Trainieren eines Modells mit automatisiertem maschinellem Lernen
Automatisiertes maschinelles Lernen ist ein Feature von Azure Databricks, das mehrere Algorithmen und Parameter auf Ihre Daten anwendet, um ein optimales Machine Learning-Modell zu trainieren.
Diese Übung dauert ca. 45 Minuten.
Hinweis: Die Benutzeroberfläche von Azure Databricks wird kontinuierlich verbessert. Die Benutzeroberfläche kann sich seit der Erstellung der Anweisungen in dieser Übung geändert haben.
Vor der Installation
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Databricks-Arbeitsbereichs
Hinweis: Für diese Übung benötigen Sie einen Azure Databricks-Arbeitsbereich im Premium-Tarif in einer Region, in der die Modellbereitstellung unterstützt wird. Details zu regionalen Azure Databricks-Funktionen finden Sie unter Azure Databricks-Regionen. Wenn Sie bereits über einen Azure Databricks-Arbeitsbereich im Premium-Tarif oder alsTestversion in einer geeigneten Region verfügen, können Sie dieses Verfahren überspringen und Ihren vorhandenen Arbeitsbereich verwenden.
Diese Übung enthält ein Skript zum Bereitstellen eines neuen Azure Databricks-Arbeitsbereichs. Das Skript versucht, eine Azure Databricks-Arbeitsbereichsressource im Premium-Tarif in einer Region zu erstellen, in der Ihr Azure-Abonnement über ein ausreichendes Kontingent für die in dieser Übung erforderlichen Computekerne verfügt. Es wird davon ausgegangen, dass Ihr Benutzerkonto über ausreichende Berechtigungen im Abonnement verfügt, um eine Azure Databricks-Arbeitsbereichsressource zu erstellen. Wenn das Skript aufgrund unzureichender Kontingente oder Berechtigungen fehlschlägt, können Sie versuchen, einen Azure Databricks-Arbeitsbereich interaktiv im Azure-Portal zu erstellen.
- Melden Sie sich in einem Webbrowser am Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie die Taste [>_] rechts neben der Suchleiste oben auf der Seite, um eine neue Cloud Shell im Azure-Portal zu erstellen, und wählen Sie eine PowerShell-Umgebung aus. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
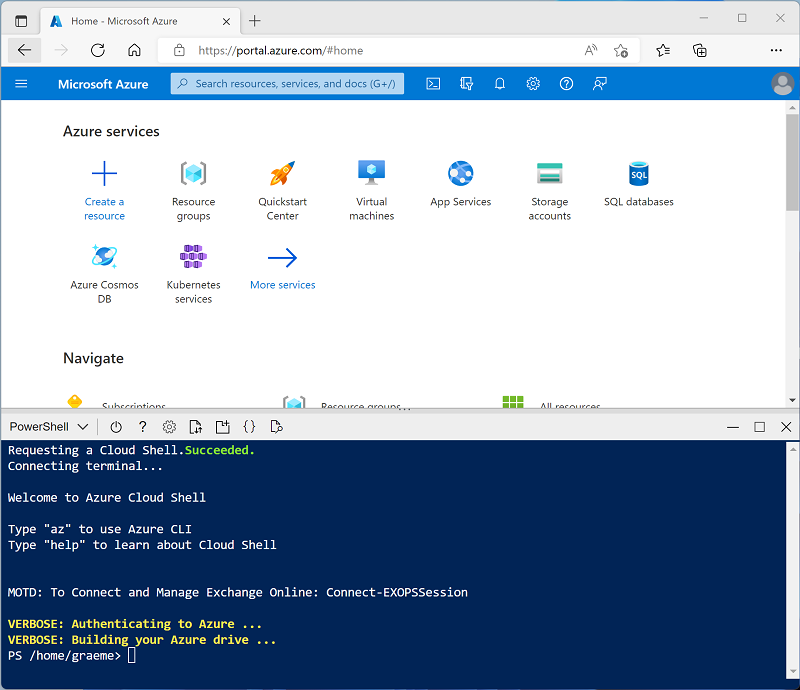
Hinweis: Wenn Sie zuvor eine Cloud-Shell erstellt haben, die eine Bash-Umgebung verwendet, wechseln Sie zu PowerShell.
