Prétraiter des données avec Data Wrangler dans Microsoft Fabric
Dans ce labo, vous allez apprendre à utiliser Data Wrangler dans Microsoft Fabric pour prétraiter des données, et générer du code à l’aide d’une bibliothèque d’opérations courantes de science des données.
Ce labo prend environ 30 minutes.
Remarque : Vous devez disposer d’un essai gratuit Microsoft Fabric pour effectuer cet exercice.
Créer un espace de travail
Avant d’utiliser des données dans Fabric, créez un espace de travail avec l’essai gratuit de Fabric activé.
- Accédez à la page d’accueil de Microsoft Fabric sur
https://app.fabric.microsoft.com/home?experience=fabricdans un navigateur et connectez-vous avec vos informations d’identification Fabric. - Dans la barre de menus à gauche, sélectionnez Espaces de travail (l’icône ressemble à 🗇).
- Créez un espace de travail avec le nom de votre choix et sélectionnez un mode de licence qui inclut la capacité Fabric (Essai, Premium ou Fabric).
-
Lorsque votre nouvel espace de travail s’ouvre, il doit être vide.
Créer un notebook
Pour entraîner un modèle, vous pouvez créer un notebook. Les notebooks fournissent un environnement interactif dans lequel vous pouvez écrire et exécuter du code (dans plusieurs langages) en tant qu’expériences.
-
Sélectionnez Créer dans la barre de menus de gauche. Dans la page Nouveau, sous la section Science des données, sélectionnez Notebook. Donnez-lui un nom unique de votre choix.
Note : si l’option Créer n’est pas épinglée à la barre latérale, vous devez d’abord sélectionner l’option avec des points de suspension (…).
Après quelques secondes, un nouveau notebook contenant une seule cellule s’ouvre. Les notebooks sont constitués d’une ou plusieurs cellules qui peuvent contenir du code ou du Markdown (texte mis en forme).
-
Sélectionnez la première cellule (qui est actuellement une cellule de code) puis, dans la barre d’outils dynamique en haut à droite, utilisez le bouton M↓ pour convertir la cellule en cellule Markdown.
Lorsque la cellule devient une cellule Markdown, le texte qu’elle contient est affiché.
-
Si nécessaire, utilisez le bouton 🖉 (Modifier) pour basculer la cellule en mode d’édition, puis supprimez le contenu et entrez le texte suivant :
# Perform data exploration for data science Use the code in this notebook to perform data exploration for data science.
Charger des données dans un DataFrame
Vous êtes maintenant prêt à exécuter du code pour obtenir des données. Vous allez utiliser le jeu de données OJ Sales à partir d’Azure Open Datasets. Après avoir chargé les données, vous allez convertir les données en dataframe Pandas, qui est la structure prise en charge par Data Wrangler.
-
Dans votre bloc-notes, utilisez l’icône + Code sous la dernière cellule pour ajouter une nouvelle cellule de code au bloc-notes.
Conseil : pour afficher l’icône + Code , déplacez la souris juste en dessous et à gauche de la sortie de la cellule active. Sinon, dans la barre de menus, sous l’onglet Modifier, sélectionnez + Ajouter une cellule de code.
-
Entrez le code suivant pour charger le jeu de données dans un dataframe.
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "ojsales-simulatedcontainer" blob_relative_path = "oj_sales_data" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark reads csv df = spark.read.csv(wasbs_path, header=True) -
Utilisez le bouton ▷ Exécuter la cellule à gauche de la cellule pour l’exécuter. Vous pouvez également appuyer
SHIFT+ENTERsur votre clavier pour exécuter une cellule.Remarque : Comme c’est la première fois que vous exécutez du code Spark dans cette session, le pool Spark doit être démarré. Cela signifie que la première exécution dans la session peut prendre environ une minute. Les exécutions suivantes seront plus rapides.
-
Utilisez l’icône + Code sous la sortie de cellule pour ajouter une nouvelle cellule de code au notebook, puis entrez le code suivant :
import pandas as pd df = df.toPandas() df = df.sample(n=500, random_state=1) df['WeekStarting'] = pd.to_datetime(df['WeekStarting']) df['Quantity'] = df['Quantity'].astype('int') df['Advert'] = df['Advert'].astype('int') df['Price'] = df['Price'].astype('float') df['Revenue'] = df['Revenue'].astype('float') df = df.reset_index(drop=True) df.head(4) -
Une fois la commande de la cellule exécutée, examinez la sortie sous la cellule, qui doit être similaire à ceci :
WeekStarting Magasin Marque Quantité Publication Price Chiffre d’affaires 0 1991-10-17 947 minute.maid 13306 1 2,42 32200,52 1 1992-03-26 1293 dominicks 18596 1 1,94 36076,24 2 1991-08-15 2278 dominicks 17457 1 2.14 37357,98 3 1992-09-03 2175 tropicana 9652 1 2,07 19979,64 … … … … … … … … La sortie affiche les quatre premières lignes du jeu de données OJ Sales.
