Trabajo con los datos de un centro de eventos de Microsoft Fabric
En Microsoft Fabric, un centro de enventos se usa para almacenar datos en tiempo real relacionados con eventos; a menudo capturados desde un origen de datos de streaming mediante un flujo de datos.
Dentro de un centro de eventos, los datos se almacenan en una o varias bases de datos KQL, cada una de las cuales contiene tablas y otros objetos que puedes consultar mediante Lenguaje de consulta Kusto (KQL) o un subconjunto de Lenguaje de consulta estructurado (SQL).
En este ejercicio, crearás y rellenarás un centro de eventos con algunos datos de ejemplo relacionados con carreras de taxi y después consultarás los datos mediante KQL y SQL.
Este ejercicio se realiza en aproximadamente 25 minutos.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, cree un área de trabajo con la capacidad gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabrice inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, seleccione Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Crea una nueva área de trabajo con el nombre que prefieras y selecciona un modo de licencia que incluya capacidad de Fabric (Evaluación gratuita, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
Creación de instancia de Eventhouse
Ahora que tienes un área de trabajo compatible con una capacidad de Fabric, puedes crear un centro de eventos en él.
- En la barra de menús de la izquierda, selecciona Cargas de trabajo. Después, selecciona el icono Inteligencia en tiempo real.
-
En la página principal de Inteligencia en tiempo real, selecciona el icono de ejemplo de Explorar inteligencia en tiempo real. Creará automáticamente un Eventhouse denominado RTISample:
