Charger des données dans un entrepôt en utilisant T-SQL
Dans Microsoft Fabric, un entrepôt de données fournit une base de données relationnelle pour l’analytique à grande échelle. Contrairement au point de terminaison SQL en lecture seule par défaut pour les tables définies dans un lakehouse, un entrepôt de données fournit une sémantique SQL complète, y compris la possibilité d’insérer, de mettre à jour et de supprimer des données dans les tables.
Ce labo prend environ 30 minutes.
Remarque : Vous devez disposer d’un essai gratuit Microsoft Fabric pour effectuer cet exercice.
Créer un espace de travail
Avant d’utiliser des données dans Fabric, créez un espace de travail avec l’essai gratuit de Fabric activé.
- Accédez à la page d’accueil de Microsoft Fabric sur
https://app.fabric.microsoft.com/home?experience=fabricdans un navigateur et connectez-vous avec vos informations d’identification Fabric. - Dans la barre de menus à gauche, sélectionnez Espaces de travail (l’icône ressemble à 🗇).
- Créez un espace de travail avec le nom de votre choix et sélectionnez un mode de licence qui inclut la capacité Fabric (Essai, Premium ou Fabric).
-
Lorsque votre nouvel espace de travail s’ouvre, il doit être vide.
Créer un lakehouse et charger des fichiers
Dans notre scénario, comme nous n’avons pas de données disponibles, nous devons ingérer des données à utiliser pour le chargement de l’entrepôt. Vous allez créer un data lakehouse pour les fichiers de données que vous allez utiliser pour charger l’entrepôt.
-
Sélectionnez + Nouvel élément et créez un lakehouse avec le nom de votre choix.
Au bout d’une minute environ, un nouveau lakehouse vide est créé. Vous devez ingérer certaines données dans le data lakehouse à des fins d’analyse. Il existe plusieurs façons de faire cela, mais dans cet exercice, vous allez télécharger un fichier CSV sur votre ordinateur local (ou le cas échéant, sur votre machine virtuelle de labo), puis le charger dans votre lakehouse.
-
Téléchargez le fichier pour cet exercice depuis
https://github.com/MicrosoftLearning/dp-data/raw/main/sales.csv. -
Revenez à l’onglet du navigateur web contenant votre lakehouse puis, dans le menu … du dossier Fichiers dans le volet Explorateur, sélectionnez Charger et Charger les fichiers, puis chargez le fichier sales.csv depuis votre ordinateur local (ou le cas échéant, depuis votre machine virtuelle de labo) dans le lakehouse.
-
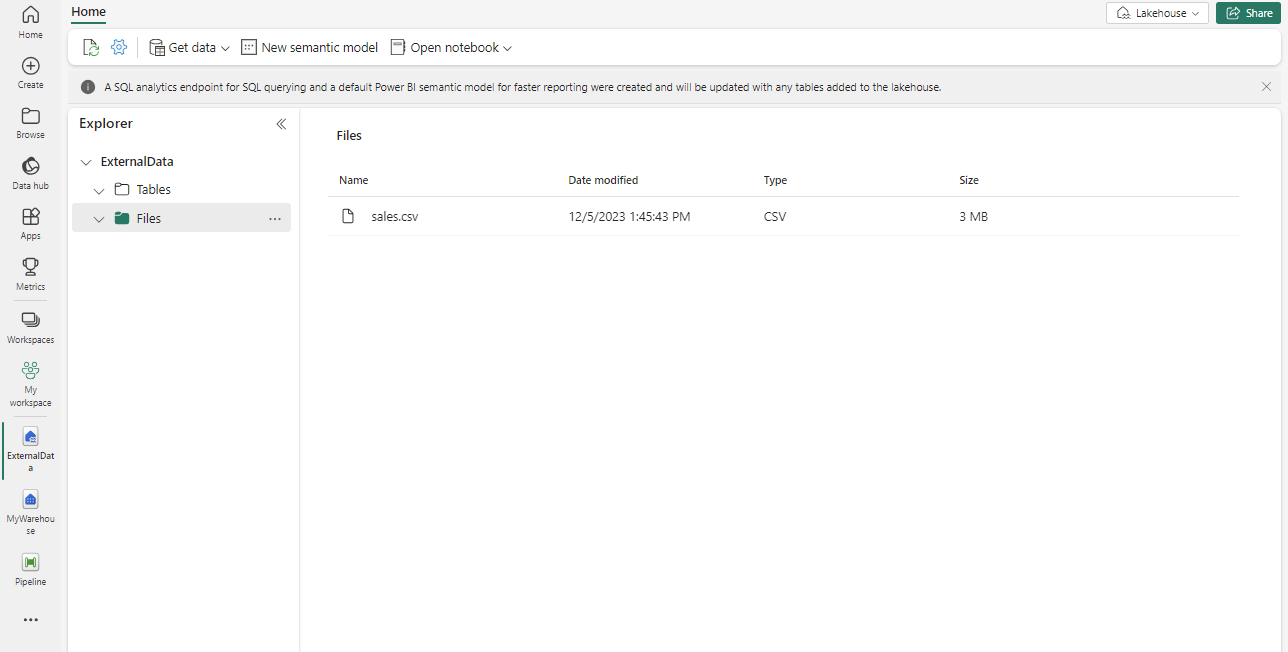
Une fois les fichiers chargés, sélectionnez Fichiers. Vérifiez que le fichier CSV a été chargé, comme indiqué ici :
Créer une table dans le lakehouse
-
Dans le menu … pour le fichier sales.csv dans le volet Explorateur, sélectionnez Charger dans des tables, puis Nouvelle table.
- Spécifiez les informations suivantes dans la boîte de dialogue Charger le fichier dans une nouvelle table.
