Ingesta de datos con una canalización en Microsoft Fabric
Un almacén de lago de datos es un almacén de datos analíticos común para soluciones de análisis a escala de la nube. Una de las tareas principales de un ingeniero de datos es implementar y administrar la ingesta de datos de varios orígenes de datos operativos en el almacén de lago. En Microsoft Fabric, puede implementar soluciones de extracción, transformación y carga (ETL) o extracción, carga y transformación (ELT) para la ingesta de datos mediante la creación de canalizaciones.
Fabric también admite Apache Spark, lo que le permite escribir y ejecutar código para procesar datos a gran escala. Al combinar las funcionalidades de canalización y de Spark en Fabric, puede implementar una lógica compleja de ingesta de datos que copia los datos de orígenes externos en el almacenamiento de OneLake en el que se basa el almacén de lago y, luego, usa código de Spark para realizar transformaciones de datos personalizadas antes de cargarlos en tablas para su análisis.
Este laboratorio tardará aproximadamente 45 minutos en completarse.
[!Note] Para completar este ejercicio, necesitas acceder a un inquilino de Microsoft Fabric.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, crea un área de trabajo con la evaluación gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabric-developere inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, seleccione Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Cree una nueva área de trabajo con el nombre que prefiera y seleccione un modo de licencia en la sección Avanzado que incluya la capacidad de Fabric (Prueba, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
Crear un almacén de lago
Ahora que tiene un área de trabajo, es el momento de crear un almacén de lago de datos en el cual ingerirá los datos.
-
En la barra de menús de la izquierda, selecciona Crear. En la página Nuevo, en la sección Ingeniería de datos, selecciona Almacén de lago de datos. Asígnale un nombre único que elijas.
Nota: si la opción Crear no está anclada a la barra lateral, primero debes seleccionar la opción de puntos suspensivos (…).
Al cabo de un minuto más o menos, se creará un nuevo almacén de lago sin tablas ni archivos.
-
En el panel del Explorador de la izquierda, en el menú … del nodo Archivos, selecciona Nueva subcarpeta y crea una subcarpeta llamada new_data.
Crear una canalización
Una manera sencilla de ingerir datos consiste en usar una actividad Copiar datos en una canalización para extraer los datos de un origen y copiarlos en un archivo del almacén de lago.
- En la página Inicio de tu instancia de tu almacén de lago, selecciona Obtener datos, selecciona Nueva canalización de datos y crea una canalización de datos denominada
Ingest Sales Data. - Si el asistente Copiar datos no se abre automáticamente, selecciona Copiar datos > Utilizar asistente de copia en la página del editor de canalización.
-
En el Asistente para copiar datos, en la página Elegir origen de datos, escribe HTTP en la barra de búsqueda y luego selecciona HTTP en la sección Nuevos orígenes.
