Utiliser un notebook Apache Spark dans un pipeline
Dans cet exercice, nous allons créer un pipeline Azure Synapse Analytics qui inclut une activité pour exécuter un notebook Apache Spark.
Cet exercice devrait prendre environ 30 minutes.
Avant de commencer
Vous avez besoin d’un abonnement Azure dans lequel vous avez un accès administratif.
Provisionner un espace de travail Azure Synapse Analytics
Vous aurez besoin d’un espace de travail Azure Synapse Analytics avec accès au Data Lake Storage et d’un pool Spark.
Dans cet exercice, vous allez utiliser la combinaison d’un script PowerShell et d’un modèle ARM pour approvisionner un espace de travail Azure Synapse Analytics.
- Connectez-vous au portail Azure à l’adresse
https://portal.azure.com. -
Utilisez le bouton [>_] à droite de la barre de recherche, en haut de la page, pour créer un environnement Cloud Shell dans le portail Azure, puis sélectionnez un environnement PowerShell et créez le stockage si vous y êtes invité. Cloud Shell fournit une interface de ligne de commande dans un volet situé en bas du portail Azure, comme illustré ici :
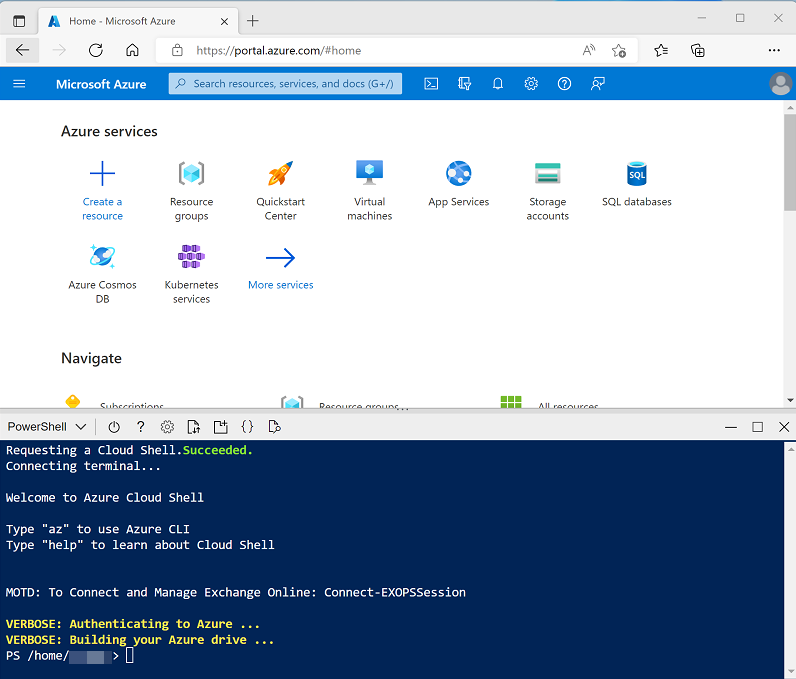
Remarque : si vous avez déjà créé un interpréteur de commandes cloud qui utilise un environnement Bash, utilisez le menu déroulant en haut à gauche du volet de l’interpréteur de commandes Cloud Shell pour le remplacer par PowerShell.
-
Notez que vous pouvez redimensionner Cloud Shell en faisant glisser la barre de séparation en haut du volet. Vous pouvez aussi utiliser les icônes —, ◻ et X situées en haut à droite du volet pour réduire, agrandir et fermer le volet. Pour plus d’informations sur l’utilisation d’Azure Cloud Shell, consultez la documentation Azure Cloud Shell.
-
Dans le volet PowerShell, entrez les commandes suivantes pour cloner ce référentiel :
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Une fois que le référentiel a été cloné, entrez les commandes suivantes pour accéder au dossier de cet exercice et exécutez le script setup.ps1 qu’il contient :
cd dp-203/Allfiles/labs/11 ./setup.ps1 - Si vous y êtes invité, choisissez l’abonnement à utiliser (uniquement si vous avez accès à plusieurs abonnements Azure).
-
Quand vous y êtes invité, entrez un mot de passe approprié à définir pour votre pool Azure Synapse SQL.
Remarque : veillez à mémoriser ce mot de passe.
- Attendez que le script se termine. Cela prend généralement environ 10 minutes, mais dans certains cas, cela peut prendre plus de temps. Pendant que vous attendez, consultez l’article Pipelines Azure Synapse dans la documentation Azure Synapse Analytics.
Exécuter un notebook Spark de manière interactive
Avant d’automatiser un processus de transformation de données avec un notebook, il peut être utile d’exécuter le notebook de manière interactive pour mieux comprendre le processus que vous automatiserez ultérieurement.
