Untersuchen von Daten mit Azure Databricks
Azure Databricks ist eine Microsoft Azure-basierte Version der beliebten Open-Source-Databricks-Plattform.
Azure Databricks erleichtert die explorative Datenanalyse (EDA), sodass Benutzende schnell Erkenntnisse gewinnen und Entscheidungen unterstützen können. Es ist in eine Vielzahl von Tools und Techniken für EDA integriert, einschließlich statistischer Methoden und Visualisierungen, um Datenmerkmale zusammenzufassen und zugrunde liegende Probleme zu identifizieren.
Diese Übung dauert ca. 30 Minuten.
Hinweis: Die Benutzeroberfläche von Azure Databricks wird kontinuierlich verbessert. Die Benutzeroberfläche kann sich seit der Erstellung der Anweisungen in dieser Übung geändert haben.
Bereitstellen eines Azure Databricks-Arbeitsbereichs
Tipp: Wenn Sie bereits über einen Azure Databricks-Arbeitsbereich verfügen, können Sie dieses Verfahren überspringen und Ihren vorhandenen Arbeitsbereich verwenden.
Diese Übung enthält ein Skript zum Bereitstellen eines neuen Azure Databricks-Arbeitsbereichs. Das Skript versucht, eine Azure Databricks-Arbeitsbereichsressource im Premium-Tarif in einer Region zu erstellen, in der Ihr Azure-Abonnement über ein ausreichendes Kontingent für die in dieser Übung erforderlichen Computekerne verfügt. Es wird davon ausgegangen, dass Ihr Benutzerkonto über ausreichende Berechtigungen im Abonnement verfügt, um eine Azure Databricks-Arbeitsbereichsressource zu erstellen.
Wenn das Skript aufgrund unzureichender Kontingente oder Berechtigungen fehlschlägt, können Sie versuchen, einen Azure Databricks-Arbeitsbereich interaktiv im Azure-Portal zu erstellen.
- Melden Sie sich in einem Webbrowser am Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie die Taste [>_] rechts neben der Suchleiste oben auf der Seite, um eine neue Cloud Shell im Azure-Portal zu erstellen, und wählen Sie eine PowerShell-Umgebung aus. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
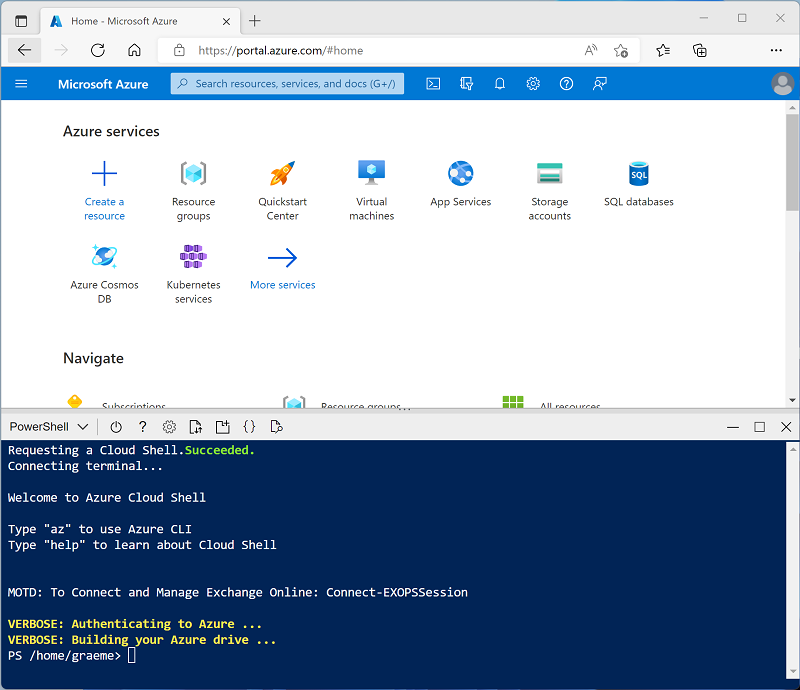
Hinweis: Wenn Sie zuvor eine Cloud-Shell erstellt haben, die eine Bash-Umgebung verwendet, wechseln Sie zu PowerShell.