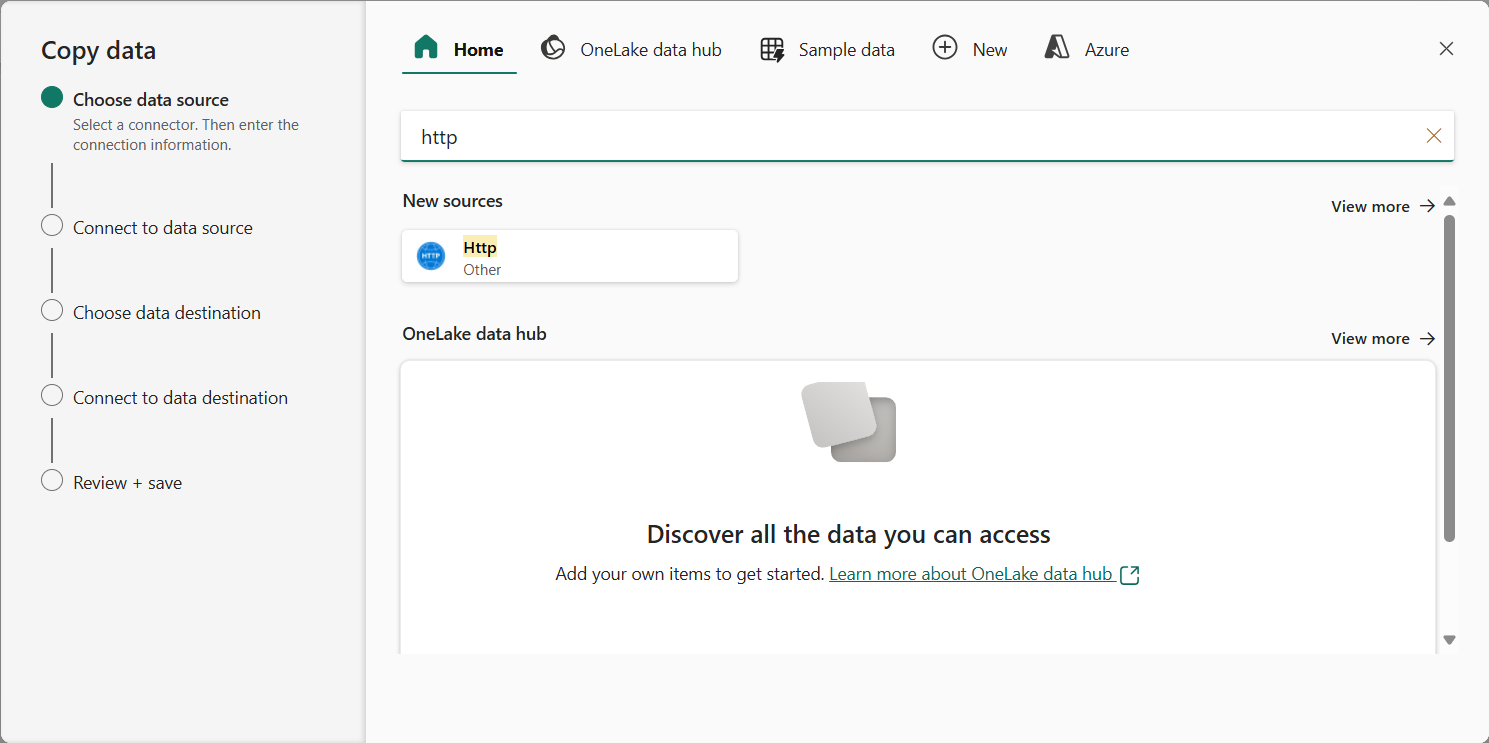
- En el panel Conectarse al origen de datos, especifica la siguiente configuración para la conexión a tu origen de datos:
- URL:
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv - Conexión: Crear nueva conexión.
- Nombre de la conexión: especifique un nombre único.
- Puerta de enlace de datos: (ninguna)
- Tipo de autenticación: Anónima.
- URL:
- Seleccione Siguiente. A continuación, asegúrese de que se seleccionan las siguientes opciones:
- Dirección URL relativa: dejar en blanco
- Request method (Método de solicitud): GET
- Encabezados adicionales: dejar en blanco
- Copia binaria: sin seleccionar
- Tiempo de espera de solicitud: dejar en blanco
- Número máximo de conexiones simultáneas: dejar en blanco
- Seleccione Siguiente y espere a que se muestreen los datos y, luego, asegúrese de que se seleccionan las siguientes opciones de configuración:
- Formato de archivo: DelimitedText
- Delimitador de columna: coma (,)
- Delimitador de fila: avance de línea (\n)
- Primera fila como encabezado: seleccionada
- Tipo de compresión: ninguno
- Seleccione Vista previa de datos para ver un ejemplo de los datos que se ingerirán. A continuación, cierre la vista previa de datos y seleccione Siguiente.
