使用 Azure Databricks 实现 LLMOps
Azure Databricks 提供了一个统一的平台,可简化从数据准备到模型服务和监控的 AI 生命周期,从而优化机器学习系统的性能和效率。 它支持生成式 AI 应用程序的开发,利用 Unity Catalog(用于数据管理)、MLflow(用于模型跟踪)和 Mosaic AI 模型服务(用于部署 LLM)等功能。
完成本实验室大约需要 20 分钟。
备注:Azure Databricks 用户界面可能会不断改进。 自编写本练习中的说明以来,用户界面可能已更改。
开始之前
需要一个你在其中具有管理级权限的 Azure 订阅。
预配 Azure OpenAI 资源
如果还没有 Azure OpenAI 资源,请在 Azure 订阅中预配 Azure OpenAI 资源。
- 登录到 Azure 门户,地址为 **。
- 请使用以下设置创建 Azure OpenAI 资源:
- 订阅**:选择已被批准访问 Azure OpenAI 服务的 Azure 订阅
- 资源组:创建或选择资源组
- 区域**:从以下任何区域中进行随机选择***
- 美国东部 2
- 美国中北部
- 瑞典中部
- 瑞士西部
- 名称:所选项的唯一名称**
- 定价层:标准版 S0
* Azure OpenAI 资源受区域配额约束。 列出的区域包括本练习中使用的模型类型的默认配额。 在与其他用户共享订阅的情况下,随机选择一个区域可以降低单个区域达到配额限制的风险。 如果稍后在练习中达到配额限制,你可能需要在不同的区域中创建另一个资源。
-
等待部署完成。 然后在 Azure 门户中转至部署的 Azure OpenAI 资源。
-
在左窗格的“资源管理”下,选择“密钥和终结点”。
-
复制终结点和其中一个可用密钥,因为稍后将在本练习中使用它。
部署所需的模块
Azure 提供了一个名为 Azure AI Studio 的基于 Web 的门户,可用于部署、管理和探索模型。 你将通过使用 Azure OpenAI Studio 部署模型,开始探索 Azure OpenAI。
备注:使用 Azure AI Studio 时,可能会显示建议你执行任务的消息框。 可以关闭这些消息框并按照本练习中的步骤进行操作。
-
在 Azure 门户中的 Azure OpenAI 资源的“概述”页上,向下滚动到“开始”部分,然后选择转到 Azure AI Studio 的按钮。
-
在 Azure AI Studio 的左侧窗格中,选择“部署”页并查看现有模型部署。 如果没有模型部署,请使用以下设置创建新的 gpt-35-turbo 模型部署:
- 部署名称:gpt-35-turbo
- 模型:gpt-35-turbo
- 模型版本:默认
- 部署类型:标准
- 每分钟令牌速率限制:5K*
- 内容筛选器:默认
- 启用动态配额:已禁用
*每分钟 5,000 个令牌的速率限制足以完成此练习,同时也为使用同一订阅的其他人留出容量。
预配 Azure Databricks 工作区
提示:如果你已有 Azure Databricks 工作区,则可以跳过此过程并使用现有工作区。
- 登录到 Azure 门户,地址为 **。
- 请使用以下设置创建 Azure Databricks 资源:
- 订阅:选择用于创建 Azure OpenAI 资源的同一 Azure 订阅
- 资源组:在其中创建了 Azure OpenAI 资源的同一资源组
