Einführung in Azure Databricks
Azure Databricks ist eine Microsoft Azure-basierte Version der beliebten Open-Source-Databricks-Plattform.
Ein Azure Databricks Workspace bietet einen zentralen Punkt für die Verwaltung von Databricks-Clustern, -Daten und -Ressourcen in Azure.
In dieser Übung stellen Sie einen Azure Databricks-Arbeitsbereich bereit und erkunden einige seiner Kernfunktionen.
Diese Übung dauert ca. 20 Minuten.
Hinweis: Die Benutzeroberfläche von Azure Databricks wird kontinuierlich verbessert. Die Benutzeroberfläche kann sich seit der Erstellung der Anweisungen in dieser Übung geändert haben.
Bereitstellen eines Azure Databricks-Arbeitsbereichs
Tipp: Wenn Sie bereits über einen Azure Databricks-Arbeitsbereich verfügen, können Sie dieses Verfahren überspringen und Ihren vorhandenen Arbeitsbereich verwenden.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. - Erstellen Sie eine Azure Databricks-Ressource mit den folgenden Einstellungen:
- Abonnement: Wählen Sie Ihr Azure-Abonnement aus.
- Ressourcengruppe: Erstellen einer neuen Ressourcengruppe mit dem Namen
msl-xxxxxxx(wobei „xxxxxxx“ ein eindeutiger Wert ist) - Arbeitsbereichsname:
databricks-xxxxxxx(wobei „xxxxxxx“ der Wert ist, der im Ressourcengruppennamen verwendet wird) - Region: Wählen Sie eine beliebige verfügbare Region aus.
- Preisstufe: Premium oder Testversion
- Gruppenname der verwalteten Ressource:
databricks-xxxxxxx-managed(wobei „xxxxxxx“ der Wert ist, der im Ressourcengruppennamen verwendet wird)
- Wählen Sie Überprüfen + Erstellen und warten Sie, bis die Bereitstellung abgeschlossen ist. Wechseln Sie dann zur Ressource, und starten Sie den Arbeitsbereich.
Erstellen eines Clusters
Azure Databricks ist eine verteilte Verarbeitungsplattform, die Apache Spark-Cluster verwendet, um Daten parallel auf mehreren Knoten zu verarbeiten. Jeder Cluster besteht aus einem Treiberknoten, um die Arbeit zu koordinieren, und Arbeitsknoten zum Ausführen von Verarbeitungsaufgaben. In dieser Übung erstellen Sie einen Einzelknotencluster , um die in der Lab-Umgebung verwendeten Computeressourcen zu minimieren (in denen Ressourcen möglicherweise eingeschränkt werden). In einer Produktionsumgebung erstellen Sie in der Regel einen Cluster mit mehreren Workerknoten.
Tipp: Wenn Sie bereits über einen Cluster mit einer Runtime 13.3 LTS oder einer höheren Runtimeversion in Ihrem Azure Databricks-Arbeitsbereich verfügen, können Sie ihn verwenden, um diese Übung abzuschließen und dieses Verfahren zu überspringen.
- Navigieren Sie im Azure-Portal zur Ressourcengruppe msl-xxxxxxx (oder zur Ressourcengruppe, die Ihren vorhandenen Azure Databricks-Arbeitsbereich enthält), und wählen Sie Ihre Azure Databricks Service-Ressource aus.
-
Verwenden Sie auf der Seite Übersicht für Ihren Arbeitsbereich die Schaltfläche Arbeitsbereich starten, um Ihren Azure Databricks-Arbeitsbereich auf einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Während Sie das Databricks-Arbeitsbereichsportal verwenden, werden möglicherweise verschiedene Tipps und Benachrichtigungen angezeigt. Schließen Sie diese, und folgen Sie den Anweisungen, um die Aufgaben in dieser Übung auszuführen.
- Wählen Sie in der linken Seitenleiste die Option (+) Neue Aufgabe und dann Cluster aus (ggf. im Untermenü Mehr suchen).
- Erstellen Sie auf der Seite Neuer Cluster einen neuen Cluster mit den folgenden Einstellungen:
- Clustername: Cluster des Benutzernamens (der Standardclustername)
- Richtlinie: Unrestricted
- Clustermodus: Einzelknoten
- Zugriffsmodus: Einzelner Benutzer (Ihr Benutzerkonto ist ausgewählt)
- Databricks-Runtimeversion: 13.3 LTS (Spark 3.4.1, Scala 2.12) oder höher
- Photonbeschleunigung verwenden: Ausgewählt
- Knotentyp: Standard_D4ds_v5
- Beenden nach 20 Minuten Inaktivität
- Warten Sie, bis der Cluster erstellt wurde. Es kann ein oder zwei Minuten dauern.
Hinweis: Wenn Ihr Cluster nicht gestartet werden kann, verfügt Ihr Abonnement möglicherweise über ein unzureichendes Kontingent in der Region, in der Ihr Azure Databricks-Arbeitsbereich bereitgestellt wird. Details finden Sie unter Der Grenzwert für CPU-Kerne verhindert die Clustererstellung. In diesem Fall können Sie versuchen, Ihren Arbeitsbereich zu löschen und in einer anderen Region einen neuen zu erstellen.