- En la página Conectar al destino de datos, establece las siguientes opciones de destino de datos y, a continuación, selecciona Siguiente:
- Carpeta raíz: Archivos.
- Nombre de la ruta de acceso de la carpeta: new_data.
- Nombre de archivo: sales.csv.
- Comportamiento de copia: ninguno
- Establezca las siguientes opciones de formato de archivo y seleccione Siguiente:
- Formato de archivo: DelimitedText
- Delimitador de columna: coma (,)
- Delimitador de fila: avance de línea (\n)
- Agregar encabezado al archivo: seleccionado
- Tipo de compresión: ninguno
-
En la página Copiar resumen, revise los detalles de la operación de copia y, luego, seleccione Guardar y ejecutar.
Se crea una nueva canalización que contiene una actividad Copiar datos, como se muestra aquí:
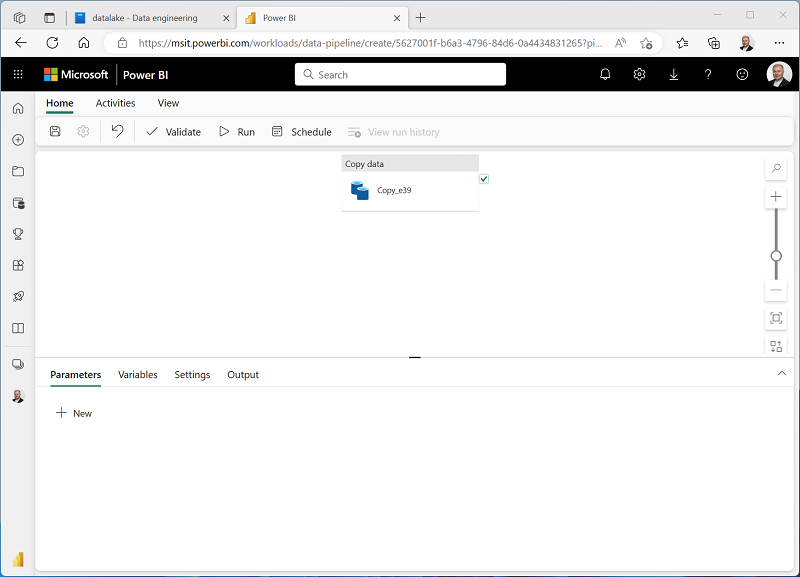
- Cuando la canalización comienza a ejecutarse, puede supervisar su estado en el panel Salida en el diseñador de canalizaciones. Use el icono ↻ (Actualizar) para actualizar el estado y espere hasta que la operación se haya realizado correctamente.
- En la barra de menús de la izquierda, seleccione el almacén de lago.
- En la página Inicio, en el panel Explorador, expande Archivos y selecciona la carpeta new_data para comprobar que se ha copiado el archivo sales.csv.
Creación de un cuaderno
-
En la página Inicio del almacén de lago, en el menú Abrir cuaderno, seleccione Nuevo cuaderno.
Al cabo de unos segundos, se abrirá un nuevo cuaderno que contiene una sola celda. Los cuadernos se componen de una o varias celdas que pueden contener código o Markdown (texto con formato).
-
Seleccione la celda existente en el cuaderno, que contiene código sencillo y, luego, reemplace el código predeterminado por la siguiente declaración de variables.
table_name = "sales" -
En el menú … de la celda (en su parte superior derecha), seleccione Alternar celda de parámetro. Esta acción configura la celda para que las variables declaradas en ella se traten como parámetros al ejecutar el cuaderno desde una canalización.
