": "updates.yyyymm" } ) \ .execute()日付ディメンションが設定されました。 次に、顧客ディメンションを作成します。
-
顧客ディメンション テーブルを構築するには、新しいコード ブロックを追加し、次のコードを貼り付けて実行します。
from pyspark.sql.types import * from delta.tables import * # Create customer_gold dimension delta table DeltaTable.createIfNotExists(spark) \ .tableName("sales.dbo.dimcustomer_gold") \ .addColumn("CustomerName", StringType()) \ .addColumn("Email", StringType()) \ .addColumn("First", StringType()) \ .addColumn("Last", StringType()) \ .addColumn("CustomerID", LongType()) \ .execute() -
新しいコード ブロックで、重複する顧客を削除し、特定の列を選択し、”CustomerName” 列を分割して “First” と “Last” の名前列を作成するための次のコードを追加して実行します。
from pyspark.sql.functions import col, split # Create customer_silver dataframe dfdimCustomer_silver = df.dropDuplicates(["CustomerName","Email"]).select(col("CustomerName"),col("Email")) \ .withColumn("First",split(col("CustomerName"), " ").getItem(0)) \ .withColumn("Last",split(col("CustomerName"), " ").getItem(1)) # Display the first 10 rows of the dataframe to preview your data display(dfdimCustomer_silver.head(10))ここでは、重複の削除、特定の列の選択、”CustomerName” 列を分割して “First” と “Last” の名前列を作成するなど、さまざまな変換を実行して、新しい DataFrame dfdimCustomer_silver を作成しました。 その結果、”CustomerName” 列から抽出された個別の “First” と “Last” の名前列を含む、クリーンで構造化された顧客データを含む DataFrame になりました。
-
次に、顧客の ID 列を作成します。 新しいコード ブロックで、次を貼り付けて実行します。
from pyspark.sql.functions import monotonically_increasing_id, col, when, coalesce, max, lit dfdimCustomer_temp = spark.read.table("Sales.dbo.dimCustomer_gold") MAXCustomerID = dfdimCustomer_temp.select(coalesce(max(col("CustomerID")),lit(0)).alias("MAXCustomerID")).first()[0] dfdimCustomer_gold = dfdimCustomer_silver.join(dfdimCustomer_temp,(dfdimCustomer_silver.CustomerName == dfdimCustomer_temp.CustomerName) & (dfdimCustomer_silver.Email == dfdimCustomer_temp.Email), "left_anti") dfdimCustomer_gold = dfdimCustomer_gold.withColumn("CustomerID",monotonically_increasing_id() + MAXCustomerID + 1) # Display the first 10 rows of the dataframe to preview your data display(dfdimCustomer_gold.head(10))ここでは、左の反結合を実行して dimCustomer_gold テーブルに既に存在する重複を除外し、monotonically_increasing_id() 関数を使用して一意の CustomerID 値を生成することで、顧客データ (dfdimCustomer_silver) をクリーニングして変換します。
-
次に、新しいデータが入力されると、顧客テーブルが最新の状態に保たれるようにします。 新しいコード ブロックで、次を貼り付けて実行します。
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dbo/dimcustomer_gold') dfUpdates = dfdimCustomer_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.CustomerName = updates.CustomerName AND gold.Email = updates.Email' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "CustomerName": "updates.CustomerName", "Email": "updates.Email", "First": "updates.First", "Last": "updates.Last", "CustomerID": "updates.CustomerID" } ) \ .execute() -
ここで、これらの手順を繰り返して製品ディメンションを作成します。 新しいコード ブロックで、次を貼り付けて実行します。
