조각화 문제 감지 및 수정
예상 시간: 15분
학생들은 단원에서 파악한 정보를 사용하여 AdventureWorks 내에서 진행되는 디지털 혁신 프로젝트의 결과물을 확인합니다. Azure Portal과 다른 도구를 살펴보며, 학생은 기본 도구를 활용하여 성능 관련 문제를 식별하고 해결하는 방법을 결정합니다. 마지막으로 학생은 데이터베이스 내에서 조각화를 식별하고 적절하게 해결하는 단계를 배울 수 있습니다.
데이터베이스 관리자는 성능 관련 문제를 식별하고 발견된 문제를 해결하는 실행 가능한 솔루션을 제공하도록 고용됩니다. AdventureWorks는 10년 이상 소비자 및 유통업체에 자전거와 자전거 부품을 직접 판매해 왔습니다. 최근 이 회사는 고객의 요청을 서비스하는 데 사용되는 제품의 성능 저하를 발견했습니다. SQL 도구를 사용하여 성능 문제를 식별한 다음 해결하는 방법을 제안해야 합니다.
참고: 이 연습을 진행할 때는 T-SQL 코드를 복사하여 붙여넣어야 합니다. 코드를 실행하기 전에 코드를 올바르게 복사했는지 확인하세요.
데이터베이스 복원
-
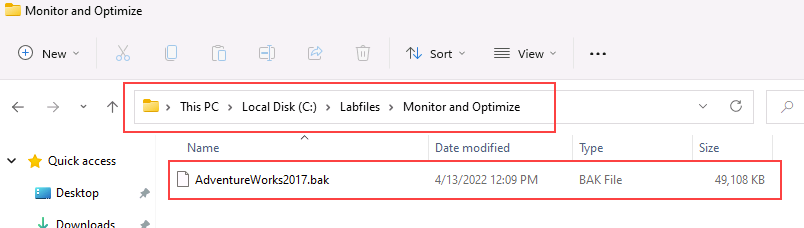
https://github.com/MicrosoftLearning/dp-300-database-administrator/blob/master/Instructions/Templates/AdventureWorks2017.bak에 있는 데이터베이스 백업 파일을 랩 가상 머신의 C:\LabFiles\Monitor and optimize 경로에 다운로드합니다(폴더 구조가 없는 경우 새로 만들기).
-
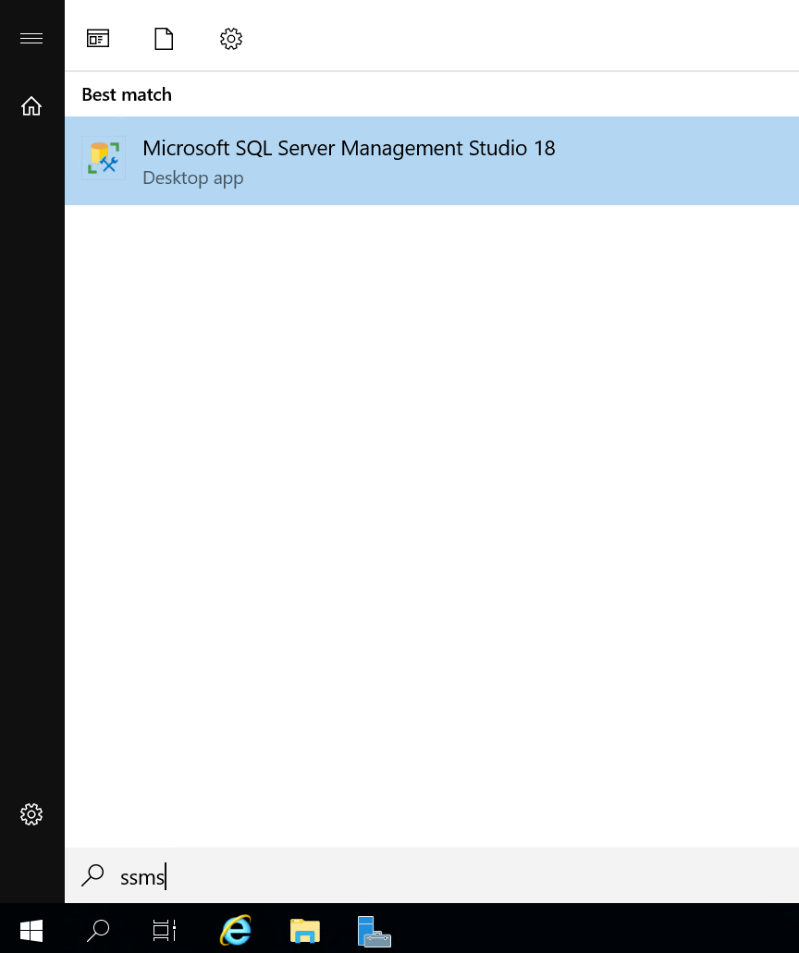
Windows 시작 단추를 선택하고 SSMS를 입력합니다. 목록에서 Microsoft SQL Server Management Studio 18을 선택합니다.
