Esplorare Machine Learning automatizzato in Azure Machine Learning
In questo esercizio si userà la funzionalità di Machine Learning automatizzata in Azure Machine Learning per eseguire il training e valutare un modello di Machine Learning. Si distribuirà e testerà quindi il modello sottoposto a training.
Il completamento di questo esercizio richiederà circa 30 minuti.
Creare un’area di lavoro di Azure Machine Learning
Per usare Azure Machine Learning, è necessario effettuare il provisioning di un’area di lavoro Azure Machine Learning nella sottoscrizione di Azure. Sarà quindi possibile usare studio di Azure Machine Learning per usare le risorse nell’area di lavoro.
Suggerimento:: se si dispone già di un’area di lavoro di Azure Machine Learning, è possibile usarla e passare all’attività successiva.
-
Accedere al portale di Azure all’indirizzo
https://portal.azure.comusando le proprie credenziali Microsoft. - Selezionare + Crea una risorsa, cercare Machine Learning e creare una nuova risorsa Azure Machine Learning con le impostazioni seguenti:
- Sottoscrizione: la sottoscrizione di Azure usata.
- Gruppo di risorse: creare o selezionare un gruppo di risorse.
- Nome: immettere un nome univoco per l’area di lavoro.
- Area: selezionare l’area geografica più vicina.
- Account di archiviazione: prendere nota del nuovo account di archiviazione predefinito che verrà creato per l’area di lavoro.
- Insieme di credenziali delle chiavi: prendere nota del nuovo insieme di credenziali delle chiavi predefinito che verrà creato per l’area di lavoro.
- Application Insights: prendere nota della nuova risorsa Application Insights predefinita che verrà creata per l’area di lavoro.
- Registro contenitori: nessuno (ne verrà creato uno automaticamente la prima volta che si distribuisce un modello in un contenitore).
-
Selezionare Rivedi e crea e quindi Crea. Attendere che l’area di lavoro venga creata (l’operazione può richiedere alcuni minuti) e quindi passare alla risorsa distribuita.
-
Selezionare Avvia studio (in alternativa, aprire una nuova scheda nel browser e passare a https://ml.azure.com) e accedere allo studio di Azure Machine Learning usando il proprio account Microsoft. Chiudere eventuali messaggi visualizzati.
- Nello studio di Azure Machine Learning verrà visualizzata l’area di lavoro appena creata. In caso contrario, selezionare All workspaces (Tutte le aree di lavoro) nel menu a sinistra e quindi selezionare l’area di lavoro appena creata.
Usare Machine Learning automatizzato per eseguire il training di un modello
Machine Learning automatizzato consente di provare più algoritmi e parametri per eseguire il training di più modelli e identificare quello migliore per i dati. In questo esercizio si userà un set di dati contenente i dettagli cronologici del noleggio di biciclette per eseguire il training di un modello che stima il numero di noleggi di biciclette che dovrebbe essere previsto per un determinato giorno, in base alle caratteristiche stagionali e meteorologiche.
Citazione: I dati usati in questo esercizio sono derivati da Capital bikeshare e vengono usati in conformità con il contratto di licenza dei dati pubblicati.
-
Nello studio di Azure Machine Learning visualizzare la pagina ML automatizzato (disponibile in Creazione).
-
Creare un nuovo processo di Machine Learning automatizzato con le impostazioni seguenti, usando Avanti come necessario per avanzare tramite l’interfaccia utente:
Impostazioni di base:
- Nome processo:
mslearn-bike-automl - Nome nuovo esperimento:
mslearn-bike-rental - Descrizione: Machine Learning automatizzato per la previsione del noleggio di biciclette
- Tag: nessuno
Tipo di attività e dati:
- Selezionare il tipo di attività: regressione
- Selezionare il set di dati: creare un nuovo set di dati con le impostazioni seguenti:
- Tipo di dati:
- Nome:
bike-rentals - Descrizione:
Historic bike rental data - Tipo: Tabella (mltable)
- Nome:
- Origine dati:
- Selezionare Da file locali
- Tipo archiviazione di destinazione:
- Tipo di archivio dati: archiviazione BLOB di Azure
- Nome: workspaceblobstore
- Selezione MLtable:
- Caricare la cartella: Scaricare e decomprimere la cartella contenente i due file necessari da cui caricare
https://aka.ms/bike-rentals
- Caricare la cartella: Scaricare e decomprimere la cartella contenente i due file necessari da cui caricare
Seleziona Crea. Dopo aver creato il set di dati, selezionare il set di dati bike-rentals per continuare a inviare il processo di ML automatizzato.
- Tipo di dati:
Impostazioni attività:
- Tipo di attività: regressione
- Set di dati: noleggi di biciclette
- Colonna di destinazione: noleggi (intero)
- Impostazioni aggiuntive per la configurazione:
- Metrica primaria: NormalizedRootMeanSquaredError
- Spiegare il modello migliore: non selezionato
- Abilitare l’impilamento dell’insieme: Non selezionata
- Usare tutti i modelli supportati: deselezionato. Durante il processo si proveranno solo alcuni algoritmi specifici.
