Analyser des données avec Apache Spark dans Fabric
Dans ce labo, vous allez ingérer des données dans le lakehouse Fabric et utiliser PySpark pour lire et analyser les données.
Ce labo prend environ 45 minutes.
Prérequis
Créer un espace de travail
Avant de pouvoir utiliser des données dans Fabric, vous devez créer un espace de travail.
- Accédez à la page d’accueil de Microsoft Fabric sur
https://app.fabric.microsoft.com/home?experience=fabricdans un navigateur et connectez-vous avec vos informations d’identification Fabric. - Dans la barre de navigation de gauche, sélectionnez Espaces de travail ** (🗇), puis **Nouvel espace de travail.
- Nommez le nouvel espace de travail et, dans la section Avancé, sélectionnez le mode de licence approprié. Si vous avez démarré une version d’évaluation de Microsoft Fabric, sélectionnez Version d’évaluation.
-
Sélectionnez Appliquer pour créer et ouvrir l’espace de travail.
Créer un lakehouse et charger des fichiers
Maintenant que vous disposez d’un espace de travail, vous pouvez créer un lakehouse pour vos fichiers de données. Dans votre nouvel espace de travail, sélectionnez + Nouvel élément et Lakehouse. Nommez le lakehouse, puis sélectionnez Créer. Après un court délai, un nouveau lakehouse est créé.
Vous pouvez désormais ingérer des données dans le lakehouse. Il existe plusieurs façons de procéder, mais vous allez pour le moment télécharger un dossier de fichiers texte de votre ordinateur local (ou machine virtuelle de labo le cas échéant), puis les charger dans votre lakehouse.
- Téléchargez tous les fichiers de données à partir de
https://github.com/MicrosoftLearning/dp-data/raw/main/orders.zip. - Extrayez l’archive compressée et vérifiez que vous disposez d’un dossier nommé orders qui contient trois fichiers CSV : 2019.csv, 2020.csv et 2021.csv.
- Revenez à votre nouveau lakehouse. Dans le volet Explorateur, en regard du dossier Fichiers, sélectionnez le menu …, puis sélectionnez Charger et Charger le dossier. Accédez au dossier orders sur votre ordinateur local (ou machine virtuelle de labo le cas échéant) et sélectionnez Charger.
-
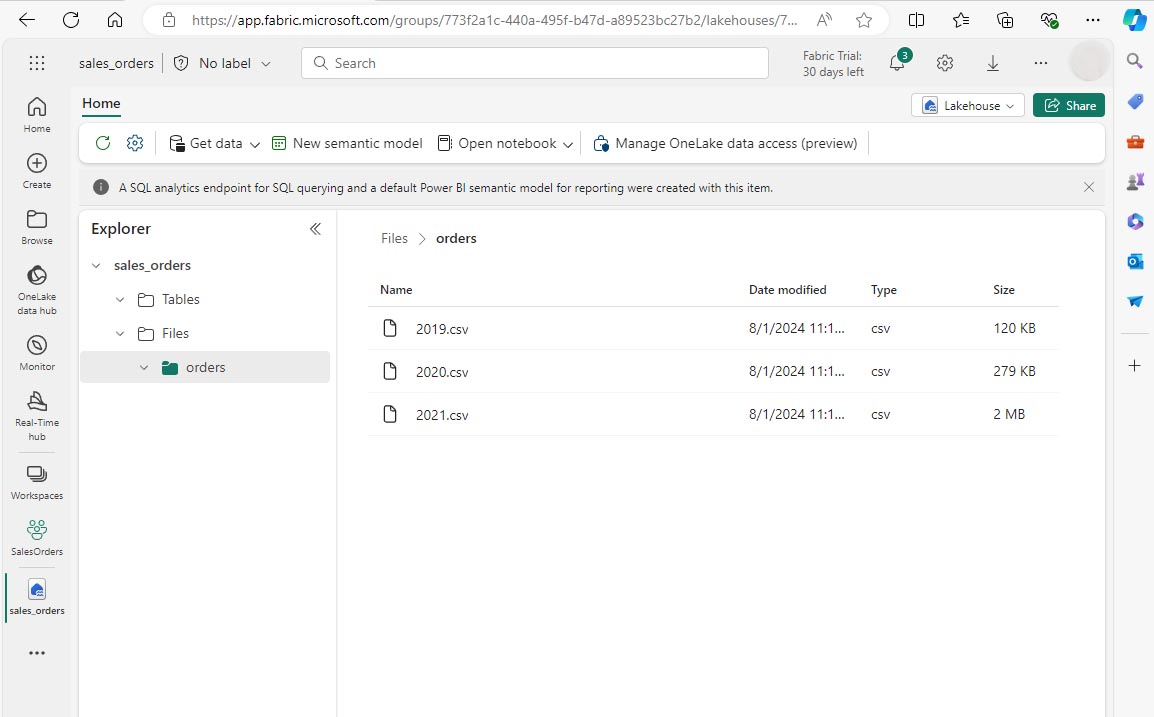
Une fois les fichiers chargés, développez Files et sélectionnez le dossier orders. Vérifiez que les fichiers CSV ont été chargés, comme indiqué ici :
Créer un notebook
Vous pouvez maintenant créer un notebook Fabric pour utiliser vos données. Les notebooks fournissent un environnement interactif dans lequel vous pouvez écrire et exécuter du code (dans plusieurs langues).
- Sélectionnez votre espace de travail, puis sélectionnez + Nouvel élément et Notebook. Après quelques secondes, un nouveau notebook contenant une seule cellule s’ouvre. Les notebooks sont constitués d’une ou plusieurs cellules qui peuvent contenir du code ou du Markdown (texte mis en forme).
- Fabric attribue un nom à chaque notebook que vous créez, tel que Notebook 1, Notebook 2, etc. Cliquez sur le panneau de noms au-dessus de l’onglet Accueil du menu pour remplacer le nom par quelque chose de plus descriptif.
- Sélectionnez la première cellule (qui est actuellement une cellule de code) puis, dans la barre d’outils en haut à droite, utilisez le bouton M↓ pour convertir la cellule en cellule Markdown. Le texte contenu dans la cellule s’affiche alors sous forme de texte mis en forme.
-
Utilisez le bouton 🖉 (Modifier) pour placer la cellule en mode édition, puis modifiez le balisage Markdown comme suit.