Verwenden von Spark zum Analysieren von Daten
Wie in vielen Spark-Umgebungen unterstützt Databricks die Verwendung von Notebooks zum Kombinieren von Notizen und interaktiven Codezellen, mit denen Sie Daten untersuchen können.
- Laden Sie die Datei products.csv aus
https://raw.githubusercontent.com/MicrosoftLearning/mslearn-databricks/main/data/products.csvauf Ihren lokalen Computer herunter, und speichern Sie sie unter dem Namen products.csv. - In der Seitenleiste im Menü (+) Neu den Link Daten hinzufügen oder hochladen auswählen.
- Wählen Sie Tabelle erstellen oder bearbeiten aus und laden Sie die Datei products.csv hoch, die Sie auf Ihren Computer heruntergeladen haben.
- Stellen Sie auf der Seite Erstellen oder Ändern einer Tabelle aus dem Dateiupload sicher, dass Ihr Cluster oben rechts auf der Seite ausgewählt ist. Wählen Sie dann den hive_metastore-Katalog und sein Standardschema aus, um eine neue Tabelle mit dem Namen Produkte zu erstellen.
- Wenn die Tabelle mit den Produkten auf der Seite Katalog Explorer erstellt wurde, wählen Sie im Menü der Taste Erstellen die Option „Notebook aus, um ein Notebook zu erstellen.
-
Stellen Sie im Notebook sicher, dass das Notebook mit Ihrem Cluster verbunden ist, und überprüfen Sie dann den Code, der automatisch der ersten Zelle hinzugefügt wurde. Er sollte etwa wie folgt aussehen:
%sql SELECT * FROM `hive_metastore`.`default`.`products`; - Verwenden Sie zum Ausführen die Menüoption ▸ Zelle Ausführen links neben der Zelle und starten Sie das Cluster und fügen Sie es an, wenn Sie dazu aufgefordert werden.
- Warten Sie, bis der vom Code ausgeführte Spark-Auftrag abgeschlossen ist. Der Code ruft Daten aus der Tabelle ab, die basierend auf der hochgeladenen Datei erstellt wurde.
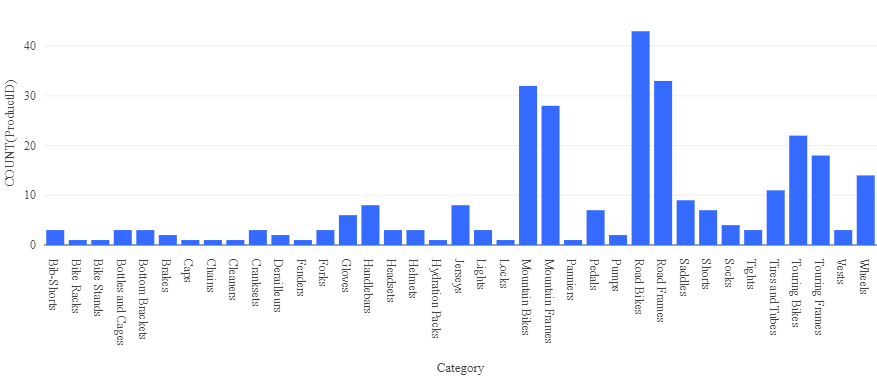
- Wählen Sie oberhalb der Ergebnistabelle + und dann Visualisierung aus, um den Visualisierungs-Editor anzuzeigen, und wenden Sie dann die folgenden Optionen an:
- Visualisierungstyp: Balken
- X-Spalte: Kategorie
- Y-Spalte: Fügen Sie eine neue Spalte hinzu, und wählen Sie ProductID aus. Wenden Sie die Anzahl-Aggregation an.
Speichern Sie die Visualisierung, und beachten Sie, dass sie im Notebook wie folgt angezeigt wird:
Analysieren von Daten mit einem Datenframe
Während die meisten Datenanalysten und -analystinnen mit SQL-Code wie im vorherigen Beispiel vertraut sind, können einige dieser Fachleute und wissenschaftliche Fachkräfte für Daten native Spark-Objekte wie einen Datenrahmen in Programmiersprachen wie PySpark (eine für Spark optimierte Version von Python) verwenden, um effizient mit Daten zu arbeiten.
-
Fügen Sie im Notebook unter der Diagrammausgabe der zuvor ausgeführten Codezelle über das Symbol + Code eine neue Zelle hinzu.
Tipp: Möglicherweise müssen Sie die Maus unter der Ausgabezelle bewegen, damit das Symbol +Code angezeigt wird.
-
Geben Sie den folgenden Code in die neue Zelle ein, und führen Sie ihn aus:
df = spark.sql("SELECT * FROM products") df = df.filter("Category == 'Road Bikes'") display(df) -
Führen Sie die neue Zelle aus, die Produkte in der Kategorie Road Bikes zurückgibt.
Bereinigung
Wählen Sie zunächst im Azure Databricks-Portal auf der Seite Compute Ihren Cluster und dann ■ Beenden aus, um ihn herunterzufahren.
Wenn Sie die Erkundung von Azure Databricks abgeschlossen haben, löschen Sie die erstellten Ressourcen, um unnötige Azure-Kosten zu vermeiden und Kapazität in Ihrem Abonnement freizugeben.