-
En la celda de parámetros, use el botón +Código para agregar una nueva celda de código. A continuación, agregue a ella el código siguiente:
from pyspark.sql.functions import * # Read the new sales data df = spark.read.format("csv").option("header","true").load("Files/new_data/*.csv") ## Add month and year columns df = df.withColumn("Year", year(col("OrderDate"))).withColumn("Month", month(col("OrderDate"))) # Derive FirstName and LastName columns df = df.withColumn("FirstName", split(col("CustomerName"), " ").getItem(0)).withColumn("LastName", split(col("CustomerName"), " ").getItem(1)) # Filter and reorder columns df = df["SalesOrderNumber", "SalesOrderLineNumber", "OrderDate", "Year", "Month", "FirstName", "LastName", "EmailAddress", "Item", "Quantity", "UnitPrice", "TaxAmount"] # Load the data into a table df.write.format("delta").mode("append").saveAsTable(table_name)Este código carga los datos del archivo sales.csv ingerido por la actividad Copiar datos, aplica lógica de transformación y guarda los datos transformados en una tabla, anexando los datos si la tabla ya existe.
-
Compruebe que los cuadernos tienen un aspecto similar al siguiente y, luego, use el botón ▷ Ejecutar todo en la barra de herramientas para ejecutar todas las celdas que contiene.
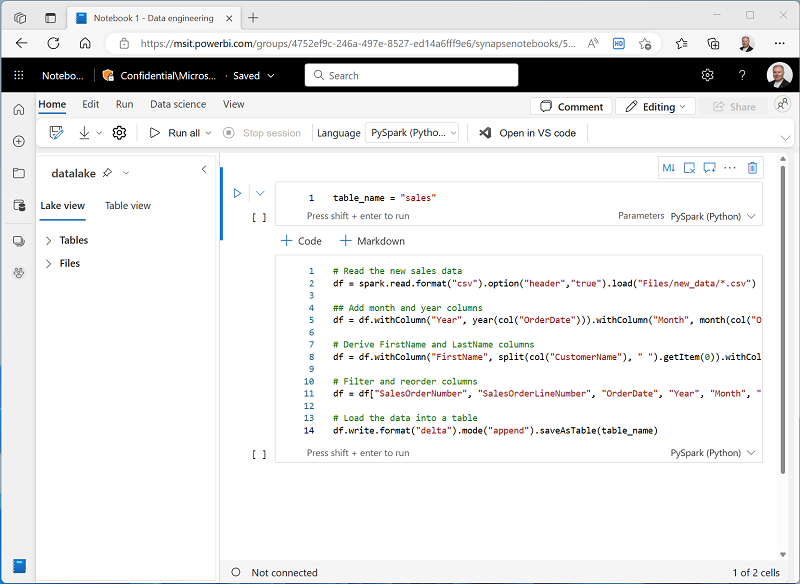
Nota: Dado que esta es la primera vez que ha ejecutado código de Spark en esta sesión, se debe iniciar el grupo de Spark. Esto significa que la primera celda puede tardar un minuto o así en completarse.
- Una vez completada la ejecución del cuaderno, en el panel Explorador de la izquierda, en el menú … de Tablas, selecciona Actualizar y comprueba que se ha creado una tabla sales.
- En la barra de menús del cuaderno, use el icono ⚙️ Configuración para ver la configuración del cuaderno. A continuación, establece el Nombre del cuaderno en
Load Salesy cierra el panel de configuración. - En la barra de menús central, a la izquierda, seleccione el almacén de lago.
- En el panel Explorador, actualice la vista. A continuación, expanda Tablas y seleccione la tabla sales para ver una vista previa de los datos que contiene.
Modificación de la canalización
Ahora que ha implementado un cuaderno para transformar los datos y cargarlos en una tabla, puede incorporarlo a una canalización para crear un proceso de ETL reutilizable.
- En la barra de menús central, a la izquierda, seleccione la canalización Ingerir datos de ventas que creó anteriormente.