# Sales order data exploration Use this notebook to explore sales order data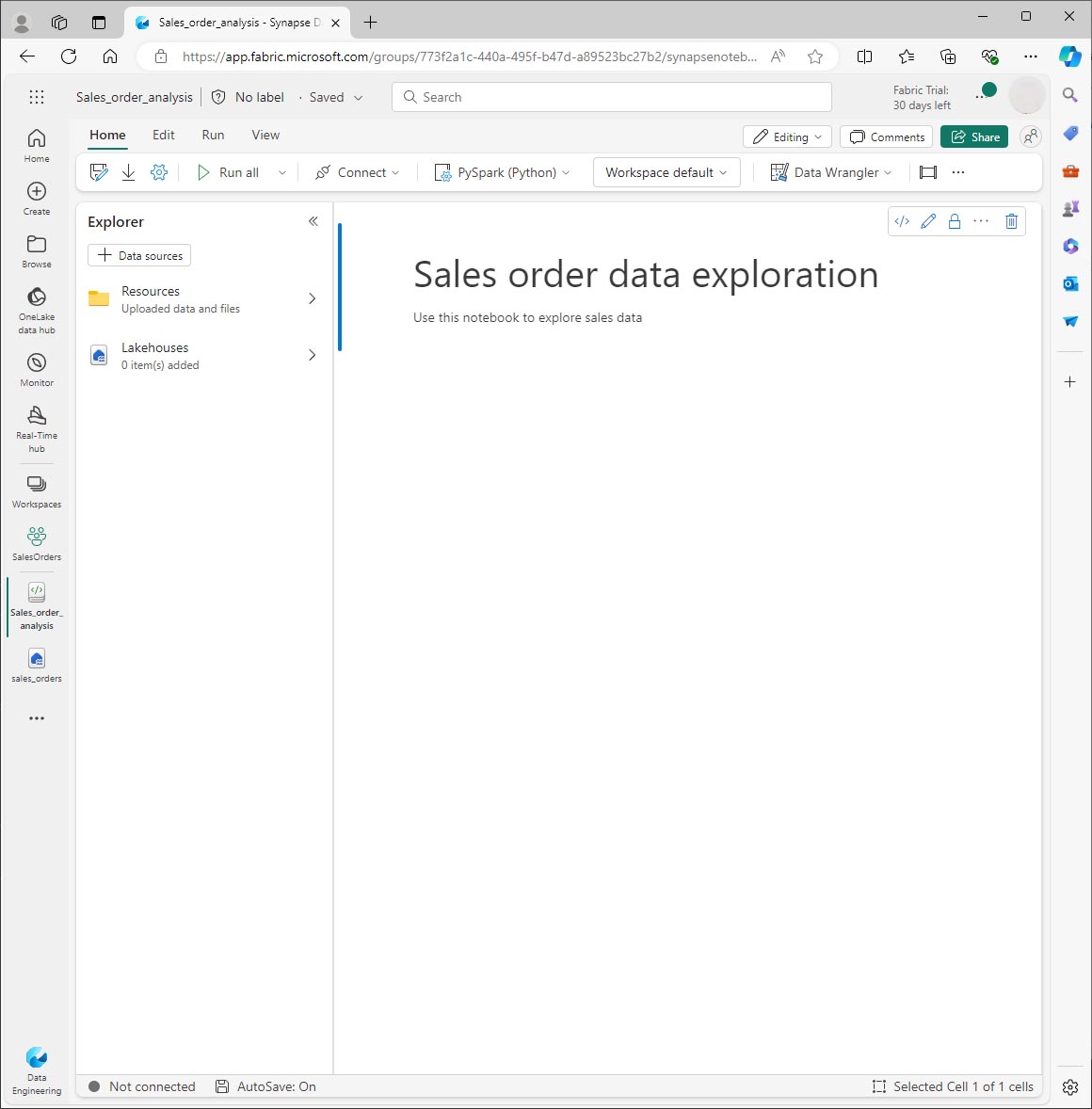
Lorsque vous avez terminé, cliquez n’importe où dans le notebook en dehors de la cellule pour arrêter sa modification et voir le balisage Markdown rendu.
Créer un DataFrame
Maintenant que vous avez créé un espace de travail, un lakehouse et un notebook, vous pouvez utiliser vos données. Vous allez utiliser PySpark, qui est le langage par défaut pour les notebooks Fabric et la version de Python optimisée pour Spark.
[!NOTE] Les notebooks Fabric prennent en charge plusieurs langages de programmation, notamment Scala, R et Spark SQL.
- Sélectionnez votre nouvel espace de travail dans la barre de gauche. Vous verrez une liste d’éléments contenus dans l’espace de travail, y compris votre lakehouse et votre notebook.
- Sélectionnez le lakehouse pour afficher le volet Explorateur, y compris le dossier orders.