- Nom de la nouvelle table : staging_sales
- Utiliser l’en-tête pour les noms de colonnes : Sélectionné
- Séparateur : ,
- Sélectionnez Charger.
Créer un entrepôt
Maintenant que vous disposez d’un espace de travail, d’un lakehouse et de la table des ventes avec les données dont vous avez besoin, c’est le moment de créer un entrepôt de données.
-
Sélectionnez Créer dans la barre de menus de gauche. Dans la page Nouveau, sous la section Entrepôt de données, sélectionnez Entrepôt. Donnez-lui un nom unique de votre choix.
Note : si l’option Créer n’est pas épinglée à la barre latérale, vous devez d’abord sélectionner l’option avec des points de suspension (…).
Au bout d’une minute environ, un nouvel entrepôt est créé :
Créer une table de faits, des dimensions et une vue
Créons les tables de faits et les dimensions pour les données de ventes (Sales). Vous allez également créer une vue pointant vers un lakehouse, ce qui simplifie le code de la procédure stockée que nous allons utiliser pour charger.
-
Dans votre espace de travail, sélectionnez l’entrepôt que vous avez créé.
-
Dans la barre d’outils de l’entrepôt, sélectionnez Nouvelle requête SQL, puis copiez et exécutez la requête suivante.
CREATE SCHEMA [Sales] GO IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Fact_Sales' AND SCHEMA_NAME(schema_id)='Sales') CREATE TABLE Sales.Fact_Sales ( CustomerID VARCHAR(255) NOT NULL, ItemID VARCHAR(255) NOT NULL, SalesOrderNumber VARCHAR(30), SalesOrderLineNumber INT, OrderDate DATE, Quantity INT, TaxAmount FLOAT, UnitPrice FLOAT ); IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Dim_Customer' AND SCHEMA_NAME(schema_id)='Sales') CREATE TABLE Sales.Dim_Customer ( CustomerID VARCHAR(255) NOT NULL, CustomerName VARCHAR(255) NOT NULL, EmailAddress VARCHAR(255) NOT NULL ); ALTER TABLE Sales.Dim_Customer add CONSTRAINT PK_Dim_Customer PRIMARY KEY NONCLUSTERED (CustomerID) NOT ENFORCED GO IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Dim_Item' AND SCHEMA_NAME(schema_id)='Sales') CREATE TABLE Sales.Dim_Item ( ItemID VARCHAR(255) NOT NULL, ItemName VARCHAR(255) NOT NULL ); ALTER TABLE Sales.Dim_Item add CONSTRAINT PK_Dim_Item PRIMARY KEY NONCLUSTERED (ItemID) NOT ENFORCED GOImportant : Dans un entrepôt de données, les contraintes de clé étrangère ne sont pas toujours nécessaires au niveau de la table. Bien que les contraintes de clé étrangère aident à garantir l’intégrité des données, elles peuvent aussi ajouter une charge de travail supplémentaire au processus ETL (Extraction, Transformation et Chargement) et ralentir le chargement des données. La décision d’utiliser des contraintes de clé étrangère dans un entrepôt de données doit être basée sur un examen attentif des compromis nécessaires entre l’intégrité des données et les performances.