-
En la pestaña Actividades, en la lista Todas las actividades, selecciona Eliminar datos. A continuación, coloque la nueva actividad Eliminar datos a la izquierda de la actividad Copiar datos y conecte su salida Al finalizar a la actividad Copiar datos, como se muestra aquí:
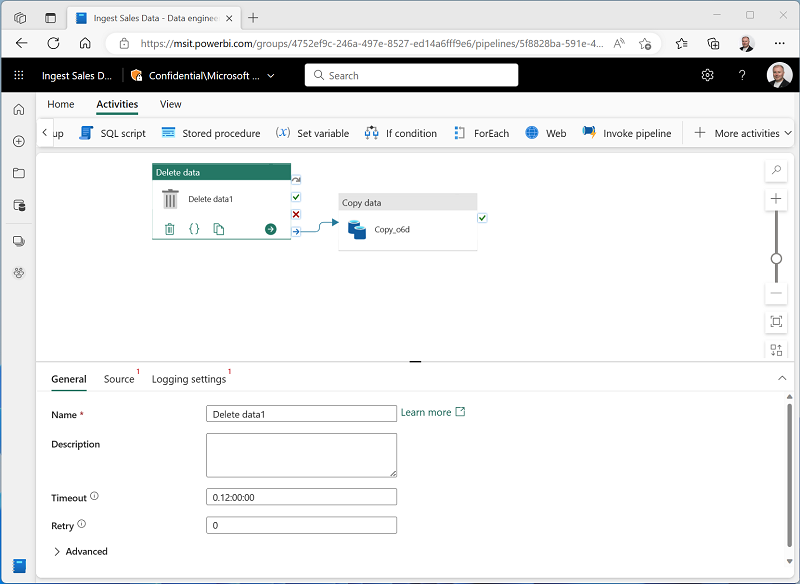
- Seleccione la actividad Eliminar datos y, en el panel debajo del lienzo de diseño, establezca las propiedades siguientes:
- General:
- Nombre:
Delete old files
- Nombre:
- Origen
- Conexión: Almacén de lago
- Tipo de ruta de acceso de archivo: ruta de acceso de archivo comodín.
- Ruta de acceso de la carpeta: Archivos / new_data.
- Nombre de archivo comodín:
*.csv - Recursivamente: Seleccionado.
- Configuración del registro:
- Habilitar registro: No seleccionado.
Esta configuración garantiza que se eliminan los archivos .csv existentes antes de copiar el archivo sales.csv.
- General:
- En el diseñador de canalizaciones, en la pestaña Actividades, seleccione Cuaderno para agregar una actividad Cuaderno a la canalización.
-
Seleccione la actividad Copiar datos y, luego, conecte su salida Al finalizar a la actividad Cuaderno, como se muestra aquí:
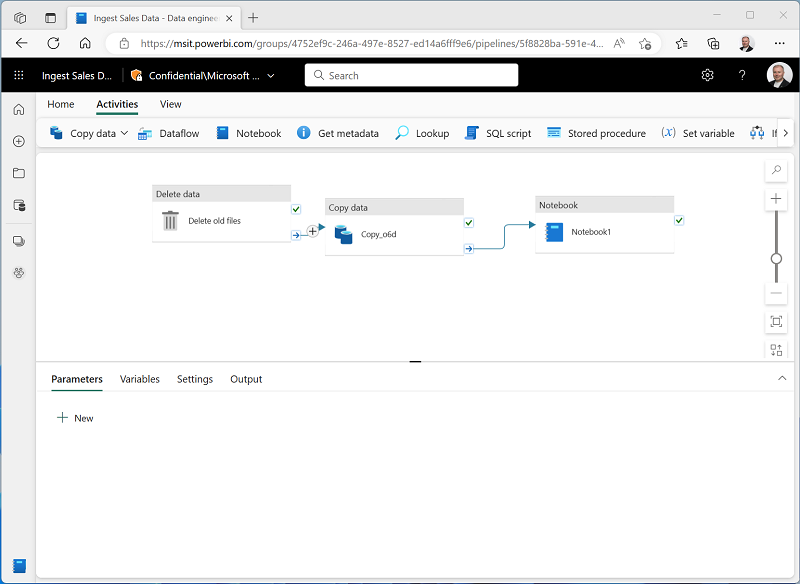
- Seleccione la actividad Cuaderno y, luego, en el panel debajo del lienzo de diseño, establezca las siguientes propiedades:
- General:
- Nombre:
Load Sales notebook
- Nombre:
- Configuración:
- Cuaderno: Cargar ventas.
