Procesamiento previo de datos con Data Wrangler en Microsoft Fabric
En este laboratorio, aprenderá a usar Data Wrangler en Microsoft Fabric para procesar previamente datos y generar código mediante una biblioteca de operaciones comunes de ciencia de datos.
Este laboratorio se tarda aproximadamente 30 minutos en completarse.
Nota: necesitarás una evaluación gratuita de Microsoft Fabric para realizar este ejercicio.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, crea un área de trabajo con la evaluación gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabrice inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, selecciona Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Crea una nueva área de trabajo con el nombre que prefieras y selecciona un modo de licencia que incluya capacidad de Fabric (Evaluación gratuita, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
Creación de un cuaderno
Para entrenar un modelo, puede crear un cuaderno. Los cuadernos proporcionan un entorno interactivo en el que puede escribir y ejecutar código (en varios lenguajes) como experimentos.
-
En la barra de menús de la izquierda, selecciona Crear. En la página Nuevo, en la sección Ciencia de datos, selecciona Bloc de notas. Asígnale un nombre único que elijas.
Nota: si la opción Crear no está anclada a la barra lateral, primero debes seleccionar la opción de puntos suspensivos (…).
Al cabo de unos segundos, se abrirá un nuevo cuaderno que contiene una sola celda. Los cuadernos se componen de una o varias celdas que pueden contener código o Markdown (texto con formato).
-
Seleccione la primera celda (que actualmente es una celda de código ) y, luego, en la barra de herramientas dinámica de su parte superior derecha, use el botón M↓ para convertir la celda en una celda de Markdown.
Cuando la celda cambie a una celda de Markdown, se representará el texto que contiene.
-
Si fuera necesario, use el botón 🖉 (Editar) para cambiar la celda al modo de edición y, después, elimine el contenido y escriba el siguiente texto:
# Perform data exploration for data science Use the code in this notebook to perform data exploration for data science.
Carga de datos en un objeto DataFrame
Ahora está listo para ejecutar código para obtener datos. Trabajará con el conjunto de datos de OJ Sales de Azure Open Datasets. Después de cargar los datos, convertirá los datos en un dataframe de Pandas, que es la estructura compatible con Data Wrangler.
-
En el cuaderno, use el icono + Código situado debajo de la celda más reciente para agregar una nueva celda de código al cuaderno.
Sugerencia: Para ver el icono + Código, mueva el ratón hasta justo debajo y a la izquierda de la salida de la celda actual. Como alternativa, en la barra de menús, en la pestaña Editar, seleccione + Añadir celda de código.
-
Escriba el código siguiente para cargar el conjunto de datos en una trama de datos.
# Azure storage access info for open dataset diabetes blob_account_name = "azureopendatastorage" blob_container_name = "ojsales-simulatedcontainer" blob_relative_path = "oj_sales_data" blob_sas_token = r"" # Blank since container is Anonymous access # Set Spark config to access blob storage wasbs_path = f"wasbs://%s@%s.blob.core.windows.net/%s" % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set("fs.azure.sas.%s.%s.blob.core.windows.net" % (blob_container_name, blob_account_name), blob_sas_token) print("Remote blob path: " + wasbs_path) # Spark reads csv df = spark.read.csv(wasbs_path, header=True) -
Use el botón ▷ Ejecutar celda situado a la izquierda de la celda para ejecutarla. Como alternativa, puede presionar
SHIFT+ENTERen el teclado para ejecutar una celda.Nota: Dado que esta es la primera vez que ha ejecutado código de Spark en esta sesión, se debe iniciar el grupo de Spark. Esto significa que la primera ejecución de la sesión puede tardar un minuto o así en completarse. Las ejecuciones posteriores serán más rápidas.
-
Use el icono +Código debajo de la salida de la celda para agregar una nueva celda de código al cuaderno y escriba en ella el código siguiente:
import pandas as pd df = df.toPandas() df = df.sample(n=500, random_state=1) df['WeekStarting'] = pd.to_datetime(df['WeekStarting']) df['Quantity'] = df['Quantity'].astype('int') df['Advert'] = df['Advert'].astype('int') df['Price'] = df['Price'].astype('float') df['Revenue'] = df['Revenue'].astype('float') df = df.reset_index(drop=True) df.head(4) -
Cuando se haya completado el comando de la celda, revise la salida que aparece debajo de ella, que será algo parecido a esto:
WeekStarting Tienda Marca Quantity Anuncio Price Ingresos 0 1991-10-17 947 minute.maid 13306 1 2,42 32200.52 1 1992-03-26 1293 dominicks 18596 1 1,94 36076.24 2 1991-08-15 2278 dominicks 17457 1 2.14 37357.98 3 1992-09-03 2175 tropicana 9652 1 2,07 19979.64 … … … … … … … … La salida muestra las cuatro primeras filas del conjunto de datos de OJ Sales.
