Azure Databricks を使用した LLMOps の実装
Azure Databricks は、データの準備からモデルの提供と監視まで、AI ライフサイクルを合理化し、機械学習システムのパフォーマンスと効率を最適化する統合プラットフォームを提供します。 データ ガバナンス用の Unity カタログ、モデル追跡用の MLflow、LLM をデプロイするための Mosaic AI Model Serving などの機能を利用して、生成 AI アプリケーションの開発をサポートします。
このラボは完了するまで、約 20 分かかります。
注: Azure Databricks ユーザー インターフェイスは継続的な改善の対象となります。 この演習の手順が記述されてから、ユーザー インターフェイスが変更されている場合があります。
開始する前に
管理レベルのアクセス権を持つ Azure サブスクリプションが必要です。
Azure OpenAI リソースをプロビジョニングする
まだ持っていない場合は、Azure サブスクリプションで Azure OpenAI リソースをプロビジョニングします。
- Azure portal (
https://portal.azure.com) にサインインします。 - 次の設定で Azure OpenAI リソースを作成します。
- [サブスクリプション]: “Azure OpenAI Service へのアクセスが承認されている Azure サブスクリプションを選びます”**
- [リソース グループ]: リソース グループを作成または選択します
- [リージョン]: 以下のいずれかのリージョンからランダムに選択する*
- 米国東部 2
- 米国中北部
- スウェーデン中部
- スイス西部
- [名前]: “希望する一意の名前”
- 価格レベル: Standard S0
* Azure OpenAI リソースは、リージョンのクォータによって制限されます。 一覧表示されているリージョンには、この演習で使用されるモデル タイプの既定のクォータが含まれています。 リージョンをランダムに選択することで、サブスクリプションを他のユーザーと共有しているシナリオで、1 つのリージョンがクォータ制限に達するリスクが軽減されます。 演習の後半でクォータ制限に達した場合は、別のリージョンに別のリソースを作成する必要が生じる可能性があります。
-
デプロイが完了するまで待ちます。 次に、Azure portal でデプロイされた Azure OpenAI リソースに移動します。
-
左側のペインで、[リソース管理] の下の [キーとエンドポイント] を選択します。
-
エンドポイントと使用可能なキーの 1 つをコピーしておきます。この演習で、後でこれを使用します。
必要なモデルをデプロイする
Azure には、モデルのデプロイ、管理、調査に使用できる Azure AI Studio という名前の Web ベース ポータルが用意されています。 Azure AI Studio を使用してモデルをデプロイすることで、Azure OpenAI の調査を開始します。
注: Azure AI Studio を使用すると、実行するタスクを提案するメッセージ ボックスが表示される場合があります。 これらを閉じて、この演習の手順に従うことができます。
-
Azure portal にある Azure OpenAI リソースの [概要] ページで、[開始する] セクションまで下にスクロールし、ボタンを選択して Azure AI Studio に移動します。
-
Azure AI Studio の左ペインで、[デプロイ] ページを選び、既存のモデル デプロイを表示します。 まだデプロイがない場合は、次の設定で gpt-35-turbo モデルの新しいデプロイを作成します。
- デプロイ名: gpt-35-turbo
- モデル: gpt-35-turbo
- モデルのバージョン: 既定値
- デプロイの種類:Standard
- 1 分あたりのトークンのレート制限: 5K*
- コンテンツ フィルター: 既定
- 動的クォータを有効にする: 無効
* この演習は、1 分あたり 5,000 トークンのレート制限内で余裕を持って完了できます。またこの制限によって、同じサブスクリプションを使用する他のユーザーのために容量を残すこともできます。
Azure Databricks ワークスペースをプロビジョニングする
ヒント: 既に Azure Databricks ワークスペースがある場合は、この手順をスキップして、既存のワークスペースを使用できます。
- Azure portal (