-
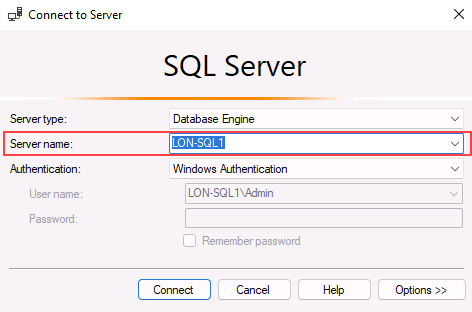
SSMS가 열리면 서버에 연결 대화 상자가 기본 인스턴스 이름으로 미리 채워집니다. 연결을 선택합니다.
-
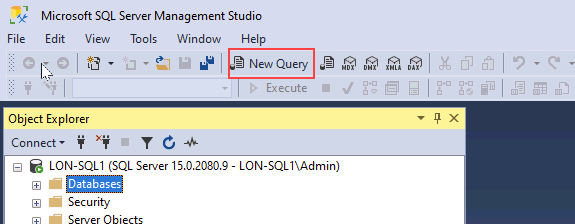
데이터베이스 폴더를 선택한 다음, 새 쿼리를 선택합니다.
-
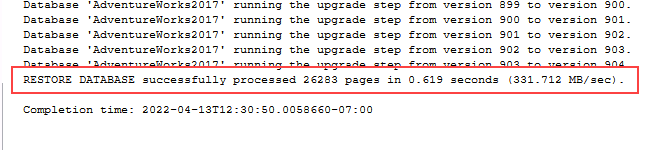
새 쿼리 창에서 아래 T-SQL을 복사하여 붙여넣습니다. 쿼리를 실행하여 데이터베이스를 복원합니다.
RESTORE DATABASE AdventureWorks2017 FROM DISK = 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.bak' WITH RECOVERY, MOVE 'AdventureWorks2017' TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.mdf', MOVE 'AdventureWorks2017_log' TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017_log.ldf';참고: 데이터베이스 백업 파일 이름 및 경로는 1단계에서 다운로드한 것과 일치해야 합니다. 일치하지 않으면 명령이 실패합니다.
-
복원이 완료되면 성공 메시지가 표시되어야 합니다.
인덱스 조각화 조사
-
새 쿼리를 선택합니다. 다음 T-SQL 코드를 복사하여 쿼리 창에 붙여넣습니다. 이 쿼리를 실행하려면 실행을 선택합니다.
USE AdventureWorks2017 GO SELECT i.name Index_Name , avg_fragmentation_in_percent , db_name(database_id) , i.object_id , i.index_id , index_type_desc FROM sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps INNER JOIN sys.indexes i ON ps.object_id = i.object_id AND ps.index_id = i.index_id WHERE avg_fragmentation_in_percent > 50 -- find indexes where fragmentation is greater than 50%이 쿼리를 통해서는 조각화가 50% 를 초과하는 인덱스를 보고합니다. 쿼리는 결과를 반환하지 않아야 합니다.
-
새 쿼리를 선택합니다. 다음 T-SQL 코드를 복사하여 쿼리 창에 붙여넣습니다. 이 쿼리를 실행하려면 실행을 선택합니다.
