Verwenden von Azure Synapse Link für Azure Cosmos DB
Bei Azure Synapse Link für Azure Cosmos DB handelt es sich um eine cloudnative HTAP-Technologie (Hybrid Transactional Analytical Processing), mit deren Hilfe in Azure Cosmos DB gespeicherte operative Daten in Quasi-Echtzeit analysiert werden können.
Diese Übung dauert ca. 35 Minuten.
Vor der Installation
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen von Azure-Ressourcen
Um Azure Synapse Link für Azure Cosmos DB zu erkunden, benötigen Sie einen Azure Synapse Analytics-Arbeitsbereich und ein Azure Cosmos DB-Konto. In dieser Übung verwenden Sie eine Kombination aus einem PowerShell-Skript und einer ARM-Vorlage, um diese Ressourcen in Ihrem Azure-Abonnement bereitzustellen.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie rechts neben der Suchleiste oben auf der Seite die Schaltfläche [>_], um eine neue Cloud Shell-Instanz im Azure-Portal zu erstellen. Wählen Sie eine PowerShell-Umgebung aus, und erstellen Sie Speicher, falls Sie dazu aufgefordert werden. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
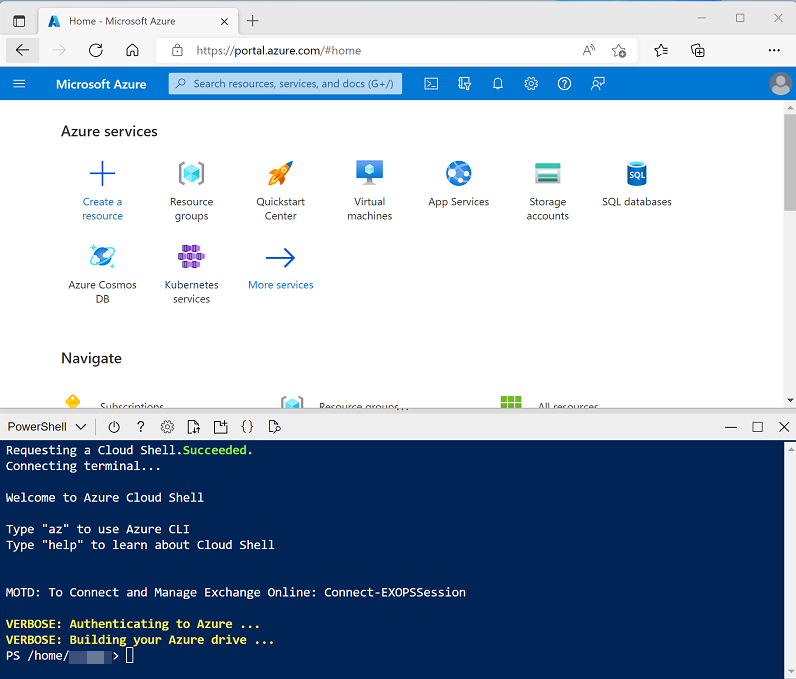
Hinweis: Wenn Sie zuvor eine Cloud Shell erstellt haben, die eine Bash-Umgebung verwendet, ändern Sie diese mithilfe des Dropdownmenüs oben links im Cloud Shell-Bereich zu PowerShell.
-
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern können oder den Bereich mithilfe der Symbole —, ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Nachdem das Repository geklont wurde, geben Sie die folgenden Befehle ein, um in den Ordner für diese Übung zu wechseln. Führen Sie das darin enthaltene Skript setup.ps1 aus:
cd dp-203/Allfiles/labs/14 ./setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
-
Wenn Sie dazu aufgefordert werden, geben Sie ein geeignetes Kennwort ein, das für Ihren Azure Synapse SQL-Pool festgelegt werden soll.
Hinweis: Merken Sie sich unbedingt dieses Kennwort!
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 10 Minuten, in einigen Fällen kann es jedoch länger dauern. Während Sie warten, lesen Sie den Artikel Was ist Azure Synapse Link für Azure Cosmos DB? in der Dokumentation zu Azure Synapse Analytics.
