Crear una arquitectura de medallas en un almacén de lago de Microsoft Fabric
En este ejercicio, creará una arquitectura de medallas en un almacén de lago de Fabric mediante cuadernos. Creará un área de trabajo, creará un almacén de lago, cargará datos en la capa de bronce, transformará los datos y los cargará en la tabla Delta de plata, después transformará aún más los datos y los cargará en las tablas Delta de oro y, entonces, explorará el modelo semántico y creará relaciones.
Este ejercicio debería tardar en completarse 45 minutos aproximadamente
[!Note] Para completar este ejercicio, necesitas acceder a un inquilino de Microsoft Fabric.
Creación de un área de trabajo
Antes de trabajar con datos de Fabric, crea un área de trabajo con la evaluación gratuita de Fabric habilitada.
- En un explorador, ve a la página principal de Microsoft Fabric en
https://app.fabric.microsoft.com/home?experience=fabric-developere inicia sesión con tus credenciales de Fabric. - En la barra de menús de la izquierda, seleccione Áreas de trabajo (el icono tiene un aspecto similar a 🗇).
- Cree una nueva área de trabajo con el nombre que prefiera y seleccione un modo de licencia en la sección Avanzado que incluya la capacidad de Fabric (Prueba, Premium o Fabric).
-
Cuando se abra la nueva área de trabajo, debe estar vacía.
-
Ve a la configuración del área de trabajo y comprueba que la característica en vista previa Configuración del modelo de datos está habilitada. Esto le permitirá crear relaciones entre tablas en el almacén de lago de datos mediante un modelo semántico de Power BI.
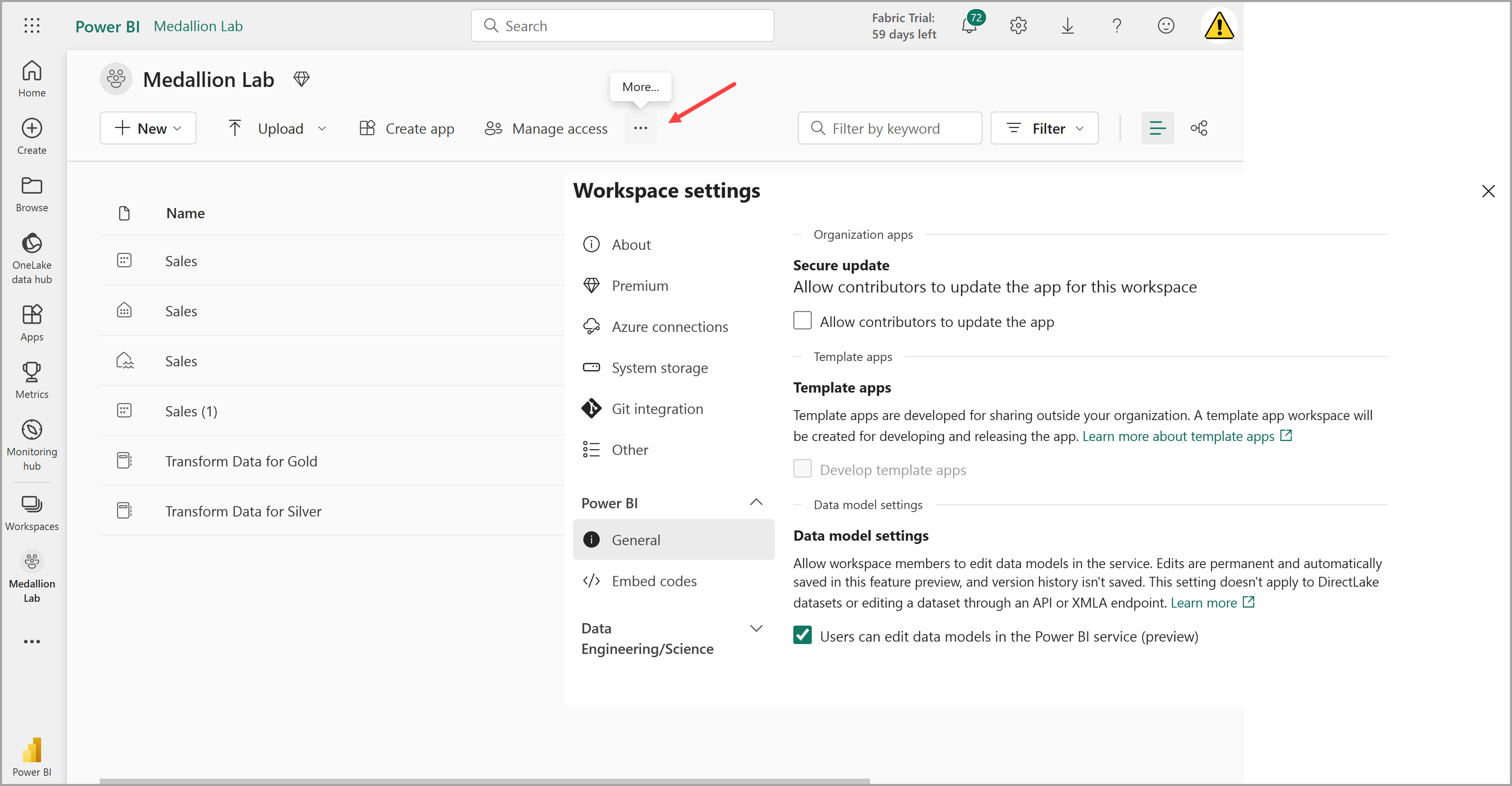
Nota: Es posible que tenga que actualizar la pestaña del explorador después de habilitar la característica en vista previa (GB).
Crear un almacén de lago y cargar datos a la capa de bronce
Ahora que tiene un área de trabajo, es el momento de crear un almacén de lago de datos para los datos que va analizar.
-
En el área de trabajo que acabas de crear, crea un nuevo almacén de lago de datos denominado Sales. Para ello, haz clic en el botón + Nuevo elemento.
Al cabo de un minuto más o menos, se creará un nuevo almacén de lago vacío. Después, debes ingerir algunos datos en el almacén de lago de datos para su análisis. Hay varias maneras de hacerlo, pero en este ejercicio simplemente descargará un archivo de texto en el equipo local (o máquina virtual de laboratorio, si procede) y, luego, lo cargará en el almacén de lago.