Afficher des statistiques récapitulatives
Maintenant que nous avons chargé les données, l’étape suivante consiste à les prétraiter à l’aide de Data Wrangler. Le prétraitement est une étape cruciale dans tout flux de travail de Machine Learning. Il implique de nettoyer les données et de les transformer dans un format qui peut être alimenté dans un modèle Machine Learning.
-
Sélectionnez Données dans le ruban du notebook, puis la liste déroulante Lancer Data Wrangler.
-
Sélectionnez le jeu de données
df. Lorsque Data Wrangler est lancé, il génère une vue d’ensemble descriptive du dataframe dans le panneau Résumé. -
Sélectionnez la fonctionnalité Revenu, et observez la distribution de données de cette fonctionnalité.
-
Passez en revue les détails du panneau latéral Résumé et observez les valeurs des statistiques.
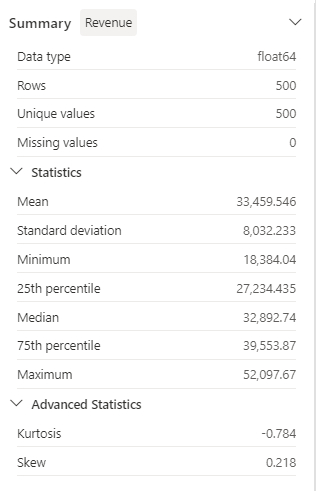
Quels sont les informations que vous pouvez en tirer ? Le revenu moyen est d’environ 33 459,54 $ , avec un écart type de 8 032,23 $ . Cela suggère que les valeurs des revenus sont réparties sur une plage d’environ 8 032,23 $ par rapport à la moyenne.
Mettre en forme des données de texte
Appliquons maintenant quelques transformations à la caractéristique Brand.
-
Dans le tableau de bord Data Wrangler, sélectionnez la fonctionnalité
Branddans la grille. -
Accédez au panneau Opérations, développez Rechercher et remplacer, puis sélectionnez Rechercher et remplacer.
-
Dans le panneau Rechercher et remplacer, modifiez les propriétés suivantes :
- Ancienne valeur : «
.» - Nouvelle valeur : «
Les résultats de l’opération sont affichés automatiquement dans la grille d’affichage.
- Ancienne valeur : «
-
Sélectionnez Appliquer.
-
Revenez au panneau Opérations et développez Format.
-
Sélectionnez Mettre en majuscules le premier caractère. Activez le bouton bascule Mettre en majuscules tous les mots, puis sélectionnez Appliquer.
-
Sélectionnez Ajouter du code au notebook. En outre, vous pouvez également copier le code et enregistrer le jeu de données transformé en tant que fichier .csv.
Remarque : le code est automatiquement copié dans la cellule du notebook, il est prêt à être utilisé.
-
Remplacez les lignes 10 et 11 par le code
df = clean_data(df), car le code généré dans Data Wrangler ne remplace pas le dataframe d’origine. Le bloc de code final devrait ressembler à ceci :def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() return df df = clean_data(df) -
Exécutez la cellule de code et observez la variable
Brand.df['Brand'].unique()Le résultat doit afficher les valeurs Minute Maid, Dominicks et Tropicana.
Vous avez appris à manipuler graphiquement des données de texte et à générer facilement du code à l’aide de Data Wrangler.
Appliquer une transformation de codage à chaud
À présent, nous allons générer le code pour appliquer la transformation d’encodage à chaud à nos données dans le cadre de nos étapes de prétraitement. Pour rendre notre scénario plus pratique, nous commençons par générer des exemples de données. Cela nous permet de simuler une situation réelle et nous fournit une fonctionnalité utilisable.
-
Lancez Data Wrangler dans le menu supérieur du dataframe
df. -
Sélectionnez la fonctionnalité
Branddans la grille. -
Dans le panneau Opérations, développez Formules, puis sélectionnez Encoder à chaud.
-
Dans le panneau Encodeur à chaud, sélectionnez Appliquer.
Accédez à la fin de la grille d’affichage Data Wrangler. Notez que trois nouvelles fonctionnalités ont été ajoutées (
Brand_Dominicks,Brand_Minute MaidetBrand_Tropicana) et que la fonctionnalitéBranda été supprimée. -
Quittez Data Wrangler sans générer le code.
Opérations de tri et de filtrage
Imaginez que nous devons passer en revue les données de chiffre d’affaires d’un magasin spécifique, puis trier les prix des produits. Dans les étapes suivantes, nous utilisons Data Wrangler pour filtrer et analyser le dataframe df.
-
Lancez Data Wrangler pour le dataframe
df. -
Dans le panneau Opérations, développez Trier et filtrer.
-
Cliquez sur Filtrer.
