分析湖数据库中的数据
Azure Synapse Analytics 让你能够通过创建湖数据库,将数据湖中文件存储的灵活性与关系数据库的结构化架构和 SQL 查询功能相结合。 湖数据库是在数据湖文件存储上定义的关系数据库架构,可以实现将数据存储与用于查询的计算相分离。 湖数据库不仅有结构化架构的优势,包括对数据类型、关系和通常仅在关系数据库系统中发现的其他功能的支持,还可以灵活地将数据存储在可独立于关系数据库存储使用的文件中。 从本质上讲,湖数据库将关系架构“覆盖”到数据湖的文件夹中的文件上。
完成此练习大约需要 45 分钟。
准备工作
需要一个你在其中具有管理级权限的 Azure 订阅。
预配 Azure Synapse Analytics 工作区
若要支持湖数据库,你需要一个可以访问数据湖存储的 Azure Synapse Analytics 工作区。 无需专用 SQL 池,因为可以使用内置的无服务器 SQL 池定义湖数据库。 (可选)还可以使用 Spark 池来处理湖数据库中的数据。
在本练习中,你将组合使用 PowerShell 脚本和 ARM 模板来预配 Azure Synapse Analytics 工作区。
- 登录到 Azure 门户,地址为 。
-
使用页面顶部搜索栏右侧的 [>_] 按钮在 Azure 门户中创建新的 Cloud Shell,在出现提示时选择“PowerShell”环境并创建存储。 Cloud Shell 在 Azure 门户底部的窗格中提供命令行界面,如下所示:
注意:如果以前创建了使用 Bash 环境的 Cloud Shell,请使用 Cloud Shell 窗格左上角的下拉菜单将其更改为 PowerShell****。
-
请注意,可以通过拖动窗格顶部的分隔条或使用窗格右上角的 —、◻ 或 X 图标来调整 Cloud Shell 的大小,以最小化、最大化和关闭窗格 。 有关如何使用 Azure Cloud Shell 的详细信息,请参阅 Azure Cloud Shell 文档。
-
在 PowerShell 窗格中,输入以下命令以克隆此存储库:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
克隆存储库后,输入以下命令以更改为此练习的文件夹,然后运行其中包含的 setup.ps1 脚本:
cd dp-203/Allfiles/labs/04 ./setup.ps1 - 如果出现提示,请选择要使用的订阅(仅当有权访问多个 Azure 订阅时才会发生这种情况)。
-
出现提示时,输入要为 Azure Synapse SQL 池设置的合适密码。
注意:请务必记住此密码!
- 等待脚本完成 - 此过程通常需要大约 10 分钟;但在某些情况下可能需要更长的时间。 在等待时,请查看 Azure Synapse Analytics 文档中的湖数据库和湖数据库模板文章。
修改容器权限
- 部署脚本完成后,请在 Azure 门户转到它创建的 dp203-xxxxxxx 资源组。请注意,此资源组包含 Synapse 工作区、数据湖的存储帐户和 Apache Spark 池**。
-
为名为 datalakexxxxxxx 的数据湖选择“存储帐户”****
-
在 datalakexxxxxx 容器中,选择“文件文件夹”
-
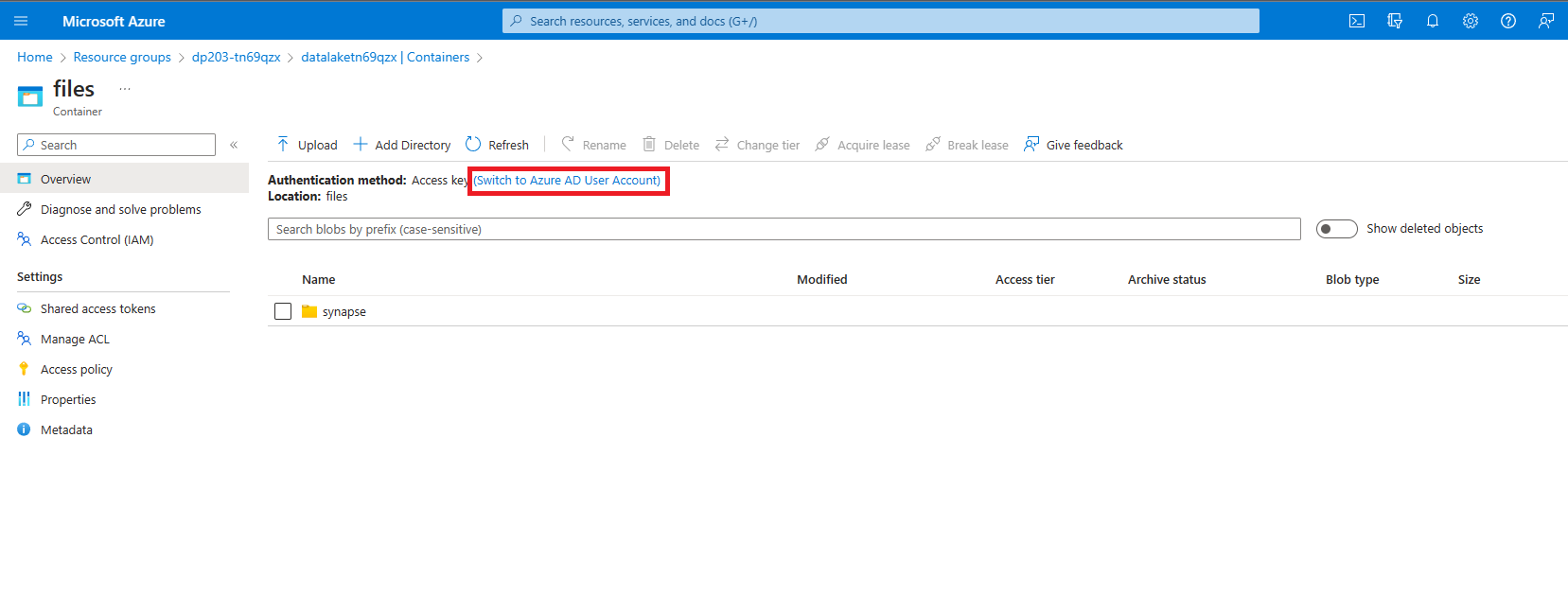
在“文件文件夹”中,会显示“身份验证方法:”为“访问密钥(切换到 Azure Entra 用户帐户)”,单击此项更改为“Entra 用户帐户”。******
创建 Lake 数据库
湖数据库是一种可在工作区中定义并通过内置无服务器 SQL 池使用的数据库。
- 选择“Synapse 工作区”,在其“概述”页的“打开 Synapse Studio”卡中,选择“打开”,以在新浏览器标签页中打开 Synapse Studio;如果出现提示,请进行登录 。
- 在 Synapse Studio 左侧,使用 ›› 图标展开菜单,这将显示 Synapse Studio 中用于管理资源和执行数据分析任务的不同页面。