- Une fois le script terminé, dans le portail Azure, accédez au groupe de ressources dp203-xxxxxxx qu’il a créé, puis sélectionnez votre espace de travail Synapse.
- Dans la page Vue d’ensemble de votre espace de travail Synapse, dans la carte Ouvrir Synapse Studio, sélectionnez Ouvrir pour ouvrir Synapse Studio dans un nouvel onglet de navigateur. Connectez-vous si vous y êtes invité.
- Sur le côté gauche de Synapse Studio, utilisez l’icône ›› pour développer le menu et afficher les différentes pages de Synapse Studio.
- Dans la page Données, affichez l’onglet Lié et vérifiez que votre espace de travail inclut un lien vers votre compte de stockage Azure Data Lake Storage Gen2, qui doit avoir un nom similaire à synapsexxx (Primary - datalakexxxxxxxxx).
- Développez votre compte de stockage et vérifiez qu’il contient un conteneur de système de fichiers nommé files (primary).
- Sélectionnez le conteneur de fichiers. Notez qu’il contient un dossier nommé data avec les fichiers de données que vous allez transformer.
- Ouvrez le dossier data** et affichez les fichiers CSV qu’il contient. Cliquez avec le bouton droit sur l’un des fichiers, puis sélectionnez Aperçu pour afficher un exemple de données. Fermez l’aperçu lorsque vous avez terminé.
- Cliquez avec le bouton droit sur l’un des fichiers et sélectionnez Aperçu pour afficher les données qu’il contient. Notez que les fichiers contiennent une ligne d’en-tête. Vous pouvez donc sélectionner l’option permettant d’afficher les en-têtes de colonnes.
-
Fermez l’aperçu. Téléchargez ensuite le fichier Spark Transform.ipynb à partir du dossier Allfiles/labs/11/notebooks.
Remarque : il est préférable de copier ce texte en utilisant Ctrl+A, Ctrl+C, puis de le coller en utilisant Ctrl+V dans un outil tel que le Bloc-notes. Sélectionnez ensuite Fichier, Enregistrer sous et enregistrez le fichier avec le nom Spark Transform.ipynb et le type de fichier tous les fichiers. Vous pouvez également sélectionner le fichier dans GitHub, sélectionner les points de suspension (…), puis choisir Télécharger pour enregistrer le fichier dans un emplacement facile à retrouver.
-
Ensuite, dans la page Développer, développez Notebooks et cliquez sur les options + Importer
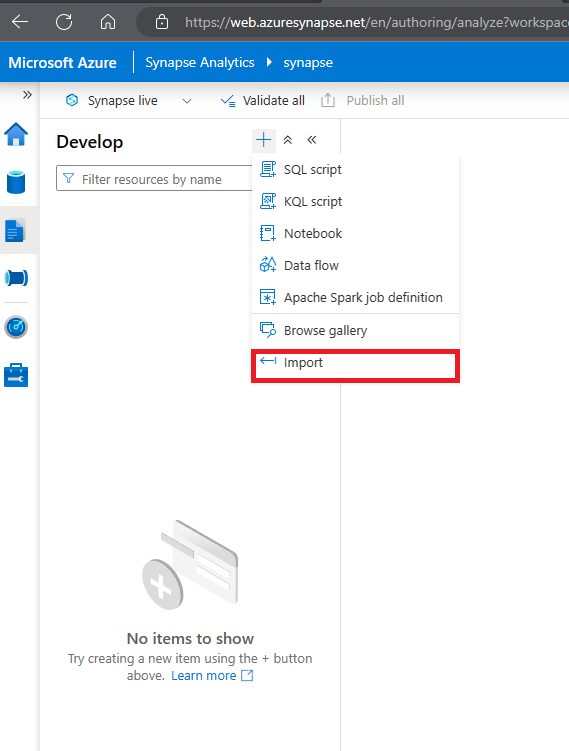
- Sélectionnez le fichier que vous venez de télécharger et d’enregistrer sous le nom Spark Transfrom.ipynb.
- Attachez le notebook à votre pool Spark sparkxxxxxxx.
-
Passez en revue les notes du notebook et exécutez les cellules de code.
Remarque : l’exécution de la première cellule de code prend quelques minutes, car le pool Spark doit être démarré. Les cellules suivantes s’exécutent plus rapidement.
- Passez en revue le code que contient le notebook et notez qu’il :
- Définit une variable pour définir un nom de dossier unique.
- Charge les données de commandes CSV à partir du dossier /data.