-
Dans le menu supérieur, sélectionnez Ouvrir le notebook, Notebook existant, puis ouvrez le notebook que vous avez créé précédemment. Le notebook doit maintenant être ouvert en regard du volet Explorateur. Développez Lakehouses, développez la liste Files et sélectionnez le dossier orders. Les fichiers CSV que vous avez chargés sont répertoriés en regard de l’éditeur de notebook, comme suit :
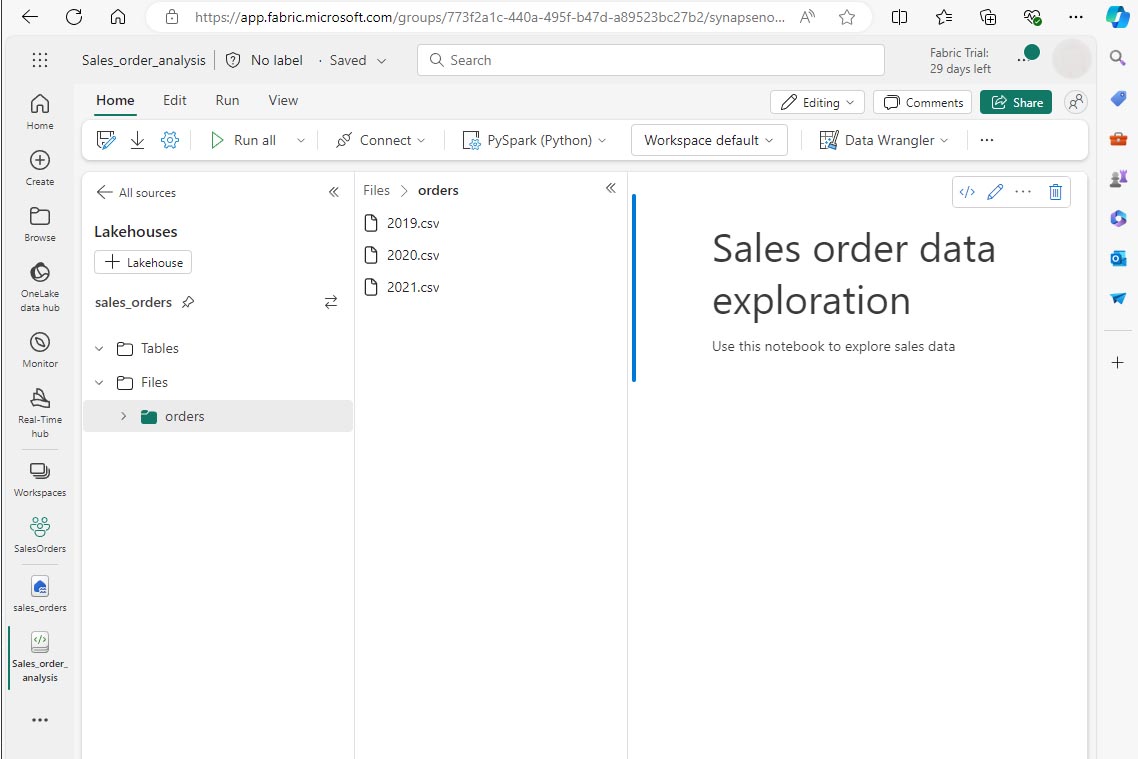
-
Dans le menu … pour 2019.csv, sélectionnez Charger des données > Spark. Le code suivant est automatiquement généré dans une nouvelle cellule de code :
df = spark.read.format("csv").option("header","true").load("Files/orders/2019.csv") # df now is a Spark DataFrame containing CSV data from "Files/orders/2019.csv". display(df)
[!TIP] Vous pouvez masquer les volets de l’explorateur Lakehouse à gauche à l’aide des icônes «. Cela donne plus d’espace pour le notebook.
- Sélectionnez ▷ Exécuter la cellule à gauche de la cellule pour exécuter le code.
[!NOTE] La première fois que vous exécutez du code Spark, une session Spark est démarrée. Cette opération peut prendre quelques secondes, voire plus. Les exécutions suivantes dans la même session seront plus rapides.
-
Une fois le code de la cellule exécuté, examinez la sortie sous la cellule, qui doit ressembler à ceci :
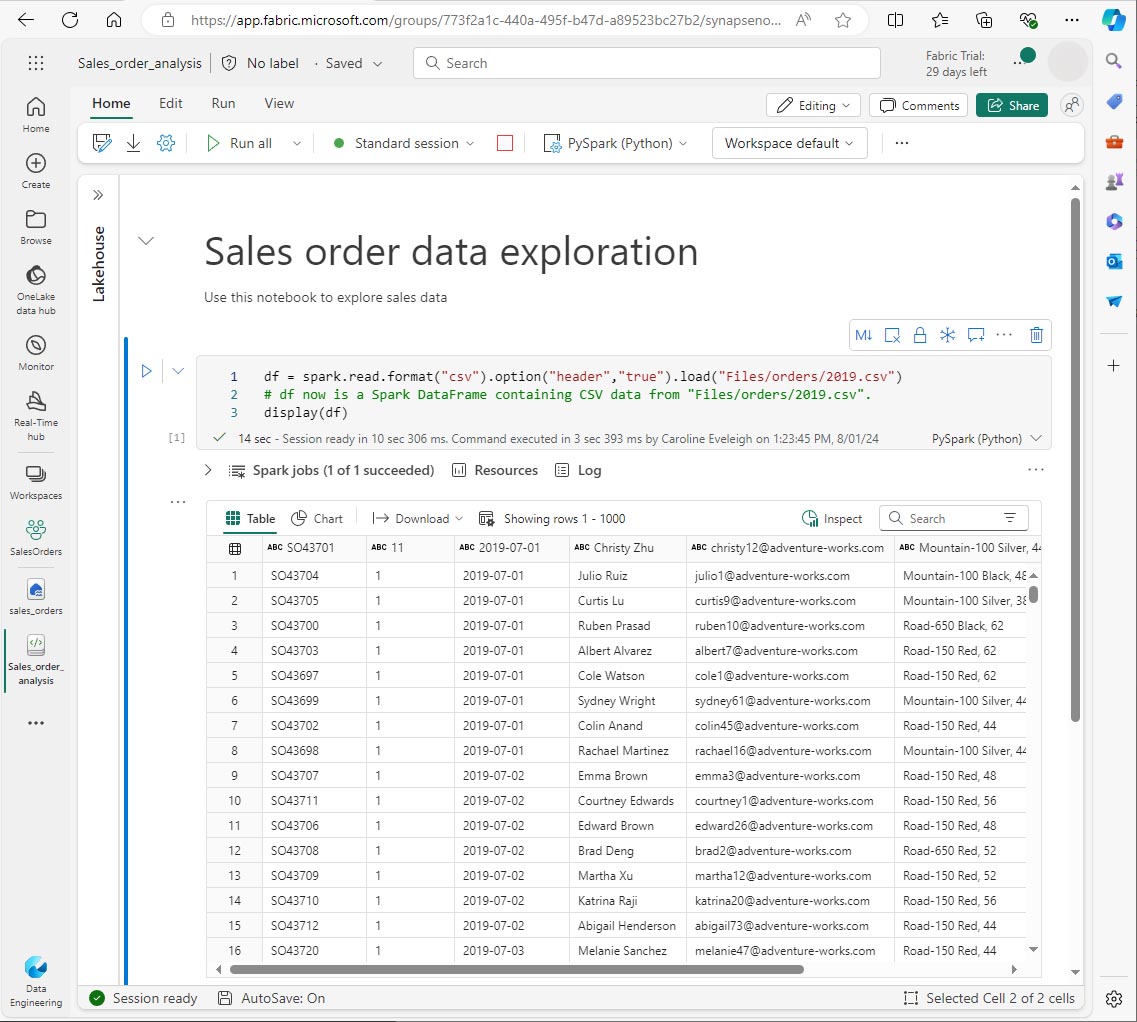
-
La sortie affiche les données du fichier 2019.csv affichées en lignes et en colonnes. Notez que les en-têtes de colonne contiennent la première ligne des données. Pour corriger ce problème, vous devez modifier la première ligne du code comme suit :
df = spark.read.format("csv").option("header","false").load("Files/orders/2019.csv") -
Réexécutez le code afin que le DataFrame identifie correctement la première ligne en tant que données. Notez que les noms de colonnes sont désormais _c0, _c1, etc.
