Wichtig: Microsoft Purview wurde aktualisiert, und die Anzahl der verfügbaren Microsoft Purview-Konten pro Azure-Mandant ist jetzt eingeschränkt. Daher wird dieses Lab in freigegebenen Mandantenumgebungen nicht unterstützt, einschließlich vieler gehosteter Labumgebungen, die bei der Präsenzschulung verwendet werden.
Verwenden von Microsoft Purview mit Azure Synapse Analytics
Microsoft Purview ermöglicht es Ihnen, Datenressourcen über Ihre Datenbestände hinweg zu katalogisieren und den Datenfluss während der Übertragung von einer Datenquelle in eine andere nachzuverfolgen – ein Schlüsselelement einer umfassenden Datengovernance-Lösung.
Diese Übung dauert ca. 40 Minuten.
Vor der Installation
Sie benötigen ein Azure-Abonnement, in dem Sie über Administratorrechte und exklusiven Zugriff auf den Mandanten verfügen, in dem das Abonnement definiert ist.
Bereitstellen von Azure-Ressourcen
In dieser Übung verwenden Sie Microsoft Purview, um Ressourcen und Datenherkunft in einem Azure Synapse Analytics-Arbeitsbereich nachzuverfolgen. Sie verwenden zunächst ein Skript, um diese Ressourcen in Ihrem Azure-Abonnement bereitzustellen.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie rechts neben der Suchleiste oben auf der Seite die Schaltfläche [>_] , um eine neue Cloud Shell-Instanz im Azure-Portal zu erstellen. Wählen Sie eine PowerShell-Umgebung aus, und erstellen Sie Speicher, falls Sie dazu aufgefordert werden. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
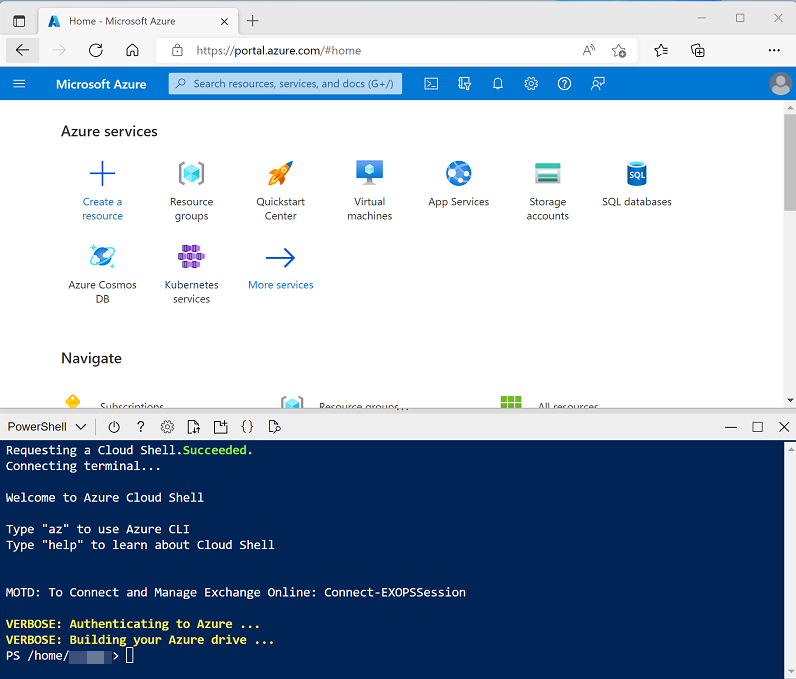
Hinweis: Wenn Sie zuvor eine Cloudshell erstellt haben, die eine Bash-Umgebung verwendet, verwenden Sie das Dropdownmenü oben links im Bereich der Cloudshell, um sie in** Power Shell **zu ändern.
-
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern können oder den Bereich mithilfe der Symbole —, ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Nachdem das Repository geklont wurde, geben Sie die folgenden Befehle ein, um in den Ordner für dieses Lab zu wechseln. Führen Sie das darin enthaltene Skript setup.ps1 aus:
cd dp-203/Allfiles/labs/22 ./setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
-
Wenn Sie dazu aufgefordert werden, geben Sie ein geeignetes Kennwort für Ihre Azure SQL-Datenbank ein.
Hinweis: Merken Sie sich unbedingt dieses Kennwort!
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 15 Minuten, in einigen Fällen kann es jedoch länger dauern. Während Sie warten, lesen Sie den Artikel Was ist im Microsoft Purview Governance-Portal verfügbar? in der Microsoft Purview-Dokumentation.
- Wenn das Skript fertig ist, überprüfen Sie die Ausgabe und beachten Sie, dass für Ihre Ressourcennamen ein eindeutiges Suffix in der Form xxxxxxx generiert wurde – beispielsweise heißt die Ressourcengruppe, die erstellt wurde, dp203-* xxxxxxx*. Merken Sie sich dieses Suffix – Sie werden es später brauchen, wenn Sie zusätzliche Ressourcen erstellen.
Tipp: Falls Sie sich nach dem Ausführen des Setupskripts entschließen, das Lab nicht abzuschließen, löschen Sie die Ressourcengruppe dp203-xxxxxxx, die in Ihrem Azure-Abonnement erstellt wurde, um unnötige Azure-Kosten zu vermeiden.
Erkunden Sie Ihren Arbeitsbereich für Azure Synapse Analytics
Das Skript hat einen Arbeitsbereich für Azure Synapse Analytics erstellt, den Sie über die webbasierte Benutzeroberfläche von Azure Synapse Studio erkunden und verwalten können. Der Arbeitsbereich umfasst einen dedizierten SQL-Pool, der pausiert wurde, um unnötige Kosten zu vermeiden. Sie werden es in Kürze brauchen, also ist jetzt ein guter Zeitpunkt, um es fortzusetzen.
-
Zeigen Sie im Azure-Portal auf der Seite für Ihren Synapse Analytics-Arbeitsbereich die Registerkarte Übersicht an. Verwenden Sie dann in der Kachel Synapse Studio öffnen den Link, um Azure Synapse Studio in einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Alternativ können Sie Azure Synapse Studio öffnen, indem Sie in einer neuen Browserregisterkarte direkt zu https://web.azuresynapse.net navigieren.
- Verwenden Sie im linken Bereich von Synapse Studio das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten in Synapse Studio angezeigt.
-
Wählen Sie auf der Seite Verwalten auf der Registerkarte SQL-Pools die Zeile für den dedizierten SQL-Pool sqlxxxxxxx aus, und klicken Sie auf das zugehörige Symbol ▷, um ihn zu starten. Bestätigen Sie, dass Sie ihn fortsetzen möchten, wenn Sie dazu aufgefordert werden.