- Modelli consentiti: selezionare solo RandomForest e LightGBM. Normalmente si vorrà provare il maggior numero possibile di modelli, ma ogni modello aggiunto aumenta il tempo necessario per eseguire il processo.
- Limiti: espandere questa sezione
- Numero massimo di versioni di valutazione:
3 - Numero massimo di versioni di valutazione simultanee:
3 - Numero massimo di nodi:
3 - Soglia di punteggio metrica:
0.085(cosicché, se un modello raggiunge un punteggio della metrica Radice normalizzata dell’errore quadratico medio di 0,085 o inferiore, il processo termina). - Timeout esperimento:
15 - Timeout iterazione:
15 - Abilitare la terminazione anticipata: selezionata
- Numero massimo di versioni di valutazione:
- Convalida e test:
- Tipo di convalida: suddivisione tra training e convalida
- Percentuale di dati di convalida: 10
- Set di dati di test: nessuno
Calcolo:
- Selezionare il tipo di elaborazione: serverless
- Tipo di macchina virtuale: CPU
- Livello macchina virtuale: dedicato
- Dimensioni macchina virtuale: Standard_DS3_V2*
- Numero di istanze: 1
* Se la sottoscrizione in uso limita le dimensioni VM disponibili, scegliere qualunque dimensione disponibile.
- Nome processo:
-
Inviare il processo di training. Viene avviato automaticamente.
-
Attendere il completamento del processo. L’operazione potrebbe richiedere un po’ di tempo.
Esaminare il modello migliore
Al termine del processo di Machine Learning automatizzato, è possibile esaminare il modello migliore sottoposto a training.
-
Nella scheda Panoramica del processo di Machine Learning automatizzato prendere nota del riepilogo del modello migliore.
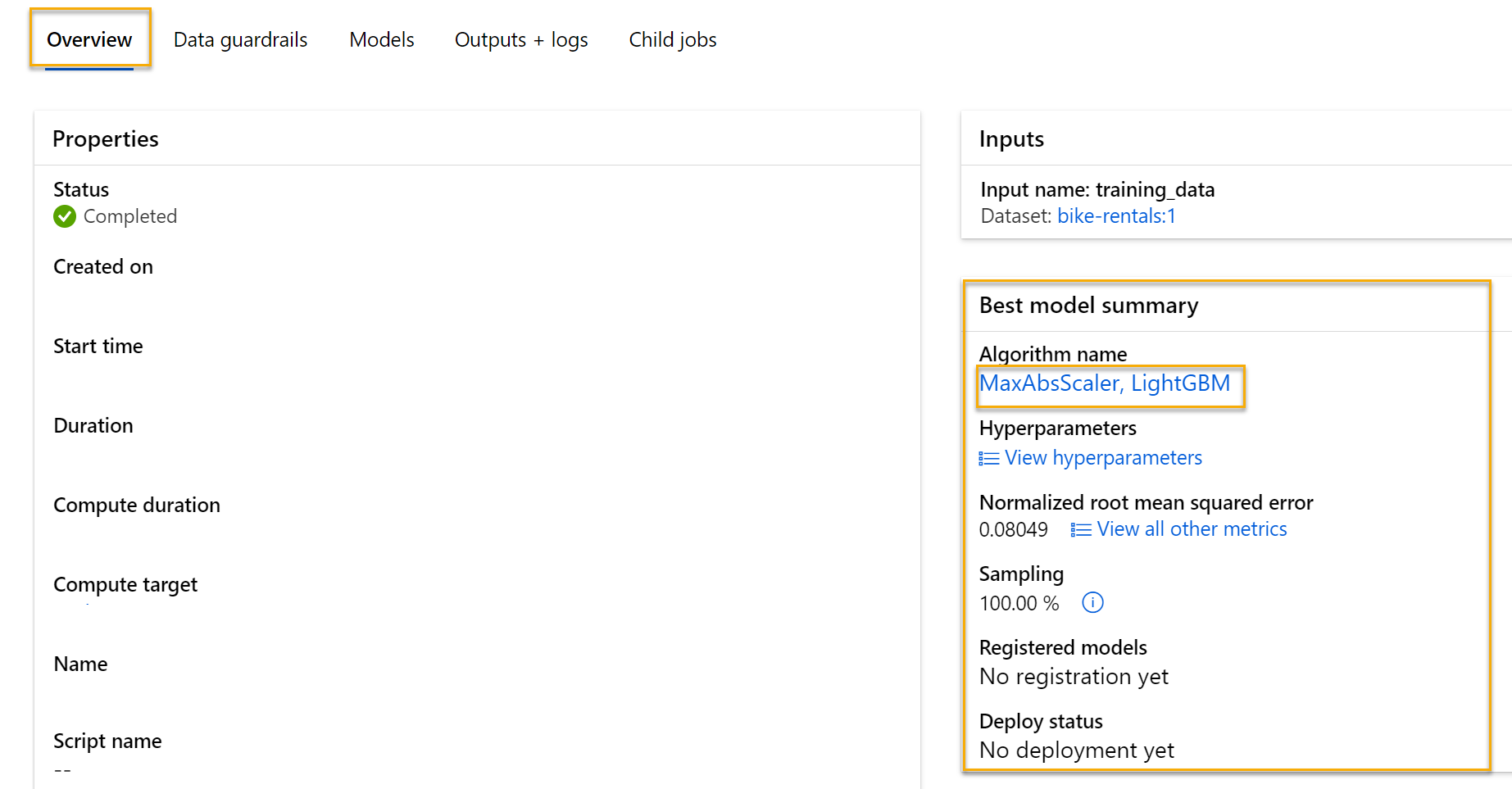
Nota: è possibile che sotto lo stato venga visualizzato un messaggio simile ad “Avviso: punteggio di uscita specificato dall’utente raggiunto…”. Si tratta di un messaggio previsto. Continuare con il passaggio successivo.