-
Beachten Sie, dass Sie die Größe der Cloud-Shell ändern können, indem Sie die Trennlinie oben im Bereich ziehen oder die Symbole —, ⤢ und X oben rechts im Bereich verwenden, um den Bereich zu minimieren, zu maximieren und zu schließen. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r mslearn-databricks -f git clone https://github.com/MicrosoftLearning/mslearn-databricks -
Nachdem das Repository geklont wurde, geben Sie den folgenden Befehl ein, um das Skript setup.ps1 auszuführen, das einen Azure Databricks-Arbeitsbereich in einer verfügbaren Region bereitstellt:
./mslearn-databricks/setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 5 Minuten, in einigen Fällen kann es jedoch länger dauern. Während Sie warten, lesen Sie den Artikel Explorative Datenanalyse in Azure Databricks in der Dokumentation zu Azure Databricks.
Erstellen eines Clusters
Azure Databricks ist eine verteilte Verarbeitungsplattform, die Apache Spark-Cluster verwendet, um Daten parallel auf mehreren Knoten zu verarbeiten. Jeder Cluster besteht aus einem Treiberknoten, um die Arbeit zu koordinieren, und Arbeitsknoten zum Ausführen von Verarbeitungsaufgaben.
In dieser Übung erstellen Sie einen Einzelknotencluster , um die in der Lab-Umgebung verwendeten Computeressourcen zu minimieren (in denen Ressourcen möglicherweise eingeschränkt werden). In einer Produktionsumgebung erstellen Sie in der Regel einen Cluster mit mehreren Workerknoten.
Tipp: Wenn Sie bereits über einen Cluster mit einer Runtime 13.3 LTS oder einer höheren Runtimeversion in Ihrem Azure Databricks-Arbeitsbereich verfügen, können Sie ihn verwenden, um diese Übung abzuschließen und dieses Verfahren zu überspringen.
- Navigieren Sie im Azure-Portal zur Ressourcengruppe msl-xxxxxxx, die vom Skript erstellt wurde (oder zur Ressourcengruppe, die Ihren vorhandenen Azure Databricks-Arbeitsbereich enthält).
- Wählen Sie die Ressource Ihres Azure Databricks-Diensts aus (sie trägt den Namen databricks-xxxxxxx, wenn Sie das Setupskript zum Erstellen verwendet haben).
-
Verwenden Sie auf der Seite Übersicht für Ihren Arbeitsbereich die Schaltfläche Arbeitsbereich starten, um Ihren Azure Databricks-Arbeitsbereich auf einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Während Sie das Databricks-Arbeitsbereichsportal verwenden, werden möglicherweise verschiedene Tipps und Benachrichtigungen angezeigt. Schließen Sie diese, und folgen Sie den Anweisungen, um die Aufgaben in dieser Übung auszuführen.
- Wählen Sie in der linken Seitenleiste die Option (+) Neue Aufgabe und dann Cluster aus (ggf. im Untermenü Mehr suchen).
- Erstellen Sie auf der Seite Neuer Cluster einen neuen Cluster mit den folgenden Einstellungen:
- Clustername: Cluster des Benutzernamens (der Standardclustername)
- Richtlinie: Unrestricted
- Clustermodus: Einzelknoten
- Zugriffsmodus: Einzelner Benutzer (Ihr Benutzerkonto ist ausgewählt)
- Databricks-Runtimeversion: 13.3 LTS (Spark 3.4.1, Scala 2.12) oder höher
- Photonbeschleunigung verwenden: Ausgewählt
- Knotentyp: Standard_D4ds_v5
- Beenden nach 20 Minuten Inaktivität
- Warten Sie, bis der Cluster erstellt wurde. Es kann ein oder zwei Minuten dauern.