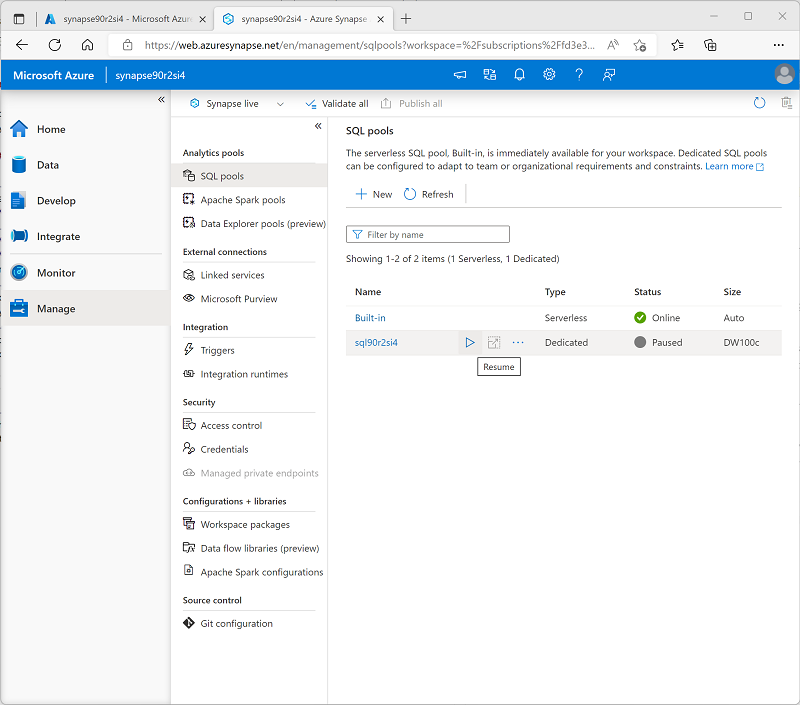
- Das Fortsetzen eines Pools kann einige Minuten dauern. Sie können den Status mithilfe der Schaltfläche ↻ Aktualisieren regelmäßig überprüfen. Der Status wird als Online angezeigt, wenn der SQL-Pool bereit ist. Während Sie warten, führen Sie die folgenden Schritte aus, um eine „Lake Database“ zu erstellen. Kehren Sie dann zur Seite „Verwalten“ zurück, um sicherzustellen, dass der dedizierte SQL-Pool online ist.
Erstellen einer Lake-Datenbank
Lake-Datenbanken speichern Daten in einem Data Lake in Azure Storage. Sie können das Parquet-, Delta- oder CSV-Format und verschiedene Einstellungen verwenden, um Speicher zu optimieren. Jede Lake-Datenbank hat einen verknüpften Dienst, um den Stammdatenordner zu definieren.
Lake-Datenbanken sind in serverlosen SQL-Pools von Synapse SQL und in Apache Spark zugänglich, sodass Benutzer und Benutzerinnen den Speicher von der Berechnung trennen können. Die Metadaten der Lake-Datenbank erleichtern es den verschiedenen Engines, ein integriertes Erlebnis zu bieten und zusätzliche Informationen (z. B. Beziehungen) zu nutzen, die ursprünglich im Data Lake nicht unterstützt wurden.
- Zeigen Sie in Azure Synapse Studio die Seite Daten an, erweitern Sie auf der Registerkarte Arbeitsbereich SQL-Datenbank, um die Datenbanken in Ihrem Arbeitsbereich anzuzeigen. Dazu sollte die sqlxxxxxxx dedizierte SQL-Pool-Datenbank gehören, die Sie gerade wieder aufgenommen haben.
-
Wählen Sie im Bereich „Daten“ im Menü + die Option „Lake database“ aus, um dem Arbeitsbereich eine neue „Lake database“ hinzuzufügen.
Hinweis: Sie werden aufgefordert, den Nutzungsbedingungen für die Azure Synapse-Datenbankvorlage zuzustimmen, die Sie lesen und verstehen sollten, bevor Sie auf die Schaltfläche OK klicken.
- Legen Sie im Bereich „Eigenschaften“ für die neue „Lake database“ (rechts) die folgenden Eigenschaften fest:
- Name: lakedb
- Eingabeordner: Navigieren Sie zu root/files/data
Tipp: Wenn beim Öffnen des Eingabeordners eine Fehlermeldung angezeigt wird, doppelklicken Sie einfach auf den Stammordner und arbeiten Sie sich bis zu den Daten vor, bevor Sie auf OK klicken, falls dies der Fall ist.
- Wählen Sie im linken Bereich „Tabellen“ im Menü „+ Tabelle“ die Option „Aus Datenpool“ aus. Fügen Sie dann eine neue Tabelle mit den folgenden Eigenschaften hinzu:
- Name der externen Tabelle: Produkte
- Verknüpfter Dienst: synapsexxxxxxx-WorkspaceDefaultStorage(datalakexxxxxxx)
- Eingabedatei oder -ordner: files/data/products.csv
-
Klicken Sie auf Weiter und wählen Sie im Bereich Neue externe Tabelle die Option „Erste Zeile“, um Spaltennamen abzuleiten, und klicken Sie auf Erstellen.
- Wählen Sie oben im Fenster „Lake database“ die Option „Veröffentlichen“, um die Änderungen zu speichern.
- Erweitern Sie im Bereich „Daten“ den Abschnitt „Lake database“, erweitern Sie „lakedb“ und wählen Sie dann in der Tabelle „Produkte“ das Menü … und wählen Sie „SQL-Skript erstellen“ > „Top 100 Zeilen“.
- Stellen Sie sicher, dass „Verbinden mit“ als „Integriert“ aufgeführt ist, aktualisieren Sie die Liste „Datenbank verwenden“ und wählen Sie „lakedb“ aus.
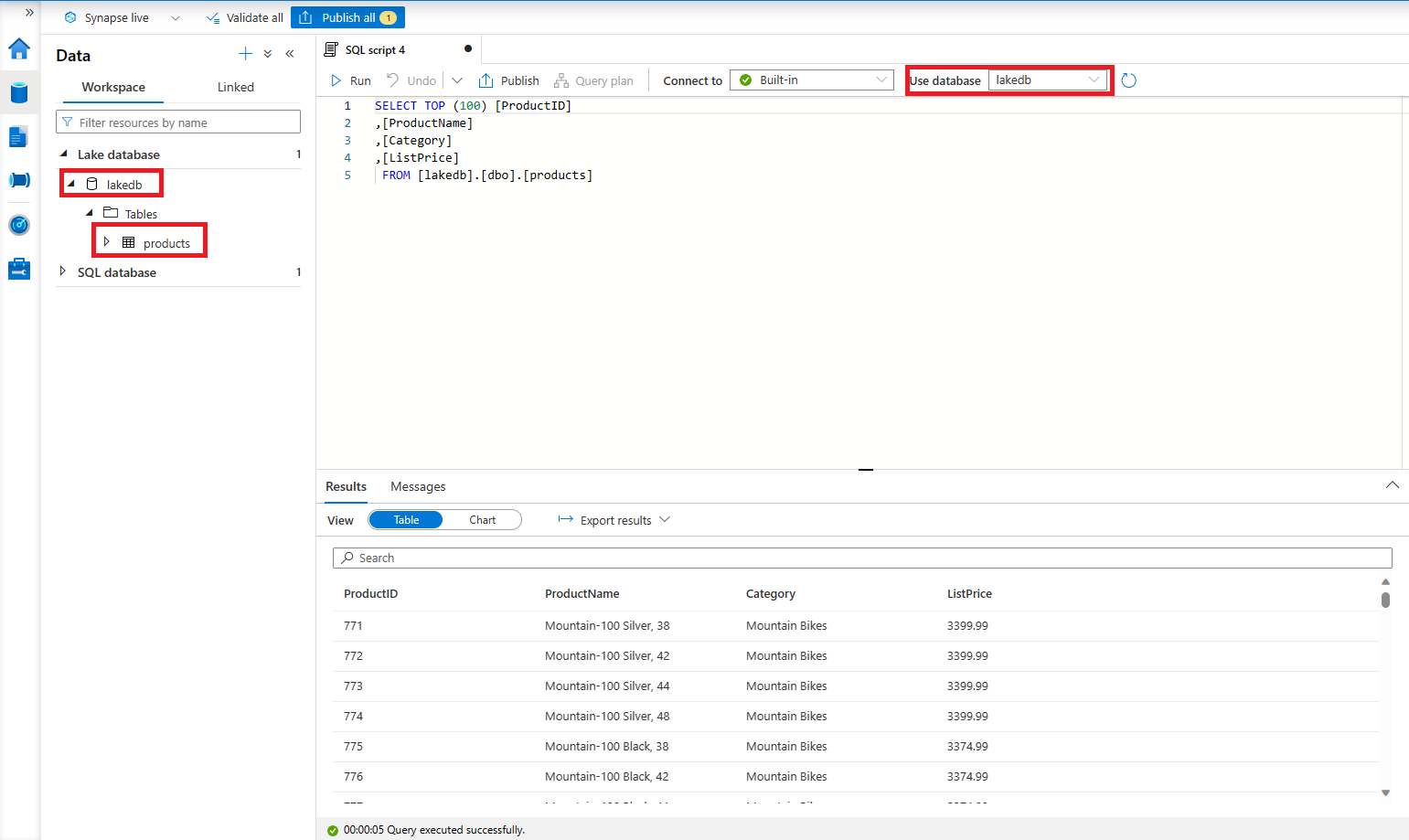
- Verwenden Sie die Schaltfläche „Ausführen“, um die Abfrage auszuführen und die Daten in der Tabelle „Produkte“ anzuzeigen.