-
Descargue el archivo de datos de este ejercicio desde
https://github.com/MicrosoftLearning/dp-data/blob/main/orders.zip. Extraiga los archivos y guárdelos con sus nombres originales en el equipo local (o máquina virtual de laboratorio, si procede). Debe haber 3 archivos con datos de ventas de 3 años: 2019.csv, 2020.csv y 2021.csv. -
Vuelva a la pestaña del explorador web que contiene el almacén de lago y, en el menú … de la carpeta Archivos del panel Explorador, seleccione Nueva subcarpeta y cree una carpeta llamada bronze.
-
En el menú … de la carpeta bronze, seleccione Cargar y Cargar archivos, entonces cargue los 3 archivos (2019.csv, 2020.csv, y 2021.csv) desde el equipo local (o máquina virtual de laboratorio, si procede) al almacén de lago. Use la tecla Mayús para cargar los 3 archivos a la vez.
-
Una vez caragados los archivos, seleccione la carpeta bronze y compruebe que los archivos han sido cargados, como se muestra aquí:
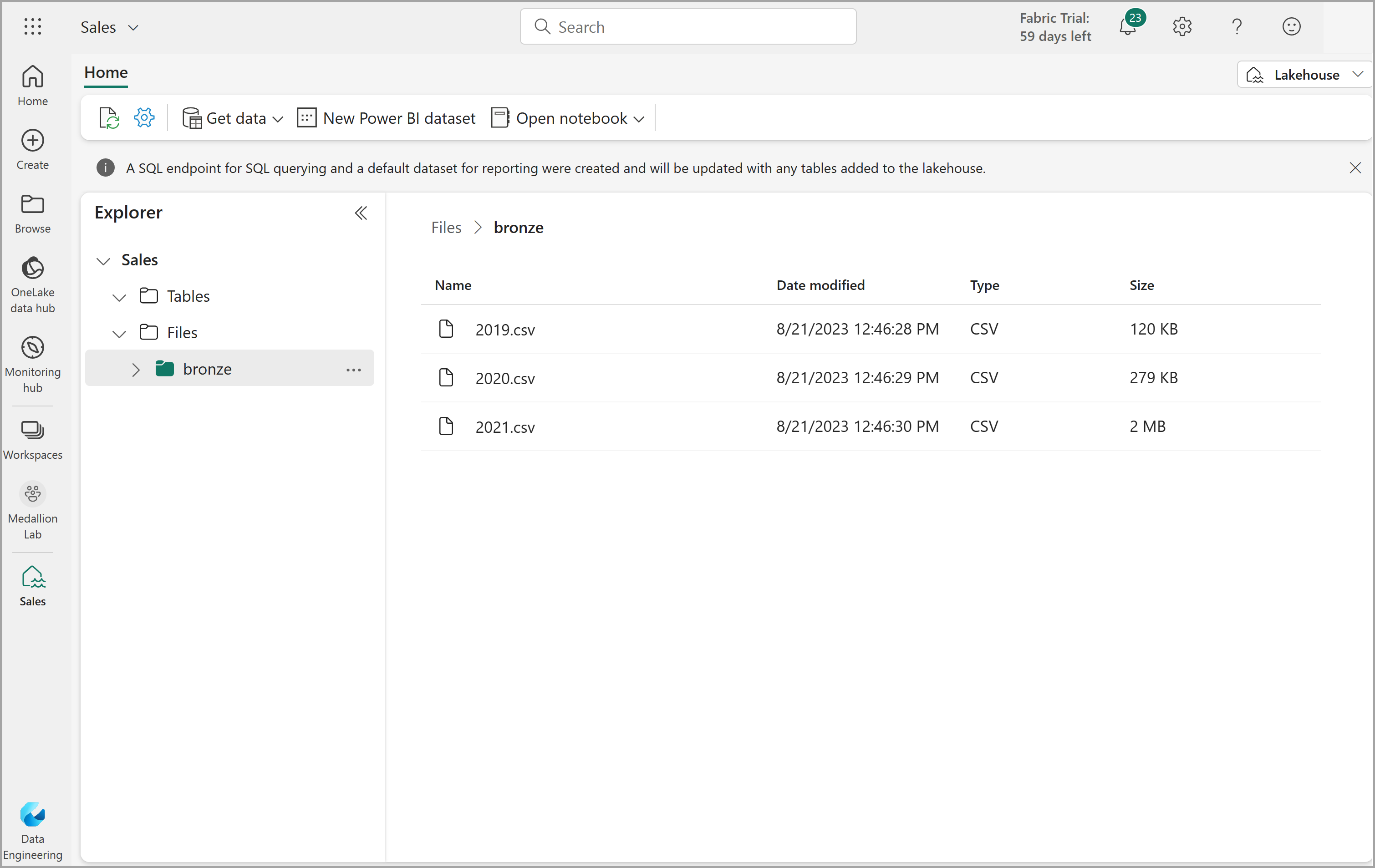
Transformar datos y cargar a la tabla Delta de plata
Ahora que tiene datos en la capa de bronce del almacén de datos, puede usar un cuaderno para transformar los datos y cargarlos a una tabla Delta en la capa de plata.
-
En la página Inicio, viendo el contenido de la carpeta bronze en el lago de datos, vaya al menú Abrir cuaderno y seleccione Nuevo cuaderno.
Al cabo de unos segundos, se abrirá un nuevo cuaderno que contiene una sola celda. Los cuadernos se componen de una o varias celdas que pueden contener código o Markdown (texto con formato).