from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.dbo.dimproduct_gold") \ .addColumn("ItemName", StringType()) \ .addColumn("ItemID", LongType()) \ .addColumn("ItemInfo", StringType()) \ .execute() -
別のコード ブロックを追加して、product_silver データフレームを作成します。
from pyspark.sql.functions import col, split, lit, when # Create product_silver dataframe dfdimProduct_silver = df.dropDuplicates(["Item"]).select(col("Item")) \ .withColumn("ItemName",split(col("Item"), ", ").getItem(0)) \ .withColumn("ItemInfo",when((split(col("Item"), ", ").getItem(1).isNull() | (split(col("Item"), ", ").getItem(1)=="")),lit("")).otherwise(split(col("Item"), ", ").getItem(1))) # Display the first 10 rows of the dataframe to preview your data display(dfdimProduct_silver.head(10)) -
次に、dimProduct_gold テーブルの ID を作成します。 新しいコード ブロックに次の構文を追加してそれを実行します。
from pyspark.sql.functions import monotonically_increasing_id, col, lit, max, coalesce #dfdimProduct_temp = dfdimProduct_silver dfdimProduct_temp = spark.read.table("Sales.dbo.dimProduct_gold") MAXProductID = dfdimProduct_temp.select(coalesce(max(col("ItemID")),lit(0)).alias("MAXItemID")).first()[0] dfdimProduct_gold = dfdimProduct_silver.join(dfdimProduct_temp,(dfdimProduct_silver.ItemName == dfdimProduct_temp.ItemName) & (dfdimProduct_silver.ItemInfo == dfdimProduct_temp.ItemInfo), "left_anti") dfdimProduct_gold = dfdimProduct_gold.withColumn("ItemID",monotonically_increasing_id() + MAXProductID + 1) # Display the first 10 rows of the dataframe to preview your data display(dfdimProduct_gold.head(10))これにより、テーブル内の現在のデータに基づいて次に使用可能な製品 ID が計算され、これらの新しい ID が製品に割り当てられ、更新された製品情報が表示されます。
-
他のディメンションで行ったことと同様に、新しいデータが入力されるたびに製品テーブルが最新の状態に保たれるようにする必要があります。 新しいコード ブロックで、次を貼り付けて実行します。
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dbo/dimproduct_gold') dfUpdates = dfdimProduct_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.ItemName = updates.ItemName AND gold.ItemInfo = updates.ItemInfo' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "ItemName": "updates.ItemName", "ItemInfo": "updates.ItemInfo", "ItemID": "updates.ItemID" } ) \ .execute()ディメンションが構築されたので、最後の手順ではファクト テーブルを作成します。
-
新しいコード ブロックで、ファクト テーブルを作成するための次のコードを貼り付けて実行します。
from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.dbo.factsales_gold") \ .addColumn("CustomerID", LongType()) \ .addColumn("ItemID", LongType()) \ .addColumn("OrderDate", DateType()) \ .addColumn("Quantity", IntegerType()) \ .addColumn("UnitPrice", FloatType()) \ .addColumn("Tax", FloatType()) \ .execute() -
新しいコード ブロックで、新しいデータフレームを作成し、売上データを顧客 ID、品目 ID、注文日、数量、単価、税を含む顧客と製品の情報と結合するための次のコードを貼り付けて実行します。
