Azure Databricks で SQL ウェアハウスを使用する
SQL は、データのクエリと操作を行うための業界標準の言語です。 多くのデータ アナリストが、SQL を使用してリレーショナル データベース内のテーブルに対してクエリを実行することで、データ分析を実行しています。 Azure Databricks には、データ レイク内のファイルに対してリレーショナル データベース レイヤーを提供する、Spark および Delta Lake テクノロジを基盤に構築された SQL 機能が含まれています。
この演習の所要時間は約 30 分です。
注: Azure Databricks ユーザー インターフェイスは継続的な改善の対象となります。 この演習の手順が記述されてから、ユーザー インターフェイスが変更されている場合があります。
Azure Databricks ワークスペースをプロビジョニングする
ヒント: Premium または 試用版 の Azure Databricks ワークスペースが既にお持ちの場合は、この手順をスキップして、既存のワークスペースを使用できます。
この演習には、新しい Azure Databricks ワークスペースをプロビジョニングするスクリプトが含まれています。 このスクリプトは、この演習で必要なコンピューティング コアに対する十分なクォータが Azure サブスクリプションにあるリージョンに、Premium レベルの Azure Databricks ワークスペース リソースを作成しようとします。また、使用するユーザー アカウントのサブスクリプションに、Azure Databricks ワークスペース リソースを作成するための十分なアクセス許可があることを前提としています。 十分なクォータやアクセス許可がないためにスクリプトが失敗した場合は、Azure portal で、Azure Databricks ワークスペースを対話形式で作成してみてください。
- Web ブラウザーで、
https://portal.azure.comの Azure portal にサインインします。 -
ページ上部の検索バーの右側にある [>_] ボタンを使用して、Azure portal に新しい Cloud Shell を作成します。PowerShell 環境を選択します。 次に示すように、Azure portal の下部にあるペインに、Cloud Shell のコマンド ライン インターフェイスが表示されます。
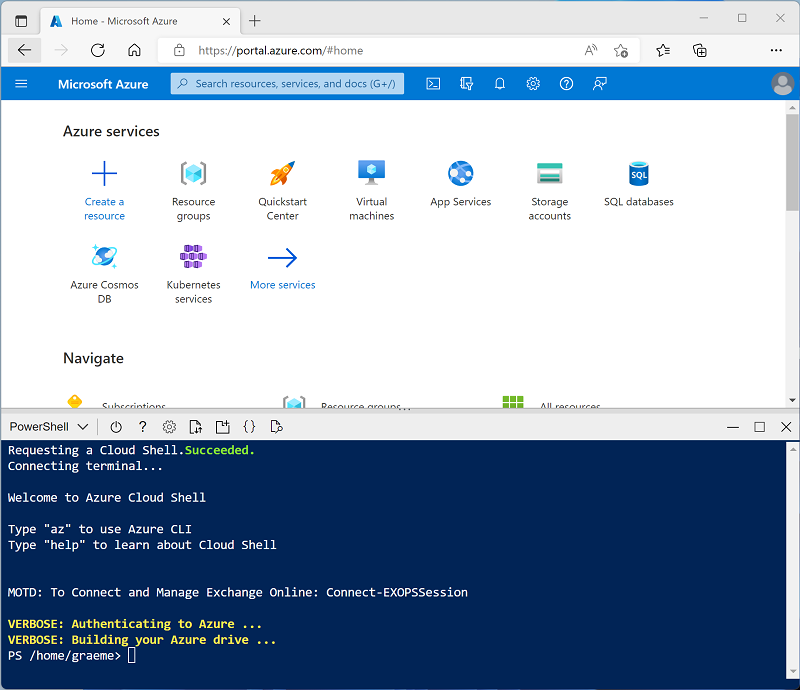
注: Bash 環境を使用するクラウド シェルを以前に作成した場合は、それを PowerShell に切り替えます。
-
ペインの上部にある区分線をドラッグして Cloud Shell のサイズを変更したり、ペインの右上にある — 、 ⤢ 、X アイコンを使用して、ペインを最小化または最大化したり、閉じたりすることができます。 Azure Cloud Shell の使い方について詳しくは、Azure Cloud Shell のドキュメントをご覧ください。
-
PowerShell のペインで、次のコマンドを入力して、リポジトリを複製します。
rm -r mslearn-databricks -f git clone https://github.com/MicrosoftLearning/mslearn-databricks -
リポジトリをクローンした後、次のコマンドを入力して setup.ps1 スクリプトを実行します。これにより、使用可能なリージョンに Azure Databricks ワークスペースがプロビジョニングされます。
./mslearn-databricks/setup.ps1 - メッセージが表示された場合は、使用するサブスクリプションを選択します (これは、複数の Azure サブスクリプションへのアクセス権を持っている場合にのみ行います)。
- スクリプトの完了まで待ちます。通常、約 5 分かかりますが、さらに時間がかかる場合もあります。 待っている間に、Azure Databricks ドキュメントの記事「Azure Databricks のデータ ウェアハウスとは」を確認してください。
SQL ウェアハウスを表示して開始する
- Azure Databricks ワークスペース リソースがデプロイされたら、Azure portal でそのリソースに移動します。
-
Azure Databricks ワークスペースの [概要] ページで、 [ワークスペースの起動] ボタンを使用して、新しいブラウザー タブで Azure Databricks ワークスペースを開きます。求められた場合はサインインします。
ヒント: Databricks ワークスペース ポータルを使用すると、さまざまなヒントと通知が表示される場合があります。 これらは無視し、指示に従ってこの演習のタスクを完了してください。
- Azure Databricks ワークスペース ポータルを表示し、左側のサイド バーに、タスク カテゴリの名前が含まれていることを確認します。
- サイドバーの [SQL] で、 [SQL Warehouses] (SQL Warehouse) を選択します。