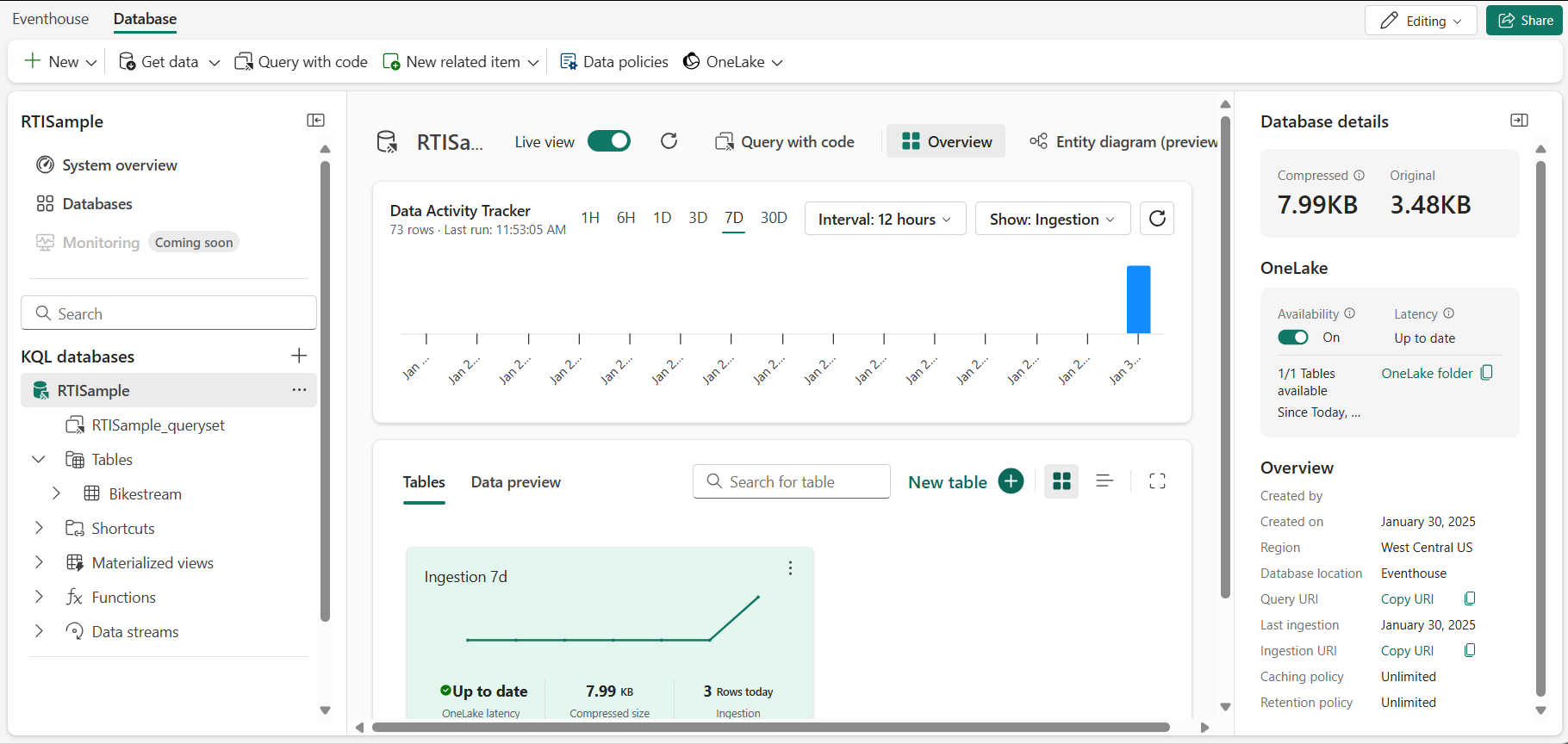
- En el panel de la izquierda, ten en cuenta que el centro de eventos contiene una base de datos KQL con el mismo nombre que el centro de eventos.
- Comprueba que también se ha creado una tabla Bikestream.
Consulta de datos mediante KQL
Lenguaje de consulta Kusto (KQL) es un lenguaje intuitivo y completo que puedes usar para consultar una base de datos KQL.
Recuperación de datos de una tabla con KQL
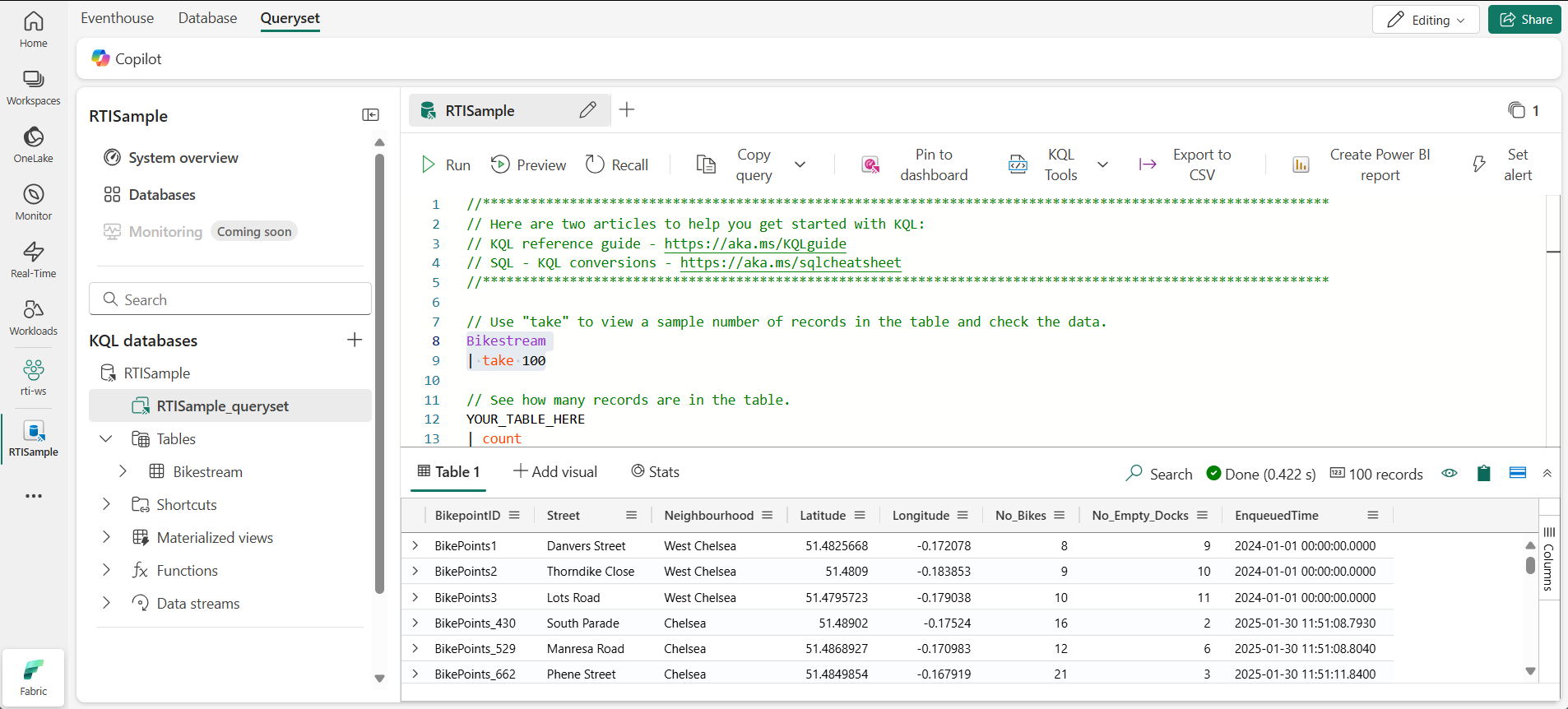
- En el panel izquierdo de la ventana del centro de eventos, en tu base de datos KQL, selecciona el archivo queryset predeterminado. Este archivo contiene algunas consultas KQL de muestra para empezar.
-
Modifica la primera consulta de ejemplo de la siguiente manera.
Bikestream | take 100NOTA: El carácter de barra vertical ( ) se usa para dos propósitos en KQL, entre ellos para separar operadores de consulta en una instrucción de expresión tabular. También se usa como operador OR lógico entre corchetes o paréntesis para indicar que se puede especificar uno de los elementos separados por la barra vertical. -
Selecciona el código de consulta y ejecútalo para devolver 100 filas de la tabla.
Puedes ser más preciso al agregar atributos específicos que deseas consultar mediante la palabra clave
projecty después usar la palabra clavetakepara indicarle al motor cuántos registros debe devolver. -
Escribe, selecciona y ejecuta la siguiente consulta:
// Use 'project' and 'take' to view a sample number of records in the table and check the data. Bikestream | project Street, No_Bikes | take 10NOTA: El uso de // denota un comentario.
