Utiliser des données dans un eventhouse Microsoft Fabric
Dans Microsoft Fabric, un eventhouse est utilisé pour stocker des données en temps réel liées à des événements, souvent capturées à partir d’une source de données de streaming par un eventstream.
Dans un eventhouse, les données sont stockées dans une ou plusieurs bases de données KQL, chacune contenant des tables et d’autres objets que vous pouvez interroger à l’aide de Langage de requête Kusto (KQL) ou d’un sous-ensemble de langage SQL.
Dans cet exercice, vous allez créer et remplir un eventhouse avec des exemples de données liés aux courses de taxi, puis interroger les données à l’aide de KQL et SQL.
Cet exercice prend environ 25 minutes.
Créer un espace de travail
Avant d’utiliser des données dans Fabric, créez un espace de travail avec la capacité Fabric activée.
- Accédez à la page d’accueil de Microsoft Fabric sur
https://app.fabric.microsoft.com/home?experience=fabricdans un navigateur et connectez-vous avec vos informations d’identification Fabric. - Dans la barre de menus à gauche, sélectionnez Espaces de travail (l’icône ressemble à 🗇).
- Créez un espace de travail avec le nom de votre choix et sélectionnez un mode de licence qui inclut la capacité Fabric (Essai, Premium ou Fabric).
-
Lorsque votre nouvel espace de travail s’ouvre, il doit être vide.
Créer un Eventhouse
Maintenant que vous disposez d’un espace de travail avec prise en charge d’une capacité Fabric, vous pouvez y créer un eventhouse.
- Dans la barre de menus à gauche, sélectionnez Charges de travail. Sélectionnez ensuite la vignette Real-Time Intelligence.
-
