Einführung in Azure Databricks
Azure Databricks ist eine Microsoft Azure-basierte Version der beliebten Open-Source-Databricks-Plattform.
Ähnlich wie Azure Synapse Analytics bietet ein Azure Databricks-Arbeitsbereich einen zentralen Punkt für die Verwaltung von Databricks-Clustern, -Daten und -Ressourcen in Azure.
Diese Übung dauert ca. 30 Minuten.
Vorbereitung
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Databricks-Arbeitsbereichs
In dieser Übung verwenden Sie ein Skript, um einen neuen Azure Databricks-Arbeitsbereich bereitzustellen.
Tipp: Wenn Sie bereits über einen Standard - oder Testarbeitsbereich für Azure Databricks verfügen, können Sie dieses Verfahren überspringen und Ihren vorhandenen Arbeitsbereich verwenden.
- Melden Sie sich in einem Webbrowser am Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie rechts neben der Suchleiste oben auf der Seite die Schaltfläche [>_], um eine neue Cloud Shell-Instanz im Azure-Portal zu erstellen. Wählen Sie eine PowerShell-Umgebung aus, und erstellen Sie Speicher, falls Sie dazu aufgefordert werden. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
Hinweis: Wenn Sie zuvor eine Cloud Shell erstellt haben, die eine Bash-Umgebung verwendet, ändern Sie diese mithilfe des Dropdownmenüs oben links im Cloud Shell-Bereich zu PowerShell.
-
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern können oder den Bereich mithilfe der Symbole —, ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Nachdem das Repository geklont wurde, geben Sie die folgenden Befehle ein, um in den Ordner für dieses Lab zu wechseln. Führen Sie das darin enthaltene Skript setup.ps1 aus:
cd dp-203/Allfiles/labs/23 ./setup.ps1 -
Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 5 Minuten, in einigen Fällen kann es jedoch länger dauern. Während Sie warten, lesen Sie den Artikel Was ist Azure Databricks? in der Dokumentation zu Azure Databricks.
Erstellen eines Clusters
Azure Databricks ist eine verteilte Verarbeitungsplattform, die Apache Spark-Cluster verwendet, um Daten parallel auf mehreren Knoten zu verarbeiten. Jeder Cluster besteht aus einem Treiberknoten, um die Arbeit zu koordinieren, und Arbeitsknoten zum Ausführen von Verarbeitungsaufgaben.
In dieser Übung erstellen Sie einen Einzelknotencluster , um die in der Lab-Umgebung verwendeten Computeressourcen zu minimieren (in denen Ressourcen möglicherweise eingeschränkt werden). In einer Produktionsumgebung erstellen Sie in der Regel einen Cluster mit mehreren Workerknoten.
Tipp: Wenn Sie bereits über einen Cluster mit einer 13.3 LTS-Laufzeitversion in Ihrem Azure Databricks-Arbeitsbereich verfügen, können Sie damit diese Übung abschließen und dieses Verfahren überspringen.
- Navigieren Sie im Azure-Portal zur Ressourcenruppe dp203-xxxxxxx, die vom Skript erstellt wurde (oder die Ressourcengruppe, die Ihren vorhandenen Azure Databricks-Arbeitsbereich enthält).
- Wählen Sie Ihre Azure Databricks-Dienstressource (mit dem Namen Databricksxxxxxxx aus, wenn Sie das Setupskript zum Erstellen verwendet haben).
-
Verwenden Sie auf der Seite Übersicht für Ihren Arbeitsbereich die Schaltfläche Arbeitsbereich starten, um Ihren Azure Databricks-Arbeitsbereich auf einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Während Sie das Databricks-Arbeitsbereichsportal verwenden, werden möglicherweise verschiedene Tipps und Benachrichtigungen angezeigt. Schließen Sie diese, und folgen Sie den Anweisungen, um die Aufgaben in dieser Übung auszuführen.
-
Zeigen Sie das Azure Databricks-Arbeitsbereichsportal an, und beachten Sie, dass die Randleiste auf der linken Seite Links zu den verschiedenen Aufgabentypen enthält, die Sie ausführen können.
- Wählen Sie in der Randleiste den Link ** (+) Neu** und dann Cluster aus.