-
Les noms de colonnes descriptifs vous aident à comprendre les données. Pour créer des noms de colonnes explicites, vous devez définir le schéma et les types de données. Vous devez également importer un ensemble standard de types SPARK SQL pour définir les types de données. Remplacez le code existant par le code ci-dessous :
from pyspark.sql.types import * orderSchema = StructType([ StructField("SalesOrderNumber", StringType()), StructField("SalesOrderLineNumber", IntegerType()), StructField("OrderDate", DateType()), StructField("CustomerName", StringType()), StructField("Email", StringType()), StructField("Item", StringType()), StructField("Quantity", IntegerType()), StructField("UnitPrice", FloatType()), StructField("Tax", FloatType()) ]) df = spark.read.format("csv").schema(orderSchema).load("Files/orders/2019.csv") display(df) -
Exécutez la cellule et passez en revue la sortie :
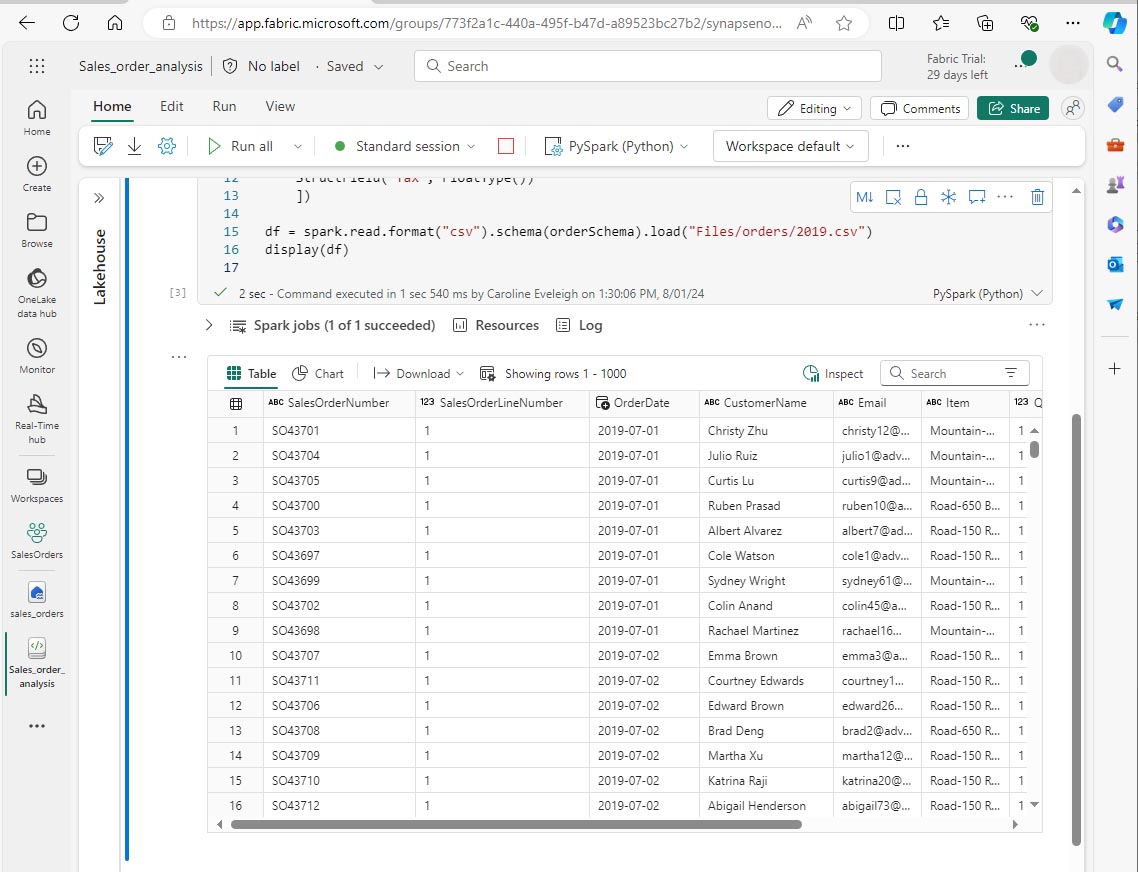
-
Le DataFrame inclut uniquement les données du fichier 2019.csv. Modifiez le code afin que le chemin de fichier utilise un caractère générique * pour lire toutes les données dans le dossier orders :
from pyspark.sql.types import * orderSchema = StructType([ StructField("SalesOrderNumber", StringType()), StructField("SalesOrderLineNumber", IntegerType()), StructField("OrderDate", DateType()), StructField("CustomerName", StringType()), StructField("Email", StringType()), StructField("Item", StringType()), StructField("Quantity", IntegerType()), StructField("UnitPrice", FloatType()), StructField("Tax", FloatType()) ]) df = spark.read.format("csv").schema(orderSchema).load("Files/orders/*.csv") display(df) -
Lorsque vous exécutez le code modifié, vous devez voir les ventes pour 2019, 2020 et 2021. Seul un sous-ensemble des lignes est affiché. Vous ne pouvez donc pas voir les lignes pour chaque année.
[!NOTE] Vous pouvez masquer ou afficher la sortie d’une cellule en sélectionnant … à côté du résultat. Cela facilite l’utilisation d’un notebook.
Explorer les données dans un DataFrame
L’objet DataFrame fournit des fonctionnalités supplémentaires, telles que la possibilité de filtrer, de regrouper et de manipuler des données.
Filtrer un DataFrame
-
Ajoutez une cellule de code en sélectionnant +Code qui apparaît lorsque vous pointez la souris au-dessus ou en dessous de la cellule active ou de sa sortie. Sinon, dans le menu du ruban, sélectionnez Modifier et +Ajouter une cellule de code ci-dessous.
-
Le code suivant filtre les données afin que seules deux colonnes soient retournées. Il utilise également count et distinct pour résumer le nombre d’enregistrements :
customers = df['CustomerName', 'Email'] print(customers.count()) print(customers.distinct().count()) display(customers.distinct()) -
Exécutez le code et examinez la sortie.
- Le code crée un DataFrame appelé customers qui contient un sous-ensemble de colonnes à partir du DataFrame df d’origine. Lors de l’exécution d’une transformation DataFrame, vous ne modifiez pas le DataFrame d’origine, mais vous en retournez un nouveau.