USE AdventureWorks2017 GO INSERT INTO [Person].[Address] ([AddressLine1] ,[AddressLine2] ,[City] ,[StateProvinceID] ,[PostalCode] ,[SpatialLocation] ,[rowguid] ,[ModifiedDate]) SELECT AddressLine1, AddressLine2, 'Amsterdam', StateProvinceID, PostalCode, SpatialLocation, newid(), getdate() FROM Person.Address; GO이 쿼리에서는 다수의 새 레코드를 추가하여 Person.Address 테이블과 해당 인덱스의 조각화 수준을 늘립니다.
-
첫 번째 쿼리를 다시 실행합니다. 이제 크게 조각난 4개의 인덱스를 볼 수 있습니다.

-
다음 T-SQL 코드를 복사하여 쿼리 창에 붙여넣습니다. 이 쿼리를 실행하려면 실행을 선택합니다.
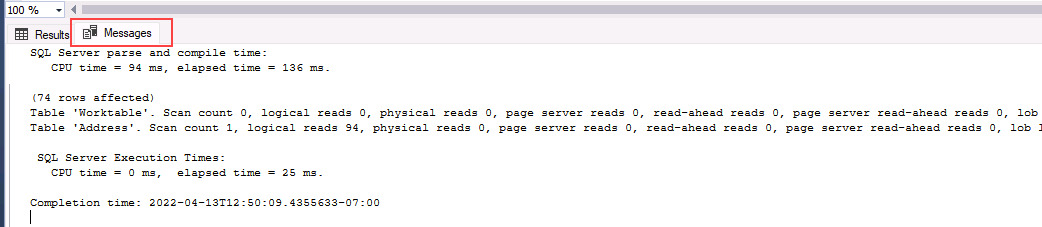
SET STATISTICS IO,TIME ON GO USE AdventureWorks2017 GO SELECT DISTINCT (StateProvinceID) ,count(StateProvinceID) AS CustomerCount FROM person.Address GROUP BY StateProvinceID ORDER BY count(StateProvinceID) DESC; GOSQL Server Management Studio의 결과 창에서 메시지 탭을 클릭합니다. 쿼리에서 수행하는 논리 읽기 수를 기록해 둡니다.
조각화된 인덱스 다시 빌드
-
다음 T-SQL 코드를 복사하여 쿼리 창에 붙여넣습니다. 이 쿼리를 실행하려면 실행을 선택합니다.
USE AdventureWorks2017 GO ALTER INDEX [IX_Address_StateProvinceID] ON [Person].[Address] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) -
아래 쿼리를 실행하여 IX_Address_StateProvinceID 인덱스에 더 이상 50%를 초과하는 조각화가 없는지 확인합니다.
USE AdventureWorks2017 GO SELECT DISTINCT i.name Index_Name , avg_fragmentation_in_percent , db_name(database_id) , i.object_id , i.index_id , index_type_desc FROM sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps INNER JOIN sys.indexes i ON (ps.object_id = i.object_id AND ps.index_id = i.index_id) WHERE i.name = 'IX_Address_StateProvinceID'결과를 비교하면 조각화가 81%에서 0으로 감소한 것을 볼 수 있습니다.
-
이전 섹션의 select 문을 다시 실행합니다. Management Studio에 있는 결과 창의 메시지 탭에서 논리 읽기 수를 기록합니다. 인덱스를 다시 빌드하기 전에 발생한 논리 읽기 수가 변경되었나요?
SET STATISTICS IO,TIME ON GO USE AdventureWorks2017 GO SELECT DISTINCT (StateProvinceID) ,count(StateProvinceID) AS CustomerCount FROM person.Address GROUP BY StateProvinceID ORDER BY count(StateProvinceID) DESC; GO
인덱스를 다시 빌드했으므로 이제 효율성이 극대화되고 논리 읽기가 감소되어야 합니다. 이제 인덱스 유지 관리가 쿼리 성능에 영향을 미칠 수 있음을 확인했습니다.
이 연습에서는 인덱스를 다시 작성하고 논리적 읽기를 분석하여 쿼리 성능을 향상시키는 방법을 알아보았습니다.