Entrenamiento y seguimiento de modelos de Machine Learning con MLflow en Microsoft Fabric
En este laboratorio, entrenará un modelo de aprendizaje automático para predecir una medida cuantitativa de la diabetes. Entrenará un modelo de regresión con Scikit-learn, hará un seguimiento y comparará los modelos con MLflow.
Al completar este laboratorio, obtendrá experiencia práctica en aprendizaje automático y seguimiento de modelos, y aprenderá a trabajar con cuadernos, experimentos y modelos en Microsoft Fabric.
Este laboratorio se tarda aproximadamente 25 minutos en completarse.
Nota: Necesitará una evaluación gratuita de Microsoft Fabric para realizar este ejercicio.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, crea un área de trabajo con la evaluación gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabrice inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, selecciona Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Crea una nueva área de trabajo con el nombre que prefieras y selecciona un modo de licencia que incluya capacidad de Fabric (Evaluación gratuita, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
Creación de un cuaderno
Para entrenar un modelo, puede crear un cuaderno. Los cuadernos proporcionan un entorno interactivo en el que puede escribir y ejecutar código (en varios lenguajes).
-
En la barra de menús de la izquierda, selecciona Crear. En la página Nuevo, en la sección Ciencia de datos, selecciona Bloc de notas. Asígnale un nombre único que elijas.
Nota: si la opción Crear no está anclada a la barra lateral, primero debes seleccionar la opción de puntos suspensivos (…).
Al cabo de unos segundos, se abrirá un nuevo cuaderno que contiene una sola celda. Los cuadernos se componen de una o varias celdas que pueden contener código o Markdown (texto con formato).
-
Seleccione la primera celda (que actualmente es una celda de código ) y, luego, en la barra de herramientas dinámica de su parte superior derecha, use el botón M↓ para convertir la celda en una celda de Markdown.
Cuando la celda cambie a una celda de Markdown, se representará el texto que contiene.
-
Si fuera necesario, use el botón 🖉 (Editar) para cambiar la celda al modo de edición y, después, elimine el contenido y escriba el siguiente texto:
# Train a machine learning model and track with MLflow
Carga de datos en un objeto DataFrame
Ahora está listo para ejecutar código para obtener los datos y entrenar un modelo. Trabajará con el conjunto de datos de diabetes de Azure Open Datasets. Después de cargar los datos, convertirá los datos en un dataframe de Pandas, que es una estructura común para trabajar con datos en filas y columnas.
-
En su cuaderno, use el icono + Código situado debajo de la última salida de celda para agregar una nueva celda de código al cuaderno.
Sugerencia: Para ver el icono + Código, mueva el ratón hasta justo debajo y a la izquierda de la salida de la celda actual. Como alternativa, en la barra de menús, en la pestaña Editar, seleccione + Añadir celda de código.
-
Escriba el siguiente código en él:
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "mlsamples" blob_relative_path = "diabetes" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark read parquet, note that it won't load any data yet by now df = spark.read.parquet(wasbs_path) -
Use el botón ▷ Ejecutar celda situado a la izquierda de la celda para ejecutarla. Como alternativa, presione MAYÚS + ENTRAR en el teclado para ejecutar una celda.
Nota: Dado que esta es la primera vez que ha ejecutado código de Spark en esta sesión, se debe iniciar el grupo de Spark. Esto significa que la primera ejecución de la sesión puede tardar un minuto o así en completarse. Las ejecuciones posteriores serán más rápidas.
-
Use el icono +Código debajo de la salida de la celda para agregar una nueva celda de código al cuaderno y escriba en ella el código siguiente:
display(df) -
Cuando se haya completado el comando de la celda, revise la salida que aparece debajo de ella, que será algo parecido a esto:
AGE SEX BMI BP S1 S2 S3 S4 S5 S6 Y 59 2 32,1 101.0 157 93.2 38.0 4.0 4.8598 87 151 48 1 21.6 87,0 183 103.2 70.0 3.0 3.8918 69 75 72 2 30,5 93.0 156 93.6 41,0 4.0 4.6728 85 141 24 1 25,3 84.0 198 131.4 40,0 5.0 4.8903 89 206 50 1 23,0 101.0 192 125,4 52,0 4.0 4.2905 80 135 … … … … … … … … … … … La salida muestra las filas y columnas del conjunto de datos de diabetes.