- Une autre façon d’obtenir le même résultat consiste à utiliser la méthode select :
customers = df.select("CustomerName", "Email")- Les fonctions DataFrame * count* et distinct sont utilisées pour fournir des totaux pour le nombre de clients et les clients uniques.
-
Modifiez la première ligne du code à l’aide de select avec une fonction where comme suit :
customers = df.select("CustomerName", "Email").where(df['Item']=='Road-250 Red, 52') print(customers.count()) print(customers.distinct().count()) display(customers.distinct()) -
Exécutez ce code modifié pour sélectionner uniquement les clients qui ont acheté le produit Road-250 Red, 52. Notez que vous pouvez « attacher » plusieurs fonctions ensemble afin que la sortie d’une fonction devienne l’entrée de la suivante. Dans ce cas, le DataFrame créé par la méthode select est le DataFrame source pour la méthode where utilisée pour appliquer des critères de filtrage.
Agréger et regrouper des données dans un DataFrame
-
Ajoutez une cellule de code et entrez le code suivant :
productSales = df.select("Item", "Quantity").groupBy("Item").sum() display(productSales) -
Exécutez le code. Vous pouvez voir que les résultats affichent la somme des quantités de commandes regroupées par produit. La méthode groupBy regroupe les lignes par Item, et la fonction d’agrégation sum suivante est appliquée à toutes les colonnes numériques restantes, dans ce cas, Quantity.
-
Ajoutez une autre cellule de code au notebook, puis entrez le code suivant :
from pyspark.sql.functions import * yearlySales = df.select(year(col("OrderDate")).alias("Year")).groupBy("Year").count().orderBy("Year") display(yearlySales) -
Exécutez la cellule. Examinez le résultat. Cette fois, les résultats indiquent le nombre de commandes client par an.
- L’instruction import vous permet d’utiliser la bibliothèque SPARK SQL.
- La méthode select est utilisée avec une fonction year SQL pour extraire le composant year du champ OrderDate.
- La méthode alias est utilisée pour affecter un nom de colonne à la valeur d’année extraite.
- La méthode groupBy regroupe les données par la colonne Year dérivée.
- Le nombre de lignes dans chaque groupe est calculé avant que la méthode orderBy soit utilisée pour trier le DataFrame résultant.
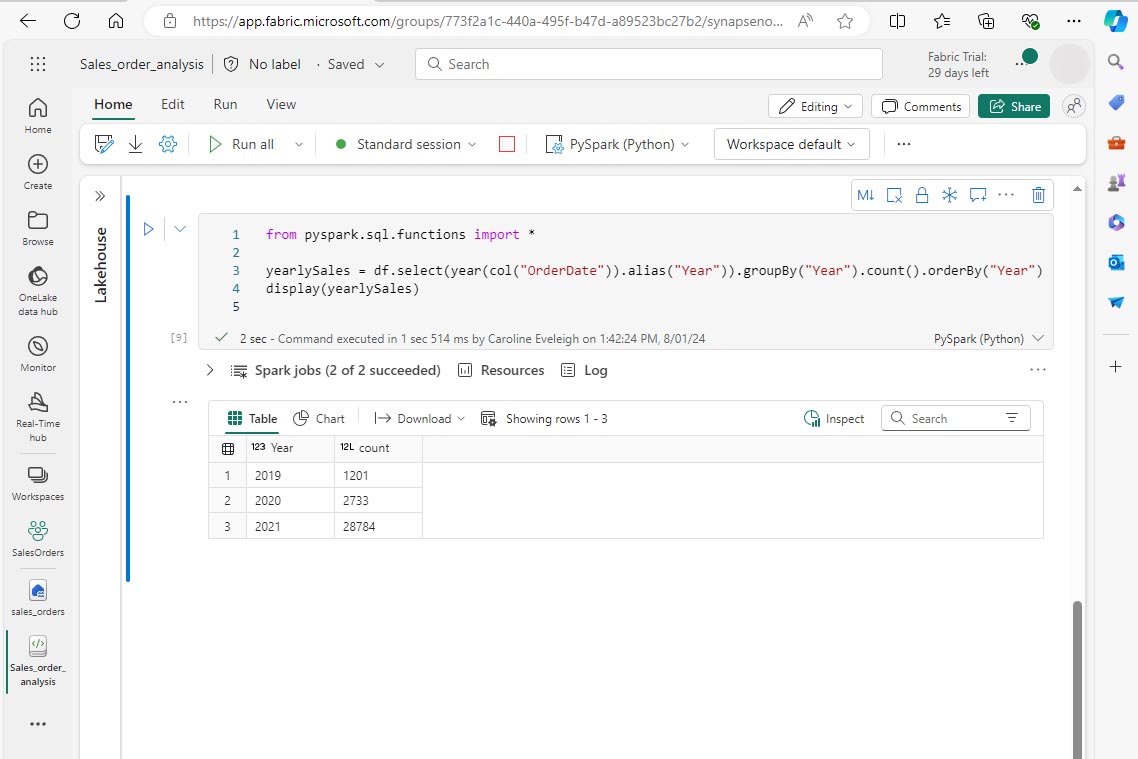
Utiliser Spark pour transformer des fichiers de données
Une tâche courante des ingénieurs et scientifiques des données consiste à transformer des données pour poursuivre leur traitement ou analyse en aval.
Utiliser des méthodes et des fonctions de DataFrame pour transformer les données
-
Ajoutez une cellule de code au notebook, puis entrez ce qui suit :
from pyspark.sql.functions import * # Create Year and Month columns transformed_df = df.withColumn("Year", year(col("OrderDate"))).withColumn("Month", month(col("OrderDate"))) # Create the new FirstName and LastName fields transformed_df = transformed_df.withColumn("FirstName", split(col("CustomerName"), " ").getItem(0)).withColumn("LastName", split(col("CustomerName"), " ").getItem(1)) # Filter and reorder columns transformed_df = transformed_df["SalesOrderNumber", "SalesOrderLineNumber", "OrderDate", "Year", "Month", "FirstName", "LastName", "Email", "Item", "Quantity", "UnitPrice", "Tax"] # Display the first five orders display(transformed_df.limit(5)) -
Exécutez la cellule. Un nouveau DataFrame est créé à partir des données de commandes d’origine avec les transformations suivantes :
- Colonnes Year et Month ajoutées, basées sur la colonne OrderDate.
- Colonnes FirstName et LastName ajoutées, basées sur la colonne CustomerName.