-
Beachten Sie, dass Sie die Größe der Cloud-Shell ändern können, indem Sie die Trennlinie oben im Bereich ziehen oder die Symbole —, ⤢ und X oben rechts im Bereich verwenden, um den Bereich zu minimieren, zu maximieren und zu schließen. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r mslearn-databricks -f git clone https://github.com/MicrosoftLearning/mslearn-databricks -
Nachdem das Repository geklont wurde, geben Sie den folgenden Befehl ein, um das Skript setup.ps1 auszuführen, das einen Azure Databricks-Arbeitsbereich in einer verfügbaren Region bereitstellt:
./mslearn-databricks/setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 5 Minuten, in einigen Fällen kann es jedoch länger dauern. Während Sie warten, lesen Sie den Artikel Was ist automatisiertes maschinelles Lernen? in der Azure Databricks-Dokumentation.
Erstellen eines Clusters
Azure Databricks ist eine verteilte Verarbeitungsplattform, die Apache Spark-Cluster verwendet, um Daten parallel auf mehreren Knoten zu verarbeiten. Jeder Cluster besteht aus einem Treiberknoten, um die Arbeit zu koordinieren, und Arbeitsknoten zum Ausführen von Verarbeitungsaufgaben. In dieser Übung erstellen Sie einen Einzelknotencluster , um die in der Lab-Umgebung verwendeten Computeressourcen zu minimieren (in denen Ressourcen möglicherweise eingeschränkt werden). In einer Produktionsumgebung erstellen Sie in der Regel einen Cluster mit mehreren Workerknoten.
Tipp: Wenn Sie bereits über einen Cluster mit einer Runtime 13.3 LTS ML oder einer höheren Runtimeversion in Ihrem Azure Databricks-Arbeitsbereich verfügen, können Sie ihn verwenden, um diese Übung abzuschließen, und dieses Verfahren überspringen.
- Navigieren Sie im Azure-Portal zur Ressourcengruppe msl-xxxxxxx, die vom Skript erstellt wurde (oder zur Ressourcengruppe, die Ihren vorhandenen Azure Databricks-Arbeitsbereich enthält).
- Wählen Sie die Ressource Ihres Azure Databricks-Diensts aus (sie trägt den Namen databricks-xxxxxxx, wenn Sie das Setupskript zum Erstellen verwendet haben).
-
Verwenden Sie auf der Seite Übersicht für Ihren Arbeitsbereich die Schaltfläche Arbeitsbereich starten, um Ihren Azure Databricks-Arbeitsbereich auf einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Während Sie das Databricks-Arbeitsbereichsportal verwenden, werden möglicherweise verschiedene Tipps und Benachrichtigungen angezeigt. Schließen Sie diese, und folgen Sie den Anweisungen, um die Aufgaben in dieser Übung auszuführen.
- Wählen Sie zunächst in der Randleiste auf der linken Seite die Aufgabe (+) Neu und dann Cluster aus.
- Erstellen Sie auf der Seite Neuer Cluster einen neuen Cluster mit den folgenden Einstellungen:
- Clustername: Cluster des Benutzernamens (der Standardclustername)
- Richtlinie: Unrestricted
- Clustermodus: Einzelknoten
- Zugriffsmodus: Einzelner Benutzer (Ihr Benutzerkonto ist ausgewählt)
- Databricks-Runtimeversion: Wählen Sie die ML-Edition der neuesten Nicht-Betaversion der Runtime aus (Nicht eine Standard-Runtimeversion), die folgende Kriterien erfüllt:
- Verwendet keine GPU
- Umfasst Scala > 2.11
- Umfasst Spark > 3.4
- Photon-Beschleunigung verwenden: Nicht ausgewählt
- Knotentyp: Standard_D4ds_v5
- Beenden nach 20 Minuten Inaktivität
- Warten Sie, bis der Cluster erstellt wurde. Es kann ein oder zwei Minuten dauern.