- Transforme les données en fractionnant le nom du client en plusieurs champs.
- Enregistre les données transformées au format Parquet dans le dossier au nom unique.
-
Dans la barre d’outils du notebook, attachez le notebook à votre pool Spark sparkxxxxxxx, puis utilisez le bouton ▷ Exécuter tout pour exécuter toutes les cellules de code dans le notebook.
Le démarrage de l’exécution des cellules de code de la session Spark peut prendre quelques minutes.
- Lorsque toutes les cellules du notebook ont été exécutées, notez le nom du dossier dans lequel les données transformées ont été enregistrées.
- Passez à l’onglet Fichiers (qui doit toujours être ouvert) et affichez le dossier racine files. Si nécessaire, dans le menu Plus, sélectionnez Actualiser pour afficher le nouveau dossier. Ouvrez-le ensuite pour vérifier qu’il contient des fichiers Parquet.
- Revenez au dossier racine files et sélectionnez le dossier au nom unique généré par le notebook puis, dans le menu Nouveau script SQL, sélectionnez Sélectionner les 100 premières lignes.
- Dans le volet Sélectionner les 100 premières lignes, définissez le type de fichier sur Format Parquet et appliquez la modification.
- Dans le volet de nouveau script SQL qui s’ouvre, utilisez le bouton ▷ Exécuter pour exécuter le code SQL et vérifier qu’il retourne les données de commandes transformées.
Exécuter le notebook dans un pipeline
Maintenant que vous comprenez le processus de transformation, vous êtes prêt à l’automatiser en encapsulant le notebook dans un pipeline.
Créer une cellule de paramètres
- Dans Synapse Studio, revenez à l’onglet Transformation Spark qui contient le notebook et, dans la barre d’outils, dans le menu … à droite, sélectionnez Effacer la sortie.
- Sélectionnez la première cellule de code (qui contient le code pour définir la variable folderName).
- Dans la barre d’outils contextuelle située en haut à droite de la cellule de code, dans le menu …, sélectionnez [@] Activer/désactiver la cellule de paramètre. Vérifiez que le mot paramètres apparaît en bas à droite de la cellule.
- Dans la barre d’outils, utilisez le bouton Publier pour enregistrer les modifications.
Créer un pipeline
- Dans Synapse Studio, sélectionnez la page Intégrer. Ensuite, dans le menu +, sélectionnez Pipeline pour créer un pipeline.
- Dans le volet des Propriétés de votre nouveau pipeline, changez son nom en remplaçant Pipeline1 par Transform Sales Data. Utilisez ensuite le bouton Propriétés au-dessus du volet des Propriétés pour le masquer.
-
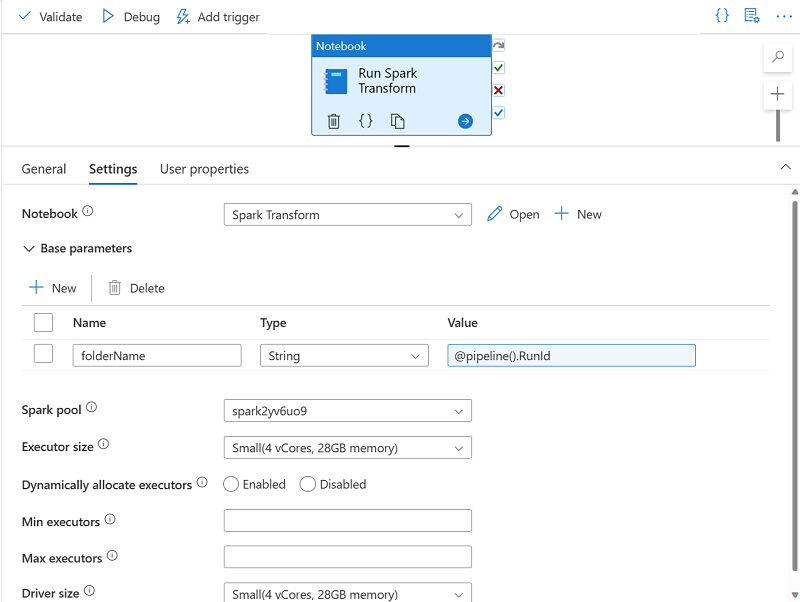
Dans le volet Activités, développez Synapse, puis faites glisser une activité de Notebook sur l’aire de conception du pipeline, comme illustré ici :
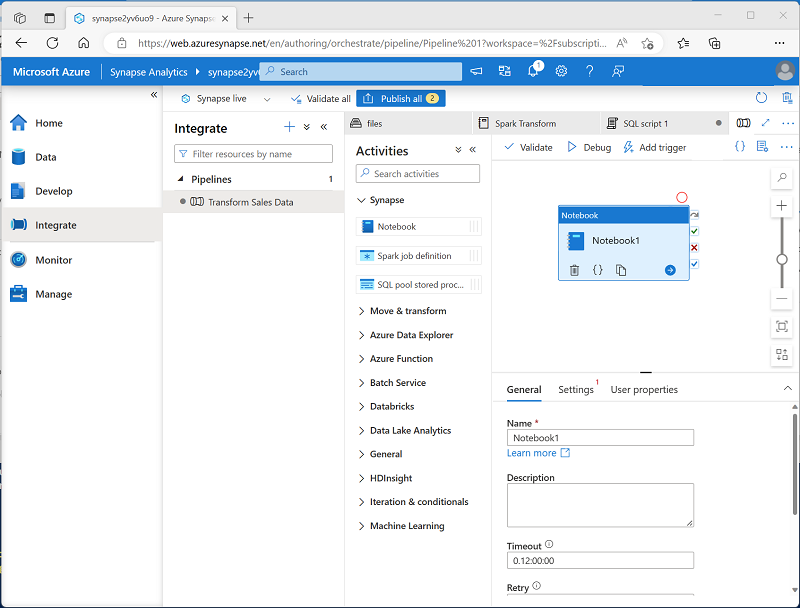
- Sous l’onglet Général de l’activité de notebook, remplacez son nom par Exécuter la transformation Spark.