- Les colonnes sont filtrées et réorganisées, et la colonne CustomerName est supprimée.
-
Passez en revue la sortie et vérifiez que les transformations ont été apportées aux données.
Vous pouvez utiliser la bibliothèque Spark SQL pour transformer les données en filtrant les lignes, en dérivant, en supprimant et en renommant des colonnes, et en appliquant d’autres modifications de données.
[!TIP] Consultez la documentation des DataFrames Spark pour en savoir plus sur l’objet Dataframe.
Enregistrer les données transformées
À ce stade, vous pouvez enregistrer les données transformées afin qu’elles puissent être utilisées pour une analyse plus approfondie.
Parquet est un format de stockage de données populaire, car il stocke les données efficacement et est pris en charge par la plupart des systèmes d’analytique données à grande échelle. En effet, la transformation de données consiste parfois à convertir des données d’un format comme CSV vers Parquet.
-
Pour enregistrer le DataFrame transformé au format Parquet, ajoutez une cellule de code et ajoutez le code suivant :
transformed_df.write.mode("overwrite").parquet('Files/transformed_data/orders') print ("Transformed data saved!") -
Exécutez la cellule et attendez le message indiquant que les données ont été enregistrées. Ensuite, dans le volet Lakehouses à gauche, dans le menu … du nœud Fichiers, sélectionnez Actualiser. Sélectionnez le dossier transformed_data pour vérifier qu’il contient un nouveau dossier nommé orders, qui contient à son tour un ou plusieurs fichiers Parquet.
-
Ajoutez une cellule avec le code suivant :
orders_df = spark.read.format("parquet").load("Files/transformed_data/orders") display(orders_df) -
Exécutez la cellule. Un DataFrame est créé à partir des fichiers Parquet dans le dossier transformed_data/orders. Vérifiez que les résultats affichent les données de commandes qui ont été chargées à partir des fichiers Parquet.
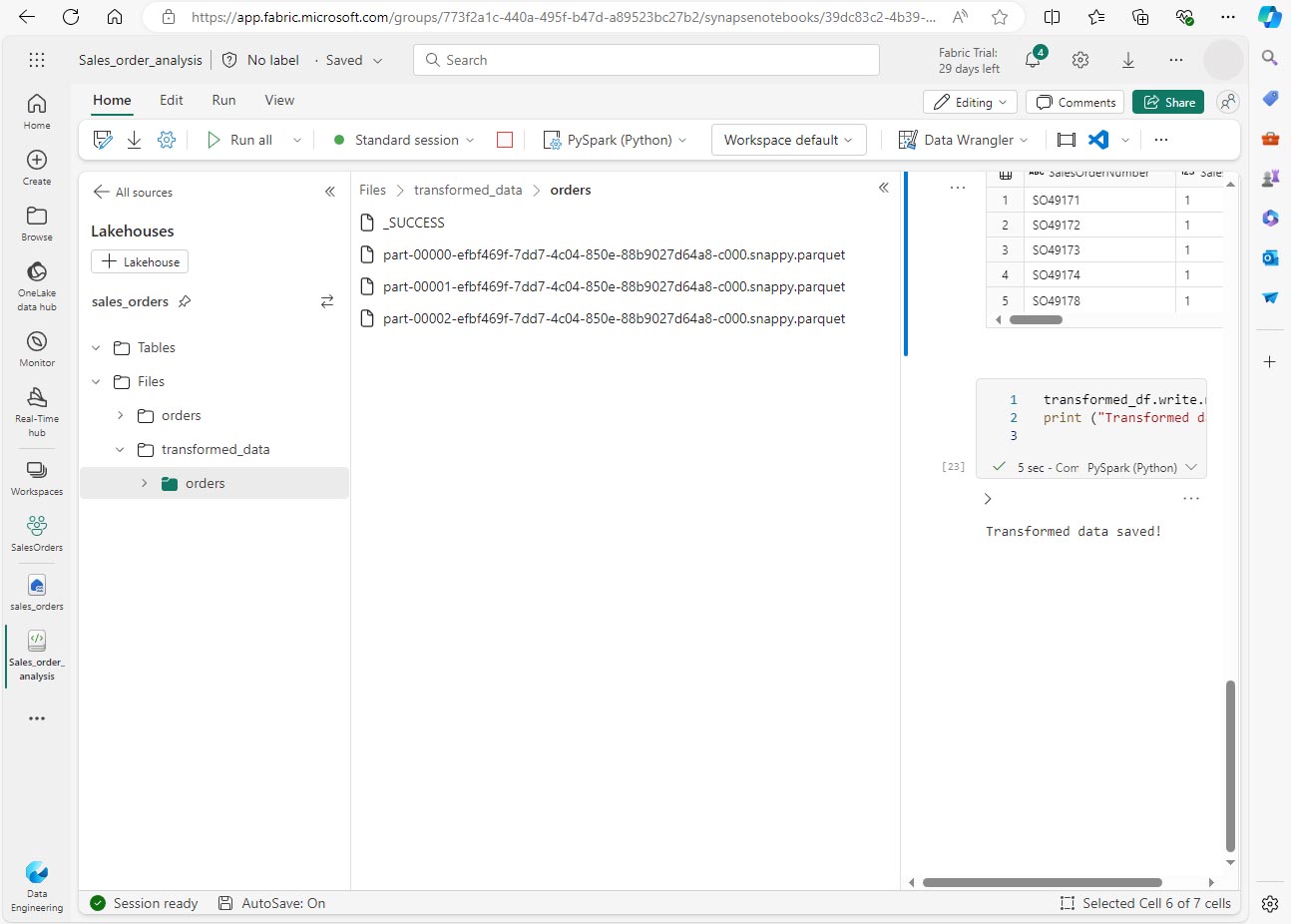
Enregistrer des données dans des fichiers partitionnés
Lorsque vous traitez de gros volumes de données, le partitionnement peut améliorer considérablement les performances et faciliter le filtrage des données.
-
Ajoutez une cellule avec le code pour enregistrer le DataFrame, en partitionnant les données par année et par mois :
orders_df.write.partitionBy("Year","Month").mode("overwrite").parquet("Files/partitioned_data") print ("Transformed data saved!") -
Exécutez la cellule et attendez le message indiquant que les données ont été enregistrées. Ensuite, dans le volet Lakehouses à gauche, dans le menu … du nœud Fichiers, sélectionnez Actualiser, puis développez le dossier partitioned_data pour vérifier qu’il contient une hiérarchie de dossiers nommés Year=xxxx, chacun contenant des dossiers nommés Month=xxxx. Chaque dossier de mois contient un fichier Parquet avec les commandes de ce mois.

