Implementieren von LLMOps mit Azure Databricks
Azure Databricks bietet eine einheitliche Plattform, die den KI-Lebenszyklus von der Datenvorbereitung über die Modellbereitstellung bis hin zur Überwachung optimiert und so die Leistung und Effizienz von Machine Learning-Systemen steigert. Es unterstützt die Entwicklung von generativen KI-Anwendungen und nutzt Features wie Unity Catalog für Datengovernance, MLflow für die Modellverfolgung und Mosaik AI Model Serving für die Bereitstellung von LLMs.
Dieses Lab dauert ungefähr 20 Minuten.
Hinweis: Die Benutzeroberfläche von Azure Databricks wird kontinuierlich verbessert. Die Benutzeroberfläche kann sich seit der Erstellung der Anweisungen in dieser Übung geändert haben.
Vor der Installation
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen einer Azure OpenAI-Ressource
Wenn Sie noch keine Azure OpenAI-Ressource haben, stellen Sie eine in Ihrem Azure-Abonnement bereit.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. - Erstellen Sie eine Azure OpenAI-Ressource mit den folgenden Einstellungen:
- Abonnement: Wählen Sie ein Azure-Abonnement aus, das für den Zugriff auf den Azure OpenAI-Dienst freigegeben wurde.
- Ressourcengruppe: Wählen Sie eine Ressourcengruppe aus, oder erstellen Sie eine.
- Region: Treffen Sie eine zufällige Auswahl aus einer der folgenden Regionen*
- USA (Ost) 2
- USA Nord Mitte
- Schweden, Mitte
- Schweiz, Westen
- Name: Wählen Sie einen Namen Ihrer Wahl aus.
- Tarif: Standard S0.
* Azure OpenAI-Ressourcen werden durch regionale Kontingente eingeschränkt. Die aufgeführten Regionen enthalten das Standardkontingent für die in dieser Übung verwendeten Modelltypen. Durch die zufällige Auswahl einer Region wird das Risiko reduziert, dass eine einzelne Region ihr Kontingentlimit in Szenarien erreicht, in denen Sie ein Abonnement für andere Benutzer freigeben. Wenn später in der Übung ein Kontingentlimit erreicht wird, besteht eventuell die Möglichkeit, eine andere Ressource in einer anderen Region zu erstellen.
-
Warten Sie, bis die Bereitstellung abgeschlossen ist. Wechseln Sie dann zur bereitgestellten Azure OpenAI-Ressource im Azure-Portal.
-
Wählen Sie im linken Fensterbereich unter Ressourcenverwaltung die Option Tasten und Endpunkt.
-
Kopieren Sie den Endpunkt und einen der verfügbaren Schlüssel, da Sie ihn später in dieser Übung verwenden werden.
Bereitstellen des erforderlichen Modells
Azure bietet ein webbasiertes Portal mit dem Namen Azure AI Foundry, das Sie zur Bereitstellung, Verwaltung und Untersuchung von Modellen verwenden können. Sie beginnen Ihre Erkundung von Azure OpenAI, indem Sie Azure AI Foundry verwenden, um ein Modell bereitzustellen.
Hinweis: Während Sie Azure AI Foundry verwenden, werden möglicherweise Meldungsfelder mit Vorschlägen für auszuführende Aufgaben angezeigt. Sie können diese schließen und die Schritte in dieser Übung ausführen.
-
Scrollen Sie im Azure-Portal auf der Seite Übersicht für Ihre Azure OpenAI-Ressource nach unten zum Abschnitt Erste Schritte, und wählen Sie die Schaltfläche aus, um zu Azure AI Foundry zu gelangen.
