Vision Studio でテキストを読み取る
この演習では、Azure AI サービスを使用して、Azure AI Vision の光学式文字認識機能を確認します。 Vision Studio を使用して、コードを記述することなく、画像からテキストを抽出する実験を行います。
画像中に埋め込まれているテキストの検出と解釈は、コンピューター ビジョン共通の課題です。 これは、光学式文字認識 (OCR) と呼ばれます。 この演習では、Azure AI Vision サービスを含む Azure AI サービス リソースを使用します。 次に、Vision Studio を使用して、さまざまな種類の画像で OCR を試します。
“Azure AI サービス” リソースを作成する**
Azure AI Vision の OCR 機能は、Azure AI サービスのマルチサービス リソースで使用できます。 まだ作成していない場合は、Azure サブスクリプションで Azure AI サービス リソースを作成します。
-
別のブラウザー タブで Azure portal (https://portal.azure.com) を開き、ご使用の Azure サブスクリプションに関連付けられている Microsoft アカウントを使用してサインインします。
- [+リソースの作成] ボタンをクリックし、「Azure AI サービス」を検索してください。** [Azure AI サービスの作成] プランを選択してください。 Azure AI サービス リソースを作成するためのページに移動します。 これを以下の設定で構成します。
- [サブスクリプション]: お使いの Azure サブスクリプション。
- [リソース グループ]: 一意の名前のリソース グループを選択するか、作成します。
- [リージョン]: “地理的に最も近いリージョンを選びます。** 米国東部の場合は、[米国東部 2] を使用します”。
- [名前]: 一意の名前を入力します。
- 価格レベル: Standard S0。
- [このボックスをオンにすることにより、以下のすべてのご契約条件を読み、同意したものとみなされます]:オン。
- [確認 + 作成]、[作成] の順に選択し、デプロイが完了するまで待ちます。
Azure AI サービス リソースを Vision Studio に接続する
次に、上記でプロビジョニングした Azure AI サービス リソースを Vision Studio に接続します。
-
別のブラウザー タブで、Vision Studio (https://portal.vision.cognitive.azure.com) にアクセスします。
-
ご使用のアカウントでサインインし、Azure AI サービス リソースを作成したのと同じディレクトリを使用していることを確認します。
-
Vision Studio のホーム ページで、[Vision の利用を始める] 見出しの下にある [すべてのリソースを表示] を選択します。
![[すべてのリソースを表示] リンクが、Vision Studio の [Vision の利用を始める] の下で強調表示されています。](/mslearn-ai-fundamentals.ja-jp/Instructions/Labs/media/analyze-images-vision/vision-resources.png)
-