- 在“数据”页上,查看“已链接”选项卡并验证工作区是否包含 Azure Data Lake Storage Gen2 存储帐户的链接 。
- 在“数据”页上,切换回“工作区”选项卡,并注意工作区中没有数据库 。
- 在 + 菜单中,选择“湖数据库”打开一个新选项卡,你可以在其中设计数据库架构(如果系统提示,接受数据库模板使用条款) 。
- 在新数据库的“属性”窗格中,将“名称”更改为“RetailDB”,并验证“输入文件夹”属性是否已自动更新为 files/RetailDB 。 将“数据格式”保留为“带分隔符的文本”(也可以使用 Parquet 格式,并且可以替代单个表的文件格式 - 我们将在本练习中使用逗号分隔的数据。 )
- 在“RetailDB”窗格顶部,选择“发布”以保存当前数据库 。
- 在左侧的“数据”窗格中,查看“链接”选项卡。然后展开“Azure Data Lake Storage Gen2”和 synapsexxxxxxx 工作区的主 datalakexxxxxxx 存储区,然后选择“文件”文件系统;该文件系统当前包含名为 synapse 的文件夹 。
- 在已打开的“文件”选项卡中,使用“+ 新建文件夹”按钮创建名为 RetailDB 的新文件夹 - 这是数据库中表使用的数据文件的输入文件夹 。
创建表
创建湖数据库后,可以通过创建表来定义其架构。
定义表架构
- 切换回数据库定义的“RetailDB”选项卡,在“+ 表”列表中选择“自定义”,并注意将名为“Table_1”的新表添加到数据库中 。
- 选中“Table_1”后,在数据库设计画布下的“常规”选项卡中,将“名称”属性更改为“客户” 。
- 展开“表的存储设置”部分,请注意,该表将以带分隔符的文本的形式存储在 Synapse 工作区的默认数据湖存储的 files/RetailDB/Customer 文件夹中 。
-
在“列”选项卡上,请注意,默认情况下,表包含一个名为 Column_1 的列 。 编辑列定义以匹配以下属性:
名称 键 说明 可空性 数据类型 格式/长度 CustomerId PK 🗹 唯一客户 ID 🗆 long -
在“+ 列”列表中,选择“新建列”,然后修改新列定义以将 FirstName 列添加到表中,如下所示 :
名称 键 说明 可空性 数据类型 格式/长度 CustomerId PK 🗹 唯一客户 ID 🗆 long 名字 PK 🗆 客户名字 🗆 string 256 -
添加更多新列,直到表定义如下所示:
名称 键 说明 可空性 数据类型 格式/长度 CustomerId PK 🗹 唯一客户 ID 🗆 long FirstName PK 🗆 客户名字 🗆 字符串 256 LastName PK 🗆 客户姓氏 🗹 字符串 256 EmailAddress PK 🗆 客户电子邮件 🗆 字符串 256 电话 PK 🗆 客户电话 🗹 字符串 256 - 添加所有列后,再次发布数据库以保存更改。
- 在左侧的“数据”窗格中,切换回“工作区”选项卡,以便可以看到 RetailDB 湖数据库 。 然后展开它并刷新其 Tables 文件夹,以查看新创建的 Customer 表 。
将数据加载到表的存储路径中
- 在主窗格中,切换回“文件”选项卡,其中包含带有 RetailDB 文件夹的文件系统 。 然后打开 RetailDB 文件夹,并在其中创建名为 Customer 的新文件夹 。 这是 Customer 表获取其数据的位置。
- 打开新的 Customer 文件夹,该文件夹应为空。
-
从 https://raw.githubusercontent.com/MicrosoftLearning/dp-203-azure-data-engineer/master/Allfiles/labs/04/data/customer.csv 下载 customer.csv 数据文件,并将其保存在本地计算机上的文件夹中(位置无关紧要)。 然后,在 Synapse Explorer 的 Customer 文件夹中,使用“⤒ 上传”按钮将 customer.csv 文件上传到数据湖中的 RetailDB/Customer 文件夹 。