Ein Microsoft Purview-Dienstkonto hinzufügen und konfigurieren
Microsoft Purview ist ein umfassendes Portfolio von Produkten, das Datengovernance, Informationsschutz, Risikomanagement und Compliancelösungen beinhaltet. Es hilft Ihnen, Ihre gesamten Datenbestände in Ihren lokalen, Multi-Cloud- und Software-as-a-Service-Daten (SaaS) zu verwalten, zu schützen und zu verwalten.
Ein Microsoft Purview-Konto bereitstellen
Beachten Sie, dass die Ressourcen innerhalb eines einzelnen Azure-Mandanten begrenzt sind. Wenn der von Ihnen verwendete Mandant sein Kontingent an Azure Purview-Instanzen bereits aufgebraucht hat, können Sie keine neue Instanz erstellen. Wenn möglich, können Sie für den Rest dieser Übung eine vorhandene Microsoft Purview-Ressource verwenden.
- Kehren Sie zum Browser-Tab mit dem Azure-Portal zurück und zeigen Sie die Ressourcengruppe dp203-xxxxxxx an.
- Verwenden Sie die Schaltfläche „+ Erstellen“, um der Ressourcengruppe eine neue Microsoft Purview-Ressource mit den folgenden Einstellungen hinzuzufügen:
- Abonnement:Wählen Sie Ihr Abonnement aus.
- Ressourcengruppe: dp203-xxxxxxx
- Microsoft Purview-Kontoname: purviewxxxxxxx**(wobei *xxxxxxx Ihr eindeutiges Suffix ist)*
- Ort: Wählen Sie eine verfügbare Region
Hinweis: Möglicherweise müssen Sie einige Regionen ausprobieren, damit die Prüfung von Purview bestanden wird.
- Warten Sie, bis die Ressource erstellt wurde, und kehren Sie dann zur Ressourcengruppe dp203-xxxxxxx zurück. Stellen Sie sicher, dass sie aufgeführt ist (möglicherweise müssen Sie die Seite aktualisieren).
Konfigurieren des rollenbasierten Zugriffs für Microsoft Purview
Microsoft Purview ist für die Verwendung einer verwalteten Identität konfiguriert. Um Datenressourcen zu katalogisieren, muss dieses Konto mit verwalteter Identität Zugriff auf den Azure Synapse Analytics-Arbeitsbereich und das Speicherkonto für seinen Data Lake-Speicher haben.
- Überprüfen Sie in der Ressourcengruppe dp203-xxxxxxx die von Ihnen erstellten Ressourcen. Dazu gehören:
- Ein Speicherkonto, dessen Name datalakexxxxxxx ähnelt.
- Ein Microsoft Purview-Konto, dessen Name purviewxxxxxxx ähnelt.
- Ein dedizierter SQL-Pool, dessen Name sqlxxxxxxx ähnelt.
- Ein Synapse-Arbeitsbereich, dessen Name synapsexxxxxxx ähnelt.
-
Öffnen Sie das Speicherkonto datalakexxxxxxx, und zeigen Sie auf der Seite Zugriffssteuerung (IAM) die Registerkarte Rollenzuweisungen an, wie hier gezeigt:
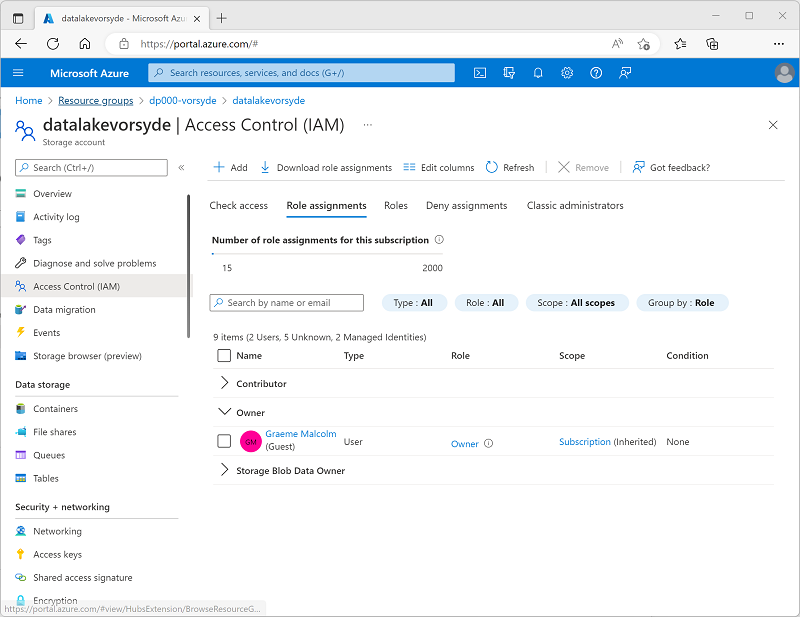
- Wählen Sie im Menü der Schaltfläche + Hinzufügen die Option Rollenzuweisung hinzufügen aus.
-
Suchen Sie auf der Seite Rollenzuweisung hinzufügen auf der Registerkarte Rolle nach „Speicherblob“ und wählen Sie die Rolle Speicherblob-Datenleser aus. Wählen Sie dann Weiter aus, um zur Registerkarte Mitglieder zu navigieren.