Konfigurieren von Synapse Link in Azure Cosmos DB
Bevor Sie Synapse Link für Azure Cosmos DB verwenden können, müssen Sie es in Ihrem Azure Cosmos DB-Konto aktivieren und einen Container als Analysespeicher konfigurieren.
Aktivieren von Azure Synapse Link in Ihrem Cosmos DB-Konto
-
Navigieren Sie im Azure-Portal zur Ressourcengruppe dp203-xxxxxxx, die vom Setupskript erstellt wurde, und identifizieren Sie Ihr Cosmos DB-Konto cosmosxxxxxxxx.
Hinweis: In einigen Fällen hat das Skript möglicherweise versucht, Cosmos DB-Konten in mehreren Regionen zu erstellen. Daher kann es ein oder mehrere Konten in einem Löschzustand geben. Das aktive Konto sollte das Konto mit der größten Zahl am Ende seines Namens sein, z. B. cosmosxxxxxxx3.
-
Öffnen Sie Ihr Azure Cosmos DB-Konto, und wählen Sie die Seite Daten-Explorer auf der linken Seite des Blatts aus.
Wenn das Dialogfeld Willkommen angezeigt wird, schließen Sie es.
-
Verwenden Sie oben auf der Seite Daten-Explorer die Schaltfläche Azure Synapse Link aktivieren, um Synapse Link zu aktivieren.
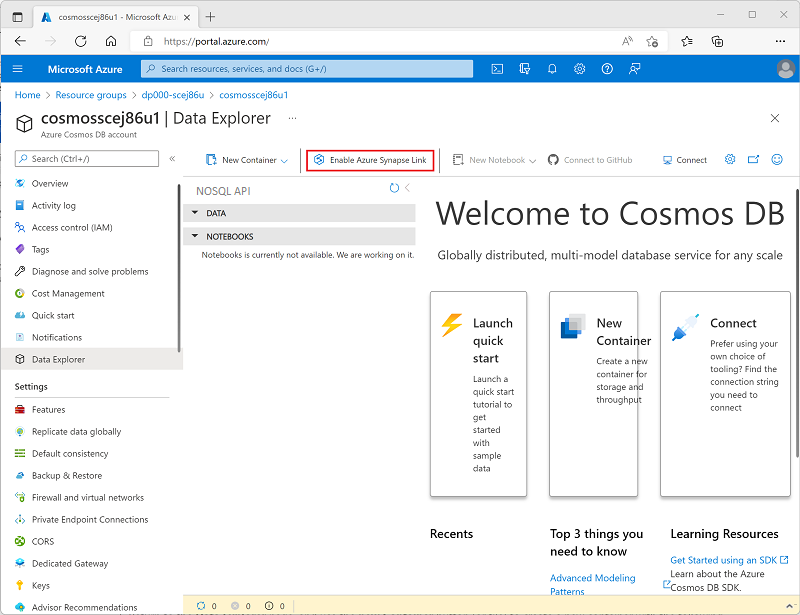
-
Wählen Sie links auf der Seite im Abschnitt Integrationen die Seite Azure Synapse Link aus, und überprüfen Sie, ob der Status des Kontos Aktiviert ist.
Erstellen eines Containers mit analytischem Speicher
- Kehren Sie zur Seite Daten-Explorer zurück, und verwenden Sie die Schaltfläche (oder Kachel) Neuer Container, um einen neuen Container mit den folgenden Einstellungen zu erstellen:
- Datenbank-ID: (Neu erstellen) AdventureWorks
- Durchsatz auf mehrere Container aufteilen: Nicht ausgewählt
- Container-ID: Sales
- Partitionsschlüssel: /customerid
- Containerdurchsatz (Autoskalierung): Autoscale
- Container Max RU/s: 4000
- Analysespeicher: Ein
Hinweis: In diesem Szenario wird customerid als Partitionsschlüssel verwendet, da es wahrscheinlich in vielen Abfragen verwendet wird, um Kunden- und Bestellinformationen in einer hypothetischen Anwendung abzurufen. Außerdem ist die Kardinalität (Anzahl der eindeutigen Werte) dieses Attributs relativ hoch, wodurch der Container entsprechend skaliert werden kann, wenn die Anzahl der Kundinnen bzw. Kunden und Bestellungen steigt. Die Verwendung der Autoskalierung und das Festlegen des Maximalwerts auf 4.000 RU/s ist für eine neue Anwendung mit anfänglich geringen Abfragemengen geeignet. Bei einem maximalen Wert von 4.000 RU/s kann der Container automatisch auf einen Maximalwert von 400 RU/s (10 % des ursprünglichen Werts) herunterskalieren, wenn er nicht verwendet wird.