-
Cuando se abra el cuaderno, cámbiale el nombre a
Transform data for Silvermediante la selección del texto Cuaderno xxxx en la parte superior izquierda del cuaderno e introduce el nuevo nombre.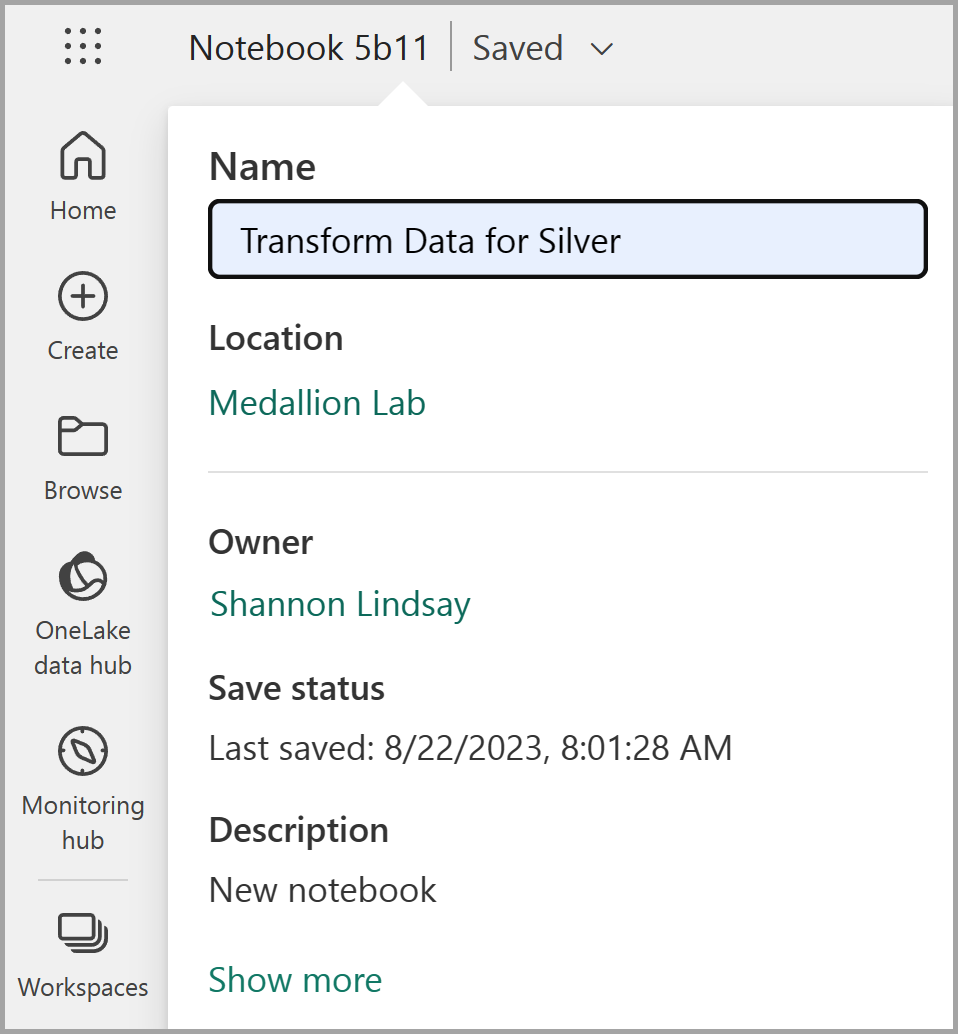
-
Seleccione la celda existente del cuaderno, que contiene un sencillo código comentado. Resalte y elimine estas dos líneas: no necesitará este código.
Nota: Los cuadernos permiten ejecutar código en varios lenguajes, como Python, Scala y SQL. En este ejercicio, usará PySpark y SQL. También puede agregar celdas Markdown para proporcionar texto con formato e imágenes para documentar el código.
-
Pegue el siguiente código en la celda:
from pyspark.sql.types import * # Create the schema for the table orderSchema = StructType([ StructField("SalesOrderNumber", StringType()), StructField("SalesOrderLineNumber", IntegerType()), StructField("OrderDate", DateType()), StructField("CustomerName", StringType()), StructField("Email", StringType()), StructField("Item", StringType()), StructField("Quantity", IntegerType()), StructField("UnitPrice", FloatType()), StructField("Tax", FloatType()) ]) # Import all files from bronze folder of lakehouse df = spark.read.format("csv").option("header", "true").schema(orderSchema).load("Files/bronze/*.csv") # Display the first 10 rows of the dataframe to preview your data display(df.head(10)) -
Use el botón **▷ (Ejecutar celda)** a la izquierda de la celda para ejecutar el código.
Nota: Dado que esta es la primera vez que se ejecuta código de Spark en este cuaderno, se debe iniciar una sesión con Spark. Esto significa que la primera ejecución puede tardar un minuto en completarse. Las ejecuciones posteriores serán más rápidas.
-
Cuando se haya completado el comando de la celda, revise la salida que aparece debajo de ella, que será algo parecido a esto:
Índice SalesOrderNumber SalesOrderLineNumber OrderDate CustomerName Correo electrónico Elemento Quantity UnitPrice Impuesto 1 SO49172 1 2021-01-01 Brian Howard brian23@adventure-works.com Road-250 Red, 52 1 2443.35 195.468 2 SO49173 1 2021-01-01 Linda Álvarez linda19@adventure-works.com Mountain-200 Silver, 38 1 2071.4197 165.7136 … … … … … … … … … … El código ejecutado ha cargado los datos de los archivos CSV de la carpeta bronze en un dataframe de Spark y, después, ha mostrado las primeras filas del dataframe.
Nota: Puede borrar, ocultar y cambiar automáticamente el tamaño del contenido de la salida de la celda seleccionando el menú … situado en la parte superior izquierda del panel de salida.
-
Ahora agregará columnas para la validación y limpieza de datos mediante un dataframe de PySpark para agregar columnas y actualizar los valores de algunas de las columnas existentes. Usa el botón + Código para agregar un nuevo bloque de código y agrega el código siguiente a la celda:
from pyspark.sql.functions import when, lit, col, current_timestamp, input_file_name # Add columns IsFlagged, CreatedTS and ModifiedTS df = df.withColumn("FileName", input_file_name()) \ .withColumn("IsFlagged", when(col("OrderDate") < '2019-08-01',True).otherwise(False)) \ .withColumn("CreatedTS", current_timestamp()).withColumn("ModifiedTS", current_timestamp()) # Update CustomerName to "Unknown" if CustomerName null or empty df = df.withColumn("CustomerName", when((col("CustomerName").isNull() | (col("CustomerName")=="")),lit("Unknown")).otherwise(col("CustomerName")))La primera línea del código importa las funciones necesarias de PySpark. Después, va a agregar nuevas columnas al dataframe para poder realizar un seguimiento del nombre del archivo de origen, si el pedido se marcó como anterior al año fiscal de interés y cuándo se creó y modificó la fila.
Por último, va a actualizar la columna CustomerName a “Unknown” si es null o está vacía.
-
Ejecute la celda para ejecutar el código mediante el botón **▷ (Ejecutar celda)**.
