使用 Azure AI 自定义视觉检测图像中的对象
在此练习中,你将使用自定义视觉服务来训练对象检测模型,该模型可检测并找到图像中的三种水果(苹果、香蕉和橙子)。
克隆本课程的存储库
如果已将mslearn-ai-vision代码存储库克隆到了要完成本实验室的环境,请在 Visual Studio Code 中将其打开;否则,请按照以下步骤立即将其克隆。
- 启动 Visual Studio Code。
- 打开面板 (SHIFT+CTRL+P) 并运行“Git:克隆”命令,以将
https://github.com/MicrosoftLearning/mslearn-ai-vision存储库克隆到本地文件夹(任意文件夹均可)。 - 克隆存储库后,在 Visual Studio Code 中打开文件夹。
-
等待其他文件安装完毕,以支持存储库中的 C# 代码项目。
注意:如果系统提示你添加生成和调试所需的资产,请选择以后再说。
创建自定义视觉资源
如果 Azure 订阅中已有用于训练和预测的“自定义视觉”资源,则可以在此练习中使用它们或某个现有的多服务帐户。 如果没有,请按照以下说明来创建自定义视觉资源。
备注:如果使用多服务帐户,则训练和预测的密钥和终结点将相同。
- 在新的浏览器标签页中,打开 Azure 门户 (
https://portal.azure.com),然后使用与 Azure 订阅关联的 Microsoft 帐户登录。 - 选择 +创建资源按钮,搜索自定义视觉,并使用以下设置创建一个自定义视觉资源:
- 创建选项:共同点
- 订阅:Azure 订阅
- 资源组:选择或创建一个资源组(如果使用受限制的订阅,你可能无权创建新的资源组 - 请使用提供的资源组)
- 区域:选择任何可用区域
- 名称:输入唯一名称
- 训练定价层:F0
- 预测定价层:F0
注意:如果在你的订阅中已有 F0 自定义视觉服务,此处请选择S0。
- 等待资源创建完成,然后查看部署详细信息,并注意两个自定义视觉资源是否已预配。一个资源用于训练,另一个用于预测(通过 -Prediction 后缀可判断出来)。 可以导航到你在其中创建了这些资源的资源组,然后查看这些资源。
重要说明:每个资源都有自己的终结点和密钥,用于管理来自代码的访问。 若要训练图像分类模型,代码必须使用训练资源(及其终结点和密钥);若要使用经过训练的模型来预测图像类别,代码必须使用预测资源(及其终结点和密钥)。
创建自定义视觉项目
若要训练对象检测模型,需要基于训练资源创建自定义视觉项目。 为此,你将使用自定义视觉门户。
- 在新的浏览器选项卡中,打开自定义视觉门户 (
https://customvision.ai),然后使用与 Azure 订阅关联的 Microsoft 帐户登录。 - 创建一个具有以下设置的新项目:
- 名称:检测水果
- 说明:针对水果的对象检测。
- 资源:先前创建的自定义视觉资源
- 项目类型:对象检测
- 域:常规
- 等待项目创建并在浏览器中打开。
添加图像并进行标记
若要训练对象检测模型,需要上传包含希望模型识别的类的图像,并标记这些图像以指示每个对象实例的边界框。
- 在 Visual Studio Code 中,查看 03-object-detection/training-images 文件夹(你在其中克隆了存储库)中的训练图像。 此文件夹包含水果图像。
- 在自定义视觉门户中的物体检测项目中,选择添加图像并上传提取的文件夹中的所有图像。
- 上传图像后,选择第一个图像将其打开。
-
将鼠标悬停在图像中的任意对象上,直到自动检测到的区域如下图所示。 然后选择对象,并根据需要调整区域大小以将其环绕。
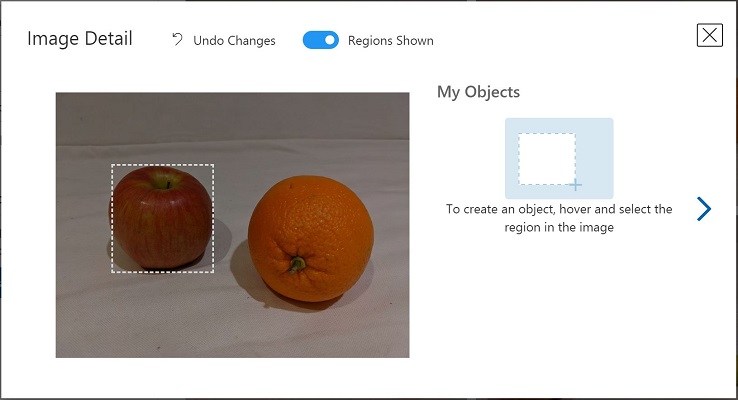
或者,只需在对象周围拖动以创建区域。
-
当区域环绕对象时,使用相应的对象类型(苹果、香蕉或橘子)添加新标记,如下所示:
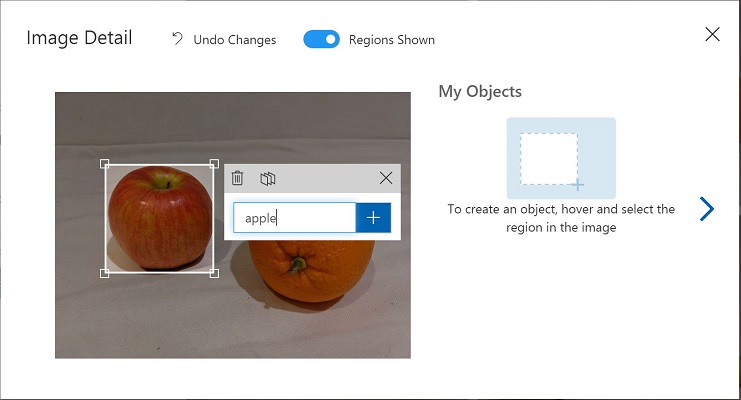
-
选择并标记图像中的各个对象,从而根据需要调整区域大小并添加新标记。
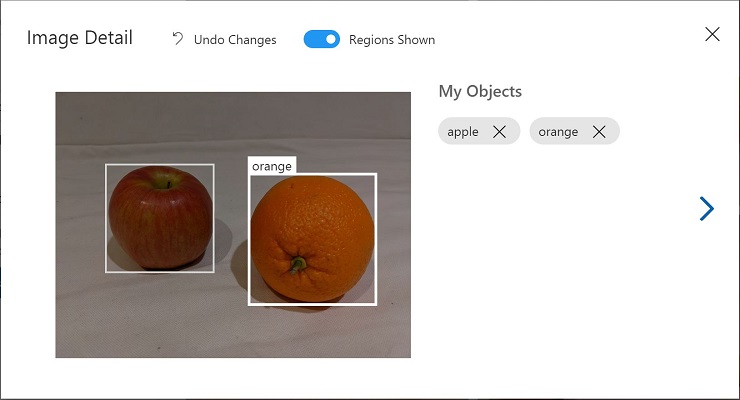
-
使用右侧的 > 链接转到下一个图像,并标记其对象。 然后,继续处理整个图像集合,标记每个苹果、香蕉和橘子。
- 标记完最后一个图像后,请关闭“图像详细信息”编辑器。 在“训练图像”页的“标记”下,选择“已标记”以查看所有标记的图像:
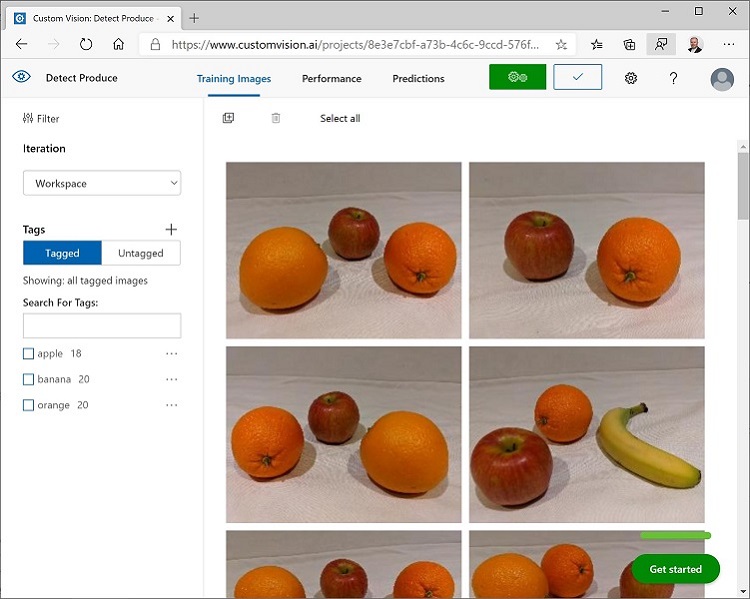
使用训练 API 上传图像
可以使用“自定义视觉”门户中的 UI 对图像进行标记,但许多 AI 开发团队会使用其他工具来生成包含有关图像中的标记和对象区域信息的文件。 在此类情况下,可以使用自定义视觉训练 API 将带标记的图像上传到项目。
注意:在此练习中,可以选择在 C# 或 Python SDK 中使用 API。 在下面的步骤中,请执行适用于你的语言首选项的操作。
- 单击自定义视觉门户中训练图像页面右上方的设置(⚙) 图标,查看项目设置。
- 在常规(左侧)下,注意唯一标识该项目的项目 ID。
- 在右侧的资源下,可看到显示了密钥和终结点。 这些是训练资源的详细信息(还可通过在 Azure 门户中查看资源来获取这些信息)。
- 在 Visual Studio Code 中的 03-object-detection 文件夹下,根据你的语言首选项,展开 C-Sharp 或 Python 文件夹。
- 右键单击 train-detector 文件夹,并打开集成终端。 然后通过运行适用于你的语言首选项的命令,安装自定义视觉训练包:
C#
dotnet add package Microsoft.Azure.CognitiveServices.Vision.CustomVision.Training --version 2.0.0
Python
pip install azure-cognitiveservices-vision-customvision==3.1.1
- 查看 train-detector 文件夹的内容,并注意其中包含一个配置设置文件:
- C# :appsettings.json
- Python:.env
打开配置文件并更新其包含的配置值,以反映自定义视觉训练资源的终结点和密钥,以及先前创建的物体检测项目的项目 ID。 保存更改。
-
在 train-detector 文件夹中,打开 tagd-images.json 并检查其包含的 JSON。 JSON 定义了一个图像列表,每个图像包含一个或多个带标记的区域。 每个带标记的区域均包括标记名称、顶部和左侧坐标,以及含带标记对象的边界框的宽度和高度维度。
注意:此文件中的坐标和维度表示在图像上的相对位置。 例如,高度值 0.7 表示框的高度是图像高度的 70%。 某些标记工具会生成其他格式的文件,其中坐标和维度值体现为像素、英寸或其他度量单位。
-
请注意,train-detector 文件夹中包含子文件夹,其中存储了 JSON 文件中引用的图像文件。
-
请注意,train-detector 文件夹中包含客户端应用程序的代码文件:
- C# :Program.cs
- Python:train-detector.py
打开代码文件并查看其中包含的代码,并注意以下详细信息:
- 已导入你安装的包中的命名空间
- Main 函数检索配置设置,并使用密钥和终结点来创建经过身份验证的 CustomVisionTrainingClient,然后将其与项目 ID 结合使用以创建对项目的项目引用。
- Upload_Images 函数从 JSON 文件提取带标记的区域信息,并按照该信息创建一批具有区域的图像,然后将其上传到项目。
-
返回 train-detector 文件夹的集成终端,然后输入以下命令以运行程序:
C#
dotnet runPython