- Erstellen Sie auf der Seite Neuer Cluster einen neuen Cluster mit den folgenden Einstellungen:
- Clustername: Cluster des Benutzernamens (der Standardclustername)
- Clustermodus: Einzelknoten
- Zugriffsmodus: Einzelner Benutzer (mit ausgewähltem Benutzerkonto)
- Databricks-Laufzeitversion: 13.3 LTS (Spark 3.4.1, Scala 2.12)
- Photonbeschleunigung verwenden: Ausgewählt
- Knotentyp: Standard_DS3_v2
- Nach 30 Minuten Inaktivität beenden
- Warten Sie, bis der Cluster erstellt wurde. Es kann ein oder zwei Minuten dauern.
Hinweis: Wenn Ihr Cluster nicht gestartet werden kann, verfügt Ihr Abonnement möglicherweise über ein unzureichendes Kontingent in der Region, in der Ihr Azure Databricks-Arbeitsbereich bereitgestellt wird. Details finden Sie unter Der Grenzwert für CPU-Kerne verhindert die Clustererstellung. In diesem Fall können Sie versuchen, Ihren Arbeitsbereich zu löschen und in einer anderen Region einen neuen zu erstellen. Sie können einen Bereich als Parameter für das Setupskript wie folgt angeben:
./setup.ps1 eastus
Verwenden von Spark zum Analysieren einer Datendatei
Wie in vielen Spark-Umgebungen unterstützt Databricks die Verwendung von Notebooks zum Kombinieren von Notizen und interaktiven Codezellen, mit denen Sie Daten untersuchen können.
- Verwenden Sie in der Randleiste den Link ** (+) Neu, um ein **Notebook zu erstellen.
- Ändern Sie den Standardnamen des Notebooks (Unbenanntes Notebook [Datum]) in Produkte erkunden, und wählen Sie in der Dropdownliste Verbinden Ihren Cluster aus, wenn er noch nicht ausgewählt ist. Wenn der Cluster nicht ausgeführt wird, kann es eine Minute dauern, bis er gestartet wird.
- Laden Sie die Datei products.csv auf Ihren lokalen Computer herunter, und speichern Sie sie als products.csv. Wählen Sie dann im Notebook Produkte erkunden im Menü Datei die Option Daten in DBFS hochladen aus.
- Notieren Sie sich im Dialogfeld Daten hochladen das DBFS-Zielverzeichnis, in das die Datei hochgeladen wird. Wählen Sie dann den Bereich Dateien aus, und laden Sie die Datei products.csv hoch, die Sie auf Ihren Computer heruntergeladen haben. Wenn die Datei hochgeladen wurde, wählen Sie Weiter aus.
- Wählen Sie im Bereich Auf Dateien aus Notebooks zugreifen den PySpark-Beispielcode aus, und kopieren Sie ihn in die Zwischenablage. Sie werden diesen Code verwenden, um die Daten aus der Datei in einen DataFrame zu laden. Wählen Sie dann Fertig aus.
-
Fügen Sie im Notebook Produkte erkunden in der leeren Codezelle den kopierten Code ein, der etwa wie folgt aussehen sollte:
df1 = spark.read.format("csv").option("header", "true").load("dbfs:/FileStore/shared_uploads/user@outlook.com/products.csv") - Verwenden Sie die Menüoption ▸ Zelle ausführen oben rechts in der Zelle, um sie auszuführen, und fügen Sie den Cluster an, wenn Sie dazu aufgefordert werden.
- Warten Sie, bis der vom Code ausgeführte Spark-Auftrag abgeschlossen ist. Der Code hat ein Dataframe-Objekt namens df1 aus den Daten in der Datei erstellt, die Sie hochgeladen haben.