- Sous l’onglet Paramètres de l’activité de notebook, définissez les propriétés suivantes :
- Notebook : sélectionnez le notebook Transformation Spark.
-
Paramètres de base : développez cette section et définissez un paramètre avec les paramètres suivants :
- Nom : NomDossier
- Type : Chaîne
-
Valeur : sélectionnez Ajouter du contenu dynamique et définissez la valeur du paramètre sur la variable système ID d’exécution du pipeline (
@pipeline().RunId)
- Pool Spark : sélectionnez le pool sparkxxxxxxx.
- Taille de l’exécuteur : sélectionnez Petite (4 vCores, 28 Go de mémoire).
Votre volet Pipeline doit ressembler à ceci :
Publier et exécuter le pipeline
- Utilisez le bouton Publier tout pour publier le pipeline (et toutes les autres ressources non enregistrées).
-
En haut du volet Concepteur de pipeline, dans le menu Ajouter un déclencheur, sélectionnez Déclencher maintenant. Sélectionnez ensuite OK pour confirmer que vous souhaitez exécuter le pipeline.
Remarque : vous pouvez également créer un déclencheur pour exécuter le pipeline à un moment planifié ou en réponse à un événement spécifique.
- Une fois le pipeline en cours d’exécution, dans la page Moniteur, affichez l’onglet Exécutions de pipeline et passez en revue l’état du pipeline Transformer les données de ventes.
-
Sélectionnez le pipeline Transformer les données de ventes pour afficher ses détails, puis notez l’ID d’exécution du pipeline dans le volet Exécutions d’activité.
Le pipeline peut prendre cinq minutes ou plus pour s’achever. Vous pouvez utiliser le bouton ↻ Actualiser dans la barre d’outils pour vérifier son état.
- Lorsque l’exécution du pipeline a réussi, dans la page Données, accédez au conteneur de stockage files et vérifiez qu’un nouveau dossier nommé pour l’ID d’exécution du pipeline a été créé et qu’il contient des fichiers Parquet pour les données de ventes transformées.
Supprimer les ressources Azure
Si vous avez fini d’explorer Azure Synapse Analytics, vous devriez supprimer les ressources que vous avez créées afin d’éviter des coûts Azure inutiles.
- Fermez l’onglet du navigateur Synapse Studio et revenez dans le portail Azure.
- Dans le portail Azure, dans la page Accueil, sélectionnez Groupes de ressources.
- Sélectionnez le groupe de ressources dp203-xxxxxxx de votre espace de travail Synapse Analytics (et non le groupe de ressources managé) et vérifiez qu’il contient l’espace de travail Synapse, le compte de stockage et le pool Spark de votre espace de travail.
- Au sommet de la page Vue d’ensemble de votre groupe de ressources, sélectionnez Supprimer le groupe de ressources.
-
Entrez le nom du groupe de ressources dp203-xxxxxxx pour confirmer que vous souhaitez le supprimer, puis sélectionnez Supprimer.
Après quelques minutes, le groupe de ressources de l’espace de travail Azure Synapse et le groupe de ressources managé de l’espace de travail qui lui est associé seront supprimés.