Otra práctica habitual en el análisis consiste en cambiar el nombre de las columnas del conjunto de consultas para que sean más fáciles de usar.
-
Prueba la siguiente consulta:
Bikestream | project Street, ["Number of Empty Docks"] = No_Empty_Docks | take 10
Resumir datos con KQL
Puedes usar la palabra clave summarize con una función para agregar y manipular datos de otro modo.
-
Prueba la siguiente consulta, que usa la función SUMA para resumir los datos de alquiler y ver cuántas bicicletas hay disponibles en total:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes)Puedes agrupar los datos resumidos por una columna o expresión especificadas.
-
Ejecuta la siguiente consulta para agrupar el número de bicicletas por barrio y determinar la cantidad de bicicletas disponibles en cada barrio:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood, ["Total Number of Bikes"]Si alguno de los puntos de bicicletas tiene una entrada nula o vacía para el barrio, los resultados del resumen incluirán un valor en blanco, lo que nunca es bueno para el análisis.
-
Modifica la consulta como se muestra aquí para usar la función case junto con las funciones isempty y isnull para agrupar todos los viajes cuyo barrio se desconoce en la categoría No identificado para su seguimiento.
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]Nota: como este conjunto de datos de ejemplo está bien mantenido, es posible que no tenga un campo No identificado en el resultado de la consulta.
Ordenar datos mediante KQL
Para darle más sentido a nuestros datos, normalmente los ordenamos por columna, y este proceso se realiza en KQL con un operador ordenar por**.