-
Verwenden Sie unter der vorhandenen Codezelle das Symbol +, um eine neue Codezelle hinzuzufügen. Geben Sie dann in der neuen Zelle den folgenden Code ein:
display(df1) -
Verwenden Sie die Menüoption ▸ Zelle ausführen oben rechts in der neuen Zelle, um sie auszuführen. Dieser Code zeigt den Inhalt des Datenframes an, der etwa wie folgt aussehen sollte:
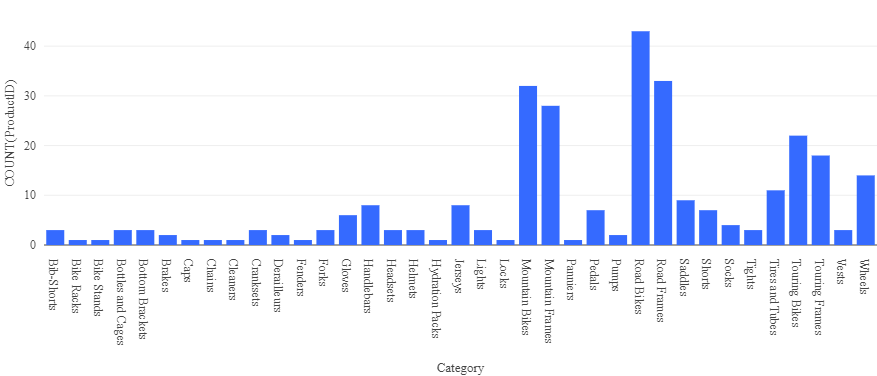
ProductID ProductName Kategorie ListPrice 771 Mountain-100 Silver, 38 Mountainbikes 3399.9900 772 Mountain-100 Silver, 42 Mountainbikes 3399.9900 … … … … - Wählen Sie oberhalb der Ergebnistabelle + und dann Visualisierung aus, um den Visualisierungs-Editor anzuzeigen, und wenden Sie dann die folgenden Optionen an:
- Visualisierungstyp: Balken
- X-Spalte: Kategorie
- Y-Spalte: Fügen Sie eine neue Spalte hinzu, und wählen Sie ProductID aus. Wenden Sie die Anzahl-Aggregation an.
Speichern Sie die Visualisierung, und beachten Sie, dass sie im Notebook wie folgt angezeigt wird:
Erstellen und Abfragen einer Tabelle
Während viele Datenanalysten gern Sprachen wie Python oder Scala verwenden, um mit Daten in Dateien zu arbeiten, basieren viele Datenanalyselösungen auf relationalen Datenbanken. In diesen werden Daten in Tabellen gespeichert und mithilfe von SQL bearbeitet.
- Verwenden Sie im Notebook Produkte erkunden unter der Diagrammausgabe aus der zuvor ausgeführten Codezelle das Symbol +, um eine neue Zelle hinzuzufügen.
-
Geben Sie den folgenden Code in die neue Zelle ein, und führen Sie ihn aus:
df1.write.saveAsTable("products") -
Wenn die Zelle abgeschlossen ist, fügen Sie darunter eine neue Zelle mit dem folgenden Code hinzu:
%sql SELECT ProductName, ListPrice FROM products WHERE Category = 'Touring Bikes'; - Führen Sie die neue Zelle aus, die SQL-Code enthält, um den Namen und Preis der Produkte in der Kategorie Touring Bikes zurückzugeben.
- In der Randleiste wählen Sie den Link Katalog und prüfen, ob die Tabelle products im Standarddatenbankschema erstellt wurde (die wenig überraschend default bezeichnet wird). Es ist möglich, Spark-Code zum Erstellen benutzerdefinierter Datenbankschemas und eines Schemas relationaler Tabellen zu verwenden, mit denen Datenanalysten Daten untersuchen und Analyseberichte generieren können.
Löschen von Databricks-Ressourcen
Nachdem Sie sich mit Azure Databricks vertraut gemacht haben, müssen Sie die von Ihnen erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden und Kapazität in Ihrem Abonnement freizugeben.
- Schließen Sie die Registerkarte mit dem Azure Databricks-Arbeitsbereich, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressourcengruppen aus.
- Wählen Sie die Ressourcengruppe dp203-xxxxxxx (nicht die verwaltete Ressourcengruppe), und vergewissern Sie sich, dass sie Ihren Azure Databricks-Arbeitsbereich enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe dp203-xxxxxxx ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach einigen Minuten werden Ihre Ressourcengruppe und die damit verknüpften Ressourcengruppen im verwalteten Arbeitsbereich gelöscht.