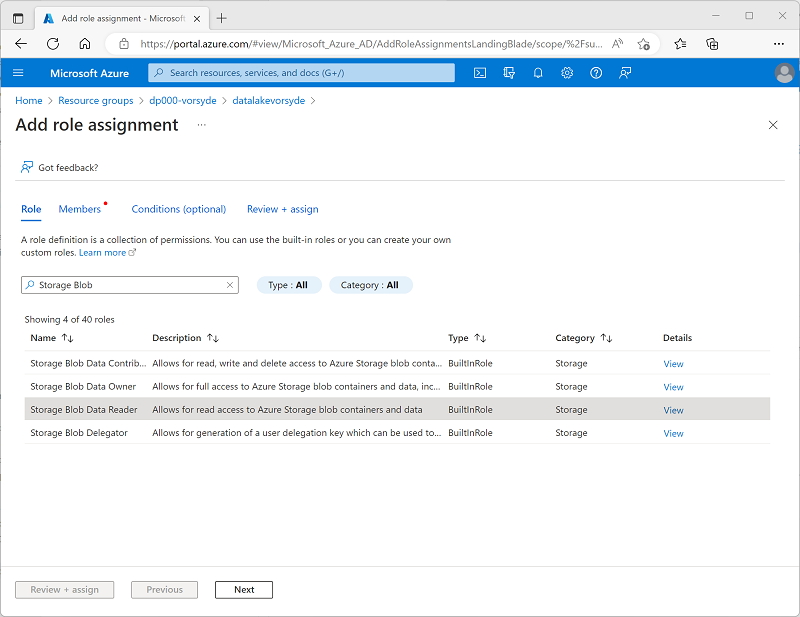
- Wählen Sie auf der Registerkarte Mitglieder in der Liste Zugriff zuweisen an die Option Verwaltete Identität aus. Wählen Sie dann unter Mitglieder die Option Mitglieder auswählen aus.
-
Wählen Sie im Bereich Verwaltete Identitäten auswählen in der Liste Verwaltete Identitäten die Option Microsoft Purview-Konto (n) aus, und wählen Sie Ihr Microsoft Purview-Konto aus, dessen Name purviewxxxxxxx ähneln sollte. Verwenden Sie die Schaltfläche Auswählen, um dieses Konto der Rollenzuweisung hinzuzufügen:
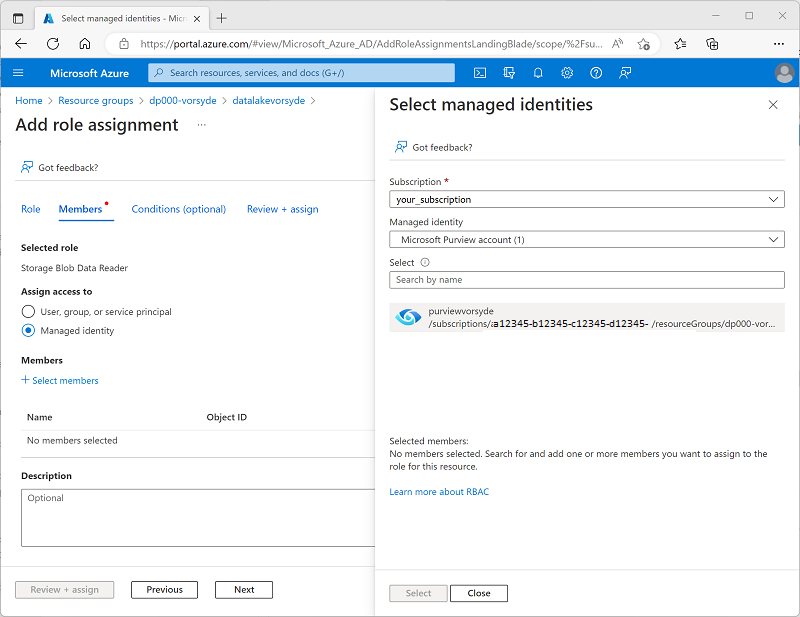
- Verwenden Sie die Schaltfläche Überprüfen und Zuweisen, um die Rollenzuweisung abzuschließen. Dadurch wird das Konto purviewxxxxxxx, das von der verwalteten Identität für Ihre Microsoft Purview-Ressource verwendet wird, zum Mitglied der Rolle Speicherblob-Datenleser für Ihr Speicherkonto.
- Kehren Sie im Azure-Portal zur Ressourcengruppe dp203-xxxxxxx zurück, und öffnen Sie den Synapse Analytics-Arbeitsbereich synapsexxxxxxx. Fügen Sie dann auf der Seite Zugriffssteuerung (IAM) eine Rollenzuweisung hinzu, um das Konto mit verwalteter Identität purviewxxxxxxx als Mitglied der Rolle Leser im Arbeitsbereich festzulegen.
Konfigurieren der Datenbank-Berechtigungen für Microsoft Purview
Ihr Azure Synapse Analytics-Arbeitsbereich enthält Datenbanken sowohl in serverlosen als auch in dedizierten SQL-Pools, auf die die von Microsoft Purview verwendete verwaltete Identität Zugriff benötigt.
- Wechseln Sie zurück zum Browser-Tab mit Azure Synapse Studio. Rufen Sie dann die Seite „Daten“ auf, um die Datenbanken in Ihrem Arbeitsbereich anzuzeigen. Diese sollten folgende umfassen:
- Eine „Lake database“ mit dem Namen lakedb.
- Eine dedizierte SQL-Pool-Datenbank mit dem Namen sqlxxxxxxx.
- Wählen Sie die Datenbank lakedb aus, und wählen Sie dann im Menü … Neues SQL-Skript > Leeres Skript aus, um einen neuen Bereich mit dem Namen SQL-Skript 1 zu öffnen. Sie können die Schaltfläche Eigenschaften (die 🗏* ähnelt) am rechten Ende der Symbolleiste verwenden, um den Bereich Eigenschaften auszublenden, damit Sie den Skriptbereich besser sehen können.
-
Geben Sie im Bereich SQL-Skript 1 den folgenden SQL-Code ein, wodurch alle Instanzen von purviewxxxxxxx durch den Namen der verwalteten Identität für Ihr Microsoft Purview-Konto ersetzt werden:
CREATE LOGIN [purviewxxxxxxx] FROM EXTERNAL PROVIDER; GO CREATE USER [purviewxxxxxxx] FOR LOGIN [purviewxxxxxxx]; GO ALTER ROLE db_datareader ADD MEMBER [purviewxxxxxxx]; GO - Verwenden Sie die Schaltfläche ▷ Ausführen, um das Skript auszuführen, das einen Login und einen Benutzer im lakedb-Benutzer für die von Microsoft Purview verwendete verwaltete Identität erstellt und den Benutzer der db_datareader-Rolle in der lakedb-Datenbank hinzufügt.
-
Erstellen Sie ein neues leeres Skript für die dedizierte SQL-Pool-Datenbank sqlxxxxxxx, und verwenden Sie es, um den folgenden SQL-Code auszuführen (ersetzen Sie purviewxxxxxxxxx durch den Namen der verwalteten Identität für Ihr Microsoft Purview-Konto). Dadurch wird ein Benutzer im dedizierten SQL-Pool für die von Microsoft Purview verwendete verwaltete Identität erstellt und der Rolle db_datareader in der Datenbank sqlxxxxxxx hinzugefügt.
CREATE USER [purviewxxxxxxx] FROM EXTERNAL PROVIDER; GO EXEC sp_addrolemember 'db_datareader', [purviewxxxxxxx]; GO
Verwenden Sie Microsoft Purview, um Datenressourcen zu scannen
Nachdem Sie nun den erforderlichen Zugriff für Microsoft Purview konfiguriert haben, um die von Ihrem Azure Synapse Analytics-Arbeitsbereich verwendeten Datenquellen zu scannen, können Sie sie in Ihrem Microsoft Purview-Katalog registrieren.
