Implementación de LLMOps con Azure Databricks
Azure Databricks proporciona una plataforma unificada que simplifica el ciclo de vida de la inteligencia artificial, desde la preparación de datos hasta la supervisión y el servicio de modelos, optimizando el rendimiento y la eficacia de los sistemas de aprendizaje automático. Admite el desarrollo de aplicaciones de IA generativa, aprovechando características como Unity Catalog para la gobernanza de datos, MLflow para el seguimiento de modelos y Mosaic AI Model Serving para implementar LLM.
Este laboratorio se tarda aproximadamente 20 minutos en completarse.
Nota: la interfaz de usuario de Azure Databricks está sujeta a una mejora continua. Es posible que la interfaz de usuario haya cambiado desde que se escribieron las instrucciones de este ejercicio.
Antes de empezar
Necesitará una suscripción de Azure en la que tenga acceso de nivel administrativo.
Aprovisionamiento de un recurso de Azure OpenAI
Si aún no tienes uno, aprovisiona un recurso de Azure OpenAI en la suscripción a Azure.
- Inicia sesión en Azure Portal en
https://portal.azure.com. - Crea un recurso de Azure OpenAI con la siguiente configuración:
- Suscripción: selecciona una suscripción a Azure aprobada para acceder al servicio Azure OpenAI
- Grupo de recursos: elige o crea un grupo de recursos
- Región: elige de forma aleatoria cualquiera de las siguientes regiones*
- Este de EE. UU. 2
- Centro-Norte de EE. UU
- Centro de Suecia
- Oeste de Suiza
- Nombre: nombre único que prefieras
- Plan de tarifa: estándar S0
* Los recursos de Azure OpenAI están restringidos por cuotas regionales. Las regiones enumeradas incluyen la cuota predeterminada para los tipos de modelo usados en este ejercicio. Elegir aleatoriamente una región reduce el riesgo de que una sola región alcance su límite de cuota en escenarios en los que se comparte una suscripción con otros usuarios. En caso de que se alcance un límite de cuota más adelante en el ejercicio, es posible que tengas que crear otro recurso en otra región.
-
Espera a que la implementación finalice. Luego, ve al recurso de Azure OpenAI implementado en Azure Portal.
-
En el panel de la izquierda, en Administración de recursos, selecciona Claves y puntos de conexión.
-
Copia el punto de conexión y una de las claves disponibles, ya que los usarás más adelante en este ejercicio.
Implementación del modelo necesario
Azure proporciona un portal basado en web denominado Fundición de IA de Azure, que puedes usar para implementar, administrar y explorar modelos. Comenzarás la exploración de Azure OpenAI mediante la Fundición de IA de Azure para implementar un modelo.
Nota: A medida que usas la Fundición de IA de Azure, es posible que se muestren cuadros de mensaje que sugieren tareas para que las realices. Puedes cerrarlos y seguir los pasos descritos en este ejercicio.
-
En Azure Portal, en la página Información general del recurso de Azure OpenAI, desplázate hacia abajo hasta la sección Introducción y selecciona el botón para ir a la Fundición de IA de Azure.
-
En la Fundición de IA de Azure, en el panel de la izquierda, selecciona la página Implementaciones y visualiza las implementaciones de modelos existentes. Si aún no tienes una, crea una nueva implementación del modelo gpt-4o con la siguiente configuración:
- Nombre de implementación: gpt-4o
- Tipo de implementación: estándar
- Versión del modelo: usa la versión predeterminada
- Límite de velocidad de tokens por minuto: 10 000*
- Filtro de contenido: valor predeterminado
- Habilitación de la cuota dinámica: deshabilitada
* Un límite de velocidad de 10 000 tokens por minuto es más que adecuado para completar este ejercicio, al tiempo que deja capacidad para otras personas que usan la misma suscripción.
Aprovisiona un área de trabajo de Azure Databricks.
Sugerencia: si ya tienes un área de trabajo de Azure Databricks, puedes omitir este procedimiento y usar el área de trabajo existente.
- Inicia sesión en Azure Portal en
https://portal.azure.com. - Crea un recurso de Azure Databricks con la siguiente configuración:
- Suscripción: selecciona la misma suscripción a Azure que usaste para crear tu recurso de Azure OpenAI
- Grupo de recursos: el mismo grupo de recursos donde creaste tu recurso de Azure OpenAI
- Región: la misma región donde creaste tu recurso de Azure OpenAI
- Nombre: nombre único que prefieras
- Plan de tarifa: Premium o Prueba
- Selecciona Revisar y crear y espera a que se complete la implementación. Después, ve al recurso e inicia el espacio de trabajo.
