Carga de datos en un almacenamiento mediante T-SQL
En Microsoft Fabric, un almacenamiento de datos proporciona una base de datos relacional para análisis a gran escala. A diferencia del punto de conexión de SQL de solo lectura predeterminado para las tablas definidas en un almacén de lago, un almacenamiento de datos proporciona semántica de SQL completa; incluida la capacidad de insertar, actualizar y eliminar datos de las tablas.
Este laboratorio se tarda aproximadamente 30 minutos en completarse.
Nota: necesitarás una evaluación gratuita de Microsoft Fabric para realizar este ejercicio.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, crea un área de trabajo con la evaluación gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabrice inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, selecciona Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Crea una nueva área de trabajo con el nombre que prefieras y selecciona un modo de licencia que incluya capacidad de Fabric (Evaluación gratuita, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
Creación de un almacén de lago y carga de archivos
En nuestro escenario, dado que no tenemos datos disponibles, debemos ingerirlos para cargar el almacenamiento. Creará una instancia de Data Lakehouse para los archivos de datos que va a usar para cargar el almacenamiento.
-
Selecciona + Nuevo elemento y crea un nuevo Almacén de lago de datos con el nombre que prefieras.
Al cabo de un minuto más o menos, se creará un nuevo almacén de lago vacío. Debe ingerir algunos datos en el almacén de lago de datos para su análisis. Hay varias maneras de hacerlo, pero en este ejercicio descargará un archivo CSV en el equipo local (o máquina virtual de laboratorio si procede) y a continuación, lo cargará en el almacén de lago.
-
Descargue el archivo de este ejercicio desde
https://github.com/MicrosoftLearning/dp-data/raw/main/sales.csv. -
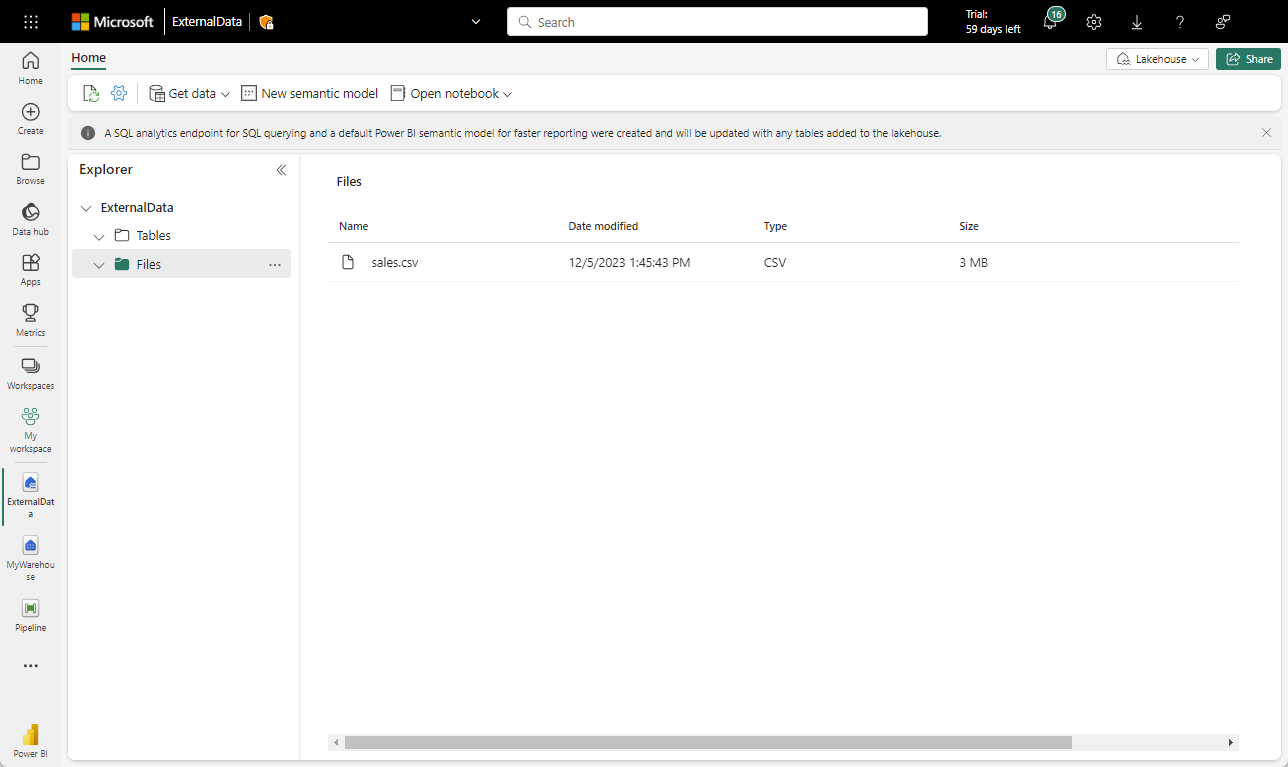
Vuelva a la pestaña del explorador web que contiene el almacén de lago y, en el menú … de la carpeta Archivos del panel Explorador, seleccione Cargar y Cargar archivos y, luego, cargue el archivo sales.csv del equipo local (o la máquina virtual de laboratorio, si procede) en el almacén de lago.
-
Una vez cargados los archivos, seleccione Archivos. Compruebe que se ha cargado el archivo CSV, como se muestra aquí:
Creación de una tabla en el almacén de lago
-
En el menú … del archivo sales.csv en el panelExplorer, seleccione Cargar en tablas y, a continuación, Nueva tabla.
- Proporcione la siguiente información en el cuadro de diálogo Cargar archivo en nueva tabla.
- Nuevo nombre de tabla: staging_sales