Registrieren von Quellen im Microsoft Purview-Katalog
Mit Microsoft Purview können Sie Datenressourcen in Ihrem gesamten Datenbestand katalogisieren – einschließlich Datenquellen in einem Azure Synapse-Arbeitsbereich. Der soeben bereitgestellte Arbeitsbereich umfasst einen Data Lake (in einem Azure Data Lake Storage Gen2-Konto), eine Lake-Datenbank und ein Data Warehouse in einem dedizierten SQL-Pool.
- Wechseln Sie zurück zur Browserregisterkarte mit dem Azure-Portal, und zeigen Sie die Seite für die Ressourcengruppe dp203-xxxxxxx an.
-
Öffnen Sie das Microsoft Purview-Konto purviewxxxxxxx, und verwenden Sie den Link auf der Seite Übersicht, um das Microsoft Purview Governanceportal in einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
Tipp: Alternativ können Sie in einer neuen Browserregisterkarte direkt zu https://web.purview.azure.com navigieren.
- Verwenden Sie auf der linken Seite des Azure Purview-Governanceportals das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten im Portal angezeigt.
-
Wählen Sie auf der Seite Datenkarte auf der Unterseite Datenquellen die Option Registrieren aus:
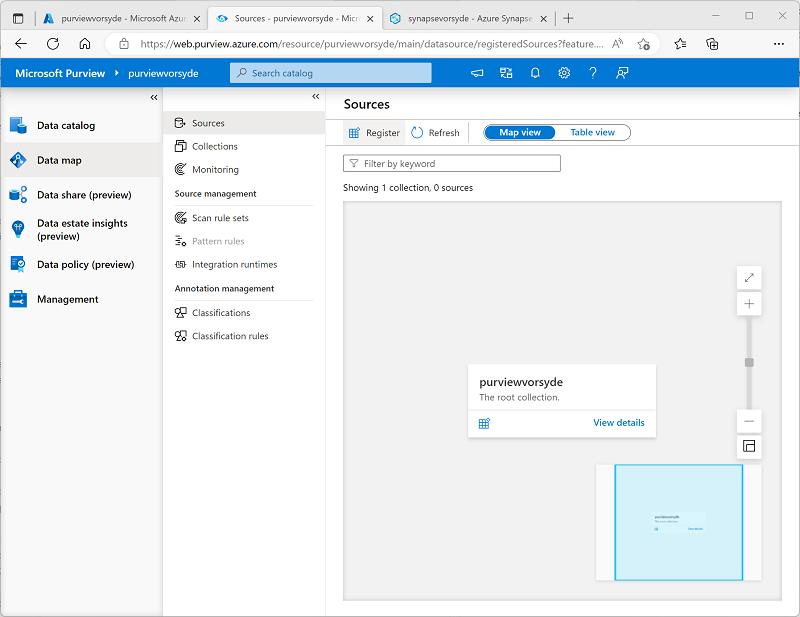
- Wählen Sie auf der nun angezeigten Registerkarte Quellen registrieren die Option Azure Synapse Analytics aus, und registrieren Sie eine Quelle mit den folgenden Einstellungen:
- Name: Synapse_data
- Azure-Abonnement: Wählen Sie Ihr Azure-Abonnement aus.
- Arbeitsbereichsname: Wählen Sie Ihren Arbeitsbereich synapsexxxxxxx aus.
- Dedizierter SQL-Endpunkt: sqlxxxxxxx.sql.azuresynapse.net
- Serverloser SQL-Endpunkt: sqlxxxxxxx-ondemand.sql.azuresynapse.net
- Sammlung auswählen: Stamm (purviewxxxxxxx)
Diese Datenquelle enthält die SQL-Datenbanken in Ihrem Azure Synapse Analytics-Arbeitsbereich.
- Nachdem Sie die Quelle Synapse_data registriert haben, wählen Sie Registrieren erneut aus, und registrieren Sie eine zweite Quelle für den Data Lake-Speicher, der von Ihrem Azure Synapse-Arbeitsbereich verwendet wird. Wählen Sie Azure Data Lake Storage Gen2 aus, und geben Sie die folgenden Einstellungen an:
- Name: Data_lake
- Azure-Abonnement: Wählen Sie Ihr Azure-Abonnement aus.
- Arbeitsbereichsname: Wählen Sie Ihr Speicherkonto datalakexxxxxxx aus.
- Endpunkt: https:/ /datalakexxxxxxx.dfs.core.windows.net/
- Sammlung auswählen: Stamm (purviewxxxxxxx)
- Verwaltung der Datennutzung: Deaktiviert
Nachdem Sie sowohl die Quelle Synapse_data als auch die Quelle Data_lake registriert haben, sollten beide unter der Stammsammlung purviewxxxxxxx in der Datenzuordnung angezeigt werden, wie hier gezeigt:
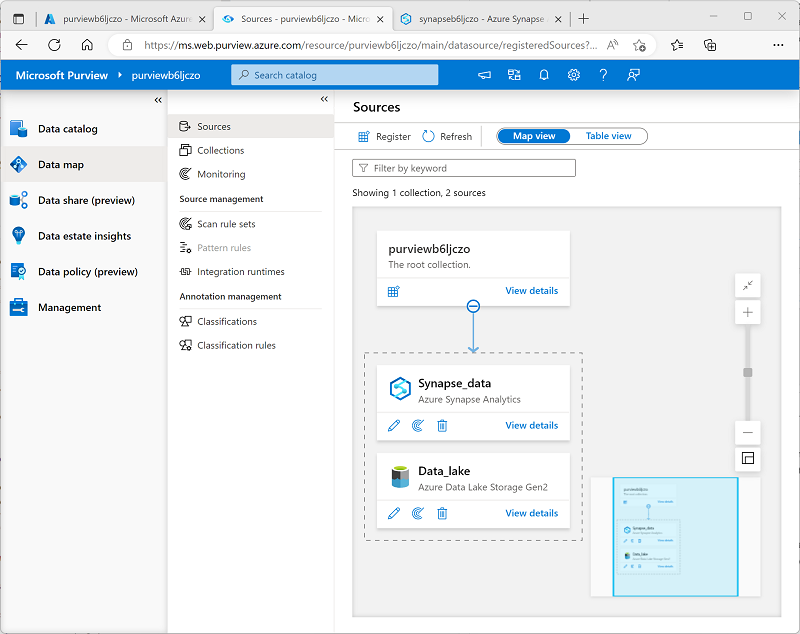
Scannen von registrierten Quellen
- Wählen Sie in der Datenzuordnung in der Quelle Synapse_data Details anzeigen aus, und beachten Sie, dass die Quelle keine katalogisierten Ressourcen enthält. Sie müssen die Quelle scannen, um die darin enthaltenen Datenressourcen zu finden.
- Wählen Sie auf der Detailseite Synapse_data die Option Neuer Scan aus, und konfigurieren Sie dann einen Scan mit den folgenden Einstellungen:
- Name: Scan-Synapse
- Mit Integration Runtime verbinden: Azure AutoresolveIntegrationRuntime
- Typ: SQL-Datenbank
- Anmeldeinformationen: Microsoft Purview MSI (System)
- * SQL-Datenbank: *Wählen Sie sowohl die dedizierte Datenbank **sqlxxxxxxx als auch die serverlose Datenbank lakedb aus.