Hinweis: Wenn Ihr Cluster nicht gestartet werden kann, verfügt Ihr Abonnement möglicherweise über ein unzureichendes Kontingent in der Region, in der Ihr Azure Databricks-Arbeitsbereich bereitgestellt wird. Details finden Sie unter Der Grenzwert für CPU-Kerne verhindert die Clustererstellung. In diesem Fall können Sie versuchen, Ihren Arbeitsbereich zu löschen und in einer anderen Region einen neuen zu erstellen. Sie können einen Bereich als Parameter für das Setupskript wie folgt angeben:
./mslearn-databricks/setup.ps1 eastus
Erstellen eines Notebooks
-
Verwenden Sie in der Randleiste den Link ** (+) Neu, um ein **Notebook zu erstellen.
-
Ändern Sie den Standardnamen des Notebooks (Unbenanntes Notebook [Datum]) in
Explore data with Sparkund wählen Sie in der Dropdown-Liste Verbinden Ihren Cluster aus, falls er nicht bereits ausgewählt ist. Wenn der Cluster nicht ausgeführt wird, kann es eine Minute dauern, bis er gestartet wird.
Einlesen von Daten
-
Geben Sie in der ersten Zelle des Notebooks den folgenden Code ein, der mit Shell-Befehlen die Datendateien von GitHub in das von Ihrem Cluster verwendete Dateisystem herunterlädt.
%sh rm -r /dbfs/spark_lab mkdir /dbfs/spark_lab wget -O /dbfs/spark_lab/2019.csv https://raw.githubusercontent.com/MicrosoftLearning/mslearn-databricks/main/data/2019.csv wget -O /dbfs/spark_lab/2020.csv https://raw.githubusercontent.com/MicrosoftLearning/mslearn-databricks/main/data/2020.csv wget -O /dbfs/spark_lab/2021.csv https://raw.githubusercontent.com/MicrosoftLearning/mslearn-databricks/main/data/2021.csv -
Verwenden Sie Menüoption ▸ Zelle Ausführen links neben der Zelle, um sie auszuführen. Warten Sie dann, bis der vom Code ausgeführte Spark-Auftrag, abgeschlossen ist.
Abfragen von Daten in Dateien
-
Fahren Sie mit der Maus unter die vorhandene Codezelle und verwenden Sie das angezeigte Symbol + Code, um eine neue Codezelle hinzuzufügen. Geben Sie dann in die neue Zelle den folgenden Code ein, und führen Sie ihn aus, um die Daten aus den Dateien zu laden und die ersten 100 Zeilen anzuzeigen.
df = spark.read.load('spark_lab/*.csv', format='csv') display(df.limit(100)) -
Zeigen Sie die Ausgabe an, und beachten Sie, dass sich die Daten in der Datei auf Verkaufsaufträge beziehen, aber keine Spaltenüberschriften oder Informationen über die Datentypen enthalten. Um die Daten übersichtlicher zu gestalten, können Sie ein Schema für den DataFrame definieren.