Hinweis: Wenn Ihr Cluster nicht gestartet werden kann, verfügt Ihr Abonnement möglicherweise über ein unzureichendes Kontingent in der Region, in der Ihr Azure Databricks-Arbeitsbereich bereitgestellt wird. Details finden Sie unter Der Grenzwert für CPU-Kerne verhindert die Clustererstellung. In diesem Fall können Sie versuchen, Ihren Arbeitsbereich zu löschen und in einer anderen Region einen neuen zu erstellen. Sie können einen Bereich als Parameter für das Setupskript wie folgt angeben:
./mslearn-databricks/setup.ps1 eastus
Hochladen von Trainingsdaten in ein SQL-Warehouse
Um ein Machine Learning-Modell mithilfe von automatisiertem maschinellem Lernen zu trainieren, müssen Sie die Trainingsdaten hochladen. In dieser Übung trainieren Sie ein Modell, um einen Pinguin als eine von drei Arten zu klassifizieren, basierend auf Beobachtungen, einschließlich seines Standorts und seiner Körpermaße. Sie laden Trainingsdaten, die die Artenbezeichnung enthalten, in eine Tabelle in einem Azure Databricks Data Warehouse.
- Wählen Sie im Azure Databricks-Portal für Ihren Arbeitsbereich in der Randleiste unter SQL SQL-Warehouses aus.
- Beachten Sie, dass der Arbeitsbereich bereits ein SQL Warehouse namens Serverless Starter Warehouse enthält.
- Wählen Sie im Menü Aktionen (⁝) für das SQL-Warehouse die Option Bearbeiten aus. Legen Sie dann die Eigenschaft Clustergröße auf 2X-Klein fest, und speichern Sie Ihre Änderungen.
-
Verwenden Sie die Schaltfläche Start, um das SQL-Warehouse zu starten (was ein oder zwei Minuten dauern kann).
Hinweis: Wenn Ihr SQL-Warehouse nicht gestartet werden kann, verfügt Ihr Abonnement möglicherweise über ein unzureichendes Kontingent in der Region, in der Ihr Azure Databricks-Arbeitsbereich bereitgestellt wird. Siehe Erforderliches Azure vCPU-Kontingent für Details. In diesem Fall können Sie versuchen, eine Kontingenterhöhung anzufordern, wie in der Fehlermeldung beschrieben wird, die beim Fehlschlagen des Starts des Warehouse angezeigt wird. Alternativ können Sie versuchen, Ihren Arbeitsbereich zu löschen und in einer anderen Region einen neuen zu erstellen. Sie können einen Bereich als Parameter für das Setupskript wie folgt angeben:
./mslearn-databricks/setup.ps1 eastus - Laden Sie die Datei penguins.csv aus
https://raw.githubusercontent.com/MicrosoftLearning/mslearn-databricks/main/data/penguins.csvauf Ihren lokalen Computer herunter, und speichern Sie sie als penguins.csv. - Wählen Sie im Azure Databricks-Arbeitsbereichsportal in der Seitenleiste (+) Neu und dann Daten hinzufügen oder hochladen. Wählen Sie auf der Seite Daten hinzufügen die Option Tabelle erstellen oder ändern und laden Sie die Datei penguins.csv, die Sie heruntergeladen haben, auf Ihren Computer hoch.
- Wählen Sie auf der Seite Tabelle aus Datei-Upload erstellen oder ändern das Schema Standard aus und legen Sie den Tabellennamen auf Pinguine fest. Wählen Sie anschließend Tabelle erstellen.
- Wenn die Tabelle erstellt wurde, überprüfen Sie die Details.
Erstellen eines Experiments für automatisiertes maschinelles Lernen
Nachdem Sie nun über einige Daten verfügen, können Sie sie mit dem automatisierten maschinellen Lernen verwenden, um ein Modell zu trainieren.
- Wählen Sie in der Randleiste auf der linken Seite Experimente aus.
- Suchen Sie auf der Seite Experimente die Kachel Klassifizierung und wählen Sie Training starten.
- Konfigurieren Sie das AutoML-Experiment mit den folgenden Einstellungen:
- Cluster: Cluster auswählen
- Eingabetrainingsdataset: Navigieren Sie zur Standarddatenbank, und wählen Sie die Tabelle penguins aus
- Vorhersageziel: Art
- Experimentname: Penguin-classification
- Erweiterte Konfiguration:
- Auswertungsmetrik: Genauigkeit
- Trainingsframeworks: lightgbm, sklearn, xgboost
- Timeout: 5
- Spalte „Zeit“ für die Aufteilung in „Training/Validierung/Tests“: Leer lassen
- Positive Bezeichnung: Leer lassen
- Zwischenspeicherort für Daten: MLflow-Artefakt
- Verwenden Sie die Schaltfläche Automatisiertes maschinelles Lernen starten, um das Experiment zu starten. Schließen Sie alle angezeigten Informationsdialogfelder.