Crear un clúster
Azure Databricks es una plataforma de procesamiento distribuido que usa clústeres* de Apache Spark para procesar datos en paralelo en varios nodos. Cada clúster consta de un nodo de controlador para coordinar el trabajo y nodos de trabajo para hacer tareas de procesamiento. En este ejercicio, crearás un clúster de *nodo único para minimizar los recursos de proceso usados en el entorno de laboratorio (en los que se pueden restringir los recursos). En un entorno de producción, normalmente crearías un clúster con varios nodos de trabajo.
Sugerencia: Si ya dispone de un clúster con una versión de runtime 16.4 LTS ML o superior en el área de trabajo de Azure Databricks, puede utilizarlo para completar este ejercicio y omitir este procedimiento.
- En Azure Portal, ve al grupo de recursos donde se creó el espacio de trabajo de Azure Databricks.
- Selecciona tu recurso del servicio Azure Databricks.
- En la página Información general del área de trabajo, usa el botón Inicio del área de trabajo para abrir el área de trabajo de Azure Databricks en una nueva pestaña del explorador; inicia sesión si se solicita.
Sugerencia: al usar el portal del área de trabajo de Databricks, se pueden mostrar varias sugerencias y notificaciones. Descártalas y sigue las instrucciones proporcionadas para completar las tareas de este ejercicio.
- En la barra lateral de la izquierda, selecciona la tarea (+) Nuevo y luego selecciona Clúster.
- En la página Nuevo clúster, crea un clúster con la siguiente configuración:
- Nombre del clúster: clúster del Nombre de usuario (el nombre del clúster predeterminado)
- Directiva: Unrestricted (Sin restricciones)
- Aprendizaje automático: Habilitado
- Databricks Runtime: 16.4 LTS
- Utilizar la Aceleración de fotones: No seleccionada
- Tipo de trabajo: Standard_D4ds_v5
- Nodo único: Activado
- Espera a que se cree el clúster. Esto puede tardar un par de minutos.
Nota: si el clúster no se inicia, es posible que la suscripción no tenga cuota suficiente en la región donde se aprovisiona el área de trabajo de Azure Databricks. Para obtener más información, consulta El límite de núcleos de la CPU impide la creación de clústeres. Si esto sucede, puedes intentar eliminar el área de trabajo y crear una nueva en otra región.
Registra el LLM mediante MLflow
Las funcionalidades de seguimiento de LLM de MLflow te permiten registrar parámetros, métricas, predicciones y Artifacts. Los parámetros incluyen pares clave-valor que detallan las configuraciones de entrada, mientras que las métricas proporcionan medidas cuantitativas de rendimiento. Las predicciones abarcan las solicitudes de entrada y las respuestas del modelo, almacenadas como Artifacts para facilitar la recuperación. Este registro estructurado ayuda a mantener un registro detallado de cada interacción, lo que facilita un mejor análisis y optimización de las LLM.
-
En una celda nueva, ejecuta el código siguiente con la información de acceso que copiaste al principio de este ejercicio para asignar variables de entorno persistentes para la autenticación al usar recursos de Azure OpenAI:
import os os.environ["AZURE_OPENAI_API_KEY"] = "your_openai_api_key" os.environ["AZURE_OPENAI_ENDPOINT"] = "your_openai_endpoint" os.environ["AZURE_OPENAI_API_VERSION"] = "2024-05-01-preview" -
En una nueva celda, ejecuta el código siguiente para inicializar el cliente de Azure OpenAI:
import os from openai import AzureOpenAI client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"), api_key = os.getenv("AZURE_OPENAI_API_KEY"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) -
En una nueva celda, ejecuta el código siguiente para inicializar el seguimiento de MLflow y registrar el modelo:
import mlflow from openai import AzureOpenAI system_prompt = "Assistant is a large language model trained by OpenAI." mlflow.openai.autolog() with mlflow.start_run(): response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "Tell me a joke about animals."}, ], ) print(response.choices[0].message.content) mlflow.log_param("completion_tokens", response.usage.completion_tokens) mlflow.end_run()
La celda anterior iniciará un experimento en tu área de trabajo y registrará los seguimientos de cada iteración de finalización de chat, para realizar un seguimiento de las entradas, salidas y metadatos de cada ejecución.