Sur la page d’accueil Real-Time Intelligence, sélectionnez la vignette Explorer l’exemple Real-Time Intelligence. Cela crée automatiquement un eventhouse appelé RTISample :
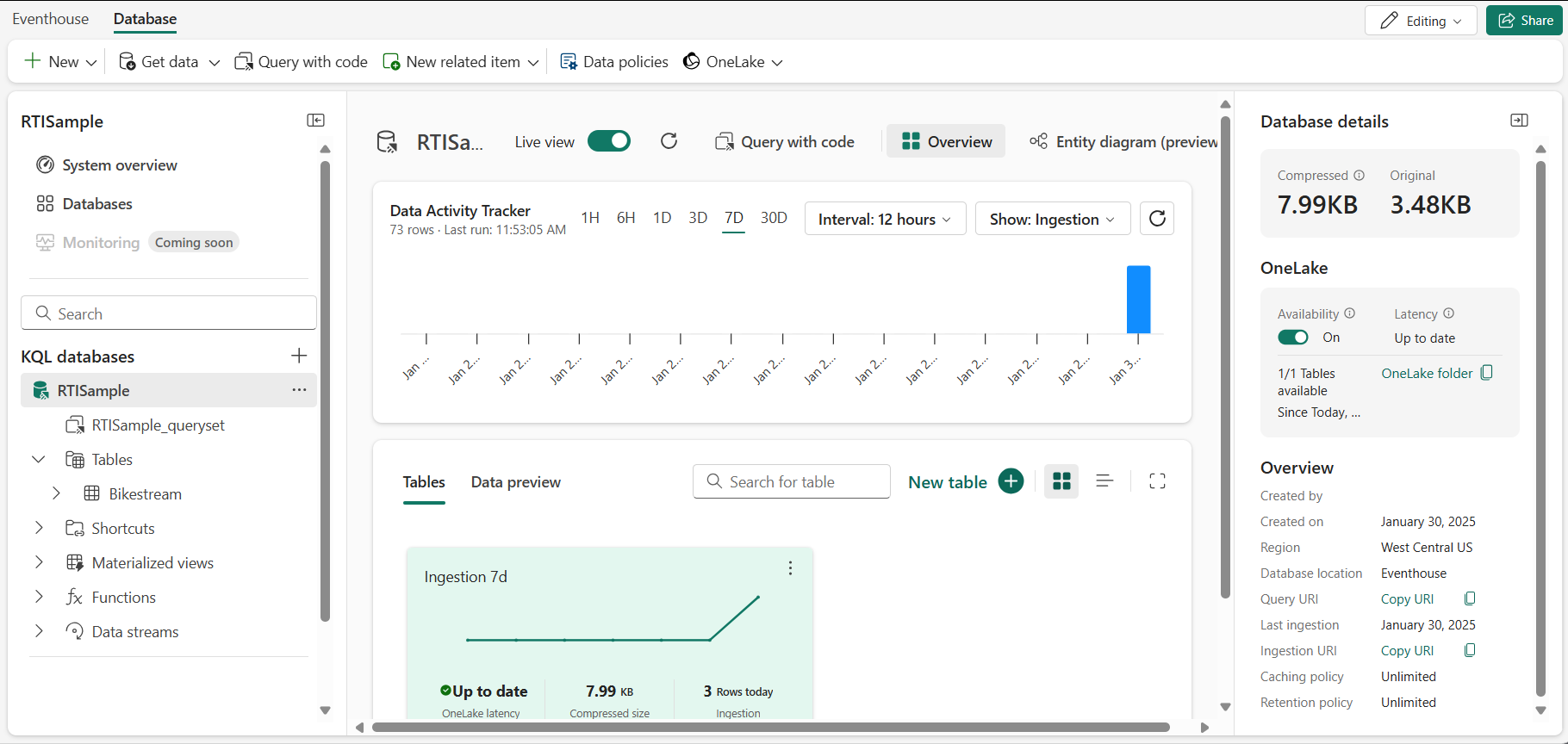
- Dans le volet de gauche, notez que votre eventhouse contient une base de données KQL portant le même nom que l’eventhouse.
- Vérifiez qu’une table Bikestream a également été créée.
Interroger des données à l’aide de KQL
Le langage de requête Kusto (KQL) est un langage intuitif et complet que vous pouvez utiliser pour interroger une base de données KQL.
Récupérer les données d’une table à l’aide de KQL
- Dans le volet gauche de la fenêtre de l’eventhouse, sous votre base de données KQL, sélectionnez le fichier queryset par défaut. Ce fichier contient des exemples de requêtes KQL pour vous aider à démarrer.
-
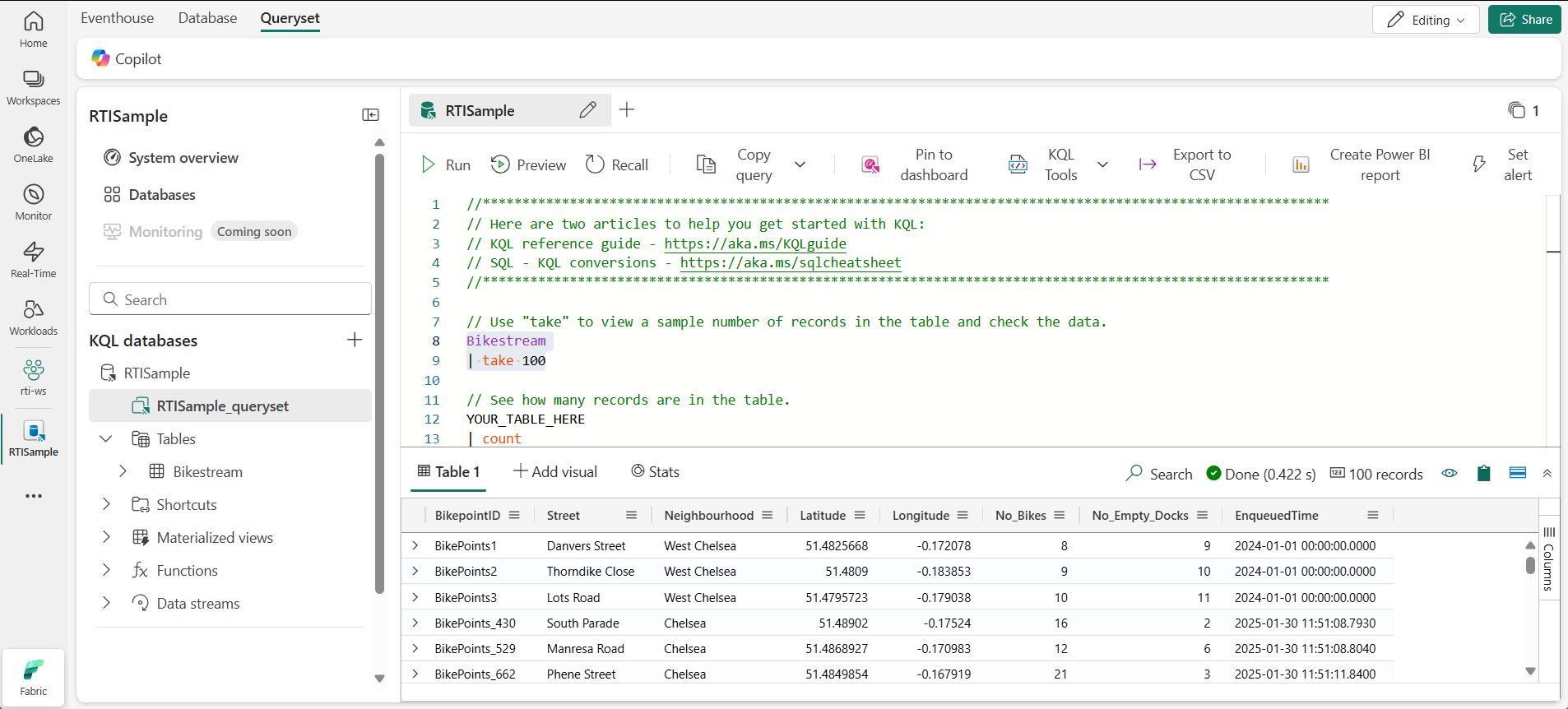
Modifiez le premier exemple de requête comme suit.
Bikestream | take 100REMARQUE : le caractère trait vertical est utilisé à deux fins dans KQL, notamment pour séparer des opérateurs de requête dans une instruction d’expression tabulaire. Il est également utilisé comme opérateur OR logique entre parenthèses carrées ou rondes pour indiquer que vous pouvez spécifier l’un des éléments séparés par le caractère du canal.
-
Sélectionnez le code de requête et exécutez-le pour renvoyer 100 lignes depuis la table.
Vous pouvez être plus précis en ajoutant des attributs spécifiques que vous souhaitez interroger à l’aide du mot clé
project, puis en utilisant le mot clétakepour indiquer au moteur le nombre d’enregistrements à renvoyer. -
Entrez la requête suivante, puis sélectionnez-la et exécutez-la.