[Select a resource to work with](操作するリソースの選択) ページで、上記で作成した一覧内のリソース上にマウス カーソルを置き、リソース名の左側にあるチェック ボックスをオンにしてから、[Select as default resource](既定のリソースとして選択) を選択します。
注:リソースが一覧にない場合は、ページを [更新] することが必要な場合があります。
 ダイアログが表示され、cog-ms-learn-vision-SUFFIX Cognitive Services リソースが強調表示されてオンになっています。 [Select as default resource](既定のリソースとして選択) ボタンが強調表示されています。](/mslearn-ai-fundamentals.ja-jp/Instructions/Labs/media/analyze-images-vision/default-resource.png)
-
画面の右上にある [x] を選択して、設定ページを閉じます。
Vision Studio で画像からテキストを抽出する
-
Web ブラウザーで、Vision Studio (https://portal.vision.cognitive.azure.com) に移動します。
-
[Vision の使用を始める] ランディング ページで、[光学式文字認識] を、次に [画像からテキストを抽出する] タイルを選択します。
-
[Try It Out](試してみる) 小見出しで、リソース利用ポリシーを読んでチェック ボックスをオンにすることで承諾します。
-
https://aka.ms/mslearn-ocr-images を選択して ocr-images.zip をダウンロードします。 次に、このフォルダーを開きます。
-
ポータルで、[ファイルを参照する] を選択し、ocr-images.zip をダウンロードしたコンピューターで、そのフォルダーに移動します。 [advert.jpg] を選択し、[開く] を選択します。
- ここで、返された内容を確認します。
- [Detected attributes](検出された属性) には、画像中に見つかったテキストが領域、行、単語の階層構造で整理されています。
- 画像では、次に示すように、テキストの場所は境界ボックスによって示されます。

-
ここで、別の画像を試してみましょう。 [ファイルを参照する] を選び、GitHub のファイルを保存したフォルダーに移動します。 letter.jpg を選択します。
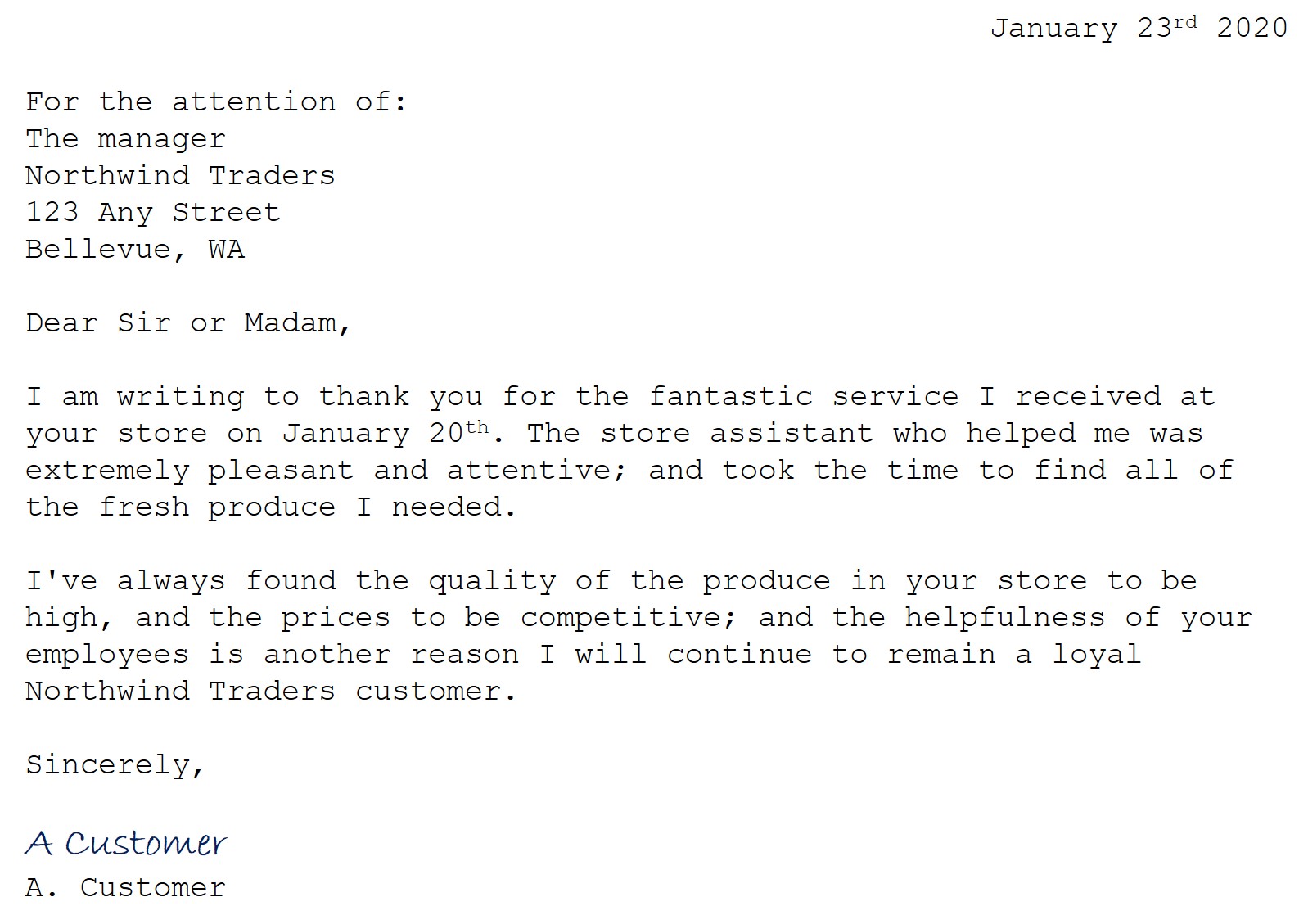
- 2 つめの画像の結果を確認します。 テキストと、テキストの境界ボックスが返されるはずです。 時間がある場合は、note.jpg と receipt.jpg を試してください。
クリーンアップ
これ以上の演習を行わない場合は、不要になったリソースを削除します。 これにより、不要なコストが発生することを防ぎます。
- Azure portal (https://portal.azure.com) を開き、作成したリソースを含むリソース グループを選択します。
- リソースを選択し、[削除] を、次に [はい] を選択して確定します。 これでリソースが削除されます。
詳細情報
このサービスでできることの詳細については、光学式文字認識に関する Azure AI Vision のドキュメントを参照してください。