- Usar encabezado para los nombres de columnas: seleccionado
- Separador: ,
- Seleccione Cargar.
Crear un almacén
Ahora que tiene un área de trabajo, una instancia de un almacén de lago y la tabla de ventas con los datos que necesita, es el momento de crear un almacenamiento de datos.
-
En la barra de menús de la izquierda, selecciona Crear. En la página Nuevo, en la sección Almacenamiento de datos, selecciona Almacén. Asígnale un nombre único que elijas.
Nota: si la opción Crear no está anclada a la barra lateral, primero debes seleccionar la opción de puntos suspensivos (…).
Al cabo de un minuto más o menos, se creará un nuevo almacén:
Creación de una tabla de hechos, dimensiones y vista
Vamos a crear las tablas de hechos y las dimensiones de los datos de Sales. También creará una vista que apunte a una instancia de un almacén de lago, lo que simplifica el código del procedimiento almacenado que usaremos para cargar.
-
En el área de trabajo, seleccione el almacén que creó.
-
En la barra de herramientas del almacén, selecciona Nueva consulta SQL y después copia y ejecuta la siguiente consulta.
CREATE SCHEMA [Sales] GO IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Fact_Sales' AND SCHEMA_NAME(schema_id)='Sales') CREATE TABLE Sales.Fact_Sales ( CustomerID VARCHAR(255) NOT NULL, ItemID VARCHAR(255) NOT NULL, SalesOrderNumber VARCHAR(30), SalesOrderLineNumber INT, OrderDate DATE, Quantity INT, TaxAmount FLOAT, UnitPrice FLOAT ); IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Dim_Customer' AND SCHEMA_NAME(schema_id)='Sales') CREATE TABLE Sales.Dim_Customer ( CustomerID VARCHAR(255) NOT NULL, CustomerName VARCHAR(255) NOT NULL, EmailAddress VARCHAR(255) NOT NULL ); ALTER TABLE Sales.Dim_Customer add CONSTRAINT PK_Dim_Customer PRIMARY KEY NONCLUSTERED (CustomerID) NOT ENFORCED GO IF NOT EXISTS (SELECT * FROM sys.tables WHERE name='Dim_Item' AND SCHEMA_NAME(schema_id)='Sales') CREATE TABLE Sales.Dim_Item ( ItemID VARCHAR(255) NOT NULL, ItemName VARCHAR(255) NOT NULL ); ALTER TABLE Sales.Dim_Item add CONSTRAINT PK_Dim_Item PRIMARY KEY NONCLUSTERED (ItemID) NOT ENFORCED GOImportante: En un almacenamiento de datos, las restricciones de clave externa no siempre son necesarias en el nivel de tabla. Aunque las restricciones de clave externa pueden ayudar a garantizar la integridad de los datos, también pueden sobrecargar el proceso ETL (extracción, transformación, carga) y ralentizar la carga de datos. La decisión de usar restricciones de clave externa en un almacenamiento de datos debe basarse en una consideración cuidadosa de las ventajas entre la integridad y el rendimiento de los datos.