-
Fügen Sie eine neue Codezelle hinzu, und verwenden Sie diese, um den folgenden Code auszuführen, der ein Schema für die Daten definiert:
from pyspark.sql.types import * from pyspark.sql.functions import * orderSchema = StructType([ StructField("SalesOrderNumber", StringType()), StructField("SalesOrderLineNumber", IntegerType()), StructField("OrderDate", DateType()), StructField("CustomerName", StringType()), StructField("Email", StringType()), StructField("Item", StringType()), StructField("Quantity", IntegerType()), StructField("UnitPrice", FloatType()), StructField("Tax", FloatType()) ]) df = spark.read.load('/spark_lab/*.csv', format='csv', schema=orderSchema) display(df.limit(100)) -
Beachten Sie, dass der DataFrame dieses Mal Spaltenüberschriften enthält. Fügen Sie dann eine neue Codezelle hinzu und verwenden Sie diese, um den folgenden Code auszuführen, um Details des DataFrame-Schemas anzuzeigen und zu überprüfen, ob die richtigen Datentypen angewendet wurden:
df.printSchema()
Abfragen von Daten mithilfe von Spark SQL
-
Fügen Sie eine neue Codezelle hinzu, und verwenden Sie diese, um den folgenden Code auszuführen:
df.createOrReplaceTempView("salesorders") spark_df = spark.sql("SELECT * FROM salesorders") display(spark_df)Mit den nativen Methoden des Dataframe-Objekts, das Sie zuvor verwendet haben, können Sie Daten sehr effektiv abfragen und analysieren. Viele Datenanalysten arbeiten jedoch lieber mit SQL-Syntax. Spark SQL ist eine SQL-Sprach-API in Spark, die Sie verwenden können, um SQL-Anweisungen auszuführen oder sogar um Daten in relationalen Tabellen zu speichern.
Der soeben ausgeführte Code erstellt eine relationale Ansicht der Daten in einem DataFrame und verwendet dann die Bibliothek spark.sql, um Spark SQL-Syntax in Ihren Python-Code einzubetten, die Ansicht abzufragen und die Ergebnisse als Datenframe zurückzugeben.
Anzeigen von Ergebnissen als Visualisierung
-
Führen Sie in einer neuen Codezelle den folgenden Code aus, um die Tabelle salesorders abzufragen:
%sql SELECT * FROM salesorders - Wählen Sie oberhalb der Ergebnistabelle + und dann Visualisierung aus, um den Visualisierungs-Editor anzuzeigen, und wenden Sie dann die folgenden Optionen an:
- Visualisierungstyp: Balken
- X-Spalte: Element
- Y-Spalte: Fügen Sie eine neue Spalte hinzu, und wählen Sie *Menge aus. *Wenden Sie die Aggregation Summe aus.
- Speichern Sie die Visualisierung, und führen Sie dann die Codezelle erneut aus, um das resultierende Diagramm im Notebook anzuzeigen.
Erste Schritte mit matplotlib
-
Führen Sie in einer neuen Codezelle den folgenden Code aus, um einige Verkaufsauftragsdaten in einen DataFrame abzurufen:
sqlQuery = "SELECT CAST(YEAR(OrderDate) AS CHAR(4)) AS OrderYear, \ SUM((UnitPrice * Quantity) + Tax) AS GrossRevenue \ FROM salesorders \ GROUP BY CAST(YEAR(OrderDate) AS CHAR(4)) \ ORDER BY OrderYear" df_spark = spark.sql(sqlQuery) df_spark.show() -
Fügen Sie eine neue Codezelle hinzu, und verwenden Sie diese, um den folgenden Code auszuführen, der die Bibliothek matplotlib importiert und zum Erstellen eines Diagramms verwendet:
from matplotlib import pyplot as plt # matplotlib requires a Pandas dataframe, not a Spark one df_sales = df_spark.toPandas() # Create a bar plot of revenue by year plt.bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue']) # Display the plot plt.show() - Überprüfen Sie die Ergebnisse, die aus einem Säulendiagramm mit dem Gesamtbruttoumsatz für jedes Jahr bestehen. Beachten Sie die folgenden Features des Codes, der zum Erstellen dieses Diagramms verwendet wird:
- Die Bibliothek matplotlib erfordert einen Pandas-DataFrame. Deshalb müssen Sie den Spark-DataFrame, der von der Spark SQL-Abfrage zurückgegeben wird, in dieses Format konvertieren.
- Der Kern der matplotlib-Bibliothek ist das pyplot-Objekt. Dies ist die Grundlage für die meisten Darstellungsfunktionen.