-
A continuación, definirá el esquema de la tabla sales_silver en la base de datos de ventas mediante el formato Delta Lake. Cree un nuevo bloque de código y agregue el siguiente código a la celda:
# Define the schema for the sales_silver table from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.sales_silver") \ .addColumn("SalesOrderNumber", StringType()) \ .addColumn("SalesOrderLineNumber", IntegerType()) \ .addColumn("OrderDate", DateType()) \ .addColumn("CustomerName", StringType()) \ .addColumn("Email", StringType()) \ .addColumn("Item", StringType()) \ .addColumn("Quantity", IntegerType()) \ .addColumn("UnitPrice", FloatType()) \ .addColumn("Tax", FloatType()) \ .addColumn("FileName", StringType()) \ .addColumn("IsFlagged", BooleanType()) \ .addColumn("CreatedTS", DateType()) \ .addColumn("ModifiedTS", DateType()) \ .execute() -
Ejecute la celda para ejecutar el código mediante el botón **▷ (Ejecutar celda)**.
-
Selecciona los puntos suspensivos … en la sección Tablas en el panel Explorador y selecciona Actualizar. Ahora debería ver la nueva tabla sales_silver en la lista. ▲ (icono de triángulo) indica que es una tabla Delta.
Nota: si no ve la nueva tabla, espere unos segundos y vuelva a seleccionar Actualizar, o actualice la pestaña del explorador.
-
Ahora va a realizar una operación upsert en una tabla Delta, actualizando los registros existentes según unas condiciones específicas e insertando nuevos registros cuando no se encuentren coincidencias. Agregue un nuevo bloque de código y pegue el siguiente código:
# Update existing records and insert new ones based on a condition defined by the columns SalesOrderNumber, OrderDate, CustomerName, and Item. from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/sales_silver') dfUpdates = df deltaTable.alias('silver') \ .merge( dfUpdates.alias('updates'), 'silver.SalesOrderNumber = updates.SalesOrderNumber and silver.OrderDate = updates.OrderDate and silver.CustomerName = updates.CustomerName and silver.Item = updates.Item' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "SalesOrderNumber": "updates.SalesOrderNumber", "SalesOrderLineNumber": "updates.SalesOrderLineNumber", "OrderDate": "updates.OrderDate", "CustomerName": "updates.CustomerName", "Email": "updates.Email", "Item": "updates.Item", "Quantity": "updates.Quantity", "UnitPrice": "updates.UnitPrice", "Tax": "updates.Tax", "FileName": "updates.FileName", "IsFlagged": "updates.IsFlagged", "CreatedTS": "updates.CreatedTS", "ModifiedTS": "updates.ModifiedTS" } ) \ .execute() -
Ejecute la celda para ejecutar el código mediante el botón **▷ (Ejecutar celda)**.
Esta operación es importante porque permite actualizar los registros existentes en la tabla según los valores de columnas específicas e insertar nuevos registros cuando no se encuentren coincidencias. Este es un requisito común cuando se cargan datos desde un sistema de origen que pueden contener actualizaciones de registros existentes y nuevos.
Ahora tiene datos en la tabla Delta de plata que están listos para ser aún más transformados y modelados.
Exploración de datos en la capa Silver mediante el punto de conexión de SQL
Ahora que tienes datos en la capa de plata, puedes usar el punto de conexión de análisis SQL para explorar los datos y realizar algunos análisis básicos. Esto es útil si estás familiarizado con SQL y quieres hacer una exploración básica de los datos. En este ejercicio, se usa la vista de punto de conexión de SQL en Fabric, pero también puedes usar otras herramientas como SQL Server Management Studio (SSMS) y Azure Data Explorer.
-
Navega de nuevo a tu área de trabajo; verás que ahora tienes varios elementos en la lista. Selecciona el punto de conexión de análisis SQL Sales para abrir el almacén de lago en la vista de punto de conexión de análisis SQL.
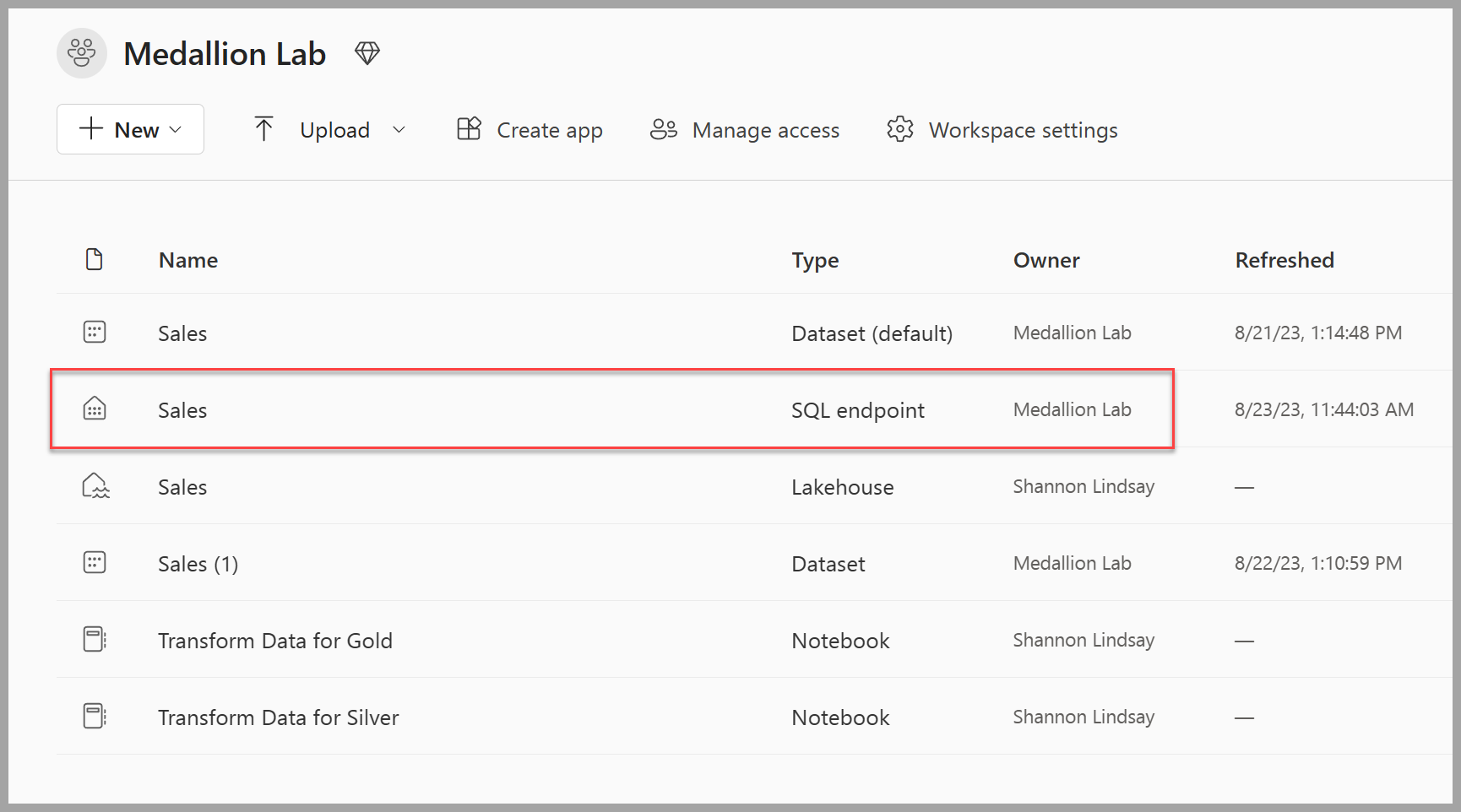
-
Seleccione Nueva consulta SQL en la cinta de opciones, que abrirá un editor de consultas SQL. Ten en cuenta que puedes cambiar el nombre de la consulta mediante el elemento de menú … situado junto al nombre de consulta existente en el panel Explorador.