-
Dans le panneau Filtre, ajoutez la condition suivante :
- Colonne cible :
Store - Opération :
Equal to - Valeur :
1227 - Action :
Keep matching rows
- Colonne cible :
-
Sélectionnez Appliquer, et observez les modifications apportées à la grille d’affichage de Data Wrangler.
-
Sélectionnez la fonctionnalité Revenu, puis passez en revue les détails du panneau latéral Résumé.
Quels sont les informations que vous pouvez en tirer ? L’asymétrie est de -0,751, ce qui indique une légère asymétrie gauche (asymétrie négative). Cela signifie que la traîne gauche de la distribution est légèrement plus longue que la traîne droite. En d’autres termes, il y a un certain nombre de périodes où les revenus sont nettement inférieurs à la moyenne.
-
De retour au panneau Opérations, développez Trier et filtrer.
-
Sélectionner Trier les valeurs.
-
Dans le panneau Trier les valeurs, sélectionnez les propriétés suivantes :
- Nom de la colonne :
Price - Ordre de tri :
Descending
- Nom de la colonne :
-
Sélectionnez Appliquer.
Le prix de produit le plus élevé pour le magasin 1227 est de 2,68 $ . Avec seulement quelques enregistrements, il est plus facile d’identifier le prix du produit le plus élevé, mais tenez compte de la complexité lorsque vous traitez des milliers de résultats.
Parcourir et supprimer les étapes
Supposez que vous avez commis une erreur et que vous devez supprimer le tri créé à l’étape précédente. Suivez ces étapes pour la supprimer :
-
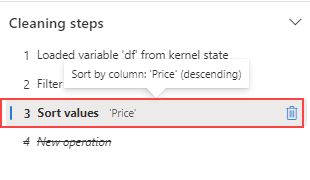
Accédez au panneau Étapes de nettoyage.
-
Sélectionnez l’étape Trier les valeurs.
-
Sélectionnez l’icône de suppression pour supprimer l’étape.
Important : L’affichage de grille et le résumé sont limités à l’étape actuelle.
Notez que les modifications sont rétablies à l’étape précédente, Filtrer.
-
Quittez Data Wrangler sans générer le code.
Données agrégées
Supposons que nous voulons comprendre le chiffre d’affaires moyen généré par chaque marque. Dans les étapes suivantes, nous utilisons Data Wrangler pour effectuer une opération « grouper par » sur le dataframe df.
-
Lancez Data Wrangler pour le dataframe
df. -
De retour au panneau Opérations, sélectionnez Regrouper et agréger.
-
Dans le panneau Colonnes de regroupement : , sélectionnez la caractéristique
Brand. -
Sélectionnez Ajouter une agrégation.
-
Dans la propriété Colonne à agréger, sélectionnez la caractéristique
Revenue. -
Sélectionnez
Meanpour la propriété Type d’agrégation. -
Sélectionnez Appliquer.
-
Sélectionnez Copier le code dans le Presse-papiers.
-
Quittez Data Wrangler sans générer le code.
-
Combinez le code de la transformation de la variable
Brandavec le code généré par l’étape d’agrégation dans la fonctionclean_data(df). Le bloc de code final devrait ressembler à ceci :def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() # Performed 1 aggregation grouped on column: 'Brand' df = df.groupby(['Brand']).agg(Revenue_mean=('Revenue', 'mean')).reset_index() return df df = clean_data(df) -
Exécutez le code de cellule.
-
Vérifiez les données dans le dataframe.
print(df)Résultats :
Marque Revenue_mean 0 Dominicks 33206,330958 1 Minute Maid 33532,999632 2 Tropicana 33637,863412
Vous avez généré le code pour certaines des opérations de prétraitement, et vous avez recopié le code dans le notebook en tant que fonction, que vous pouvez ensuite exécuter, réutiliser ou modifier en fonction des besoins.
Enregistrer le notebook et mettre fin à la session Spark
Maintenant que vous avez terminé d’utiliser les données, vous pouvez enregistrer le notebook avec un nom explicite et mettre fin à la session Spark.
- Dans la barre de menus du notebook, utilisez l’icône ⚙️ Paramètres pour afficher les paramètres du notebook.
- Définissez Prétraiter des données avec Data Wrangler comme Nom du notebook, puis fermez le volet des paramètres.
- Dans le menu du notebook, sélectionnez Arrêter la session pour mettre fin à la session Spark.
Nettoyer les ressources
Dans cet exercice, vous avez créé un notebook et utilisé Data Wrangler pour explorer et prétraiter des données pour un modèle Machine Learning.
Si vous avez terminé d’explorer les étapes de prétraitement, vous pouvez supprimer l’espace de travail que vous avez créé pour cet exercice.
- Dans la barre de gauche, sélectionnez l’icône de votre espace de travail pour afficher tous les éléments qu’il contient.
- Dans le menu … de la barre d’outils, sélectionnez Paramètres de l’espace de travail.
- Dans la section Général, sélectionnez Supprimer cet espace de travail.