Ingesta de datos con cuadernos de Spark y Microsoft Fabric
En este laboratorio, creará un cuaderno de Microsoft Fabric y usará PySpark para conectarse a una ruta de acceso de Azure Blob Storage y, a continuación, cargará los datos en un lago mediante optimizaciones de escritura.
Este laboratorio se tarda aproximadamente 30 minutos en completarse.
Para esta experiencia, creará el código en varias celdas de código del cuaderno, lo que podría no reflejar cómo lo hará en su entorno, aunque podría resultar útil para la depuración.
Dado que también está trabajando con un conjunto de datos de ejemplo, la optimización no refleja lo que podría ver en producción a escala, aunque todavía podrá ver mejoras y, cuando cada milisegundo cuente, la optimización resultará clave.
Nota: Necesitarás una evaluación gratuita de Microsoft Fabric para realizar este ejercicio.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, crea un área de trabajo con la evaluación gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabrice inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, selecciona Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Crea una nueva área de trabajo con el nombre que prefieras y selecciona un modo de licencia que incluya capacidad de Fabric (Evaluación gratuita, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
Creación de un área de trabajo y un destino de almacén de lago
Empiece por crear un área de trabajo, una nueva instancia de almacén de lago y una carpeta de destino en el almacén de lago.
-
En el área de trabajo, selecciona + Nuevo elemento > Almacén de lago de datos, proporciona un nombre y selecciona Crear.
Nota: podría tardar unos minutos en crear un nuevo almacén de lago sin Tablas o Archivos.
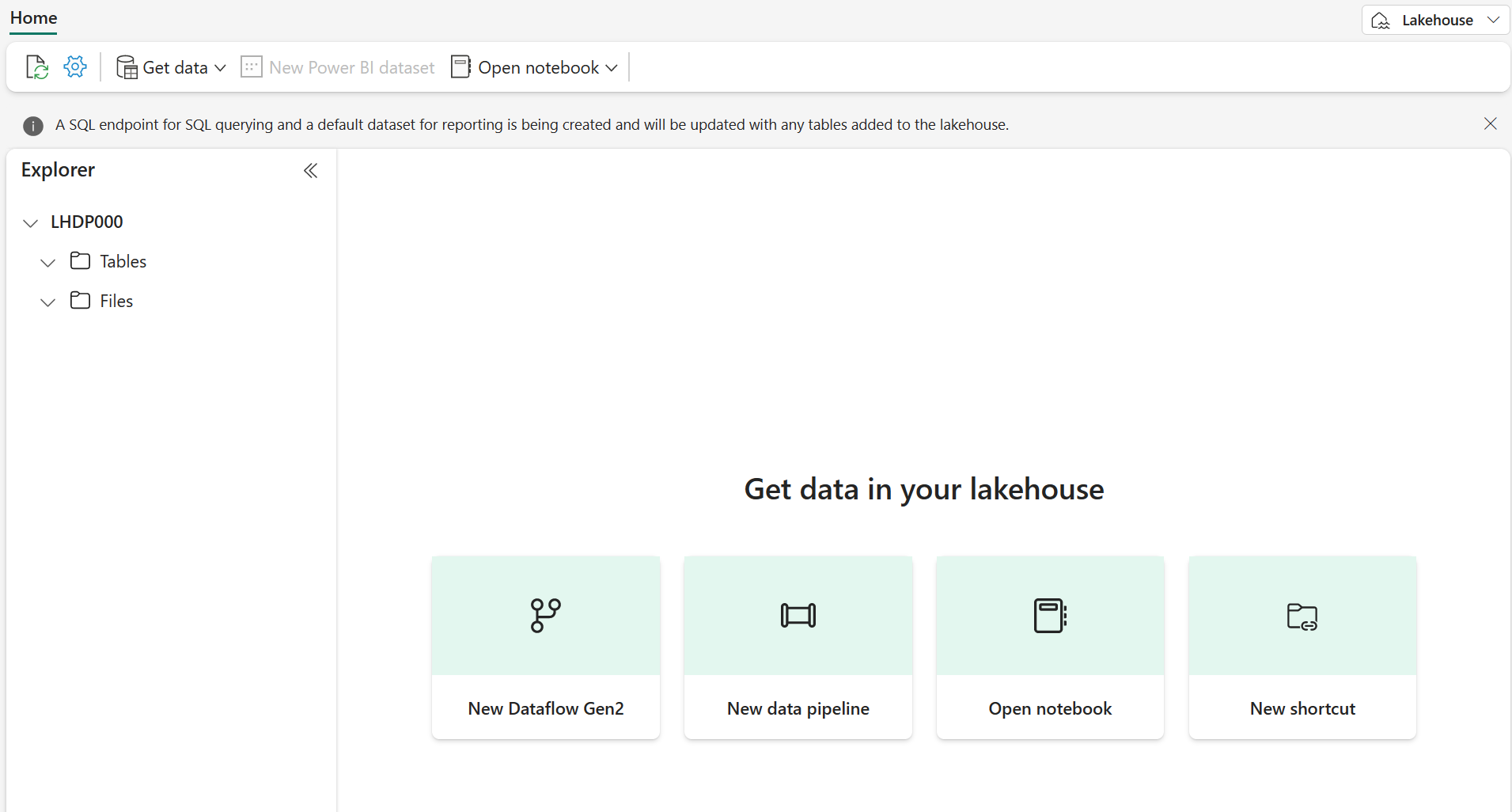
-
En Archivos, seleccione […] para crear una Nueva subcarpeta denominada RawData.
-
En el Explorador de Almacén de lago dentro del almacén de lago, seleccione RawData > … > Propiedades.
-
Copie la ruta de acceso de ABFS de la carpeta RawData en un bloc de notas vacío para su uso posterior, que debería tener un aspecto similar al siguiente:
abfss://{workspace_name}@onelake.dfs.fabric.microsoft.com/{lakehouse_name}.Lakehouse/Files/{folder_name}/{file_name}
Ahora debería tener un área de trabajo con una instancia de Almacén de lago y una carpeta de destino RawData.
Creación de un cuaderno de Fabric y carga de datos externos
Cree un cuaderno de Fabric y conéctese al origen de datos externo con PySpark.
-
En el menú superior de almacén de lago, seleccione Abrir cuaderno > Nuevo cuaderno, que se abrirá una vez creado.
Sugerencia: tiene acceso al explorador del Almacén de lago desde este cuaderno y podrá actualizar para ver el progreso a medida que complete este ejercicio.
-
En la celda predeterminada, observe que el código está establecido en PySpark (Python) .
- Inserte el código siguiente en la celda de código, que hará lo siguiente:
- Declaración de parámetros para la cadena de conexión
- Cree la cadena de conexión
- Lectura de datos en un elemento DataFrame
# Azure Blob Storage access info blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" # Construct connection path wasbs_path = f'wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}' print(wasbs_path) # Read parquet data from Azure Blob Storage path blob_df = spark.read.parquet(wasbs_path) -
Seleccione ▷ Ejecutar celda junto a la celda de código para conectarse y leer datos en un elemento DataFrame.
Resultado esperado: El comando debe realizarse correctamente e imprimir
wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellowNota: una sesión de Spark se inicia en la primera ejecución de código, por lo que podría tardar más tiempo en completarse.
-
Para escribir los datos en un archivo, ahora necesita esa Ruta de acceso de ABFS para la carpeta RawData.
-
Inserte el código siguiente en una nueva celda de código:
# Declare file name file_name = "yellow_taxi" # Construct destination path output_parquet_path = f"**InsertABFSPathHere**/{file_name}" print(output_parquet_path) # Load the first 1000 rows as a Parquet file blob_df.limit(1000).write.mode("overwrite").parquet(output_parquet_path) -
Agregue la ruta de acceso ABFS RawData y seleccione ▷ Ejecutar celda para escribir 1000 filas en un archivo yellow_taxi.parquet.