Después, ejecutarás dos consultas SQL para explorar los datos.
-
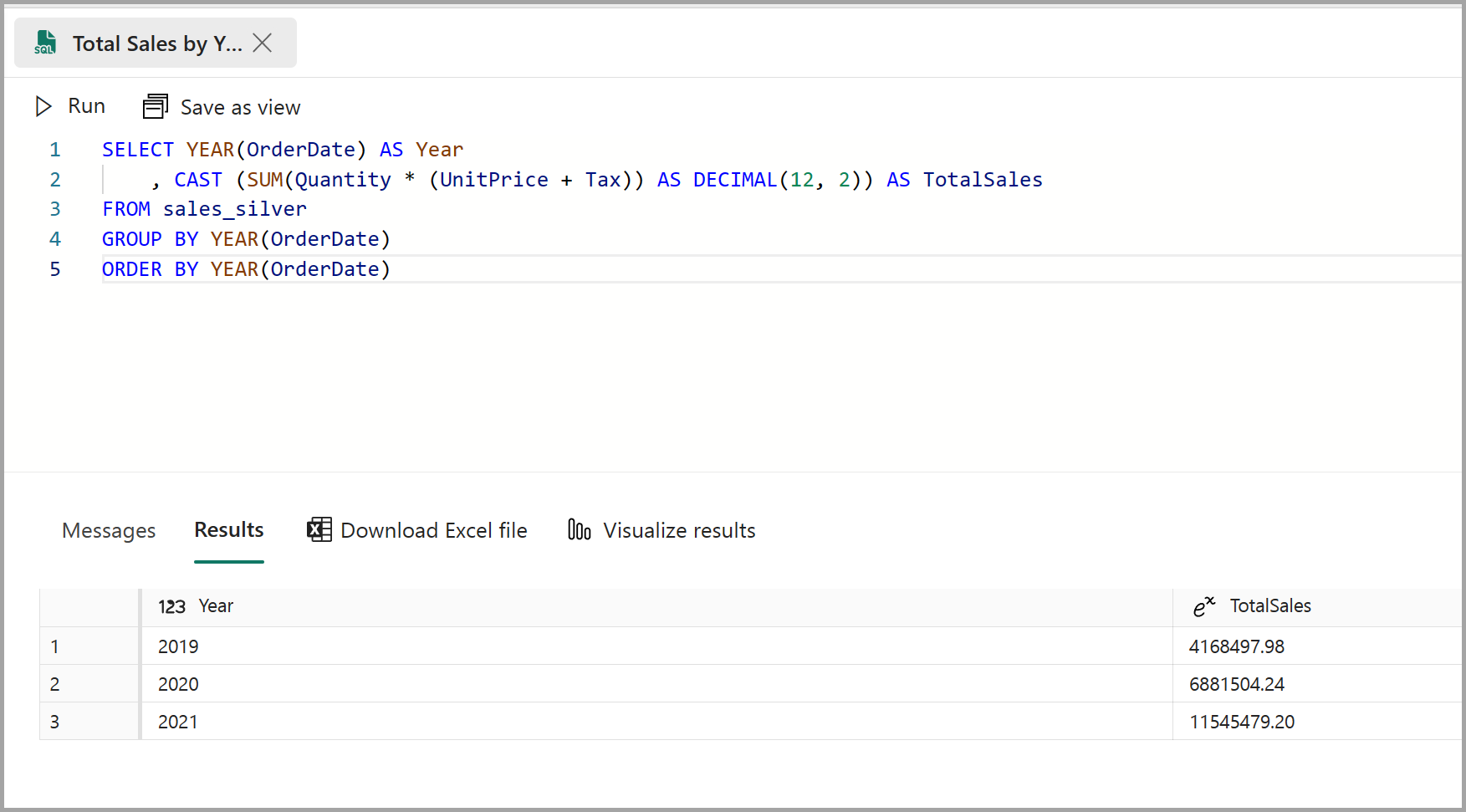
Pegue la consulta siguiente en el editor de consultas y seleccione Ejecutar:
SELECT YEAR(OrderDate) AS Year , CAST (SUM(Quantity * (UnitPrice + Tax)) AS DECIMAL(12, 2)) AS TotalSales FROM sales_silver GROUP BY YEAR(OrderDate) ORDER BY YEAR(OrderDate)Esta consulta calcula las ventas totales de cada año en la tabla sales_silver. Los resultados deben tener un aspecto parecido al siguiente:
-
Luego, debes revisar qué clientes compran más (en términos de cantidad). Pegue la consulta siguiente en el editor de consultas y seleccione Ejecutar:
SELECT TOP 10 CustomerName, SUM(Quantity) AS TotalQuantity FROM sales_silver GROUP BY CustomerName ORDER BY TotalQuantity DESCEsta consulta calcula la cantidad total de artículos adquiridos por cada cliente en la tabla sales_silver y,después, devuelve los 10 clientes principales en términos de cantidad.