- Sammlung auswählen: Stamm (purviewxxxxxxx)
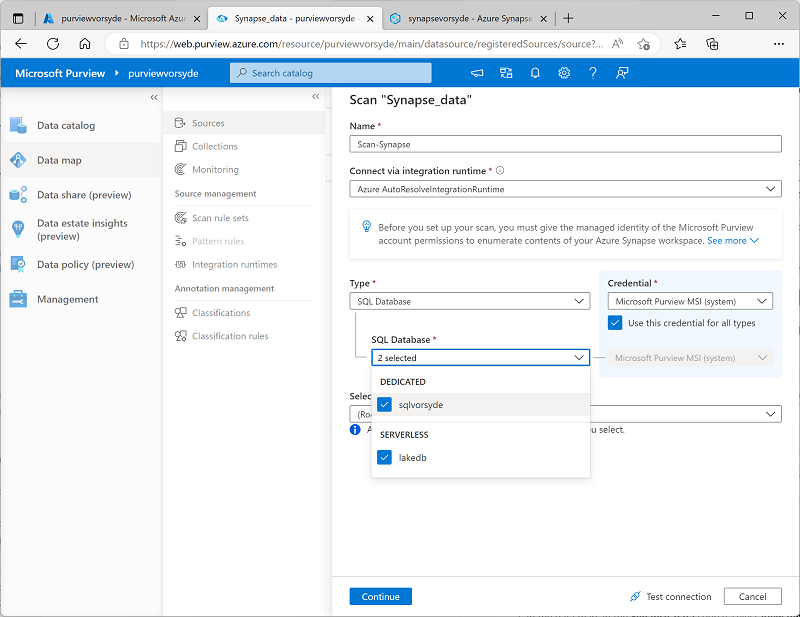
- Fahren Sie mit der Seite Scanregelsatz auswählen fort, auf der der standardmäßige Regelsatz AzureSynapseSQL ausgewählt sein sollte.
- Fahren Sie mit der Seite Scantrigger festlegen fort, und wählen Sie Einmal aus, um den Scan einmal auszuführen.
- Fahren Sie mit der Seite Ihren Scan überprüfen fort, und speichern Sie den Scan, und führen Sie ihn aus.
- Während der Scan Synapse_data ausgeführt wird, kehren Sie zur Seite Quellen zurück, um die Datenzuordnung anzuzeigen, und verwenden Sie in der Quelle Data_lake das Symbol Neuer Scan, um einen Scan des Data Lakes mit den folgenden Einstellungen zu starten:
- Name: Scan-Data-Lake
- Mit Integration Runtime verbinden: Azure AutoresolveIntegrationRuntime
- Anmeldeinformationen: Microsoft Purview MSI (System)
- Sammlung auswählen: Stamm (purviewxxxxxxx)
- Bereich des Scans: Wählen Sie Data_lake und alle Unterressourcen aus.
- Scanregelsatz auswählen: AdlsGen2
- Überprüfungstrigger festlegen: Einmal
- Ihren Scan überprüfen: Speichern und ausführen
-
Warten Sie, bis beide Scans abgeschlossen sind. Dieser Vorgang kann mehrere Minuten dauern. Sie können die Detailseite für jede einzelne Quelle anzeigen, um den Status der letzten Ausführung anzuzeigen, wie unten dargestellt (Sie können die Schaltfläche ↻ Aktualisieren verwenden, um den Status zu aktualisieren). Sie können auch die Seite Überwachen anzeigen (es kann jedoch einige Zeit dauern, bis die Scans dort angezeigt werden):
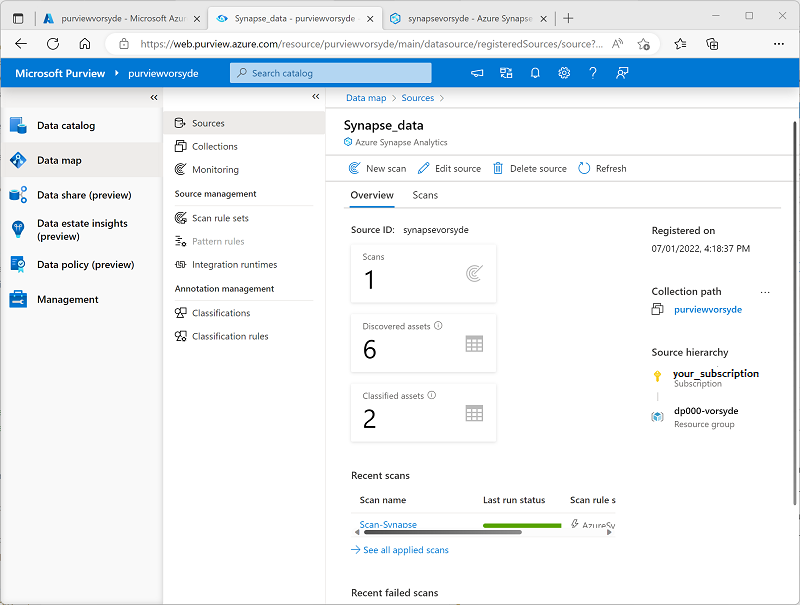
Anzeigen der gescannten Ressourcen
- Wählen Sie auf der Seite Datenkatalog auf der Unterseite Durchsuchen die Sammlung purviewxxxxxxx aus. Hier sehen Sie die Datenressourcen, die in Ihrem Azure Synapse-Arbeitsbereich und Data Lake-Speicher katalogisiert wurden, einschließlich des Azure Synapse Analytics-Arbeitsbereichs, des Azure Storage-Kontos für den Data Lake, der beiden SQL-Pool-Datenbanken in Azure Synapse Analytics, des Schemas dbo in jeder Datenbank, der Tabellen und Ansichten in den Datenbanken sowie der Ordner und Dateien im Data Lake.
-
Um die Ergebnisse zu filtern, wählen Sie in der Liste der Objekttypen Ergebnisse filtern nach die Optionen Dateien und Tabellen aus, sodass nur die Dateien, Tabellen und Ansichten aufgelistet werden, die durch den Scan katalogisiert wurden:
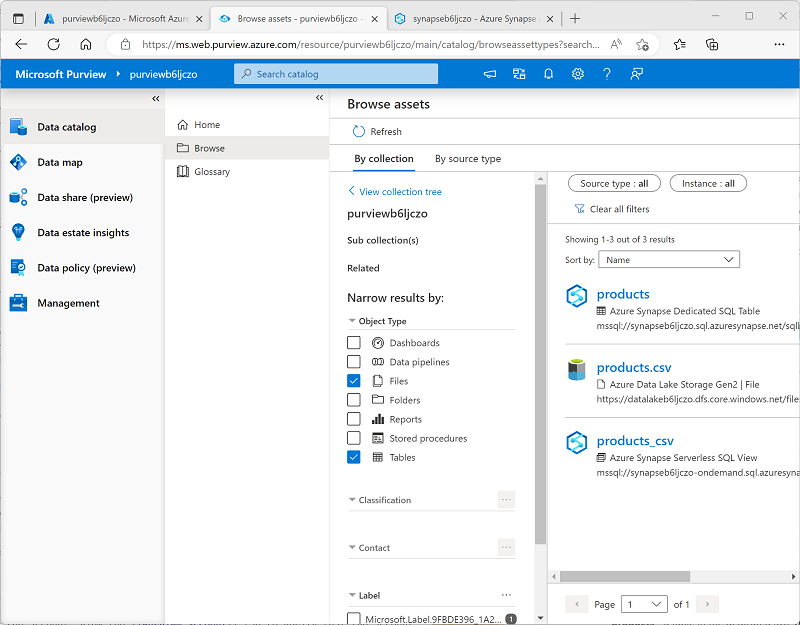
Beachten Sie, dass die Datenressourcen Folgendes enthalten:
- products – eine Tabelle im dedizierten SQL-Pool für Produktdaten.