注意:在实际生产场景中,可能会创建一个管道,将数据引入到表数据的文件夹中。 在本练习中,我们权且在 Synapse Studio 用户界面直接上传它。
- 在左侧“数据”窗格的“工作区”选项卡上,在 Customer 表的“…”菜单中,选择“新建 SQL 脚本” > 选择前 100 行 。 然后,在打开的新的“SQL 脚本 1”窗格中,确保内置 SQL 池已连接,并使用“▷ 运行”按钮运行 SQL 代码 。 结果应包含 Customer 表中的前 100 行,具体取决于数据湖的基础文件夹中存储的数据。
- 关闭“SQL 脚本 1”选项卡,放弃所做的更改。
从数据库模板创建表
如你所见,可以从头开始在湖数据库中创建所需的表。 但是,Azure Synapse Analytics 还提供许多基于常见数据库工作负载和实体的数据库模板,这些模板可以用作数据库架构的起点。
定义表架构
- 在主窗格中,切换回“RetailDB”窗格,其中包含数据库架构(当前仅包含 Customer 表) 。
- 在“+ 表”菜单中,选择“从模板” 。 然后在“从模板添加”页中,选择“零售”,然后单击“继续” 。
- 在“从模板添加(零售)”页中,等待表列表填充,然后展开“产品”并选择“RetailProduct” 。 然后单击“添加” 。 这会将基于 RetailProduct 模板的新表添加到数据库。
- 在“RetailDB”窗格中,选择新的 RetailProduct 表 。 然后,在设计画布下的窗格中的“常规”选项卡上,将名称更改为“Product”,并验证表的存储设置是否指定输入文件夹 files/RetailDB/Product 。
- 请注意,在 Product 表的“列”选项卡上,该表已包含大量继承自模板的列 。 此表的列数超出所需列数,因此需要删除一些列。
- 选中“名称”旁边的复选框以选择所有列,然后取消选中(需要保留的)以下列:
- ProductId
- ProductName
- IntroductionDate
- ActualAbandonmentDate
- ProductGrossWeight
- ItemSku
-
在“列”窗格的工具栏上,选择“删除”以删除所选列 。 这应该会留下以下列:
名称 键 说明 可空性 数据类型 格式/长度 ProductId PK 🗹 产品的唯一标识符。 🗆 long ProductName PK 🗆 产品的名称… 🗹 字符串 128 IntroductionDate PK 🗆 产品推出销售的日期。 🗹 date YYYY-MM-DD ActualAbandonmentDate PK 🗆 停止销售产品的实际日期… 🗹 date YYY-MM-DD ProductGrossWeight PK 🗆 产品毛重。 🗹 Decimal 18,8 ItemSku PK 🗆 库存单位标识符… 🗹 字符串 20 -
将名为“ListPrice”的新列添加到表中,如下所示:
名称 键 说明 可空性 数据类型 格式/长度 ProductId PK 🗹 产品的唯一标识符。 🗆 long ProductName PK 🗆 产品的名称… 🗹 字符串 128 IntroductionDate PK 🗆 产品推出销售的日期。 🗹 date YYYY-MM-DD ActualAbandonmentDate PK 🗆 停止销售产品的实际日期… 🗹 date YYY-MM-DD ProductGrossWeight PK 🗆 产品毛重。 🗹 Decimal 18,8 ItemSku PK 🗆 库存单位标识符… 🗹 字符串 20 ListPrice PK 🗆 产品价格。 🗆 decimal 18,2 - 如上所示修改列后,请再次发布数据库以保存更改。
- 在左侧的“数据”窗格中,切换回“工作区”选项卡,以便可以看到 RetailDB 湖数据库 。 然后使用 Tables 文件夹的“…”菜单刷新视图并查看新创建的 Product 表 。