La exploración de datos en la capa Silver es útil para el análisis básico, pero tendrá que transformar los datos aún más y modelarlos en un esquema de estrella para habilitar análisis e informes más avanzados. Lo hará en la sección siguiente.
Transformar datos para la capa de oro
Ha tomado correctamente los datos de la capa de bronce, los ha transformado y cargado en una tabla Delta de plata. Ahora usará un nuevo cuaderno para transformar los datos aún más, modelarlos en un esquema de estrella y cargarlos en tablas Delta de oro.
Podrías haber hecho todo esto en un único cuaderno, pero para este ejercicio vas a utilizar cuadernos separados para demostrar el proceso de transformación de datos de bronce a plata y luego de plata a oro. Esto puede ayudar con la depuración, la solución de problemas y la reutilización.
-
Vuelve a la página principal del área de trabajo y crea un cuaderno nuevo denominado
Transform data for Gold. -
En el panel Explorador, agrega tu almacén de lago Sales. Para ello, selecciona Agregar elementos de datos y selecciona el almacén de lago Sales que creaste anteriormente. Debería ver la tabla sales_silver en la sección Tablas del panel de exploración.
-
En el bloque de código existente, elimina el texto comentado y agrega el siguiente código para cargar datos en tu marco de datos y empezar a construir tu esquema de estrella, luego ejecútalo:
# Load data to the dataframe as a starting point to create the gold layer df = spark.read.table("Sales.sales_silver") -
Agregue un nuevo bloque de código y pegue el código siguiente para crear la tabla de dimensiones y ejecútelo:
from pyspark.sql.types import * from delta.tables import* # Define the schema for the dimdate_gold table DeltaTable.createIfNotExists(spark) \ .tableName("sales.dimdate_gold") \ .addColumn("OrderDate", DateType()) \ .addColumn("Day", IntegerType()) \ .addColumn("Month", IntegerType()) \ .addColumn("Year", IntegerType()) \ .addColumn("mmmyyyy", StringType()) \ .addColumn("yyyymm", StringType()) \ .execute()Nota: Puede ejecutar el comando
display(df)en cualquier momento para comprobar el progreso del trabajo. En este caso, ejecutaría “display(dfdimDate_gold)” para ver el contenido del dataframe dimDate_gold. -
En un nuevo bloque de código, agregue y ejecute el código siguiente para crear una trama de datos para la dimensión de fecha, dimdate_gold:
from pyspark.sql.functions import col, dayofmonth, month, year, date_format # Create dataframe for dimDate_gold dfdimDate_gold = df.dropDuplicates(["OrderDate"]).select(col("OrderDate"), \ dayofmonth("OrderDate").alias("Day"), \ month("OrderDate").alias("Month"), \ year("OrderDate").alias("Year"), \ date_format(col("OrderDate"), "MMM-yyyy").alias("mmmyyyy"), \ date_format(col("OrderDate"), "yyyyMM").alias("yyyymm"), \ ).orderBy("OrderDate") # Display the first 10 rows of the dataframe to preview your data display(dfdimDate_gold.head(10)) -
Está separando el código en nuevos bloques de código para poder comprender y observar lo que sucede en el cuaderno a medida que transforma los datos. En otro bloque de código nuevo, agregue y ejecute el siguiente código para actualizar la dimensión de fecha a medida se ingresan nuevos datos:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dimdate_gold') dfUpdates = dfdimDate_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.OrderDate = updates.OrderDate' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "OrderDate": "updates.OrderDate", "Day": "updates.Day", "Month": "updates.Month", "Year": "updates.Year", "mmmyyyy": "updates.mmmyyyy", "yyyymm": "updates.yyyymm" } ) \ .execute()La dimensión de fecha ahora está configurada. Ahora creará la dimensión del cliente.
-
Para crear la tabla de dimensiones de cliente, agregue un nuevo bloque de código, pegue y ejecute el código siguiente:
from pyspark.sql.types import * from delta.tables import * # Create customer_gold dimension delta table DeltaTable.createIfNotExists(spark) \ .tableName("sales.dimcustomer_gold") \ .addColumn("CustomerName", StringType()) \ .addColumn("Email", StringType()) \ .addColumn("First", StringType()) \ .addColumn("Last", StringType()) \ .addColumn("CustomerID", LongType()) \ .execute() -
En un nuevo bloque de código, agregue y ejecute el código siguiente para quitar clientes duplicados; seleccione columnas específicas y divida la columna “CustomerName” para crear columnas “First” y “Last” (nombres y apellidos):
from pyspark.sql.functions import col, split # Create customer_silver dataframe dfdimCustomer_silver = df.dropDuplicates(["CustomerName","Email"]).select(col("CustomerName"),col("Email")) \ .withColumn("First",split(col("CustomerName"), " ").getItem(0)) \ .withColumn("Last",split(col("CustomerName"), " ").getItem(1)) # Display the first 10 rows of the dataframe to preview your data display(dfdimCustomer_silver.head(10))Aquí ha creado un nuevo DataFrame “dfdimCustomer_silver” realizando varias transformaciones, como anular duplicados, seleccionar columnas específicas y separar la columna “CustomerName” para crear las columnas “First” y “Last” name. El resultado es un DataFrame con datos de cliente estructurados limpios, incluyendo las columnas “First” y “Last” name extraídas de la columna “CustomerName”.
-
Después, crearemos la columna ID para nuestros clientes. En un nuevo bloque de código, pegue y ejecute lo siguiente:
from pyspark.sql.functions import monotonically_increasing_id, col, when, coalesce, max, lit dfdimCustomer_temp = spark.read.table("Sales.dimCustomer_gold") MAXCustomerID = dfdimCustomer_temp.select(coalesce(max(col("CustomerID")),lit(0)).alias("MAXCustomerID")).first()[0] dfdimCustomer_gold = dfdimCustomer_silver.join(dfdimCustomer_temp,(dfdimCustomer_silver.CustomerName == dfdimCustomer_temp.CustomerName) & (dfdimCustomer_silver.Email == dfdimCustomer_temp.Email), "left_anti") dfdimCustomer_gold = dfdimCustomer_gold.withColumn("CustomerID",monotonically_increasing_id() + MAXCustomerID + 1) # Display the first 10 rows of the dataframe to preview your data display(dfdimCustomer_gold.head(10))Aquí va a limpiar y transformar los datos del cliente (dfdimCustomer_silver) mediante la realización de una anticombinación izquierda para excluir duplicados que ya existen en la tabla dimCustomer_gold y, a continuación, generar valores CustomerID únicos mediante la función monotonically_increasing_id().