-
Selezionare il testo in Nome dell’algoritmo per il modello migliore per visualizzarne i dettagli.
-
Selezionare la scheda Metriche e selezionare i grafici residui e predicted_true, se non sono già selezionati.
Esaminare i grafici che mostrano le prestazioni del modello. Il grafico dei residui mostra i residui (le differenze tra i valori stimati e effettivi) come istogramma. Il grafico predicted_true confronta i valori stimati con i valori true.
Distribuire e testare il modello
- Nella scheda Modello per il modello migliore sottoposto a training dal processo di Machine Learning automatizzato, selezionare Distribuisci e usa l’opzione Endpoint in tempo reale per distribuire il modello con le impostazioni seguenti:
- Macchina virtuale: Standard_DS3_v2
- Numero di istanze: 3
- Endpoint: Nuovo
- Nome dell’endpoint: Lasciare il valore predefinito o assicurarsi che sia univoco a livello globale
- Nome distribuzione: Lasciare il valore predefinito
- Raccolta di dati di inferenza: Disabilitato
- Pacchetto del modello: Disabilitato
- Attendere l’avvio della distribuzione. L’operazione potrebbe richiedere alcuni secondi. Lo Stato di distribuzione per l’endpoint predizione-noleggi verrà indicato nella parte principale della pagina come In esecuzione.
- Attendere che lo Stato di distribuzione cambi in Completato. L’operazione potrebbe richiedere da 5 a 10 minuti.
Testare il servizio distribuito
A questo punto è possibile testare il servizio distribuito.
-
In Azure Machine Learning Studio, nel menu di sinistra, selezionare Endpoint e aprire l’endpoint in tempo reale previsione-noleggi.
-
Nella pagina dell’endpoint in tempo reale previsione-noleggi visualizzare la scheda Test.
-
Nel riquadro Dati di input per testare l’endpoint sostituire il codice JSON del modello con i dati di input seguenti:
{ "input_data": { "columns": [ { "day": 1, "mnth": 1, "year": 2022, "season": 2, "holiday": 0, "weekday": 1, "workingday": 1, "weathersit": 2, "temp": 0.3, "atemp": 0.3, "hum": 0.3, "windspeed": 0.3 } ], "index": [], "data": [] } } -
Fare clic sul pulsante Test.
-
Esaminare i risultati dei test, che includono un numero stimato dei noleggi in base alle caratteristiche di input, simile a questo:
{ "Results": [ 444.27799000000000 ] }Il riquadro di test ha considerato i dati di input e ha usato il modello sottoposto a training per restituire il numero stimato di noleggi.
Di seguito vengono descritte le operazioni eseguite. È stato usato un set di dati cronologici relativi al noleggio di biciclette per eseguire il training di un modello. Il modello stima il numero di noleggi di biciclette previsti in un determinato giorno, in base a caratteristiche stagionali e meteorologiche.
Eliminazione
Il servizio Web creato è ospitato in un’Istanza di contenitore di Azure. Se non si vogliono eseguire altri esperimenti con tale servizio, è consigliabile eliminare l’endpoint per evitare di accumulare tempi di utilizzo superflui per Azure.
-
In Azure Machine Learning Studio nella scheda Endpoint selezionare l’endpoint previsione-noleggi. Selezionare quindi Elimina e confermare l’eliminazione dell’endpoint.
L’eliminazione delle risorse di calcolo garantisce che alla sottoscrizione non vengano addebitati i costi di calcolo corrispondenti. Verrà tuttavia addebitato un importo ridotto per l’archiviazione dei dati, fintanto che l’area di lavoro di Azure Machine Learning è presente nella sottoscrizione. Se è stata completata l’esplorazione di Azure Machine Learning, è possibile eliminare l’area di lavoro di Azure Machine Learning e le risorse associate.
Per eliminare l’area di lavoro:
- Nel portale di Azure, nella pagina Gruppi di risorse, aprire il gruppo di risorse specificato durante la creazione dell’area di lavoro di Azure Machine Learning.
- Fare clic su Elimina gruppo di risorse, digitare il nome del gruppo di risorse per confermare che si vuole eliminarlo e quindi selezionare Elimina.