-
Ajoutez une nouvelle cellule avec le code suivant pour charger un nouveau DataFrame à partir du fichier orders.parquet :
orders_2021_df = spark.read.format("parquet").load("Files/partitioned_data/Year=2021/Month=*") display(orders_2021_df) -
Exécutez cette cellule et vérifiez que les résultats affichent les données de commandes pour les ventes de 2021. Notez que les colonnes de partitionnement spécifiées dans le chemin (Year et Month) ne sont pas incluses dans le DataFrame.
Utiliser des tables et SQL
Vous avez désormais vu comment les méthodes natives de l’objet DataFrame vous permettent d’interroger et d’analyser des données à partir d’un fichier. Toutefois, vous pouvez être plus à l’aise avec les tables à l’aide de la syntaxe SQL. Spark fournit un metastore dans lequel vous pouvez définir des tables relationnelles.
La bibliothèque Spark SQL prend en charge l’utilisation d’instructions SQL pour interroger les tables figurant dans le metastore. Cela permet d’allier la flexibilité d’un lac de données au schéma de données structuré et aux requêtes SQL d’un entrepôt de données relationnelles, d’où le terme de « data lakehouse ».
Créer une table
Les tables d’un metastore Spark sont des abstractions relationnelles sur les fichiers figurant dans le lac de données. Les tables peuvent être managées par le metastore, ou externes et managées indépendamment du metastore.
-
Ajoutez une cellule de code au notebook, puis entrez le code suivant, qui enregistre le DataFrame des données de commandes client sous la forme d’une table nommée salesorders :
# Create a new table df.write.format("delta").saveAsTable("salesorders") # Get the table description spark.sql("DESCRIBE EXTENDED salesorders").show(truncate=False)
[!NOTE] Dans cet exemple, aucun chemin explicite n’est fourni, de sorte que les fichiers de la table sont managés par le metastore. En outre, la table est enregistrée au format delta, ce qui ajoute des fonctionnalités de base de données relationnelle aux tables. Cela inclut la prise en charge des transactions, du contrôle de version des lignes et d’autres fonctionnalités utiles. La création de tables au format delta est recommandée pour les data lakehouses dans Fabric.
-
Exécutez la cellule de code et passez en revue la sortie, qui décrit la définition de la nouvelle table.
-
Dans le volet Lakehouses, dans le menu … du dossier Tables, sélectionnez Actualiser. Développez ensuite le nœud Tables et vérifiez que la table salesorders a été créée.
-
Dans le menu … de la table salesorders, sélectionnez Charger des données > Spark. Une nouvelle cellule de code contenant du code similaire à l’exemple suivant :
df = spark.sql("SELECT * FROM [your_lakehouse].salesorders LIMIT 1000") display(df) -
Exécutez le nouveau code, qui utilise la bibliothèque Spark SQL pour incorporer une requête SQL sur la table salesorder dans le code PySpark et charger les résultats de la requête dans un DataFrame.
Exécuter du code SQL dans une cellule
Bien qu’il soit utile d’incorporer des instructions SQL dans une cellule contenant du code PySpark, les analystes de données veulent souvent simplement travailler directement dans SQL.
-
Ajoutez une nouvelle cellule de code au notebook, puis entrez le code suivant :
%%sql SELECT YEAR(OrderDate) AS OrderYear, SUM((UnitPrice * Quantity) + Tax) AS GrossRevenue FROM salesorders GROUP BY YEAR(OrderDate) ORDER BY OrderYear; -
Exécutez la cellule et passez en revue les résultats. Observez que :
- La commande %%sql au début de la cellule (appelée magic) change le langage en Spark SQL au lieu de PySpark.
- Le code SQL fait référence à la table salesorders que vous avez créée précédemment.
- La sortie de la requête SQL s’affiche automatiquement en tant que résultat sous la cellule.
[!NOTE] Pour plus d’informations sur Spark SQL et les DataFrames, consultez la documentation Spark SQL.
Visualiser les données avec Spark
Les graphiques vous aident à voir les modèles et les tendances plus rapidement que possible en analysant des milliers de lignes de données. Les notebooks Fabric incluent une vue graphique intégrée, mais elle n’est pas conçue pour les graphiques complexes. Pour plus de contrôle sur la façon dont les graphiques sont créés à partir de données dans des DataFrames, utilisez des bibliothèques graphiques Python telles que matplotlib ou seaborn.
Afficher les résultats sous forme de graphique
-
Ajoutez une nouvelle cellule de code et entrez le code suivant :
%%sql SELECT * FROM salesorders -
Exécutez le code pour afficher les données de la vue salesorders que vous avez créée précédemment. Dans la section des résultats sous la cellule, modifiez l’option Affichage de Tableau à Graphique.
-
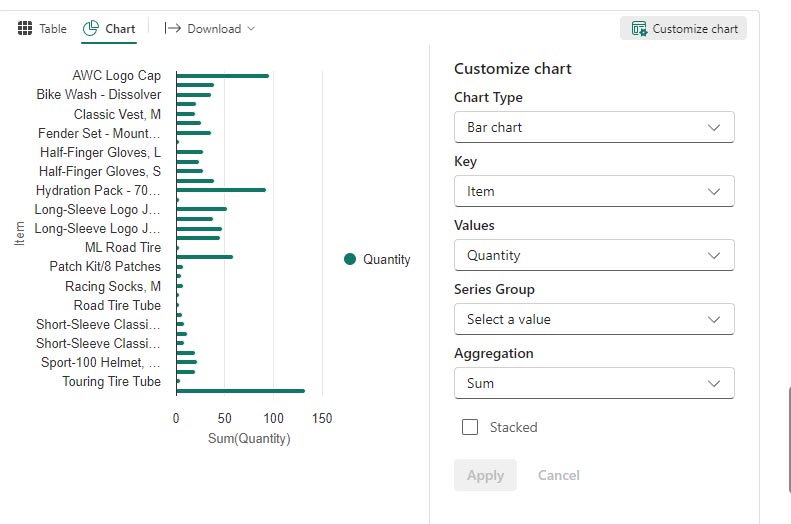
Utilisez le bouton Personnaliser le graphique en haut à droite du graphique pour définir les options suivantes :
- Type de graphique : Graphique à barres
- Clé : Élément
- Valeurs : Quantité
- Groupe de séries : laissez vide
- Agrégation : Somme
- Empilé : Non sélectionné
Lorsque vous avez terminé, sélectionnez Appliquer.