python train-detector.py - 等待程序结束。 然后返回到浏览器,并在自定义视觉门户中查看项目的训练图像页面(如有必要,请刷新浏览器)。
- 验证某些带标记的新图像是否已添加到项目中。
训练和测试模型
现在你已标记项目中的图像,即可训练模型。 大家
- 在自定义视觉项目中,单击训练以使用已标记的图像训练对象检测模型。 选择快速训练选项。
- 等待训练完成(可能需要 10 分钟左右),然后检查精度、召回率和 mAP 性能指标 - 这些指标用于衡量分类模型的预测准确度,且应该都很高。
- 在页面的右上角,单击快速测试,然后在图像 URL框中输入
https://aka.ms/apple-orange并查看已生成的预测。 然后关闭快速测试窗口。
发布对象检测模型
现在即可发布经过训练的模型,以便在客户端应用程序中使用。
- 在自定义视觉门户的性能页面上,单击 🗸 发布以使用以下设置发布经过训练的模型 :
- 模型名称:fruit-detector
- 预测资源:先前创建的以Prediction结尾的预测资源(不是训练资源)。
- 在项目设置页面的左上角,单击项目库(👁) 图标以返回到自定义视觉门户主页,此时其中列出了你的项目。
- 在自定义视觉门户主页的右上角,单击设置(⚙) 图标以查看自定义视觉服务的设置。 然后,在资源下查找以-Prediction结尾的预测资源(不是训练资源),以确定其密钥和终结点值(也可以通过在 Azure 门户中查看资源来获取这些信息)。
使用客户端应用程序中的图像分类器
现在,你已经发布了图像分类模型,接下来,可在客户端应用程序中使用。 同样,可以选择使用 C# 或 Python。
- 在 Visual Studio Code 中,导航到 03-object-detection 文件夹,然后在首选语言(C-Sharp 或 Python)的文件夹中,展开 test-detector 文件夹。
- 右键单击 test-detector 文件夹,并打开集成终端。 然后,输入以下 SDK 特定的命令,安装自定义视觉预测包:
C#
dotnet add package Microsoft.Azure.CognitiveServices.Vision.CustomVision.Prediction --version 2.0.0
Python
pip install azure-cognitiveservices-vision-customvision==3.1.1
注意:Python SDK 包包括训练和预测包,并且可能已安装完毕。
- 打开客户端应用程序的配置文件(对于 C#,是 appsettings.json;对于 Python,则是 .env),并更新其包含的配置值,以反映自定义视觉预测资源的终结点和密钥、物体检测项目的项目 ID,以及发布的模型的名称(应为 fruit-detector)。 保存更改。
- 打开客户端应用程序的代码文件(对于 C#,是 Program.cs;对于 Python,则是 test-detector.py),然后查看其包含的代码,并注意以下详细信息 :
- 已导入你安装的包中的命名空间
- Main 函数检索配置设置,并使用密钥和终结点创建经过身份验证的 CustomVisionPredictionClient。
- 预测客户端对象用于获取 produce.jpg 图像的对象检测预测,并指定请求中的项目 ID 和模型名称。 然后,预测的带标记的区域会绘制在图像上,并且结果将另存为 output.jpg。
- 返回到 test-detector 文件夹的集成终端,然后输入以下命令以运行程序:
C#
dotnet run
Python
python test-detector.py
- 程序完成后,查看生成的 output.jpg 文件以查看图像中检测到的对象。
详细信息
若要详细了解自定义视觉服务中的对象检测,请参阅自定义视觉文档。