- 区域:在其中创建 Azure OpenAI 资源的同一区域
- 名称:所选项的唯一名称**
- 定价层:高级或试用版
- 选择“查看 + 创建”,然后等待部署完成。 然后转到资源并启动工作区。
创建群集
Azure Databricks 是一个分布式处理平台,可使用 Apache Spark 群集在多个节点上并行处理数据。 每个群集由一个用于协调工作的驱动程序节点和多个用于执行处理任务的工作器节点组成。 在本练习中,将创建一个单节点群集,以最大程度地减少实验室环境中使用的计算资源(在实验室环境中,资源可能会受到限制)。 在生产环境中,通常会创建具有多个工作器节点的群集。
提示:如果 Azure Databricks 工作区中已有一个具有 13.3 LTS ML 或更高运行时版本的群集,则可以使用它来完成此练习并跳过此过程。
- 在Azure 门户中,浏览到创建 Azure Databricks 工作区的资源组。
- 单击 Azure Databricks 服务资源。
- 在工作区的“概述”** 页中,使用“启动工作区”** 按钮在新的浏览器标签页中打开 Azure Databricks 工作区;请在出现提示时登录。
提示:使用 Databricks 工作区门户时,可能会显示各种提示和通知。 消除这些内容,并按照提供的说明完成本练习中的任务。
- 在左侧边栏中,选择“(+) 新建”任务,然后选择“群集”。
- 在“新建群集”页中,使用以下设置创建新群集:
- 群集名称:用户名的群集(默认群集名称)
- 策略:非受限
- 群集模式:单节点
- 访问模式:单用户(选择你的用户帐户)
- Databricks Runtime 版本**:选择最新非 beta 版本运行时的 ML** 版本(不是**标准运行时版本),该版本符合以下条件:
- 不使用 GPU**
- 包括 Scala > 2.11
- 包括 Spark > 3.4
- 使用 Photon 加速**:未选定
- 节点类型:Standard_D4ds_v5
- 在处于不活动状态 20 分钟后终止****
- 等待群集创建完成。 这可能需要一到两分钟时间。
注意:如果群集无法启动,则订阅在预配 Azure Databricks 工作区的区域中的配额可能不足。 请参阅 CPU 内核限制阻止创建群集,了解详细信息。 如果发生这种情况,可以尝试删除工作区,并在其他区域创建新工作区。
安装所需的库
-
在 Databricks 工作区中,转到“工作区”** 部分。
-
选择“创建”**,然后选择“笔记本”**。
-
为笔记本命名,然后选择“
Python”作为语言。 -
在第一个代码单元格中,输入并运行以下代码以安装 OpenAI 库:
%pip install openai -
安装完成后,在新单元格中重启内核:
%restart_python
使用 MLflow 记录 LLM
MLflow 的 LLM 跟踪功能允许记录参数、指标、预测和项目。 参数包括详细描述输入配置的键值对,而指标提供性能的定量度量值。 预测包括输入提示和模型的响应,这些响应存储为项目,以便轻松检索。 这种结构化日志记录有助于维护每个交互的详细记录,从而更好地分析和优化 LLM。
-
在新单元格中,使用本练习开始时复制的访问信息运行以下代码,以便在使用 Azure OpenAI 资源时分配用于身份验证的持久性环境变量:
import os os.environ["AZURE_OPENAI_API_KEY"] = "your_openai_api_key" os.environ["AZURE_OPENAI_ENDPOINT"] = "your_openai_endpoint" os.environ["AZURE_OPENAI_API_VERSION"] = "2023-03-15-preview" -
在新单元格中,运行以下代码来初始化 Azure OpenAI 客户端:
import os from openai import AzureOpenAI client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"), api_key = os.getenv("AZURE_OPENAI_API_KEY"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) -
在新单元格中,运行以下代码来初始化 MLflow 跟踪并记录模型:
import mlflow from openai import AzureOpenAI system_prompt = "Assistant is a large language model trained by OpenAI." mlflow.openai.autolog() with mlflow.start_run(): response = client.chat.completions.create( model="gpt-35-turbo", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "Tell me a joke about animals."}, ], ) print(response.choices[0].message.content) mlflow.log_param("completion_tokens", response.usage.completion_tokens) mlflow.end_run()
上面的单元格将在工作区中启动试验,并注册每个聊天完成迭代的跟踪,跟踪每个运行的输入、输出和元数据。
监视模型
-
在左侧边栏中,选择“试验”,然后选择与用于本练习的笔记本关联的实验。 选择最新的运行并在“概述”页中验证是否有一个记录的参数:
completion_tokens。 此命令mlflow.openai.autolog()将默认记录每个运行的跟踪,但也可以使用mlflow.log_param()记录其他参数,以便稍后使用该参数监视模型。 -
选择“跟踪”选项卡,然后选择最后创建的跟踪选项卡。 验证
completion_tokens参数是否为跟踪输出的一部分: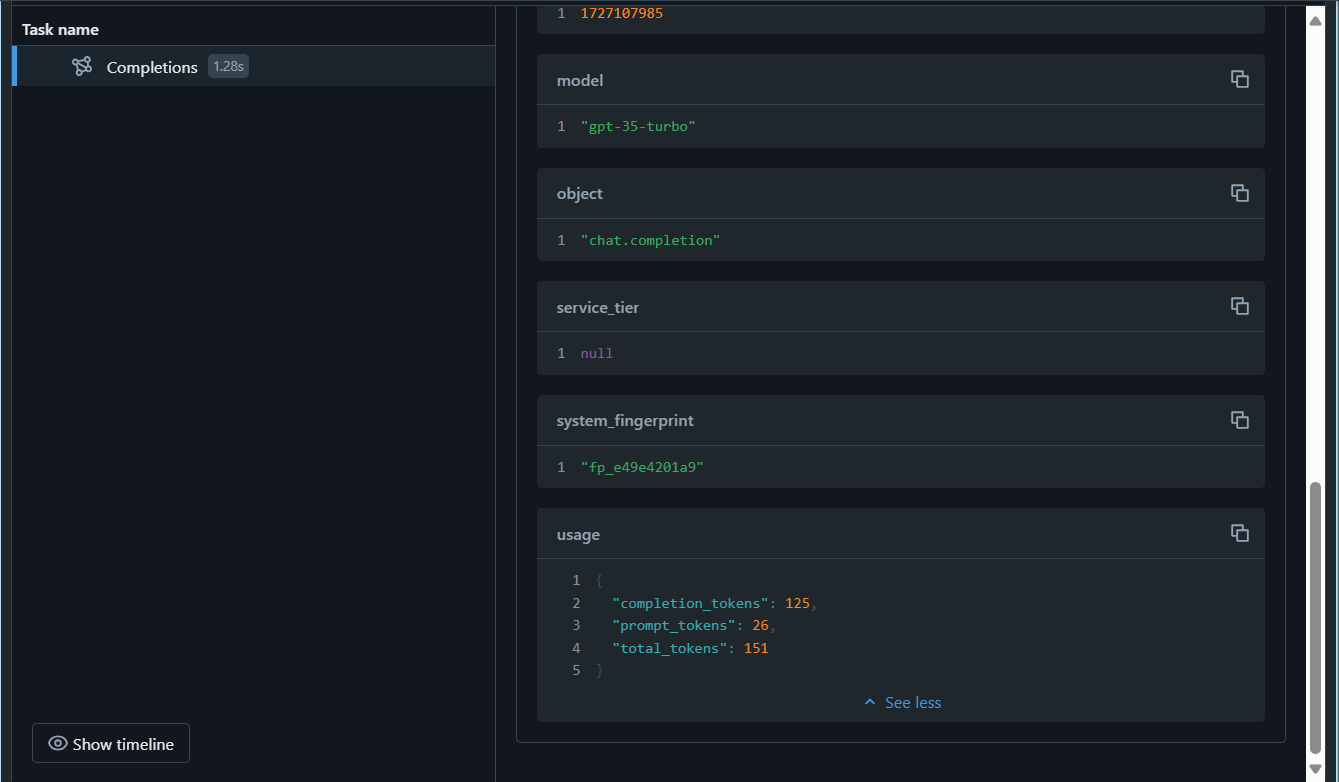
开始监视模型后,可以比较不同运行中的跟踪以检测数据偏移。 在一段时间内查找输入数据分布、模型预测或性能指标的重大更改。 可以使用统计测试或可视化工具来帮助进行此分析。
清理
使用完 Azure OpenAI 资源后,请记得在位于 https://portal.azure.com 的 Azure 门户 中删除部署或整个资源。
在 Azure Databricks 门户的“计算”页上,选择群集,然后选择“■ 终止”以将其关闭。
如果已完成对 Azure Databricks 的探索,则可以删除已创建的资源,以避免产生不必要的 Azure 成本并释放订阅中的容量。