-
Votre graphique doit ressembler à ceci :
Bien démarrer avec matplotlib
-
Ajoutez une nouvelle cellule de code et entrez le code suivant :
sqlQuery = "SELECT CAST(YEAR(OrderDate) AS CHAR(4)) AS OrderYear, \ SUM((UnitPrice * Quantity) + Tax) AS GrossRevenue, \ COUNT(DISTINCT SalesOrderNumber) AS YearlyCounts \ FROM salesorders \ GROUP BY CAST(YEAR(OrderDate) AS CHAR(4)) \ ORDER BY OrderYear" df_spark = spark.sql(sqlQuery) df_spark.show() -
Exécutez le code. Il renvoie un DataFrame Spark contenant le chiffre d’affaires annuel et le nombre de commandes. Pour visualiser les données sous forme graphique, nous allons utiliser d’abord la bibliothèque Python matplotlib. Cette bibliothèque est la bibliothèque de traçage principale sur laquelle de nombreuses autres bibliothèques sont basées, et elle offre une grande flexibilité dans la création de graphiques.
-
Ajoutez une nouvelle cellule de code, puis ajoutez le code suivant :
from matplotlib import pyplot as plt # matplotlib requires a Pandas dataframe, not a Spark one df_sales = df_spark.toPandas() # Create a bar plot of revenue by year plt.bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue']) # Display the plot plt.show() -
Exécutez la cellule et passez en revue les résultats, qui se composent d’un histogramme indiquant le chiffre d’affaires brut total pour chaque année. Passez en revue le code et notez les points suivants :
- La bibliothèque matplotlib nécessite un DataFrame Pandas. Vous devez donc convertir le DataFrame Spark retourné par la requête Spark SQL.
- Au cœur de la bibliothèque matplotlib figure l’objet pyplot. Il s’agit de la base de la plupart des fonctionnalités de traçage.
- Les paramètres par défaut aboutissent à un graphique utilisable, mais il existe de nombreuses façons de le personnaliser.
-
Modifiez le code pour tracer le graphique comme suit :
from matplotlib import pyplot as plt # Clear the plot area plt.clf() # Create a bar plot of revenue by year plt.bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue'], color='orange') # Customize the chart plt.title('Revenue by Year') plt.xlabel('Year') plt.ylabel('Revenue') plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7) plt.xticks(rotation=45) # Show the figure plt.show() - Réexécutez la cellule de code et examinez les résultats. Le graphique est désormais plus facile à comprendre.
-
Un tracé est contenu dans une figure. Dans les exemples précédents, la figure a été créée implicitement, mais elle peut être créée explicitement. Modifiez le code pour tracer le graphique comme suit :
from matplotlib import pyplot as plt # Clear the plot area plt.clf() # Create a Figure fig = plt.figure(figsize=(8,3)) # Create a bar plot of revenue by year plt.bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue'], color='orange') # Customize the chart plt.title('Revenue by Year') plt.xlabel('Year') plt.ylabel('Revenue') plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7) plt.xticks(rotation=45) # Show the figure plt.show() - Réexécutez la cellule de code et examinez les résultats. La figure détermine la forme et la taille du tracé.
-
Une figure peut contenir plusieurs sous-tracés, chacun sur son propre axe. Modifiez le code pour tracer le graphique comme suit :
from matplotlib import pyplot as plt # Clear the plot area plt.clf() # Create a figure for 2 subplots (1 row, 2 columns) fig, ax = plt.subplots(1, 2, figsize = (10,4)) # Create a bar plot of revenue by year on the first axis ax[0].bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue'], color='orange') ax[0].set_title('Revenue by Year') # Create a pie chart of yearly order counts on the second axis ax[1].pie(df_sales['YearlyCounts']) ax[1].set_title('Orders per Year') ax[1].legend(df_sales['OrderYear']) # Add a title to the Figure fig.suptitle('Sales Data') # Show the figure plt.show() - Réexécutez la cellule de code et examinez les résultats.
[!NOTE] Pour en savoir plus sur le traçage avec matplotlib, consultez la documentation matplotlib.
Utiliser la bibliothèque seaborn
Bien que matplotlib vous permette de créer des types de graphiques différents, du code complexe peut être nécessaire pour obtenir les meilleurs résultats. Pour cette raison, de nombreuses nouvelles bibliothèques ont été construites sur matplotlib pour en extraire la complexité et améliorer ses capacités. L’une de ces bibliothèques est seaborn.
-
Ajoutez une nouvelle cellule de code au notebook, puis entrez le code suivant :
import seaborn as sns # Clear the plot area plt.clf() # Create a bar chart ax = sns.barplot(x="OrderYear", y="GrossRevenue", data=df_sales) plt.show() - Exécutez le code pour afficher un graphique à barres créé à l’aide de la bibliothèque seaborn.
-
Modifiez le code comme suit :
import seaborn as sns # Clear the plot area plt.clf() # Set the visual theme for seaborn sns.set_theme(style="whitegrid") # Create a bar chart ax = sns.barplot(x="OrderYear", y="GrossRevenue", data=df_sales) plt.show() - Exécutez le code modifié et notez que seaborn vous permet de définir un thème de couleur pour vos tracés.
-
Modifiez à nouveau le code comme suit :
import seaborn as sns # Clear the plot area plt.clf() # Create a line chart ax = sns.lineplot(x="OrderYear", y="GrossRevenue", data=df_sales) plt.show() - Exécutez le code modifié pour afficher le chiffre d’affaires annuel sous forme de graphique en courbes.
[!NOTE] Pour en savoir plus sur le traçage avec seaborn, consultez la documentation seaborn.
Nettoyer les ressources
Dans cet exercice, vous avez appris à utiliser Spark pour travailler sur des données dans Microsoft Fabric.
Si vous avez terminé d’explorer vos données, vous pouvez mettre fin à la session Spark et supprimer l’espace de travail que vous avez créé pour cet exercice.
- Dans le menu du notebook, sélectionnez Arrêter la session pour mettre fin à la session Spark.
- Dans la barre de gauche, sélectionnez l’icône de votre espace de travail pour afficher tous les éléments qu’il contient.
- Sélectionnez Paramètres de l’espace de travail et, dans la sectionGénéral, faites défiler vers le bas et sélectionnez Supprimer cet espace de travail.
- Sélectionnez Supprimer pour supprimer l’espace de travail.