https://portal.azure.com) にサインインします。 - 次の設定で Azure Databricks リソースを作成します。
- サブスクリプション: Azure OpenAI リソースの作成に使用したサブスクリプションと同じ Azure サブスクリプションを選択します
- リソース グループ: Azure OpenAI リソースを作成したリソース グループと同じです
- リージョン: Azure OpenAI リソースを作成したリージョンと同じです
- [名前]: “希望する一意の名前”
- 価格レベル: Premium または試用版
- [確認および作成] を選択し、デプロイが完了するまで待ちます。 次にリソースに移動し、ワークスペースを起動します。
クラスターの作成
Azure Databricks は、Apache Spark “クラスター” を使用して複数のノードでデータを並列に処理する分散処理プラットフォームです。** 各クラスターは、作業を調整するドライバー ノードと、処理タスクを実行するワーカー ノードで構成されています。 この演習では、ラボ環境で使用されるコンピューティング リソース (リソースが制約される場合がある) を最小限に抑えるために、単一ノード クラスターを作成します。 運用環境では、通常、複数のワーカー ノードを含むクラスターを作成します。
ヒント: Azure Databricks ワークスペースに 13.3 LTS ML 以降のランタイム バージョンを備えたクラスターが既にある場合は、この手順をスキップし、そのクラスターを使用してこの演習を完了できます。
- Azure portal で、Azure Databricks ワークスペースが作成されたリソース グループを参照します。
- Azure Databricks サービス リソースを選択します。
- Azure Databricks ワークスペースの [概要] ページで、[ワークスペースの起動] ボタンを使用して、新しいブラウザー タブで Azure Databricks ワークスペースを開きます。サインインを求められた場合はサインインします。
ヒント: Databricks ワークスペース ポータルを使用すると、さまざまなヒントと通知が表示される場合があります。 これらは無視し、指示に従ってこの演習のタスクを完了してください。
- 左側のサイドバーで、[(+) 新規] タスクを選択し、[クラスター] を選択します。
- [新しいクラスター] ページで、次の設定を使用して新しいクラスターを作成します。
- クラスター名: “ユーザー名の” クラスター (既定のクラスター名)**
- ポリシー:Unrestricted
- クラスター モード: 単一ノード
- アクセス モード: 単一ユーザー (自分のユーザー アカウントを選択)
- Databricks Runtime のバージョン: “以下に該当する最新の非ベータ版ランタイム (標準ランタイム バージョンではない*) の ML エディションを選択します。”
- “GPU を使用しない”
- Scala > 2.11 を含める
- “3.4 以上の Spark を含む”**
- Photon Acceleration を使用する: オフにする
- ノード タイプ: Standard_D4ds_v5
- 非アクティブ状態が ** 20 ** 分間続いた後終了する
- クラスターが作成されるまで待ちます。 これには 1、2 分かかることがあります。
注: クラスターの起動に失敗した場合、Azure Databricks ワークスペースがプロビジョニングされているリージョンでサブスクリプションのクォータが不足していることがあります。 詳細については、「CPU コアの制限によってクラスターを作成できない」を参照してください。 その場合は、ワークスペースを削除し、別のリージョンに新しいワークスペースを作成してみてください。
必要なライブラリをインストールする
-
Databricks ワークスペースで、Workspace セクションに移動します。
-
[作成] を選択し、[ノートブック] を選択します。
-
ノートブックに名前を付け、言語として [
Python] を選択します。 -
最初のコード セルに、次のコードを入力して実行し、OpenAI ライブラリをインストールします。
%pip install openai -
インストールが完了したら、新しいセルでカーネルを再起動します。
%restart_python
MLflow を使用して LLM をログする