-
Dans l’Explorateur, accédez à Schémas » Sales » Tables.. Notez la présence des tables Fact_Sales, Dim_Customeret Dim_Item que vous venez de créer.
Note : si vous ne voyez pas les nouveaux schémas, ouvrez le menu … pour les tables dans le volet Explorateur, puis sélectionnez Actualiser.
-
Ouvrez un nouvel éditeur Nouvelle requête SQL, puis copiez et exécutez la requête suivante. Mettez à jour *
* avec le lakehouse que vous avez créé. CREATE VIEW Sales.Staging_Sales AS SELECT * FROM [<your lakehouse name>].[dbo].[staging_sales]; -
Dans l’Explorateur, accédez à Schémas » Sales » Vues.. Notez la présence de la vue Staging_Sales que vous avez créée.
Charger des données dans l’entrepôt
Maintenant que les tables de faits et de dimensions sont créées, créons une procédure stockée pour charger les données de notre lakehouse dans l’entrepôt. Grâce au point de terminaison SQL automatique créé quand nous créons le lakehouse, vous pouvez accéder directement aux données de votre lakehouse depuis l’entrepôt en utilisant T-SQL et des requêtes entre bases de données.
Par souci de simplicité dans cette étude de cas, vous allez utiliser le nom de client et le nom d’article comme clés primaires.
-
Créez un nouvel éditeur Nouvelle requête SQL, puis copiez et exécutez la requête suivante.
CREATE OR ALTER PROCEDURE Sales.LoadDataFromStaging (@OrderYear INT) AS BEGIN -- Load data into the Customer dimension table INSERT INTO Sales.Dim_Customer (CustomerID, CustomerName, EmailAddress) SELECT DISTINCT CustomerName, CustomerName, EmailAddress FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear AND NOT EXISTS ( SELECT 1 FROM Sales.Dim_Customer WHERE Sales.Dim_Customer.CustomerName = Sales.Staging_Sales.CustomerName AND Sales.Dim_Customer.EmailAddress = Sales.Staging_Sales.EmailAddress ); -- Load data into the Item dimension table INSERT INTO Sales.Dim_Item (ItemID, ItemName) SELECT DISTINCT Item, Item FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear AND NOT EXISTS ( SELECT 1 FROM Sales.Dim_Item WHERE Sales.Dim_Item.ItemName = Sales.Staging_Sales.Item ); -- Load data into the Sales fact table INSERT INTO Sales.Fact_Sales (CustomerID, ItemID, SalesOrderNumber, SalesOrderLineNumber, OrderDate, Quantity, TaxAmount, UnitPrice) SELECT CustomerName, Item, SalesOrderNumber, CAST(SalesOrderLineNumber AS INT), CAST(OrderDate AS DATE), CAST(Quantity AS INT), CAST(TaxAmount AS FLOAT), CAST(UnitPrice AS FLOAT) FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear; END -
Créez un nouvel éditeur Nouvelle requête SQL, puis copiez et exécutez la requête suivante.
EXEC Sales.LoadDataFromStaging 2021Remarque : Dans le cas présent, nous chargeons seulement les données de l’année 2021. Cependant, vous avez la possibilité de la modifier pour charger des données des années précédentes.
Exécuter des requêtes analytiques
Exécutons des requêtes analytiques pour vérifier les données de l’entrepôt.