-
Wählen Sie in Azure AI Foundry im linken Bereich die Seite Bereitstellungen aus, und sehen Sie sich Ihre vorhandenen Modellbereitstellungen an. Falls noch nicht vorhanden, erstellen Sie eine neue Bereitstellung des gpt-4o-Modells mit den folgenden Einstellungen:
- Bereitstellungsname: gpt-4o
- Bereitstellungstyp: Standard
- Modellversion: Standardversion verwenden
- Ratenbegrenzung für Token pro Minute: 10 TSD.*
- Inhaltsfilter: Standard
- Dynamische Quote aktivieren: Deaktiviert
* Ein Ratenlimit von 10.000 Token pro Minute ist mehr als ausreichend, um diese Übung auszuführen und gleichzeitig Kapazität für andere Personen zu schaffen, die das gleiche Abonnement nutzen.
Bereitstellen eines Azure Databricks-Arbeitsbereichs
Tipp: Wenn Sie bereits über einen Azure Databricks-Arbeitsbereich verfügen, können Sie dieses Verfahren überspringen und Ihren vorhandenen Arbeitsbereich verwenden.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. - Erstellen Sie eine Azure Databricks-Ressource mit den folgenden Einstellungen:
- Abonnement: Wählen Sie das gleiche Azure-Abonnement aus, das Sie zum Erstellen Ihrer Azure OpenAI-Ressource verwendet haben
- Ressourcengruppe: Die gleiche Ressourcengruppe, in der Sie Ihre Azure OpenAI-Ressource erstellt haben
- Region: Die gleiche Region, in der Sie Ihre Azure OpenAI-Ressource erstellt haben
- Name: Wählen Sie einen Namen Ihrer Wahl aus.
- Preisstufe: Premium oder Testversion
- Wählen Sie Überprüfen + Erstellen und warten Sie, bis die Bereitstellung abgeschlossen ist. Wechseln Sie dann zur Ressource, und starten Sie den Arbeitsbereich.
Erstellen eines Clusters
Azure Databricks ist eine verteilte Verarbeitungsplattform, die Apache Spark-Cluster verwendet, um Daten parallel auf mehreren Knoten zu verarbeiten. Jeder Cluster besteht aus einem Treiberknoten, um die Arbeit zu koordinieren, und Arbeitsknoten zum Ausführen von Verarbeitungsaufgaben. In dieser Übung erstellen Sie einen Einzelknotencluster , um die in der Lab-Umgebung verwendeten Computeressourcen zu minimieren (in denen Ressourcen möglicherweise eingeschränkt werden). In einer Produktionsumgebung erstellen Sie in der Regel einen Cluster mit mehreren Workerknoten.
Tipp: Wenn Sie bereits über einen Cluster mit der Runtimeversion 16.4 LTS ML oder höher in Ihrem Azure Databricks-Arbeitsbereich verfügen, können Sie ihn verwenden, um diese Übung abzuschließen, und diesen Prozess überspringen.
- Navigieren Sie im Azure-Portal zu der Ressourcengruppe, in der der Azure Databricks-Arbeitsbereich erstellt wurde.
- Wählen Sie Ihre Azure Databricks Service-Ressource aus.
- Verwenden Sie auf der Seite Übersicht für Ihren Arbeitsbereich die Schaltfläche Arbeitsbereich starten, um Ihren Azure Databricks-Arbeitsbereich auf einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Während Sie das Databricks-Arbeitsbereichsportal verwenden, werden möglicherweise verschiedene Tipps und Benachrichtigungen angezeigt. Schließen Sie diese, und folgen Sie den Anweisungen, um die Aufgaben in dieser Übung auszuführen.
- Wählen Sie zunächst in der Randleiste auf der linken Seite die Aufgabe (+) Neu und dann Cluster aus.
- Erstellen Sie auf der Seite Neuer Cluster einen neuen Cluster mit den folgenden Einstellungen:
- Clustername: Cluster des Benutzernamens (der Standardclustername)
- Richtlinie: Unrestricted
- Maschinelles Lernen: Aktiviert
- Databricks Runtime: 16.4 LTS
- Photon-Beschleunigung verwenden: Nicht ausgewählt
- Workertyp: Standard_D4ds_v5
- Einzelner Knoten: Aktiviert
- Warten Sie, bis der Cluster erstellt wurde. Es kann ein oder zwei Minuten dauern.