- products.csv – eine Datei im Data Lake.
- products_csv – eine Ansicht im serverlosen SQL-Pool, die Produktdaten aus der Datei products.csv liest.
- Erkunden Sie die gefundenen Ressourcen, indem Sie sie auswählen und deren Eigenschaften und Schema anzeigen. Sie können die Eigenschaften der Ressourcen (einschließlich einzelner Felder) bearbeiten, um Metadaten, Kategorisierungen, Kontaktdetails für Fachexperten und andere nützliche Details hinzuzufügen, damit Datenanalysten viele Informationen zu den Datenressourcen in Ihrem Datenbestand finden können, indem Sie sie im Microsoft Purview-Datenkatalog untersuchen.
Bisher haben Sie Microsoft Purview zum Katalogisieren von Datenressourcen in Ihrem Azure Synapse Analytics-Arbeitsbereich verwendet. Sie können mehrere Arten von Datenquellen in einem Microsoft Purview-Katalog registrieren und dadurch eine zentrale, konsolidierte Ansicht von Datenressourcen erstellen.
Sehen wir uns nun einige andere Möglichkeiten zur Integration von Azure Synapse Analytics und Microsoft Purview an.
Integrieren von Microsoft Purview in Azure Synapse Analytics
Azure Synapse Analytics unterstützt die Integration in Microsoft Purview, um Datenressourcen auffindbar zu machen und die Datenherkunft über Erfassungspipelines nachzuverfolgen, die Daten von einer Quelle in eine andere übertragen.
Aktivieren der Microsoft Purview-Integration in Azure Synapse Analytics
- Wechseln Sie zurück zur Browserregisterkarte mit Synapse Studio, und wählen Sie auf der Seite Verwalten die Registerkarte Microsoft Purview aus. Verwenden Sie dann die Schaltfläche Mit einem Purview-Konto verbinden, um das Konto purviewxxxxxxx in Ihrem Abonnement mit dem Arbeitsbereich zu verbinden.
-
Zeigen Sie nach dem Verbinden des Kontos die Registerkarte Purview-Konto an, um zu überprüfen, ob der Status Datenherkunft – Synapse Pipeline für das Konto Verbunden lautet:
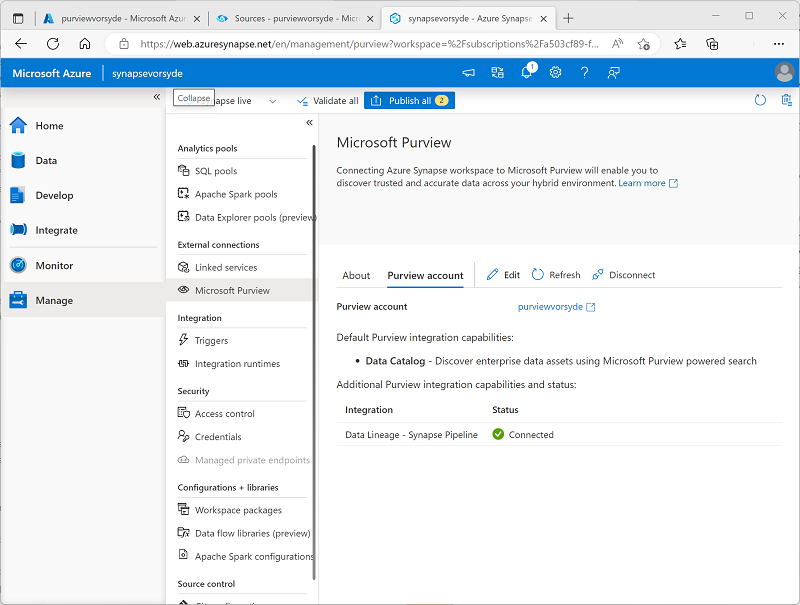
Durchsuchen des Purview-Katalogs in Synapse Studio
Nachdem Sie Ihr Microsoft Purview-Konto nun mit Ihrem Azure Synapse Analytics-Arbeitsbereich verbunden haben, können Sie den Katalog von Synapse Studio aus durchsuchen, sodass Sie Datenressourcen in Ihrem gesamten Datenbestand ermitteln können.
- Navigieren Sie in Synapse Studio zur Seite Integrieren.
-
Verwenden Sie oben auf der Seite das Feld Suche, um die Quelle Purview nach dem Begriff „Produkte“ zu durchsuchen, wie hier gezeigt:
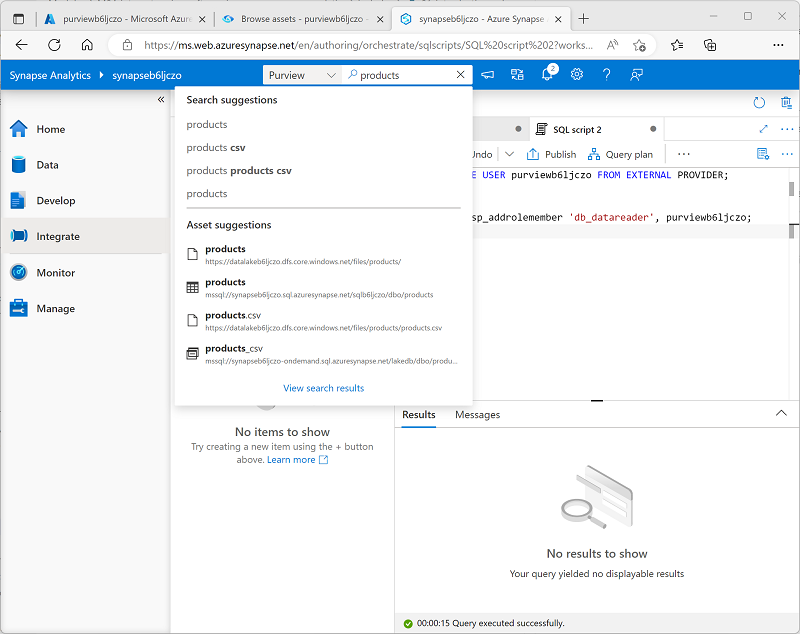
- Wählen Sie in den Ergebnissen products.csv aus, um die Details aus dem Purview-Katalog anzuzeigen.
Durch die Integration des Purview-Katalogs in die Synapse Studio-Schnittstelle können Datenanalysten und technische Fachkräfte für Daten registrierte Datenressourcen aus dem gesamten Datenbestand (nicht nur innerhalb des Azure Synapse Studio-Arbeitsbereichs) finden und untersuchen.
Erstellen und Ausführen einer Pipeline
Die Ansicht products_csv in der Datenbank lakedb basiert auf einer Textdatei im Data Lake, die Produktdaten enthält. Die Tabelle Produkte in der dedizierten SQL-Datenbank sqlxxxxxxx ist zurzeit leer. Verwenden wir eine Synapse-Pipeline, um Daten aus dem Data Lake in die Tabelle zu laden.
- Wählen Sie in Synapse Studio auf der Seite Integrieren im Menü + das Tool Daten kopieren aus.
- Wählen Sie im Tool „Daten kopieren“ die Optionen Integrierte Kopieraufgabe und Jetzt einmal ausführen aus, und wählen Sie dann Weiter aus.