-
Ahora se asegurará de que su tabla de clientes se mantenga actualizada conforme vayan entrando nuevos datos. En un nuevo bloque de código, pegue y ejecute lo siguiente:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dimcustomer_gold') dfUpdates = dfdimCustomer_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.CustomerName = updates.CustomerName AND gold.Email = updates.Email' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "CustomerName": "updates.CustomerName", "Email": "updates.Email", "First": "updates.First", "Last": "updates.Last", "CustomerID": "updates.CustomerID" } ) \ .execute() -
Ahora repetirá esos pasos para crear la dimensión del producto. En un nuevo bloque de código, pegue y ejecute lo siguiente:
from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.dimproduct_gold") \ .addColumn("ItemName", StringType()) \ .addColumn("ItemID", LongType()) \ .addColumn("ItemInfo", StringType()) \ .execute() -
Agregue otro bloque de código para crear el dataframe product_silver.
from pyspark.sql.functions import col, split, lit, when # Create product_silver dataframe dfdimProduct_silver = df.dropDuplicates(["Item"]).select(col("Item")) \ .withColumn("ItemName",split(col("Item"), ", ").getItem(0)) \ .withColumn("ItemInfo",when((split(col("Item"), ", ").getItem(1).isNull() | (split(col("Item"), ", ").getItem(1)=="")),lit("")).otherwise(split(col("Item"), ", ").getItem(1))) # Display the first 10 rows of the dataframe to preview your data display(dfdimProduct_silver.head(10)) -
Ahora creará identificadores para la tabla dimProduct_gold. Agregue la siguiente sintaxis a un nuevo bloque de código y ejecútelo:
from pyspark.sql.functions import monotonically_increasing_id, col, lit, max, coalesce #dfdimProduct_temp = dfdimProduct_silver dfdimProduct_temp = spark.read.table("Sales.dimProduct_gold") MAXProductID = dfdimProduct_temp.select(coalesce(max(col("ItemID")),lit(0)).alias("MAXItemID")).first()[0] dfdimProduct_gold = dfdimProduct_silver.join(dfdimProduct_temp,(dfdimProduct_silver.ItemName == dfdimProduct_temp.ItemName) & (dfdimProduct_silver.ItemInfo == dfdimProduct_temp.ItemInfo), "left_anti") dfdimProduct_gold = dfdimProduct_gold.withColumn("ItemID",monotonically_increasing_id() + MAXProductID + 1) # Display the first 10 rows of the dataframe to preview your data display(dfdimProduct_gold.head(10))Esto calcula el siguiente id. de producto disponible según los datos actuales de la tabla, asignando estos nuevos identificadores a los productos, y mostrando entonces la información de producto actualizada.
-
De forma similar a lo que ha hecho con las otras dimensiones, debe asegurarse de que la tabla de productos permanezca actualizada a medida que entran nuevos datos. En un nuevo bloque de código, pegue y ejecute lo siguiente:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/dimproduct_gold') dfUpdates = dfdimProduct_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.ItemName = updates.ItemName AND gold.ItemInfo = updates.ItemInfo' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "ItemName": "updates.ItemName", "ItemInfo": "updates.ItemInfo", "ItemID": "updates.ItemID" } ) \ .execute()Ahora que ha creado las dimensiones, el último paso es crear la tabla de hechos.
-
En un nuevo bloque de código, pegue y ejecute el código siguiente para crear la tabla de hechos:
from pyspark.sql.types import * from delta.tables import * DeltaTable.createIfNotExists(spark) \ .tableName("sales.factsales_gold") \ .addColumn("CustomerID", LongType()) \ .addColumn("ItemID", LongType()) \ .addColumn("OrderDate", DateType()) \ .addColumn("Quantity", IntegerType()) \ .addColumn("UnitPrice", FloatType()) \ .addColumn("Tax", FloatType()) \ .execute() -
En un nuevo bloque de código, pegue y ejecute el código siguiente para crear un nuevo dataframe para combinar los datos de ventas con la información del cliente y del producto, como el identificador de cliente, el identificador del artículo, la fecha de pedido, la cantidad, el precio unitario y los impuestos:
from pyspark.sql.functions import col dfdimCustomer_temp = spark.read.table("Sales.dimCustomer_gold") dfdimProduct_temp = spark.read.table("Sales.dimProduct_gold") df = df.withColumn("ItemName",split(col("Item"), ", ").getItem(0)) \ .withColumn("ItemInfo",when((split(col("Item"), ", ").getItem(1).isNull() | (split(col("Item"), ", ").getItem(1)=="")),lit("")).otherwise(split(col("Item"), ", ").getItem(1))) \ # Create Sales_gold dataframe dffactSales_gold = df.alias("df1").join(dfdimCustomer_temp.alias("df2"),(df.CustomerName == dfdimCustomer_temp.CustomerName) & (df.Email == dfdimCustomer_temp.Email), "left") \ .join(dfdimProduct_temp.alias("df3"),(df.ItemName == dfdimProduct_temp.ItemName) & (df.ItemInfo == dfdimProduct_temp.ItemInfo), "left") \ .select(col("df2.CustomerID") \ , col("df3.ItemID") \ , col("df1.OrderDate") \ , col("df1.Quantity") \ , col("df1.UnitPrice") \ , col("df1.Tax") \ ).orderBy(col("df1.OrderDate"), col("df2.CustomerID"), col("df3.ItemID")) # Display the first 10 rows of the dataframe to preview your data display(dffactSales_gold.head(10)) -
Ahora se asegurará de que los datos de ventas permanecen actualizados mediante la ejecución del código siguiente en un nuevo bloque de código:
from delta.tables import * deltaTable = DeltaTable.forPath(spark, 'Tables/factsales_gold') dfUpdates = dffactSales_gold deltaTable.alias('gold') \ .merge( dfUpdates.alias('updates'), 'gold.OrderDate = updates.OrderDate AND gold.CustomerID = updates.CustomerID AND gold.ItemID = updates.ItemID' ) \ .whenMatchedUpdate(set = { } ) \ .whenNotMatchedInsert(values = { "CustomerID": "updates.CustomerID", "ItemID": "updates.ItemID", "OrderDate": "updates.OrderDate", "Quantity": "updates.Quantity", "UnitPrice": "updates.UnitPrice", "Tax": "updates.Tax" } ) \ .execute()Aquí va a usar la operación merge de Delta Lake para sincronizar y actualizar la tabla de factsales_gold con nuevos datos de ventas (dffactSales_gold). La operación compara la fecha de pedido, el identificador de cliente y el identificador de producto entre los datos existentes (tabla de plata) y los nuevos datos (actualiza DataFrame), actualizando los registros coincidentes e insertando nuevos registros según sea necesario.