Visualización de estadísticas de resumen
Ahora que hemos cargado los datos, el siguiente paso consiste en preprocesarlos mediante Data Wrangler. El preprocesamiento es un paso fundamental en cualquier flujo de trabajo de aprendizaje automático. Implica limpiar los datos y transformarlos en un formato que se pueda introducir en un modelo de Machine Learning.
-
Seleccione Datos en la cinta de opciones del cuaderno y, a continuación, seleccione Iniciar Data Wrangler.
-
Seleccione el conjunto de datos
df. Cuando se inicia Data Wrangler, se genera una introducción descriptiva del dataframe en el panel Resumen. -
Seleccione la función Ingresos y observe la distribución de datos de esta función.
-
Revise los detalles del panel lateral Resumen y observe los valores de las estadísticas.
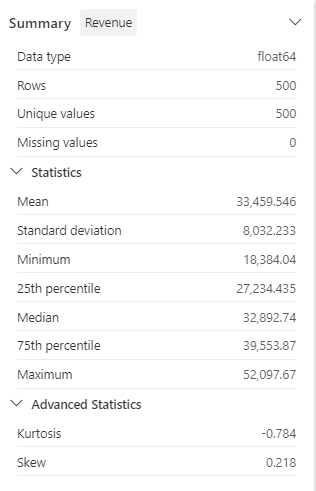
¿Cuáles son algunas de las conclusiones que se pueden extraer? Los ingresos promedio son de, aproximadamente, 33 459,54 $, con una desviación estándar de 8032,23 $. Esto sugiere que los valores de los ingresos se reparten en un intervalo de, aproximadamente, 8032,23 USD con respecto a la media.
Aplicación de formato a los datos de texto
Ahora vamos a aplicar algunas transformaciones a la característica Marca.
-
En el panel Data Wrangler, seleccione la característica
Branden la cuadrícula. -
Vaya al panel Operaciones, expanda Buscar y reemplazar y, a continuación, seleccione Buscar y reemplazar.
-
En el panel Buscar y reemplazar, cambie las propiedades siguientes:
- Valor anterior: “
.” - Nuevo valor: “
Puede ver los resultados de la operación en vista previa automática en la cuadrícula de presentación.
- Valor anterior: “
-
Seleccione Aplicar.
-
Vuelva al panel Operaciones y expanda Formato.
-
Seleccione Poner en mayúsculas el primer carácter. Active el botón de alternancia Poner en mayúscula todas las palabras y, a continuación, seleccione Aplicar.
-
Seleccione Agregar código al cuaderno. Además, también puede copiar el código y guardar el conjunto de datos transformado como un archivo CSV.
Nota: El código se copia automáticamente en la celda del cuaderno y está listo para su uso.
-
Reemplace las líneas 10 y 11 por el código
df = clean_data(df), ya que el código generado en Data Wrangler no sobrescribe el dataframe original. El bloque de código final debería ser similar al siguiente:def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() return df df = clean_data(df) -
Ejecute la celda de código y compruebe la variable
Brand.df['Brand'].unique()El resultado debe mostrar los valores Minute Maid, Dominicks y Tropicana.
Ha aprendido a manipular gráficamente los datos de texto y a generar fácilmente código mediante Data Wrangler.
Aplicación de transformación de codificación one-hot
Ahora, generaremos el código para aplicar la transformación de codificación one-hot a nuestros datos como parte de nuestros pasos de preprocesamiento. Para que nuestro escenario sea más práctico, empezamos generando algunos datos de ejemplo. Esto nos permite simular una situación real y nos proporciona una característica que se puede trabajar.
-
Inicie Data Wrangler en el menú superior del dataframe
df. -
Seleccione la característica
Branden la cuadrícula. -
En el panel Operaciones, expanda Fórmulas y, a continuación, seleccione Codificación one-hot.
-
En el panel Codificación de acceso único, seleccione Aplicar.
Navegue hasta el final de la cuadrícula de visualización de Data Wrangler. Observe que se agregaron tres nuevas características (
Brand_Dominicks,Brand_Minute MaidyBrand_Tropicana) y se quitó la característicaBrand. -
Cierre Data Wrangler sin generar el código.
Operaciones de ordenación y filtrado
Imagine que necesitamos revisar los datos de ingresos de una tienda específica y, a continuación, ordenar los precios de los productos. En los pasos siguientes, usamos Data Wrangler para filtrar y analizar el dataframe df.
-
Inicie Data Wrangler para el dataframe
df. -
En el panel Operaciones, expanda Ordenar y filtrar.
-
Seleccione la opción Filtro.