-
In el Explorer, vaya a Esquemas» Sales » Tablas. Tenga en cuenta las tablas Fact_Sales, Dim_Customer y Dim_Item que acaba de crear.
Nota: si no puedes ver los nuevos esquemas, abre el menú … para Tablas en el panel Explorador y selecciona Actualizar.
-
Abra un nuevo Nuevo editor de consultas SQL y, a continuación, copie y ejecute la siguiente consulta. Actualice *
* con el almacén de lago que creó. CREATE VIEW Sales.Staging_Sales AS SELECT * FROM [<your lakehouse name>].[dbo].[staging_sales]; -
En el Explorer, vaya a Esquemas» Sales » Vistas. Tenga en cuenta la vista Staging_Sales que ha creado.
Carga de datos en el almacenamiento
Ahora que se crean las tablas de hechos y dimensiones, vamos a crear un procedimiento almacenado para cargar los datos de nuestro almacén de lago en el almacén. Debido al punto de conexión SQL automático creado al crear el almacén de lago, puede acceder directamente a los datos de su instancia de almacén de lago desde el almacén mediante consultas de T-SQL y entre bases de datos.
Por motivos de simplicidad en este caso práctico, usará el nombre del cliente y el nombre del elemento como claves principales.
-
Cree un nuevo Nuevo editor de consultas SQL y, a continuación, copie y ejecute la siguiente consulta.
CREATE OR ALTER PROCEDURE Sales.LoadDataFromStaging (@OrderYear INT) AS BEGIN -- Load data into the Customer dimension table INSERT INTO Sales.Dim_Customer (CustomerID, CustomerName, EmailAddress) SELECT DISTINCT CustomerName, CustomerName, EmailAddress FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear AND NOT EXISTS ( SELECT 1 FROM Sales.Dim_Customer WHERE Sales.Dim_Customer.CustomerName = Sales.Staging_Sales.CustomerName AND Sales.Dim_Customer.EmailAddress = Sales.Staging_Sales.EmailAddress ); -- Load data into the Item dimension table INSERT INTO Sales.Dim_Item (ItemID, ItemName) SELECT DISTINCT Item, Item FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear AND NOT EXISTS ( SELECT 1 FROM Sales.Dim_Item WHERE Sales.Dim_Item.ItemName = Sales.Staging_Sales.Item ); -- Load data into the Sales fact table INSERT INTO Sales.Fact_Sales (CustomerID, ItemID, SalesOrderNumber, SalesOrderLineNumber, OrderDate, Quantity, TaxAmount, UnitPrice) SELECT CustomerName, Item, SalesOrderNumber, CAST(SalesOrderLineNumber AS INT), CAST(OrderDate AS DATE), CAST(Quantity AS INT), CAST(TaxAmount AS FLOAT), CAST(UnitPrice AS FLOAT) FROM [Sales].[Staging_Sales] WHERE YEAR(OrderDate) = @OrderYear; END -
Cree un nuevo Nuevo editor de consultas SQL y, a continuación, copie y ejecute la siguiente consulta.
EXEC Sales.LoadDataFromStaging 2021Nota: En este caso, solo estamos cargando datos del año 2021. Sin embargo, tiene la opción de modificarlo para cargar datos de años anteriores.