- Warten Sie, bis das Experiment abgeschlossen ist. Sie können Details zu den erzeugten Ausführungen auf der Registerkarte Ausführungen einsehen.
- Nach fünf Minuten endet das Experiment. Die Aktualisierung der Ausführungen zeigt die Ausführung oben in der Liste an, die zu dem leistungsstärksten Modell geführt hat (basierend auf der Metrik Genauigkeit, die Sie ausgewählt haben).
Bereitstellen des leistungsstärksten Modells
Nachdem Sie ein Experiment für automatisiertes maschinelles Lernen ausgeführt haben, können Sie das leistungsstärkste Modell untersuchen, das generiert wurde.
- Wählen Sie auf der Experimentseite Penguin-classification die Option **Notebook für bestes Modell anzeigen ** aus, um das Notebook zu öffnen, das zum Trainieren des Modells auf einer neuen Browserregisterkarte verwendet wird.
- Scrollen Sie durch die Zellen im Notebook, und notieren Sie den Code, der zum Trainieren des Modells verwendet wurde.
- Schließen Sie die Browserregisterkarte, die das Notebook enthält, um zur Experimentseite Penguin-classification zurückzukehren.
- Wählen Sie in der Liste der Ausführungen den Namen der ersten Ausführung aus (die das beste Modell erzeugt hat), um sie zu öffnen.
- Beachten Sie im Abschnitt Artefakte, dass das Modell als MLflow-Artefakt gespeichert wurde. Verwenden Sie dann die Schaltfläche Modell registrieren, um das Modell als neues Modell mit dem Namen Penguin-Classifier zu registrieren.
- Wechseln Sie in der Randleiste auf der linken Seite zur Seite Modelle. Wählen Sie dann das Modell Penguin-Classifier aus, das Sie gerade registriert haben.
- Verwenden Sie auf der Seite Penguin-Classifier die Schaltfläche Modell für Rückschlüsse verwenden, um einen neuen Echtzeitendpunkt mit den folgenden Einstellungen zu erstellen:
- Modell: Penguin-Classifier
- Modellversion: 1
- Endpunkt: classify-penguin
- Computegröße: Klein
Der Bereitstellungsendpunkt wird in einem neuen Cluster gehostet, dessen Erstellung einige Minuten dauern kann.
-
Wenn der Endpunkt erstellt worden ist, verwenden Sie die Schaltfläche Abfrageendpunkt oben rechts, um eine Schnittstelle zu öffnen, über die Sie den Endpunkt testen können. Geben Sie dann in der Testschnittstelle auf der Registerkarte Browser die folgende JSON-Anforderung ein, und verwenden Sie die Schaltfläche Anforderung senden, um den Endpunkt aufzurufen und eine Vorhersage zu generieren.
{ "dataframe_records": [ { "Island": "Biscoe", "CulmenLength": 48.7, "CulmenDepth": 14.1, "FlipperLength": 210, "BodyMass": 4450 } ] } - Experimentieren Sie mit einigen unterschiedlichen Werten für die Pinguinmerkmale, und beobachten Sie die zurückgegebenen Ergebnisse. Schließen Sie dann die Testschnittstelle.
Löschen des Endpunkts
Wenn der Endpunkt nicht mehr benötigt wird, sollten Sie ihn löschen, um unnötige Kosten zu vermeiden.
Wählen Sie auf der Endpunktseite classify-penguin im Menü ⁝ Menü die Option Löschen aus.
Bereinigung
Wählen Sie zunächst im Azure Databricks-Portal auf der Seite Compute Ihren Cluster und dann ■ Beenden aus, um ihn herunterzufahren.
Wenn Sie die Erkundung von Azure Databricks abgeschlossen haben, löschen Sie die erstellten Ressourcen, um unnötige Azure-Kosten zu vermeiden und Kapazität in Ihrem Abonnement freizugeben.
Weitere Informationen: Weitere Informationen finden Sie unter So funktioniert automatisiertes maschinelles Lernen in Databricks in der Azure Databricks-Dokumentation.