- Wählen Sie auf der Seite Quellendatenspeicher in der Liste Verbindung die Verbindung synapsexxxxxxx-WorkspaceDefaultStorage aus (die auf den Data Lake für den Arbeitsbereich verweist), und navigieren Sie für die Datei oder den Ordner zur Datei files/products/products.csv. Wählen Sie dann Weiter aus.
- Wählen Sie auf der Seite Dateiformateinstellungen die Option Textformat erkennen aus. Stellen Sie dann sicher, dass die folgenden Einstellungen angegeben sind, bevor Sie Weiter auswählen:
- Dateiformat: DelimitedText
- Spaltentrennzeichen: Komma (,)
- Zeilen-Trennzeichen: Zeilenvorschub (\n)
- Erste Zeile ist Überschrift: Ausgewählt
- Komprimierungstyp: Keiner
- Wählen Sie auf der Seite Zieldatenspeicher in der Liste Verbindung die Option sqlxxxxxxx (die Verbindung mit Ihrem dedizierten SQL-Pool) aus. Legen Sie dann das Ziel auf die vorhandene Tabelle dbo.products fest, und wählen Sie Weiter aus.
- Überprüfen Sie auf der Seite Spaltenzuordnung die Standard-Spaltenzuordnungen, und wählen Sie dann Weiter aus.
- Legen Sie auf der Seite Einstellungen den Aufgabennamen auf Load_Product_Data fest. Wählen Sie dann die Kopiermethode Einfügen per Massenvorgang aus, und wählen Sie Weiter aus.
- Wählen Sie auf der Seite Zusammenfassung die Option Weiter aus.
- Warten Sie, bis die Pipeline bereitgestellt wird, und wählen Sie dann Fertigstellen aus.
- Zeigen Sie in Synapse Studio die Seite Überwachen an. Beobachten Sie dann auf der Registerkarte Pipelineausführungen den Status der Pipeline Load_Product_Data. Es kann einige Minuten dauern, bis der Status zu Erfolgreich wechselt.
- Wenn die Pipelineausführung erfolgreich abgeschlossen wurde, wählen Sie ihren Namen (Load_Product_Data) aus, um Details der Aktivitäten in der Pipeline anzuzeigen. Beachten Sie, dass die Pipeline die Aufgabe Daten kopieren mit einem automatisch abgeleiteten Namen enthält, der Copy_* xxx* ähnelt. Diese Aktivität hat die Daten aus der Textdatei im Data Lake in die Tabelle Produkte in der Datenbank sqlxxxxxxx kopiert.
Anzeigen der Datenherkunft in Microsoft Purview
Sie haben eine Synapse-Pipeline zum Laden von Daten in eine Datenbank verwendet. Überprüfen wir, ob diese Aktivität in Microsoft Purview nachverfolgt wurde.
- Wechseln Sie zur Browserregisterkarte mit dem Microsoft Purview-Governanceportal.
- Wählen Sie auf der Seite Datenkatalog auf der Unterseite Durchsuchen die Sammlung purviewxxxxxxx aus.
- Filtern Sie die Ressourcen, um nur Datenpipelines, Dateien und Tabellen anzuzeigen. Die Liste der Ressourcen sollte die Datei products.csv, die Pipelineaktivität Copy_xxx und die Tabelle Produkte enthalten.
- Wählen Sie die Ressource Copy_xxx aus, um ihre Details anzuzeigen, wobei die Aktualisierte Zeit die letzte Pipelineausführung widerspiegelt.
-
Zeigen Sie auf der Registerkarte Herkunft für die Ressource Copy_xxx das Diagramm an, das den Datenfluss aus der Datei products.csv in die Tabelle Produkte zeigt:
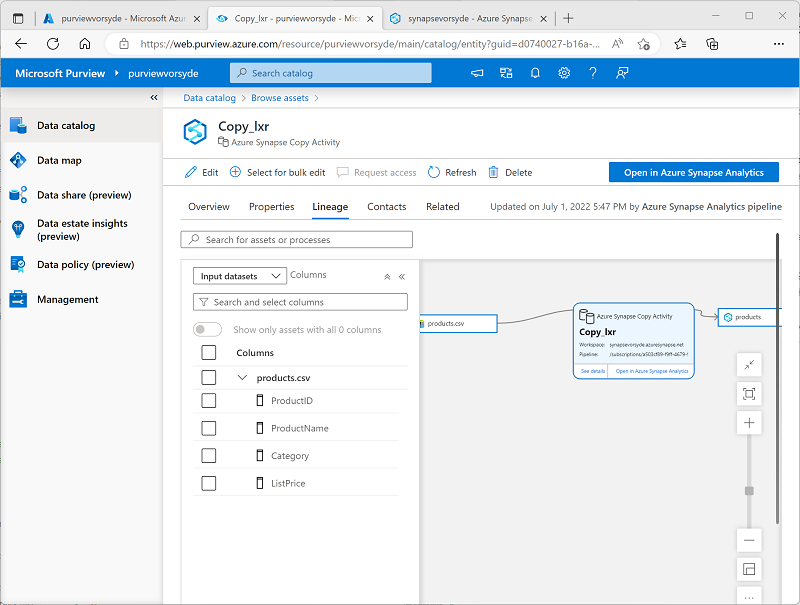
- Wählen Sie im Herkunftsdiagramm Copy_xxx die Datei products.csv aus, und verwenden Sie den Link Zur Ressource wechseln, um Details der Quelldatei anzuzeigen.
- Wählen Sie im Herkunftsdiagramm products.csv die Tabelle Produkte aus, und verwenden Sie den Link Zur Ressource wechseln, um Details der Tabelle anzuzeigen (Möglicherweise müssen Sie die Schaltfläche ↻ Aktualisieren verwenden, um das Herkunftsdiagramm der Tabelle anzuzeigen).
Die Integration von Azure Synapse Analytics in Microsoft Purview ermöglicht die Funktionalität zur Nachverfolgung der Herkunft, mit der Sie ermitteln können, wie und wann die Daten in Ihren Datenspeichern geladen wurden und woher sie stammen.
Tipp: In dieser Übung haben Sie die Herkunftsinformationen im Microsoft Purview Governanceportal angezeigt. Denken Sie jedoch daran, dass dieselben Ressourcen auch in Synapse Studio über die Funktion zur Suchintegration angezeigt werden können.
Anhalten des dedizierten SQL-Pools
- Wechseln Sie zurück zur Registerkarte mit Synapse Studio, und halten Sie auf der Seite Verwalten den dedizierten SQL-Pool sqlxxxxxxx an.
Löschen von Azure-Ressourcen
Wenn Sie sich mit Azure Synapse Analytics vertraut gemacht haben, sollten Sie die erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden.
- Schließen Sie die Registerkarte mit Synapse Studio, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressourcengruppen aus.
- Wählen Sie die Ressourcengruppe dp203-xxxxxxx für Ihren Synapse Analytics-Arbeitsbereich aus (nicht die verwaltete Ressourcengruppe), und vergewissern Sie sich, dass sie den Synapse-Arbeitsbereich, das Speicherkonto und den dedizierten SQL-Pool für Ihren Arbeitsbereich enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe dp203-xxxxxxx ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach einigen Minuten werden die Ressourcengruppe in Ihrem Azure Synapse-Arbeitsbereich und die damit verknüpfte Ressourcengruppe im verwalteten Arbeitsbereich gelöscht.