-
Prueba la siguiente consulta:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | sort by Neighbourhood asc -
Modifica la consulta de la siguiente manera y ejecútala de nuevo y observa cómo funciona el operador ordenar por**:
Bikestream | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | order by Neighbourhood asc
Filtrado de datos mediante KQL
En KQL, la cláusula where se usa para filtrar los datos. Puedes combinar condiciones en una cláusula where mediante los operadores lógicos y y o.
-
Ejecuta la siguiente consulta para filtrar los datos de bicicletas para incluir solo puntos de bicicletas en el barrio de Chelsea:
Bikestream | where Neighbourhood == "Chelsea" | summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood | project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"] | sort by Neighbourhood asc
Consulta de datos mediante Transact-SQL
La base de datos KQL no admite Transact-SQL de forma nativa, pero proporciona un punto de conexión de T-SQL que emula a Microsoft SQL Server y permite ejecutar consultas de T-SQL en los datos. El punto de conexión de T-SQL tiene algunas limitaciones y diferencias con respecto al SQL Server nativo. Por ejemplo, no admite la creación, modificación o eliminación de tablas, ni la inserción, actualización o eliminación de datos. Tampoco admite algunas funciones y sintaxis de T-SQL que no son compatibles con KQL. Se creó para permitir que los sistemas que no admitan KQL usen T-SQL para consultar los datos dentro de una base de datos KQL. Por lo tanto, se recomienda usar KQL como lenguaje de consulta principal para bases de datos KQL, ya que ofrece más funcionalidades y rendimiento que T-SQL. También se pueden usar algunas funciones de SQL compatibles con KQL, como count, sum, avg, min, max, etc.
Recuperación de datos de una tabla mediante Transact-SQL
-
En el conjunto de consultas, agrega y ejecuta la siguiente consulta de Transact-SQL:
SELECT TOP 100 * from Bikestream -
Modifica la consulta como se indica a continuación para recuperar columnas específicas
SELECT TOP 10 Street, No_Bikes FROM Bikestream -
Modifica la consulta para asignar un alias que cambie el nombre de No_Empty_Docks a un nombre más descriptivo.
SELECT TOP 10 Street, No_Empty_Docks as [Number of Empty Docks] from Bikestream
Resumen de datos mediante Transact-SQL
-
Ejecuta la consulta siguiente para encontrar el número total de bicicletas disponibles:
SELECT sum(No_Bikes) AS [Total Number of Bikes] FROM Bikestream -
Modifica la consulta para agrupar el número total de bicicletas por barrio:
SELECT Neighbourhood, Sum(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY Neighbourhood -
Modifica aún más la consulta para usar una instrucción CASE para agrupar puntos de bicicletas con un origen desconocido en una categoría No identificado para su seguimiento.
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END;
Ordenar datos mediante Transact-SQL
-
Ejecuta la siguiente consulta para ordenar los resultados agrupados por barrio:
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END ORDER BY Neighbourhood ASC;
Filtrado de datos mediante Transact-SQL
-
Ejecuta la siguiente consulta para filtrar los datos agrupados para que solo se incluyan en los resultados filas que tengan en barrio de “Chelsea”.
SELECT CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END AS Neighbourhood, SUM(No_Bikes) AS [Total Number of Bikes] FROM Bikestream GROUP BY CASE WHEN Neighbourhood IS NULL OR Neighbourhood = '' THEN 'Unidentified' ELSE Neighbourhood END HAVING Neighbourhood = 'Chelsea' ORDER BY Neighbourhood ASC;
Limpieza de recursos
En este ejercicio, has creado un centro de eventos y has consultado datos mediante KQL y SQL.
Si ha terminado de explorar la base de datos KQL, puede eliminar el área de trabajo que ha creado para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo.
- En la barra de herramientas, selecciona Configuración del área de trabajo.
- En la sección General, selecciona Quitar esta área de trabajo.