-
Dans le menu du haut, sélectionnez Nouvelle requête SQL, puis copiez et exécutez la requête suivante.
SELECT c.CustomerName, SUM(s.UnitPrice * s.Quantity) AS TotalSales FROM Sales.Fact_Sales s JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID WHERE YEAR(s.OrderDate) = 2021 GROUP BY c.CustomerName ORDER BY TotalSales DESC;Remarque : Cette requête montre les clients par ventes totales pour l’année 2021. Le client ayant le total des ventes le plus élevé pour l’année spécifiée est Jordan Turner, avec des ventes totales de 14686,69.
-
Dans le menu du haut, sélectionnez Nouvelle requête SQL ou réutilisez le même éditeur, puis copiez et exécutez la requête suivante.
SELECT i.ItemName, SUM(s.UnitPrice * s.Quantity) AS TotalSales FROM Sales.Fact_Sales s JOIN Sales.Dim_Item i ON s.ItemID = i.ItemID WHERE YEAR(s.OrderDate) = 2021 GROUP BY i.ItemName ORDER BY TotalSales DESC;Remarque : Cette requête montre les articles les plus vendus par ventes totales pour l’année 2021. Ces résultats suggèrent que le modèle Mountain-200 bike, à la fois en noir et en argent, était l’élément le plus demandé parmi les clients en 2021.
-
Dans le menu du haut, sélectionnez Nouvelle requête SQL ou réutilisez le même éditeur, puis copiez et exécutez la requête suivante.
WITH CategorizedSales AS ( SELECT CASE WHEN i.ItemName LIKE '%Helmet%' THEN 'Helmet' WHEN i.ItemName LIKE '%Bike%' THEN 'Bike' WHEN i.ItemName LIKE '%Gloves%' THEN 'Gloves' ELSE 'Other' END AS Category, c.CustomerName, s.UnitPrice * s.Quantity AS Sales FROM Sales.Fact_Sales s JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID JOIN Sales.Dim_Item i ON s.ItemID = i.ItemID WHERE YEAR(s.OrderDate) = 2021 ), RankedSales AS ( SELECT Category, CustomerName, SUM(Sales) AS TotalSales, ROW_NUMBER() OVER (PARTITION BY Category ORDER BY SUM(Sales) DESC) AS SalesRank FROM CategorizedSales WHERE Category IN ('Helmet', 'Bike', 'Gloves') GROUP BY Category, CustomerName ) SELECT Category, CustomerName, TotalSales FROM RankedSales WHERE SalesRank = 1 ORDER BY TotalSales DESC;Remarque : Les résultats de cette requête montrent le plus gros client pour chacune des catégories : Bike (Vélo), Helmet (Casque) et Gloves (Gants) en fonction de leurs ventes totales. Par exemple, Joan Coleman est le premier client de la catégorie Gants.
Les informations de catégorie ont été extraites de la colonne
ItemNameen utilisant une manipulation de chaîne, car il n’existe pas de colonne de catégorie distincte dans la table de dimension. Cette approche suppose que les noms des articles suivent une convention de nommage cohérente. Si les noms des articles ne suivent pas une convention de nommage cohérente, les résultats peuvent ne pas refléter avec exactitude la véritable catégorie de chaque article.
Dans cet exercice, vous avez créé un lakehouse et un entrepôt de données avec plusieurs tables. Vous avez ingéré des données et utilisé des requêtes entre bases de données pour charger les données du lakehouse vers l’entrepôt. En outre, vous avez utilisé l’outil de requête pour effectuer des requêtes analytiques.
Nettoyer les ressources
Si vous avez terminé d’explorer votre entrepôt de données, vous pouvez supprimer l’espace de travail que vous avez créé pour cet exercice.
- Dans la barre de gauche, sélectionnez l’icône de votre espace de travail pour afficher tous les éléments qu’il contient.
- Sélectionnez Paramètres de l’espace de travail et, dans la sectionGénéral, faites défiler vers le bas et sélectionnez Supprimer cet espace de travail.
- Sélectionnez Supprimer pour supprimer l’espace de travail.