Hinweis: Wenn Ihr Cluster nicht gestartet werden kann, verfügt Ihr Abonnement möglicherweise über ein unzureichendes Kontingent in der Region, in der Ihr Azure Databricks-Arbeitsbereich bereitgestellt wird. Details finden Sie unter Der Grenzwert für CPU-Kerne verhindert die Clustererstellung. In diesem Fall können Sie versuchen, Ihren Arbeitsbereich zu löschen und in einer anderen Region einen neuen zu erstellen.
Protokollieren des LLM mithilfe von MLflow
Mit den LLM-Tracking-Funktionen von MLflow können Sie Parameter, Metriken, Vorhersagen und Artifacts protokollieren. Zu den Parametern gehören Schlüsselwertpaare, die die Eingabekonfigurationen detailliert beschreiben, während Metriken quantitative Leistungsmessungen liefern. Die Vorhersagen umfassen sowohl die Eingabeaufforderungen als auch die Antworten des Modells, die als Artifacts gespeichert werden, um sie leicht abrufen zu können. Diese strukturierte Protokollierung hilft bei der Aufrechterhaltung eines detaillierten Datensatzes jeder Interaktion, wodurch eine bessere Analyse und Optimierung von LLMs erleichtert wird.
-
Führen Sie in einer neuen Zelle den folgenden Code mit den Zugriffsinformationen aus, die Sie am Anfang dieser Übung kopiert haben, um beständige Umgebungsvariablen für die Authentifizierung bei Verwendung von Azure OpenAI-Ressourcen zuzuweisen:
import os os.environ["AZURE_OPENAI_API_KEY"] = "your_openai_api_key" os.environ["AZURE_OPENAI_ENDPOINT"] = "your_openai_endpoint" os.environ["AZURE_OPENAI_API_VERSION"] = "2024-05-01-preview" -
Führen Sie in einer neuen Zelle den folgenden Code aus, um Ihren Azure OpenAI-Client zu initialisieren:
import os from openai import AzureOpenAI client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"), api_key = os.getenv("AZURE_OPENAI_API_KEY"), api_version = os.getenv("AZURE_OPENAI_API_VERSION") ) -
Führen Sie in einer neuen Zelle den folgenden Code aus, um MLflow-Tracking zu initialisieren und das Modell zu protokollieren:
import mlflow from openai import AzureOpenAI system_prompt = "Assistant is a large language model trained by OpenAI." mlflow.openai.autolog() with mlflow.start_run(): response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": "Tell me a joke about animals."}, ], ) print(response.choices[0].message.content) mlflow.log_param("completion_tokens", response.usage.completion_tokens) mlflow.end_run()
In der obigen Zelle wird ein Experiment in Ihrem Arbeitsbereich gestartet und die Ablaufverfolgungen jeder Iteration des Chatabschlusses registriert, wobei die Eingaben, Ausgaben und Metadaten jeder Ausführung nachverfolgt werden.