MLflow の LLM 追跡機能を使用すると、パラメーター、メトリック、予測、および成果物をログに記録できます。 パラメーターには入力構成の詳細を示すキーと値のペアが含まれるのに対して、メトリックはパフォーマンスの定量的な測定値を提供します。 予測には、入力プロンプトとモデルの応答の両方が含まれており、簡単に取得できるように成果物として格納されています。 この構造化ログは、各対話の詳細な記録を維持するのに役立ち、LLM の分析と最適化の向上を促進します。
-
新しいセルで、この演習の冒頭でコピーしたアクセス情報を含む次のコードを実行して、Azure OpenAI リソースを使用するときに認証用の永続的な環境変数を割り当てます。
import os os.environ["AZURE_OPENAI_API_KEY"] = "your_openai_api_key" os.environ["AZURE_OPENAI_ENDPOINT"] = "your_openai_endpoint" os.environ["AZURE_OPENAI_API_VERSION"] = "2023-03-15-preview" -
新しいセルで、次のコードを実行して、Azure OpenAI クライアントを初期化します。
import os from openai import AzureOpenAI client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"), api_key = os.getenv("AZURE_OPENAI_API_KEY"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) -
新しいセルで、次のコードを実行して、MLflow 追跡を初期化しモデルをログに記録します。
import mlflow from openai import AzureOpenAI system_prompt = "Assistant is a large language model trained by OpenAI." mlflow.openai.autolog() with mlflow.start_run(): response = client.chat.completions.create( model="gpt-35-turbo", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "Tell me a joke about animals."}, ], ) print(response.choices[0].message.content) mlflow.log_param("completion_tokens", response.usage.completion_tokens) mlflow.end_run()
上記のセルは、ワークスペースで実験を開始し、各チャット完了イテレーションのトレースを登録して、各実行の入力、出力、およびメタデータを追跡します。
モデルを監視する
-
左側のサイドバーで [実験] を選択し、この演習で使用したノートブックに関連付けられている実験を選択します。 最新の実行を選択し、ログに記録された 1 つのパラメーター
completion_tokensがあることを [概要] ページで確認します。 コマンドmlflow.openai.autolog()を実行すると、既定で各実行のトレースがログに記録されますが、モデルを監視するために後で使用できるmlflow.log_param()を使用すると、追加のパラメーターをログに記録することもできます。 -
[トレース] タブを選択し、最後に作成されたものを選択します。
completion_tokensパラメーターがトレースの出力に含まれていることを確認します。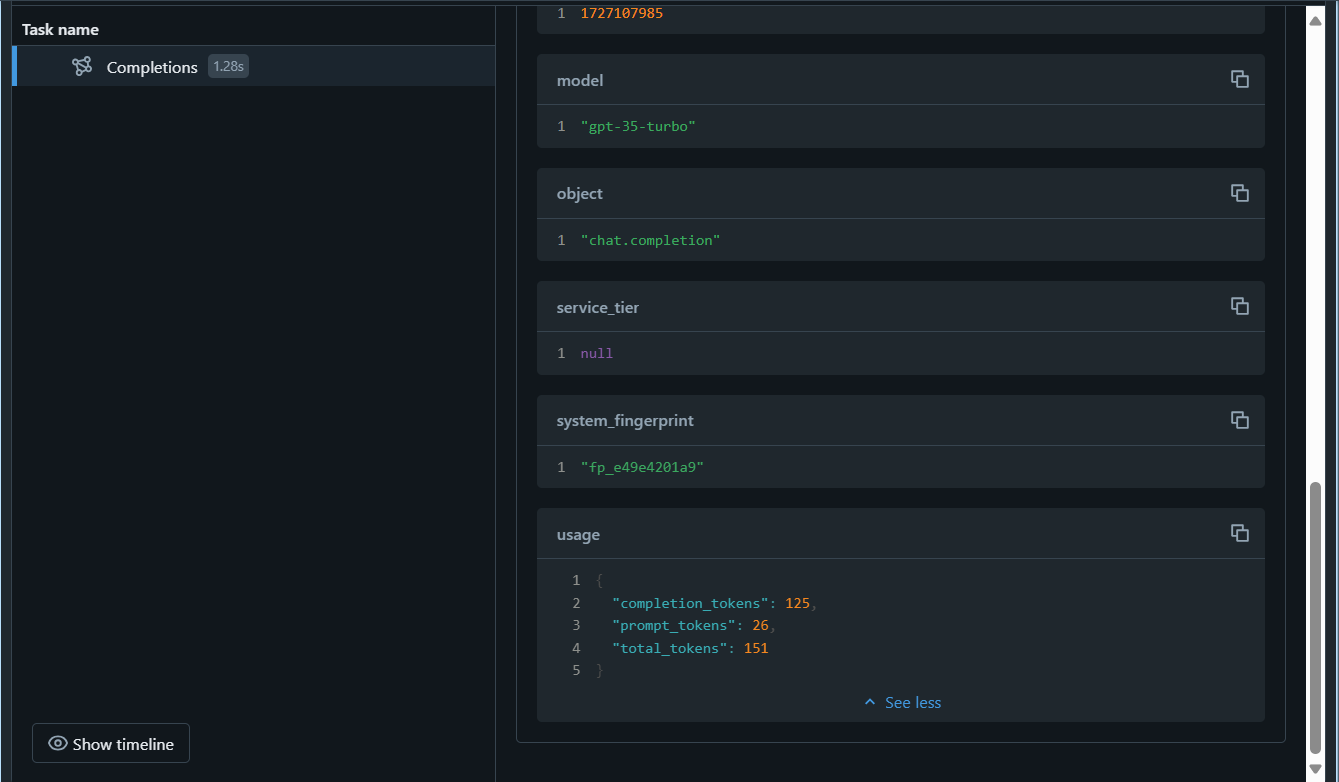
モデルの監視を開始したら、さまざまな実行のトレースを比較してデータ ドリフトを検出できます。 入力データ分布、モデル予測、またはパフォーマンス メトリックの大幅な時間的変化を探します。 統計テストまたは視覚化ツールを使用すると、この分析に役立ちます。
クリーンアップ
Azure OpenAI リソースでの作業が完了したら、Azure portal (https://portal.azure.com) でデプロイまたはリソース全体を忘れずに削除します。
Azure Databricks ポータルの [コンピューティング] ページでクラスターを選択し、[■ 終了] を選択してクラスターをシャットダウンします。
Azure Databricks を調べ終わったら、作成したリソースを削除できます。これにより、不要な Azure コストが生じないようになり、サブスクリプションの容量も解放されます。