Supervisión del modelo
Después de ejecutar la última celda, la interfaz de usuario de seguimiento de MLflow se mostrará automáticamente junto con la salida de la celda. También puede verlo si selecciona Experimentos en la barra lateral de la izquierda y, después, abre la ejecución del experimento del cuaderno:
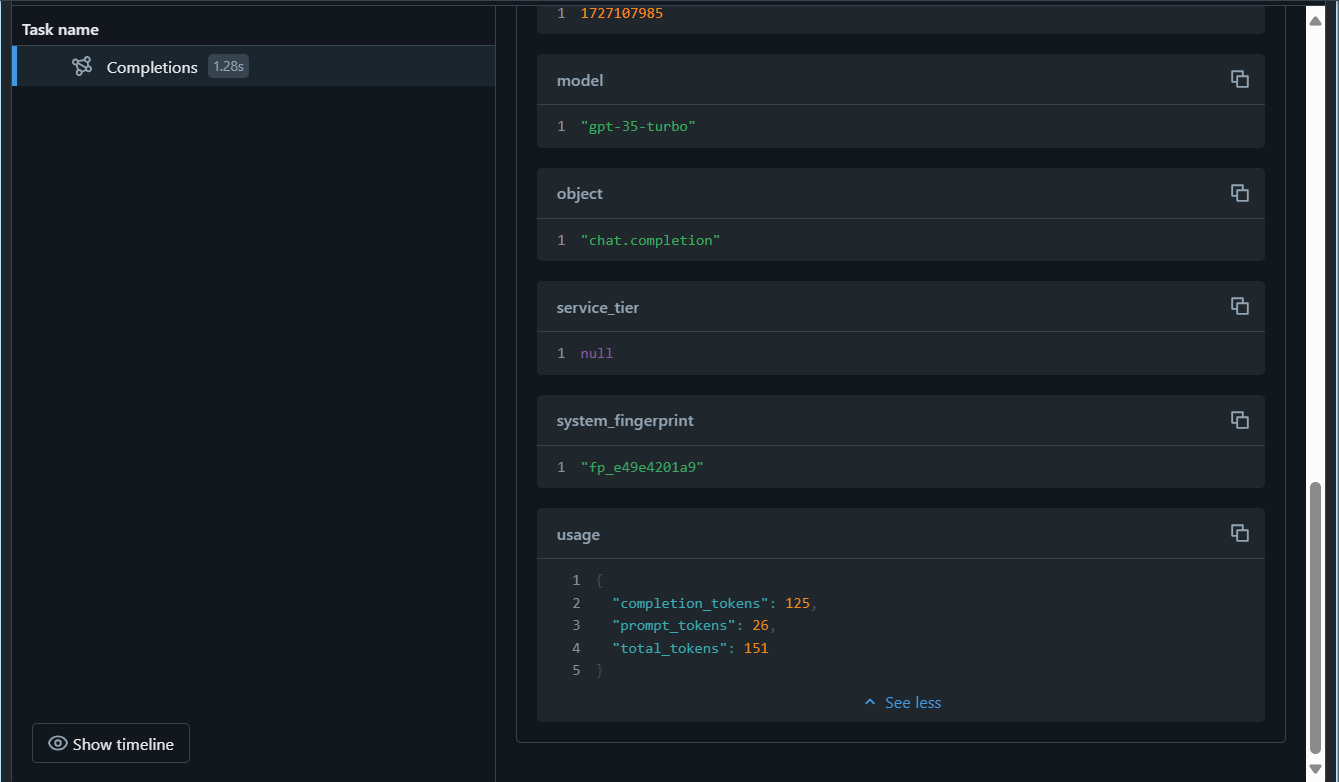
El comando mlflow.openai.autolog() registrará los seguimientos de cada ejecución de forma predeterminada, pero también puedes registrar parámetros adicionales con mlflow.log_param() que se pueden usar más adelante para supervisar el modelo. Una vez que empieces a supervisar el modelo, puedes comparar los seguimientos de diferentes ejecuciones para detectar el desfase de datos. Busca cambios significativos en las distribuciones de datos de entrada, las predicciones del modelo o las métricas de rendimiento a lo largo del tiempo. También puede usar pruebas estadísticas o herramientas de visualización para ayudarle en este análisis.
Limpieza
Cuando hayas terminado de usar el recurso de Azure OpenAI, recuerda eliminar la implementación o todo el recurso en Azure Portal, en https://portal.azure.com.
En el portal de Azure Databricks, en la página Proceso, selecciona el clúster y ■ Finalizar para apagarlo.
Si has terminado de explorar Azure Databricks, puedes eliminar los recursos que has creado para evitar costes innecesarios de Azure y liberar capacidad en tu suscripción.