Überwachen des Modells
Nach dem Ausführen der letzten Zelle wird die MLflow-Ablaufverfolgungsbenutzeroberfläche automatisch zusammen mit der Ausgabe der Zelle angezeigt. Sie können dies auch sehen, indem Sie in der linken Randleiste Experimente auswählen und dann die Experimentausführung Ihres Notebooks öffnen:
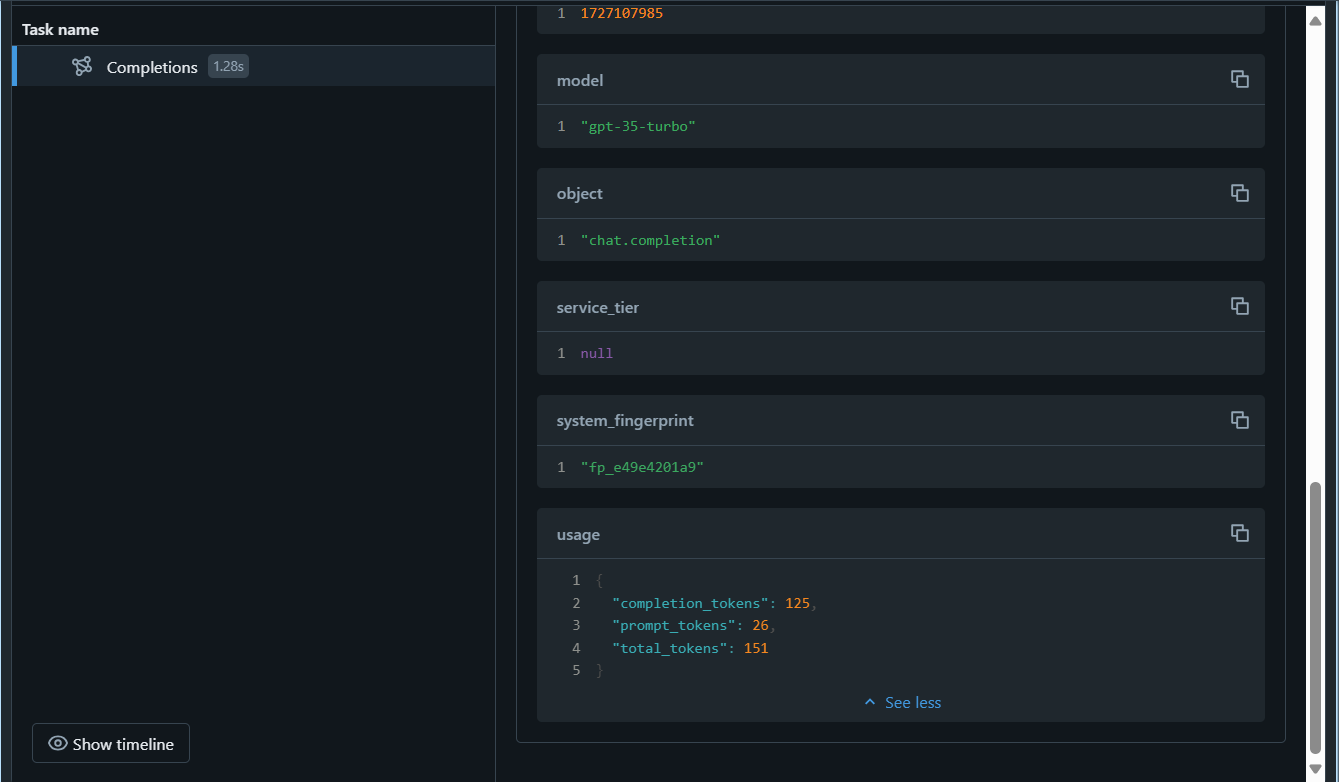
Der Befehl mlflow.openai.autolog() protokolliert standardmäßig die Spuren jedes Durchlaufs, aber Sie können mit mlflow.log_param() auch zusätzliche Parameter protokollieren, die später zur Überwachung des Modells verwendet werden können. Nachdem Sie mit der Überwachung des Modells begonnen haben, können Sie die Ablaufverfolgungen aus verschiedenen Läufen vergleichen, um Datenabweichungen zu erkennen. Suchen Sie im Laufe der Zeit nach signifikanten Änderungen in den Eingabedatenverteilungen, Modellvorhersagen oder Leistungsmetriken. Sie können auch statistische Tests oder Visualisierungstools verwenden, um diese Analyse zu unterstützen.
Bereinigen
Wenn Sie mit Ihrer Azure OpenAI-Ressource fertig sind, denken Sie daran, die Bereitstellung oder die gesamte Ressource im Azure-Portal auf https://portal.azure.com zu löschen.
Wählen Sie zunächst im Azure Databricks-Portal auf der Seite Compute Ihren Cluster und dann ■ Beenden aus, um ihn herunterzufahren.
Wenn Sie die Erkundung von Azure Databricks abgeschlossen haben, löschen Sie die erstellten Ressourcen, um unnötige Azure-Kosten zu vermeiden und Kapazität in Ihrem Abonnement freizugeben.