将数据加载到表的存储路径中
- 在主窗格中,切换回包含文件系统的“文件”选项卡,然后导航到 files/RetailDB 文件夹,该文件夹当前包含前面创建的表的 Customer 文件夹 。
- 在 RetailDB 文件夹中,创建一个名为 Product 的新文件夹 。 这是 Product 表获取其数据的位置。
- 打开新的 Product 文件夹,该文件夹应为空。
- 从 https://raw.githubusercontent.com/MicrosoftLearning/dp-203-azure-data-engineer/master/Allfiles/labs/04/data/product.csv 下载 product.csv 数据文件,并将其保存在本地计算机上的文件夹中(位置无关紧要)。 然后,在 Synapse Explorer 的 Product 文件夹中,使用“⤒ 上传”按钮将 product.csv 文件上传到数据湖中的 RetailDB/Product 文件夹 。
- 在左侧“数据”窗格的“工作区”选项卡上,在 Product 表的“…”菜单中,选择“新建 SQL 脚本” > 选择前 100 行 。 然后,在打开的新的“SQL 脚本 1”窗格中,确保内置 SQL 池已连接,并使用“▷ 运行”按钮运行 SQL 代码 。 结果应包含 Product 表中的前 100 行,具体取决于数据湖的基础文件夹中存储的数据。
- 关闭“SQL 脚本 1”选项卡,放弃所做的更改。
从现有数据创建表
到目前为止,你已创建表,然后填充了数据。 在某些情况下,你可能已具有数据湖中要用于派生表的数据。
上传数据
- 在主窗格中,切换回包含文件系统的“文件”选项卡,然后导航到 files/RetailDB 文件夹,该文件夹当前包含前面创建的表的 Customer 和 Product 文件夹 。
- 在 RetailDB 文件夹中,创建一个名为 SalesOrder 的新文件夹 。
- 打开新的 SalesOrder 文件夹,该文件夹应为空。
- 从 https://raw.githubusercontent.com/MicrosoftLearning/dp-203-azure-data-engineer/master/Allfiles/labs/04/data/salesorder.csv 下载 salesorder.csv 数据文件,并将其保存在本地计算机上的文件夹中(位置无关紧要)。 然后,在 Synapse Explorer 的 SalesOrder 文件夹中,使用“⤒ 上传”按钮将 salesorder.csv 文件上传到数据湖中的 RetailDB/SalesOrder 文件夹 。
创建表
- 在主窗格中,切换回“RetailDB”窗格,其中包含数据库架构(当前包含 Customer 和 Product 表) 。
- 在“+ 表”菜单中,选择“从数据湖” 。 然后在“从数据湖创建外部表”窗格中,指定以下选项:
- 外部表名称:SalesOrder
- 链接服务:选择“synapse xxxxxxx-WorkspaceDefautStorage (datalakexxxxxxx)”
- 文件夹的输入文件:files/RetailDB/SalesOrder
- 继续下一页,然后使用以下选项创建表:
- File type:CSV
- 字段终止符:默认(逗号 ,)
- 第一行:将“推理列名称”保留为未选中状态。
- 字符串分隔符:默认(空字符串)
- 使用默认类型:默认类型(true、false)
- 最大字符串长度:4000
-
创建表后,请注意,它包括名为 C1、C2 等的列,并且数据类型已从文件夹中的数据推断出来 。 按如下所示修改列定义:
名称 键 说明 可空性 数据类型 格式/长度 SalesOrderId PK 🗹 订单的唯一标识符。 🗆 long OrderDate PK 🗆 订单的日期。 🗆 timestamp yyyy-MM-dd LineItemId PK 🗹 单个商品种类的 ID。 🗆 long CustomerId PK 🗆 客户。 🗆 long ProductId PK 🗆 产品。 🗆 long 数量 PK 🗆 订单数量。 🗆 long 注意:该表包含订购的每个商品的记录,并包含由 SalesOrderId 和 LineItemId 组成的复合主键 。
-
在 SalesOrder 表的“关系”选项卡上的“+ 关系”列表中,选择“到表”,然后定义以下关系 :
从表 从列 到表 到列 客户 CustomerId 订单 CustomerId -
使用以下设置添加第二个“到表”关系:
从表 从列 到表 到列 产品 ProductId 订单 ProductId 定义表间关系的功能有助于在相关数据实体之间强制执行引用完整性规则。 这是关系数据库的一个常见功能,此功能通过其他方式很难应用于数据湖中的文件。
- 再次发布数据库以保存更改。
- 在左侧的“数据”窗格中,切换回“工作区”选项卡,以便可以看到 RetailDB 湖数据库 。 然后使用 Tables 文件夹的“…”菜单刷新视图并查看新创建的 SalesOrder 表 。
使用湖数据库表
现在,数据库中已有一些表,可以使用它们来处理基础数据。
使用 SQL 查询表
- 在 Synapse Studio 中,选择“开发”页。
- 在“开发”窗格的“+”菜单中,选择“SQL 脚本” 。
- 在新的“SQL 脚本 1”窗格中,确保脚本已连接到内置 SQL 池,并在“用户数据库”列表中选择“RetailDB” 。
-
输入以下 SQL 代码:
SELECT o.SalesOrderID, c.EmailAddress, p.ProductName, o.Quantity FROM SalesOrder AS o JOIN Customer AS c ON o.CustomerId = c.CustomerId JOIN Product AS p ON o.ProductId = p.ProductId -
使用“▷ 运行”按钮运行 SQL 代码。
结果显示订单详细信息以及客户和产品信息。
- 关闭“SQL 脚本 1”窗格,放弃所做的更改。
Spark 插入数据
- 在“开发”窗格的“+”菜单中,选择“笔记本” 。
- 在新的“笔记本 1”窗格中,将笔记本附加到 sparkxxxxxxx*** Spark 池。
-
在空笔记本单元格中输入以下代码:
%%sql INSERT INTO `RetailDB`.`SalesOrder` VALUES (99999, CAST('2022-01-01' AS TimeStamp), 1, 6, 5, 1) - 使用单元格左侧的“▷”按钮运行,并等待运行完成。 请注意,启动 Spark 池需要一些时间。
- 使用“+ 代码”按钮向笔记本添加一个新的单元格。
-
在新单元格中,输入以下代码:
%%sql SELECT * FROM `RetailDB`.`SalesOrder` WHERE SalesOrderId = 99999 - 使用单元格左侧的“▷”按钮运行,并验证 SalesOrder 表中是否插入了销售订单 99999 的行 。
- 关闭“笔记本 1”窗格,停止 Spark 会话并放弃更改。
删除 Azure 资源
你已完成对 Azure Synapse Analytics 的探索,现在应删除已创建的资源,以避免产生不必要的 Azure 成本。
- 关闭 Synapse Studio 浏览器选项卡并返回到 Azure 门户。
- 在 Azure 门户的“主页”上,选择“资源组”。
- 选择 Synapse Analytics 工作区的 dp203-xxxxxxx 资源组(不是受管理资源组),并确认它包含 Synapse 工作区、存储帐户和工作区的 Spark 池**。
- 在资源组的“概述”页的顶部,选择“删除资源组”。
-
输入 dp203-xxxxxxx 资源组名称以确认要删除该资源组,然后选择“删除” 。
几分钟后,将删除 Azure Synapse 工作区资源组及其关联的托管工作区资源组。