// Use 'project' and 'take' to view a sample number of records in the table and check the data. Bikestream | project Street, No_Bikes | take 10REMARQUE : l’utilisation de // désigne un commentaire.
Une autre pratique courante dans l’analyse consiste à renommer des colonnes dans notre ensemble de requêtes pour les rendre plus conviviales.
-
Essayez la requête suivante :
Bikestream | project Street, ["Number of Empty Docks"] = No_Empty_Docks | take 10
Résumer les données à l’aide de KQL
Vous pouvez utiliser le mot clé summarize avec une fonction pour agréger et manipuler des données d’autres façons.
-
Essayez la requête suivante, qui utilise la fonction sum pour résumer les données de location pour voir combien de vélos sont disponibles au total :
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes)Vous pouvez regrouper les données résumées selon une colonne ou une expression spécifiée.
-
Exécutez la requête suivante pour regrouper le nombre de vélos par quartier afin de déterminer la quantité de vélos disponibles dans chaque quartier :
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood, ["Total Number of Bikes"]Si l’un des points de vélo a une entrée nulle ou vide pour le quartier, les résultats du résumé incluront une valeur vide, ce qui n’est jamais bon pour l’analyse.
-
Modifiez la requête comme indiqué ici pour utiliser la fonction case avec les fonctions isempty et isnull pour regrouper tous les trajets pour lesquels le quartier est inconnu dans une catégorie Non identifié pour le suivi.
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]Note : étant donné que cet exemple de jeu de données est bien géré, vous n’avez peut-être pas de champ non identifié dans le résultat de la requête.