-
En el panel Filtrar, agregue la siguiente condición:
- Columna de destino:
Store - Operación:
Equal to - Valor:
1227 - Acción:
Keep matching rows
- Columna de destino:
-
Seleccione Aplicar y observe los cambios en la cuadrícula de visualización de Data Wrangler.
-
Seleccione la característica Ingresos y, a continuación, revise los detalles del panel lateral Resumen.
¿Cuáles son algunas de las conclusiones que se pueden extraer? La asimetría es -0,751, lo que indica un ligero sesgo a la izquierda (sesgo negativo). Esto significa que la cola izquierda de la distribución es ligeramente más larga que la cola derecha. En otras palabras, hay un número de períodos con ingresos significativamente por debajo de la media.
-
Vuelva al panel Operaciones y expanda Ordenar y filtrar.
-
Seleccione Ordenar valores.
-
En el panel Ordenar valores, seleccione las siguientes propiedades:
- Nombre de la columna:
Price - Criterio de ordenación:
Descending
- Nombre de la columna:
-
Seleccione Aplicar.
El precio de producto más alto para la tienda 1227 es 2,68 $. Con solo unos pocos registros es más fácil identificar el precio de producto más alto, pero tenga en cuenta la complejidad al tratar con miles de resultados.
Examen y eliminación de pasos
Supongamos que cometió un error y necesitase quitar el orden que creó en el paso anterior. Siga estos pasos para quitarla:
-
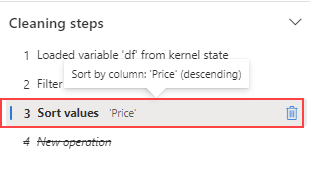
Vaya al panel Pasos de limpieza.
-
Seleccione el paso Ordenar valores.
-
Seleccione el icono de eliminación para quitarla.
Importante: La vista de cuadrícula y el resumen se limitan al paso actual.
Observe que los cambios se revierten al paso anterior, que es el paso Filtrar.
-
Cierre Data Wrangler sin generar el código.
Agregar datos
Supongamos que necesitamos comprender el promedio de ingresos generados por cada marca. En los pasos siguientes, se usa Data Wrangler para realizar un grupo por operación en el dataframe df.
-
Inicie Data Wrangler para el dataframe
df. -
De vuelta en el panel Operaciones, seleccione Agrupar por y agregar.
-
En el panel Columnas para agrupar por, seleccione la característica
Brand. -
Seleccione Agregar agregación.
-
En la propiedad Columna para agregar, seleccione la característica
Revenue. -
Seleccione
Meanen la propiedad Tipo de agregación. -
Seleccione Aplicar.
-
Seleccione Copiar código en el Portapapeles.
-
Cierre Data Wrangler sin generar el código.
-
Combine el código de la transformación de la variable
Brandcon el código generado por el paso de agregación de la funciónclean_data(df). El bloque de código final debería ser similar al siguiente:def clean_data(df): # Replace all instances of "." with " " in column: 'Brand' df['Brand'] = df['Brand'].str.replace(".", " ", case=False, regex=False) # Capitalize the first character in column: 'Brand' df['Brand'] = df['Brand'].str.title() # Performed 1 aggregation grouped on column: 'Brand' df = df.groupby(['Brand']).agg(Revenue_mean=('Revenue', 'mean')).reset_index() return df df = clean_data(df) -
Ejecute el código de la celda.
-
Compruebe los datos del dataframe.
print(df)Resultados:
Marca Revenue_mean 0 Dominicks 33206.330958 1 Minute Maid 33532.999632 2 Tropicana 33637.863412
Ha generado el código para algunas de las operaciones de procesamiento previo y lo ha copiado en el cuaderno como una función, que luego puede ejecutar, reutilizar o modificar según sea necesario.
Guardado del cuaderno y finalización de la sesión con Spark
Ahora que ha terminado el procesamiento previo de los datos para el modelado, puede guardar el cuaderno con un nombre descriptivo y finalizar la sesión con Spark.
- En la barra de menús del cuaderno, use el icono ⚙️ Configuración para ver la configuración del cuaderno.
- Establezca el nombre del cuaderno en Procesamiento previo de datos con Data Wrangler y, luego, cierre el panel de configuración.
- En el menú del cuaderno, seleccione Detener sesión para finalizar la sesión con Spark.
Limpieza de recursos
En este ejercicio, ha creado un cuaderno y ha usado Data Wrangler para explorar y procesar previamente los datos de un modelo de Machine Learning.
Si ha terminado de explorar los pasos de procesamiento previo, puede eliminar el área de trabajo que creó para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo para ver todos los elementos que contiene.
- En el menú … de la barra de herramientas, seleccione Configuración del área de trabajo.
- En la sección General, selecciona Quitar esta área de trabajo.