-
Su output_parquet_path debe ser similar a:
abfss://Spark@onelake.dfs.fabric.microsoft.com/DPDemo.Lakehouse/Files/RawData/yellow_taxi - Para confirmar la carga de datos desde el Explorador de Almacén de lago, seleccione Archivos > … > Actualizar.
Ahora debería ver la nueva carpeta RawData con un “archivo”yellow_taxi.parquet, que se muestra como una carpeta con archivos de partición dentro.
Transformar y cargar datos en una tabla Delta
Es probable que la tarea de ingesta de datos no termine solo con cargar un archivo. Las tablas Delta de una instancia de Almacén de lago permiten consultas y almacenamiento escalables y flexibles, por lo que también crearemos una.
-
Cree una celda de código e inserte el código siguiente:
from pyspark.sql.functions import col, to_timestamp, current_timestamp, year, month # Read the parquet data from the specified path raw_df = spark.read.parquet(output_parquet_path) # Add dataload_datetime column with current timestamp filtered_df = raw_df.withColumn("dataload_datetime", current_timestamp()) # Filter columns to exclude any NULL values in storeAndFwdFlag filtered_df = filtered_df.filter(col("storeAndFwdFlag").isNotNull()) # Load the filtered data into a Delta table table_name = "yellow_taxi" filtered_df.write.format("delta").mode("append").saveAsTable(table_name) # Display results display(filtered_df.limit(1)) -
Seleccione ▷ Ejecutar celda junto a la celda de código.
- Esto agregará una columna de marca de tiempo dataload_datetime para registrar cuándo se cargaron los datos en una tabla Delta
- Filtrar valores NULL en storeAndFwdFlag
- Carga de datos filtrados en una tabla Delta
- Mostrar una sola fila para la validación
-
Revise y confirme los resultados mostrados, algo similar a la siguiente imagen:

Ahora se ha conectado correctamente a datos externos, los ha escrito en un archivo parquet, ha cargado los datos en un DataFrame, ha transformado los datos y los ha cargado en una tabla Delta.
Análisis de datos de tabla Delta con consultas SQL
Este laboratorio se centra en la ingesta de datos, que realmente explica el proceso de extracción, transformación y carga, pero también es útil para obtener una vista previa de los datos.
-
Cree una nueva celda de código e inserte el código siguiente:
# Load table into df delta_table_name = "yellow_taxi" table_df = spark.read.format("delta").table(delta_table_name) # Create temp SQL table table_df.createOrReplaceTempView("yellow_taxi_temp") # SQL Query table_df = spark.sql('SELECT * FROM yellow_taxi_temp') # Display 10 results display(table_df.limit(10)) -
Seleccione ▷ Ejecutar celda junto a la celda de código.
A muchos analistas de datos les gusta trabajar con sintaxis SQL. Spark SQL es una API de lenguaje SQL en Spark que puedes usar para ejecutar instrucciones SQL o incluso conservar datos en tablas relacionales.
El código que acaba de ejecutar crea una vista relacional de los datos de un DataFrame y, a continuación, usa la biblioteca spark.sql para insertar la sintaxis de Spark SQL en el código de Python, consultar la vista y devolver los resultados como un DataFrame.
Limpieza de recursos
En este ejercicio, usó cuadernos con PySpark en Fabric para cargar datos y guardarlos en Parquet. A continuación, usó ese archivo de Parquet para transformar aún más los datos. Por último, usó SQL para consultar las tablas Delta.
Si ha terminado de explorar, puede eliminar el área de trabajo que ha creado para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo para ver todos los elementos que contiene.
- Selecciona Configuración del área de trabajo y, en la sección General, desplázate hacia abajo y selecciona Quitar esta área de trabajo.
- Selecciona Eliminar para eliminar el área de trabajo.