Trier les données à l’aide de KQL
Pour donner plus de sens à nos données, nous les trions généralement par colonne, et ce processus est effectué dans KQL avec un opérateur sort by ou order by (ils se comportent de la même façon).
-
Essayez la requête suivante :
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | sort by Neighbourhood asc -
Modifiez la requête comme suit et réexécutez-la, et remarquez que l’opérateur order by fonctionne de la même façon que sort by :
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | order by Neighbourhood asc
Filtrer les données à l’aide de KQL
Dans KQL, la clause where est utilisée pour filtrer les données. Vous pouvez combiner des conditions dans une clause where à l’aide des opérateurs logiques and et or.
-
Exécutez la requête suivante pour filtrer les données de vélo pour inclure uniquement des points de vélo dans le quartier de Chelsea :
Bikestream | where Neighbourhood == "Chelsea" | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | sort by Neighbourhood asc
Interroger les données à l’aide de Transact-SQL
La base de données KQL ne prend pas en charge Transact-SQL de manière native, mais elle fournit un point de terminaison T-SQL qui émule Microsoft SQL Server et vous permet d’exécuter des requêtes T-SQL sur vos données. Le point de terminaison T-SQL présente certaines limitations et différences par rapport au SQL Server natif. Il ne prend par exemple pas en charge la création, la modification ou la suppression de tables, ni l’insertion, la mise à jour ou la suppression de données. Il ne prend pas non plus en charge certaines fonctions et syntaxe T-SQL non compatibles avec KQL. Il a été créé pour permettre aux systèmes (ne prenant pas en charge KQL) d’utiliser T-SQL pour interroger les données au sein d’une base de données KQL. Il est donc recommandé d’utiliser KQL comme langage de requête principal pour une base de données KQL, car il offre davantage de fonctionnalités et de performances que T-SQL. Vous pouvez également utiliser certaines fonctions SQL prises en charge par KQL, telles que count, sum, avg, min, max, etc.
Récupérer des données d’une table à l’aide de Transact-SQL
-
Dans votre ensemble de requêtes, ajoutez et exécutez la requête Transact-SQL suivante :
SELECT TOP 100 * from Bikestream -
Modifiez la requête comme suit pour récupérer des colonnes spécifiques :
SELECT TOP 10 Street, No_Bikes FROM Bikestream -
Modifiez la requête pour attribuer un alias qui renomme No_Empty_Docks en utilisant un nom plus convivial.
SELECT TOP 10 Street, No_Empty_Docks as [Number of Empty Docks] from Bikestream
Résumer les données à l’aide de Transact-SQL
-
Exécutez la requête suivante pour rechercher le nombre total de vélos disponibles :
SELECT sum(No_Bikes) AS [Total Number of Bikes] FROM Bikestream -
Modifiez la requête pour regrouper le nombre total de vélos par quartier :
SELECT Neighbourhood, Sum(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY Neighbourhood -
Modifiez la requête pour utiliser une instruction CASE afin de regrouper les points de vélo avec une origine inconnue dans une catégorie Non identifié pour le suivi.
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END;
Trier les données à l’aide de Transact-SQL
-
Exécutez la requête suivante pour trier les résultats groupés par quartier :
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END ORDER BY Neighbourhood ASC;
Filtrer les données à l’aide de Transact-SQL
-
Exécutez la requête suivante pour filtrer les données groupées afin que seules les lignes avec le quartier « Chelsea » soient incluses dans les résultats :
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END HAVING Neighbourhood = 'Chelsea' ORDER BY Neibourhood ASC;
Nettoyer les ressources
Dans cet exercice, vous avez créé un eventhouse et interrogé les données à l’aide de KQL et SQL.
Lorsque vous avez terminé d’explorer votre base de données KQL, vous pouvez supprimer l’espace de travail que vous avez créé pour cet exercice.
- Dans la barre de gauche, sélectionnez l’icône de votre espace de travail.
- Dans la barre d’outils, sélectionnez Paramètres de l’espace de travail.
- Dans la section Général, sélectionnez Supprimer cet espace de travail.