Ahora tiene una capa de oro mantenida y modelada que puede usarse para informes y análisis.
Creación de un modelo semántico
En el área de trabajo, ahora puede usar la capa de oro para crear un informe y analizar los datos. Puede acceder al modelo semántico directamente en el área de trabajo para crear relaciones y medidas para los informes.
Tenga en cuenta que no puede usar el modelo semántico predeterminado que se crea automáticamente al crear un almacén de lago de datos. Debes crear un nuevo modelo semántico que incluya las tablas de oro que creaste en este ejercicio, desde el Explorador.
- En el área de trabajo, vaya a su almacén de lago Sales.
- Selecciona Nuevo modelo semántico en la cinta de la vista de Explorador.
- Asigne el nombre Sales_Gold al nuevo modelo semántico.
- Seleccione las tablas de oro transformadas para incluirlas en el modelo semántico y seleccione Confirmar.
- dimdate_gold
- dimcustomer_gold
- dimproduct_gold
- factsales_gold
Esto abrirá el modelo semántico en Fabric, donde podrá crear relaciones y medidas como se muestra aquí:
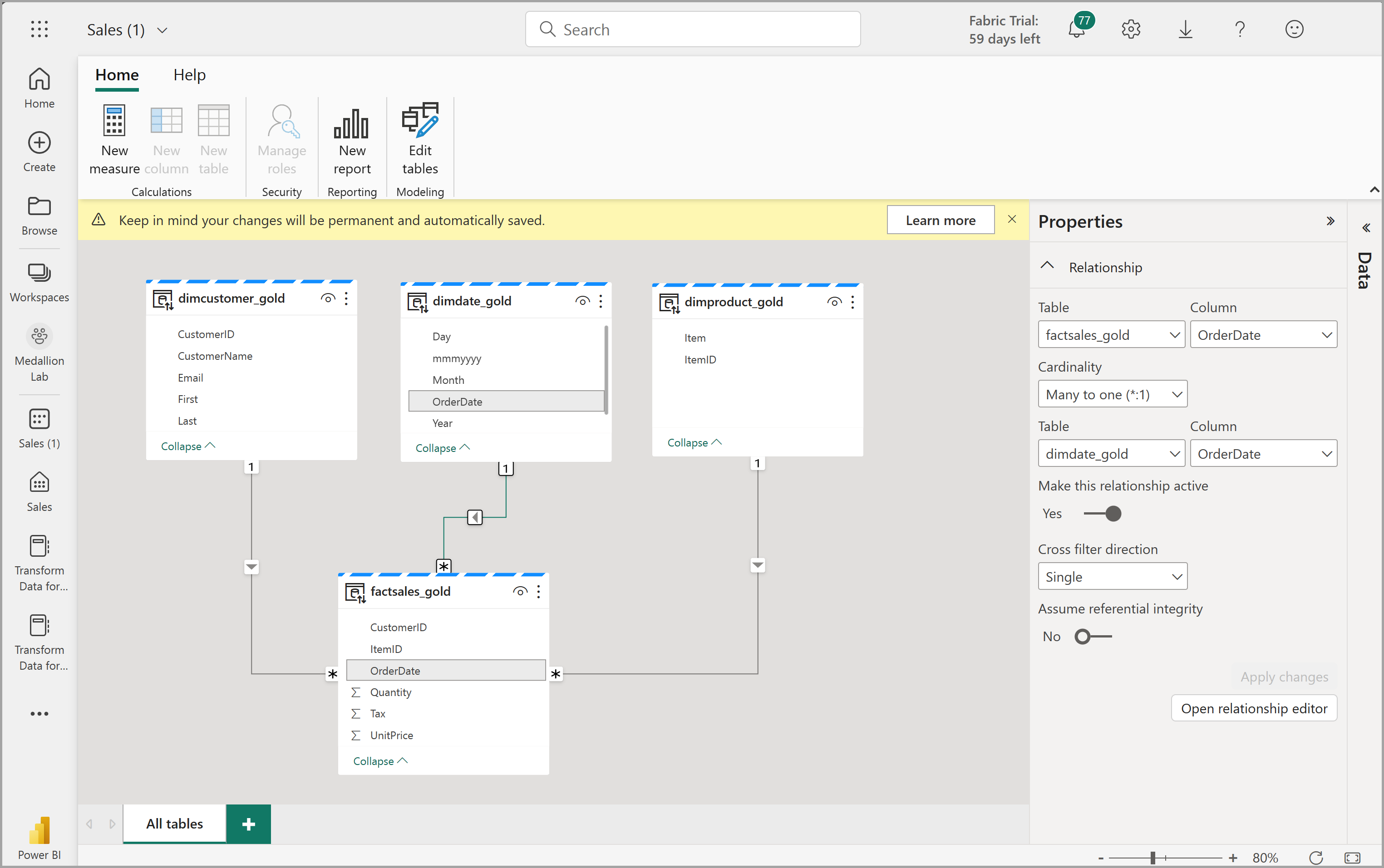
Desde aquí, usted u otros miembros del equipo de datos pueden crear informes y paneles basados en los datos del almacén de lago. Estos informes se conectarán directamente a la capa de oro de su lago, por lo que siempre reflejarán los datos más recientes.
Limpieza de recursos
En este ejercicio, ha aprendido a crear una arquitectura de medallas en un almacén de lago de Microsoft Fabric.
Si ha terminado de explorar el almacén de lago, puede eliminar el área de trabajo que ha creado para este ejercicio.
- En la barra de la izquierda, seleccione el icono del área de trabajo para ver todos los elementos que contiene.
- En el menú … de la barra de herramientas, selecciona Configuración del área de trabajo.
- En la sección General, selecciona Quitar esta área de trabajo.