-
Los datos se cargan como un dataframe de Spark. Scikit-learn esperará que el conjunto de datos de entrada sea un dataframe de Pandas. Ejecute el código siguiente para convertir el conjunto de datos en un dataframe de Pandas:
import pandas as pd df = df.toPandas() df.head()
Entrenar un modelo de Machine Learning
Ahora que ha cargado los datos, puede usarlos para entrenar un modelo de Machine Learning y predecir una medida cuantitativa de la diabetes. Entrenará un modelo de regresión mediante la biblioteca Scikit-Learn y hará un seguimiento del modelo con MLflow.
-
Ejecute el código siguiente para dividir los datos en un conjunto de datos de entrenamiento y prueba, y para separar las características de la etiqueta que desea predecir:
from sklearn.model_selection import train_test_split X, y = df[['AGE','SEX','BMI','BP','S1','S2','S3','S4','S5','S6']].values, df['Y'].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0) -
Agregue otra nueva celda de código al cuaderno, escriba en ella el código siguiente y ejecútela:
import mlflow experiment_name = "experiment-diabetes" mlflow.set_experiment(experiment_name)El código crea un experimento de MLflow llamado experiment-diabetes. En este experimento se realizará un seguimiento de los modelos.
-
Agregue otra nueva celda de código al cuaderno, escriba en ella el código siguiente y ejecútela:
from sklearn.linear_model import LinearRegression with mlflow.start_run(): mlflow.autolog() model = LinearRegression() model.fit(X_train, y_train) mlflow.log_param("estimator", "LinearRegression")El código entrena un modelo de regresión mediante la regresión lineal. Los parámetros, las métricas y los artefactos se registran automáticamente con MLflow. Además, va a registrar un parámetro denominado estimator con el valor LinearRegression.
-
Agregue otra nueva celda de código al cuaderno, escriba en ella el código siguiente y ejecútela:
from sklearn.tree import DecisionTreeRegressor with mlflow.start_run(): mlflow.autolog() model = DecisionTreeRegressor(max_depth=5) model.fit(X_train, y_train) mlflow.log_param("estimator", "DecisionTreeRegressor")El código entrena un modelo de regresión mediante regresión del árbol de decisión. Los parámetros, las métricas y los artefactos se registran automáticamente con MLflow. Además, va a registrar un parámetro denominado estimator con el valor DecisionTreeRegressor.
Uso de MLflow para buscar y ver los experimentos
Cuando haya entrenado y realizado un seguimiento de los modelos con MLflow, puede usar la biblioteca de MLflow para recuperar los experimentos y sus detalles.
-
Para enumerar todos los experimentos, use el código siguiente:
import mlflow experiments = mlflow.search_experiments() for exp in experiments: print(exp.name) -
Para recuperar un experimento específico, puede obtenerlo por su nombre:
experiment_name = "experiment-diabetes" exp = mlflow.get_experiment_by_name(experiment_name) print(exp) -
Con un nombre de experimento, puede recuperar todos los trabajos de ese experimento:
mlflow.search_runs(exp.experiment_id) -
Para comparar más fácilmente las ejecuciones y salidas del trabajo, puede configurar la búsqueda para ordenar los resultados. Por ejemplo, la celda siguiente ordena los resultados por start_time, y muestra un máximo de dos resultados:
mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=2) -
Por último, puede trazar las métricas de evaluación de varios modelos para compararlos fácilmente:
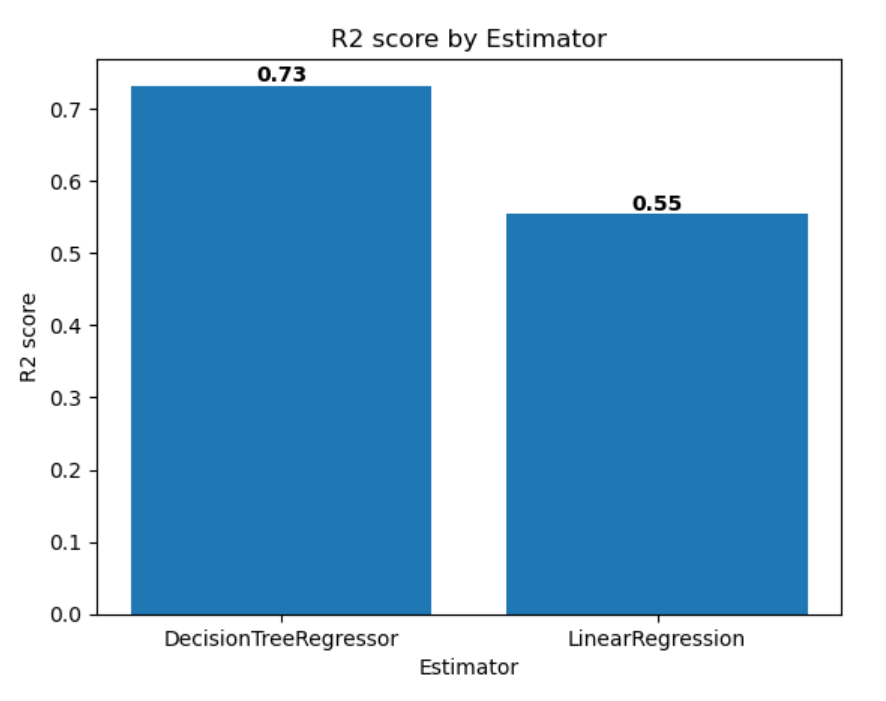
import matplotlib.pyplot as plt df_results = mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=2)[["metrics.training_r2_score", "params.estimator"]] fig, ax = plt.subplots() ax.bar(df_results["params.estimator"], df_results["metrics.training_r2_score"]) ax.set_xlabel("Estimator") ax.set_ylabel("R2 score") ax.set_title("R2 score by Estimator") for i, v in enumerate(df_results["metrics.training_r2_score"]): ax.text(i, v, str(round(v, 2)), ha='center', va='bottom', fontweight='bold') plt.show()La salida debe ser similar a la de la imagen siguiente:
Exploración de los experimentos
Microsoft Fabric realizará un seguimiento de todos los experimentos y le permitirá explorarlos visualmente.