Ejecución de consultas de análisis
Vamos a ejecutar algunas consultas analíticas para validar los datos en el almacenamiento.
-
En el menú superior, seleccione Nueva consulta SQLy, a continuación, copie y ejecute la siguiente consulta.
SELECT c.CustomerName, SUM(s.UnitPrice * s.Quantity) AS TotalSales FROM Sales.Fact_Sales s JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID WHERE YEAR(s.OrderDate) = 2021 GROUP BY c.CustomerName ORDER BY TotalSales DESC;Nota: Esta consulta muestra los clientes por ventas totales para el año 2021. El cliente con las ventas totales más altas del año especificado es Jordan Turner, con unas ventas totales de 14686.69.
-
En el menú superior, seleccione Nueva consulta SQLo reutilice el mismo editor y, a continuación, copie y ejecute la siguiente consulta.
SELECT i.ItemName, SUM(s.UnitPrice * s.Quantity) AS TotalSales FROM Sales.Fact_Sales s JOIN Sales.Dim_Item i ON s.ItemID = i.ItemID WHERE YEAR(s.OrderDate) = 2021 GROUP BY i.ItemName ORDER BY TotalSales DESC;Nota: En esta consulta se muestran los elementos iniciales por ventas totales para el año 2021. Estos resultados sugieren que el modelo Mountain-200 bike, en los colores negro y plateado, fue el elemento más popular entre los clientes en 2021.
-
En el menú superior, seleccione Nueva consulta SQLo reutilice el mismo editor y, a continuación, copie y ejecute la siguiente consulta.
WITH CategorizedSales AS ( SELECT CASE WHEN i.ItemName LIKE '%Helmet%' THEN 'Helmet' WHEN i.ItemName LIKE '%Bike%' THEN 'Bike' WHEN i.ItemName LIKE '%Gloves%' THEN 'Gloves' ELSE 'Other' END AS Category, c.CustomerName, s.UnitPrice * s.Quantity AS Sales FROM Sales.Fact_Sales s JOIN Sales.Dim_Customer c ON s.CustomerID = c.CustomerID JOIN Sales.Dim_Item i ON s.ItemID = i.ItemID WHERE YEAR(s.OrderDate) = 2021 ), RankedSales AS ( SELECT Category, CustomerName, SUM(Sales) AS TotalSales, ROW_NUMBER() OVER (PARTITION BY Category ORDER BY SUM(Sales) DESC) AS SalesRank FROM CategorizedSales WHERE Category IN ('Helmet', 'Bike', 'Gloves') GROUP BY Category, CustomerName ) SELECT Category, CustomerName, TotalSales FROM RankedSales WHERE SalesRank = 1 ORDER BY TotalSales DESC;Nota: Los resultados de esta consulta muestran el cliente superior para cada una de las categorías: Bicicleta, casco y guantes, en función de sus ventas totales. Por ejemplo, Joan Coleman es el cliente principal de la categoría Guantes.
La información de categoría se extrajo de la columna
ItemNamemediante la manipulación de cadenas, ya que no hay ninguna columna de categoría independiente en la tabla de dimensiones. Este enfoque supone que los nombres de elemento siguen una convención de nomenclatura coherente. Si los nombres de elemento no siguen una convención de nomenclatura coherente, es posible que los resultados no reflejen con precisión la categoría verdadera de cada elemento.
En este ejercicio, ha creado una instancia de almacén de lago y un almacenamiento de datos con varias tablas. Ha ingerido datos y ha usado consultas entre bases de datos para cargar datos desde un almacén de lago al almacén. Además, ha usado la herramienta de consulta para realizar consultas analíticas.
Limpieza de recursos
Si ha terminado de explorar el almacenamiento de datos, puede eliminar el área de trabajo que creó para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo para ver todos los elementos que contiene.
- Selecciona Configuración del área de trabajo y, en la sección General, desplázate hacia abajo y selecciona Quitar esta área de trabajo.
- Selecciona Eliminar para eliminar el área de trabajo.