-
Die Standardeinstellungen ergeben ein brauchbares Diagramm, aber es gibt beträchtliche Möglichkeiten, es anzupassen. Fügen Sie eine neue Codezelle mit dem folgenden Code hinzu, und führen Sie ihn aus:
# Clear the plot area plt.clf() # Create a bar plot of revenue by year plt.bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue'], color='orange') # Customize the chart plt.title('Revenue by Year') plt.xlabel('Year') plt.ylabel('Revenue') plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7) plt.xticks(rotation=45) # Show the figure plt.show() -
Plots sind technisch gesehen in Abbildungen enthalten. In den vorherigen Beispielen wurde die Abbildung implizit für Sie erstellt, aber Sie können sie auch explizit erstellen. Versuchen Sie, Folgendes in einer neuen Zelle auszuführen:
# Clear the plot area plt.clf() # Create a Figure fig = plt.figure(figsize=(8,3)) # Create a bar plot of revenue by year plt.bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue'], color='orange') # Customize the chart plt.title('Revenue by Year') plt.xlabel('Year') plt.ylabel('Revenue') plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7) plt.xticks(rotation=45) # Show the figure plt.show() -
Eine Abbildung kann mehrere Teilplots enthalten (jeweils auf einer eigenen Achse). Verwenden Sie diesen Code zum Erstellen mehrerer Diagramme:
# Clear the plot area plt.clf() # Create a figure for 2 subplots (1 row, 2 columns) fig, ax = plt.subplots(1, 2, figsize = (10,4)) # Create a bar plot of revenue by year on the first axis ax[0].bar(x=df_sales['OrderYear'], height=df_sales['GrossRevenue'], color='orange') ax[0].set_title('Revenue by Year') # Create a pie chart of yearly order counts on the second axis yearly_counts = df_sales['OrderYear'].value_counts() ax[1].pie(yearly_counts) ax[1].set_title('Orders per Year') ax[1].legend(yearly_counts.keys().tolist()) # Add a title to the Figure fig.suptitle('Sales Data') # Show the figure plt.show()
Hinweis: Weitere Informationen zur Darstellung mit „matplotlib“ finden Sie in der matplotlib-Dokumentation.
Verwenden der seaborn-Bibliothek
-
Fügen Sie eine neue Codezelle hinzu, und verwenden Sie sie, um den folgenden Code auszuführen, der die Bibliothek seaborn (die auf matplotlib basiert und einen Teil ihrer Komplexität abstrahiert) zum Erstellen eines Diagramms verwendet:
import seaborn as sns # Clear the plot area plt.clf() # Create a bar chart ax = sns.barplot(x="OrderYear", y="GrossRevenue", data=df_sales) plt.show() -
Die Bibliothek seaborn vereinfacht die Erstellung komplexer Diagramme für statistische Daten und ermöglicht es Ihnen, das visuelle Thema für konsistente Datenvisualisierungen zu steuern. Führen Sie den folgenden Code in eine neue Zelle aus:
# Clear the plot area plt.clf() # Set the visual theme for seaborn sns.set_theme(style="whitegrid") # Create a bar chart ax = sns.barplot(x="OrderYear", y="GrossRevenue", data=df_sales) plt.show() -
Wie matplotlib. seaborn unterstützt mehrere Diagrammtypen. Führen Sie den folgenden Code aus, um ein Liniendiagramm zu erstellen:
# Clear the plot area plt.clf() # Create a bar chart ax = sns.lineplot(x="OrderYear", y="GrossRevenue", data=df_sales) plt.show()
Hinweis: Weitere Informationen zur Darstellung mithilfe der seaborn-Bibliothek finden Sie in der seaborn-Dokumentation.
Bereinigung
Wählen Sie zunächst im Azure Databricks-Portal auf der Seite Compute Ihren Cluster und dann ■ Beenden aus, um ihn herunterzufahren.
Wenn Sie die Erkundung von Azure Databricks abgeschlossen haben, löschen Sie die erstellten Ressourcen, um unnötige Azure-Kosten zu vermeiden und Kapazität in Ihrem Abonnement freizugeben.