- Vaya al área de trabajo desde la barra de menús de conectividad de la izquierda.
-
Seleccione el experimento experiment-diabetes para abrirlo.
Sugerencia: Si ve que no hay ninguna ejecución de experimentos registrada, actualice la página.
- Seleccione la pestaña Ver.
- Seleccione Ejecutar lista.
-
Seleccione las dos ejecuciones más recientes activando su casilla.
Como resultado, las dos últimas ejecuciones se compararán entre sí en el panel Comparación de métricas. De forma predeterminada, las métricas se trazan por nombre de ejecución.
- Seleccione el botón 🖉 (Editar) del gráfico que visualiza el error medio absoluto de cada ejecución.
- Cambie el tipo de visualización a ** barra**.
- Cambie el valor de eje X a estimador.
- Seleccione Reemplazar y explore el nuevo gráfico.
- Opcionalmente, puede repetir estos pasos para los demás gráficos en el panel Comparación de métricas.
Al trazar las métricas de rendimiento por estimador registrado, puede revisar qué algoritmo dio lugar a un mejor modelo.
Guardar el modelo
Después de comparar los modelos de aprendizaje automático que ha entrenado entre ejecuciones de experimentos, puede elegir aquel con el mejor rendimiento. Para usar el modelo con el mejor rendimiento, guarde el modelo y úselo para generar predicciones.
- En la información general del experimento, asegúrese de que la pestaña Ver está seleccionada.
- Seleccione Detalles de ejecución.
- Seleccione la ejecución con la puntuación de Entrenamiento de R2 más alta.
- Seleccione Guardar en el cuadro Guardar ejecución como modelo (es posible que tenga que desplazarse a la derecha para verlo).
- Seleccione Crear un nuevo modelo en la ventana emergente recién abierta.
- Seleccione la carpeta model.
- Asigne al modelo el nombre
model-diabetesy seleccione Guardar. - Seleccione Ver modelo de ML en la notificación que aparece en la parte superior derecha de la pantalla cuando se crea el modelo. También puede actualizar la ventana. El modelo guardado se vincula en Versiones del modelo.
Tenga en cuenta que el modelo, el experimento y la ejecución del experimento están vinculados, lo que le permite revisar cómo se entrena el modelo.
Guardado del cuaderno y finalización de la sesión con Spark
Ahora que ha terminado de entrenar y evaluar los modelos, puede guardar el cuaderno con un nombre descriptivo y finalizar la sesión con Spark.
- Vuelva a su cuaderno y, en la barra de menús del cuaderno, use el icono ⚙️ Configuración para ver la configuración del cuaderno.
- Establezca el nombre del cuaderno en Entrenar y comparar modelos y, luego, cierre el panel de configuración.
- En el menú del cuaderno, seleccione Detener sesión para finalizar la sesión con Spark.
Limpieza de recursos
En este ejercicio, ha creado un cuaderno y entrenado un modelo de aprendizaje automático. Ha usado Scikit-Learn para entrenar el modelo y MLflow para realizar un seguimiento de su rendimiento.
Si ha terminado de explorar el modelo y los experimentos, puede eliminar el área de trabajo que ha creado para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo para ver todos los elementos que contiene.
- En el menú … de la barra de herramientas, seleccione Configuración del área de trabajo.
- En la sección General, selecciona Quitar esta área de trabajo.