- ワークスペースに Starter Warehouse という名前の SQL ウェアハウスが既に含まれていることを確認します。
- その SQL ウェアハウスの [アクション] ( ⁝ ) メニューで、 [編集] を選択します。 次に、 [クラスター サイズ] プロパティを [2X-Small] に設定し、変更を保存します。
- [開始] ボタンを使用して SQL ウェアハウスを起動します (1 - 2 分かかる場合があります)。
注: SQL ウェアハウスの起動に失敗した場合、Azure Databricks ワークスペースがプロビジョニングされているリージョンでサブスクリプションのクォータが不足している可能性があります。 詳細については、「必要な Azure vCPU クォータ」を参照してください。 このような場合は、ウェアハウスの起動に失敗したときのエラー メッセージで詳しく説明されているように、クォータの引き上げを要求してみてください。 または、このワークスペースを削除し、別のリージョンに新しいワークスペースを作成することもできます。 次のように、セットアップ スクリプトのパラメーターとしてリージョンを指定できます:
./setup.ps1 eastus
データベース スキーマの作成
- SQL Warehouse の “実行中” に、サイドバーで [SQL エディター] を選択します。**
- [スキーマ ブラウザー] ペインで、hive_metastore カタログに default という名前のデータベースが含まれていることを確認します。
-
[新しいクエリ] ペインで、次の SQL コードを入力します。
CREATE DATABASE retail_db; - [► 実行 (1000)] ボタンを使用して SQL コードを実行します。
- コードが正常に実行されたら、 [スキーマ ブラウザー] ペインで、ペインの上部にある [更新] ボタンを使用して一覧を更新します。 次に、hive_metastore と retail_db を展開して、データベースが作成されていること、ただしテーブルは含まれていないことを確認します。
ここではテーブルに既定のデータベースを使用できますが、分析データ ストアを構築する場合は、特定のデータ用のカスタム データベースを作成するのが最適です。
テーブルの作成
products.csvファイルをローカル コンピューターにダウンロードし、products.csv として保存します。- Azure Databricks ワークスペース ポータルのサイドバーで、 (+) [新規] を選択し、[データ] を選択します。
- [データの追加] ページで、[テーブルの作成または変更] を選択しダウンロードした products.csv ファイルをコンピューターにアップロードします。
- [ファイルのアップロードからテーブルを作成または変更する] ページで retail_db スキーマを選び、テーブル名を products に設定します。 次に、ページの右下隅にある [テーブルの作成] を選択します。
- テーブルが作成されたら、その詳細を確認します。
ファイルからデータをインポートしてテーブルを作成できるため、データベースを簡単に設定できます。 Spark SQL を使用して、コードを使ってテーブルを作成することもできます。 テーブル自体は Hive メタストアのメタデータ定義であり、含まれるデータは Databricks ファイル システム (DBFS) ストレージにデルタ形式で保存されます。
ダッシュボードを作成する
- サイド バーで [(+) 新規] を選択し、 [ダッシュボード] を選択します。
- [新しいダッシュボード名] を選択し、
Retail Dashboardに変更します。 -
[データ] タブで、[SQL から作成] を選択し、次のクエリを使用します。
SELECT ProductID, ProductName, Category FROM retail_db.products; - [実行] を選択し、無題のデータセットの名前を「
Products and Categories」に変更します。 - [キャンバス] タブを選択し、[視覚化の追加] を選択します。
-
視覚化エディターで、次のプロパティを設定します。
- データセット: 製品とカテゴリ
- 視覚化: バー
- X 軸: COUNT(ProductID)
- Y 軸: カテゴリ
- [発行] を選択すると、ユーザーに表示されるとおりのダッシュボードが表示されます。
ダッシュボードは、ビジネス ユーザーとデータ テーブルや視覚化を共有するための優れた方法です。 ダッシュボードを定期的に更新したり、サブスクライバーに電子メールで送信したりするようにスケジュールできます。
クリーンアップ
Azure Databricks ポータルの [SQL Warehouses] (SQL ウェアハウス) ページでお使いの SQL ウェアハウスを選び、[■ 停止] を選んでシャットダウンします。
Azure Databricks を調べ終わったら、作成したリソースを削除して、不要な Azure のコストを回避し、サブスクリプションの容量を解放できます。