-
Parámetros base: agregue un nuevo parámetro con las siguientes propiedades:
Nombre Tipo Valor table_name String new_sales
El parámetro table_name se pasará al cuaderno e invalidará el valor predeterminado asignado a la variable table_name en la celda de parámetros.
- General:
-
En la pestaña Inicio, use el icono 🖫 (Guardar) para guardar la canalización. A continuación, use el botón ▷ Ejecutar para ejecutar la canalización y espere a que se completen todas las actividades.
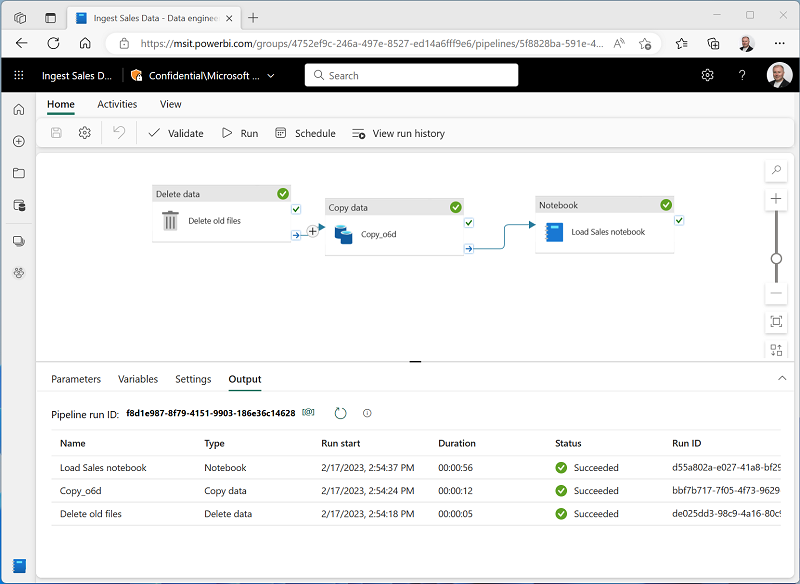
Nota: En caso de que reciba el mensaje de error Las consultas de Spark SQL solo son posibles en el contexto de un almacén de lago. Adjunte un almacén de lago para continuar: Abra el cuaderno, seleccione el almacén de lago que creó en el panel izquierdo, seleccione Quitar todos los almacenes de lago y, a continuación, vuelva a agregarlo. Vuelva al diseñador de canalizaciones y seleccione ▷ Ejecutar.
- En la barra de menús central, en el borde izquierdo del portal, seleccione su almacén de lago.
- En el panel Explorador, expanda Tablas y seleccione la tabla new_sales para ver una vista previa de los datos que contiene. Esta tabla se creó mediante el cuaderno cuando la canalización lo ejecutó.
En este ejercicio, ha implementado una solución de ingesta de datos que usa una canalización para copiar datos en el almacén de lago desde un origen externo y, a continuación, emplea un cuaderno de Spark para transformar los datos y cargarlos en una tabla.
Limpieza de recursos
En este ejercicio, ha aprendido a implementar una canalización en Microsoft Fabric.
Si ha terminado de explorar el almacén de lago, puede eliminar el área de trabajo que ha creado para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo para ver todos los elementos que contiene.
- Selecciona Configuración del área de trabajo y, en la sección General, desplázate hacia abajo y selecciona Quitar esta área de trabajo.
- Selecciona Eliminar para eliminar el área de trabajo.