from pyspark.sql.functions import col dfdimCustomer_temp = spark.read.table("Sales.dbo.dimCustomer_gold") dfdimProduct_temp = spark.read.table("Sales.dbo.dimProduct_gold") df = df.withColumn("ItemName",split(col("Item"), ", ").getItem(0)) \ .withColumn("ItemInfo",when((split(col("Item"), ", ").getItem(1).isNull() | (split(col("Item"), ", ").getItem(1)=="")),lit("")).otherwise(split(col("Item"), ", ").getItem(1))) \ # Create Sales_gold dataframe dffactSales_gold = df.alias("df1").join(dfdimCustomer_temp.alias("df2"),(df.CustomerName == dfdimCustomer_temp.CustomerName) & (df.Email == dfdimCustomer_temp.Email), "left") \ .join(dfdimProduct_temp.alias("df3"),(df.ItemName == dfdimProduct_temp.ItemName) & (df.ItemInfo == dfdimProduct_temp.ItemInfo), "left") \ .select(col("df2.CustomerID") \ , col("df3.ItemID") \ , col("df1.OrderDate") \ , col("df1.Quantity") \ , col("df1.UnitPrice") \ , col("df1.Tax") \ ).orderBy(col("df1.OrderDate"), col("df2.CustomerID"), col("df3.ItemID")) # Display the first 10 rows of the dataframe to preview your data display(dffactSales_gold.head(10)) -
次に、新しいコード ブロックで次のコードを実行して、売上データを最新の状態に保つようにします。
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dbo/factsales_gold') dfUpdates = dffactSales_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.OrderDate = updates.OrderDate AND gold.CustomerID = updates.CustomerID AND gold.ItemID = updates.ItemID' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "CustomerID": "updates.CustomerID", "ItemID": "updates.ItemID", "OrderDate": "updates.OrderDate", "Quantity": "updates.Quantity", "UnitPrice": "updates.UnitPrice", "Tax": "updates.Tax" } ) \ .execute()
ここでは、Delta Lake のマージ操作を使用して、factsales_gold テーブルを新しい売上データ (dffactSales_gold) と同期して更新します。 この操作では、注文日、顧客 ID、および項目 ID が既存のデータ (シルバー テーブル) と新しいデータ (更新 DataFrame) の間で比較され、一致するレコードが更新され、必要に応じて新しいレコードが挿入されます。
これで、レポートと分析に使用できるキュレーションおよびモデル化されたゴールド レイヤーが手に入りました。
(省略可能) セマンティック モデルを作成する
これで、ゴールド レイヤーをレポートの作成とデータの分析に使用できるようになりました。 まず、レポート用にリレーションシップとメジャーを定義するセマンティック モデルを作成する必要があります。
注: この省略可能なタスクを完了するには、有料容量に Power BI 機能が含まれている必要があります。または、別の Power BI Pro あるいは Premium Per User ライセンスが必要です。
- ワークスペースで、Sales レイクハウスに移動します。
- エクスプローラー ビューのリボンから [新しいセマンティック モデル] を選択します。
- 名前 Sales_Gold を新しいセマンティック モデルに割り当てます。
- セマンティック モデルに含める変換済のゴールド テーブルを選び、[確認] を選びます。
- dimdate_gold
- dimcustomer_gold
- dimproduct_gold
- factsales_gold
これにより、Fabric でセマンティック モデルが開き、そこで次に示すようにリレーションシップとメジャーを作成できます。
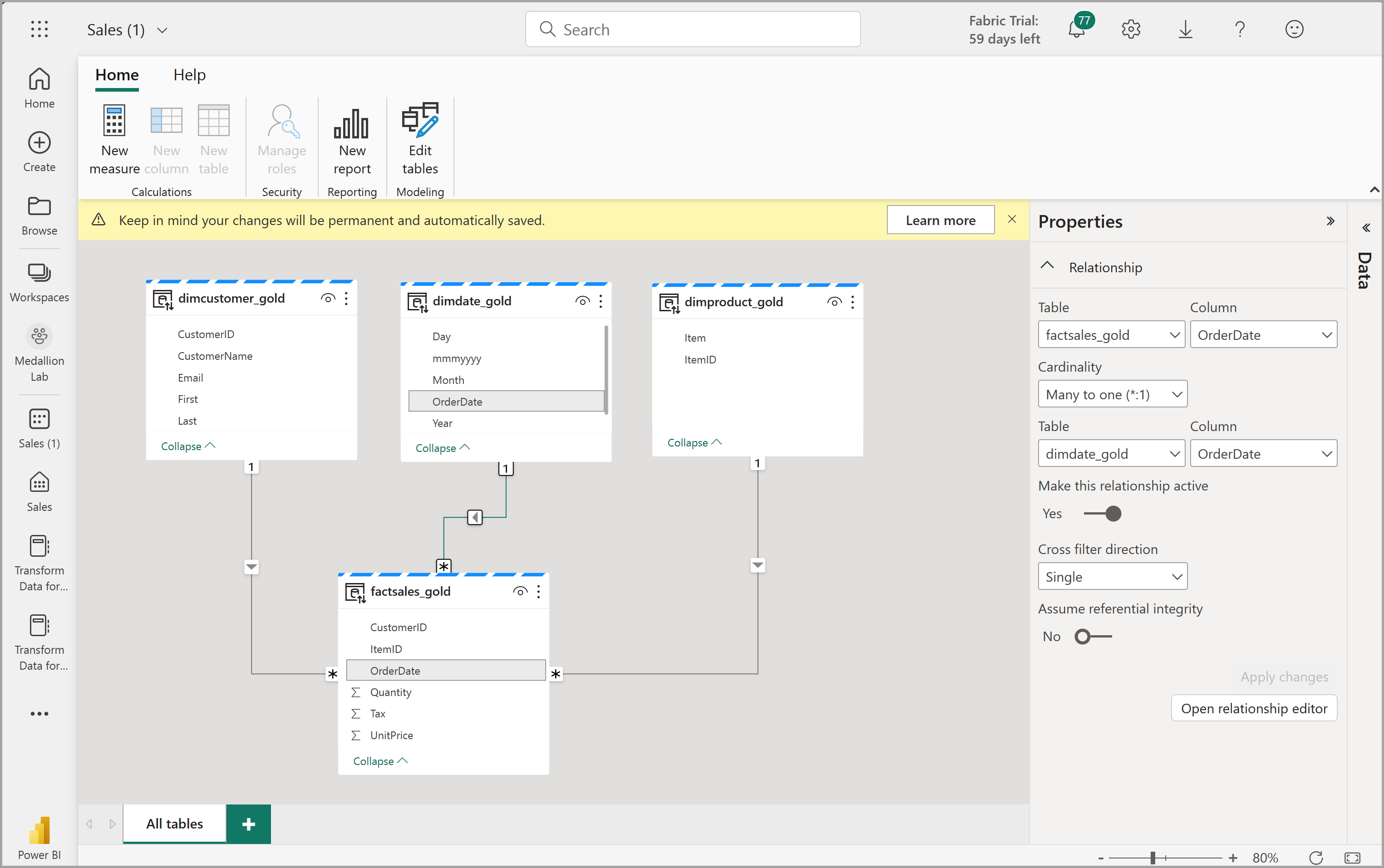
ここから、自分またはデータ チームの他のメンバーが、レイクハウス内のデータに基づいてレポートとダッシュボードを作成できます。 これらのレポートはレイクハウスのゴールド レイヤーに直接接続されるため、常に最新のデータが反映されます。
リソースをクリーンアップする
この演習では、Microsoft Fabric レイクハウスでメダリオン アーキテクチャを作成する方法を学習しました。
レイクハウスの探索が完了したら、この演習用に作成したワークスペースを削除できます。
- 左側のバーで、ワークスペースのアイコンを選択して、それに含まれるすべての項目を表示します。
- ツール バーの […] メニューで、 [ワークスペースの設定] を選択してください。
- [全般] セクションで、[このワークスペースの削除] を選択します。