-
Nachdem der Container erstellt wurde, erweitern Sie auf der Seite Daten-Explorer die Datenbank AdventureWorks und den zugehörigen Ordner Sales, und wählen Sie dann den Ordner Items aus.
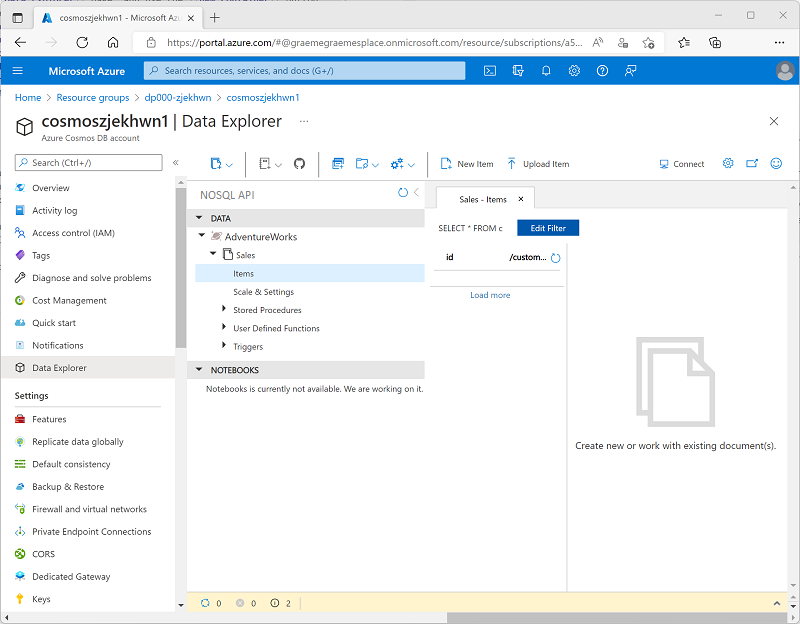
-
Verwenden Sie die Schaltfläche Neues Element, um ein neues Kundenelement basierend auf dem folgenden JSON-Code zu erstellen. Speichern Sie dann das neue Element (einige zusätzliche Metadatenfelder werden hinzugefügt, wenn Sie das Element speichern).
{ "id": "SO43701", "orderdate": "2019-07-01", "customerid": 123, "customerdetails": { "customername": "Christy Zhu", "customeremail": "christy12@adventure-works.com" }, "product": "Mountain-100 Silver, 44", "quantity": 1, "price": 3399.99 } -
Fügen Sie ein zweites Element mit dem folgenden JSON-Code hinzu:
{ "id": "SO43704", "orderdate": "2019-07-01", "customerid": 124, "customerdetails": { "customername": "Julio Ruiz", "customeremail": "julio1@adventure-works.com" }, "product": "Mountain-100 Black, 48", "quantity": 1, "price": 3374.99 } -
Fügen Sie ein drittes Element mit dem folgenden JSON-Code hinzu:
{ "id": "SO43707", "orderdate": "2019-07-02", "customerid": 125, "customerdetails": { "customername": "Emma Brown", "customeremail": "emma3@adventure-works.com" }, "product": "Road-150 Red, 48", "quantity": 1, "price": 3578.27 }
Hinweis: In Wirklichkeit würde der Analysespeicher ein viel größeres Datenvolumen enthalten, das von einer Anwendung in den Speicher geschrieben würde. Diese wenigen Punkte reichen aus, um das Prinzip in dieser Übung zu veranschaulichen.
Konfigurieren von Synapse Link in Azure Synapse Analytics
Nachdem Sie Ihr Azure Cosmos DB-Konto vorbereitet haben, können Sie Azure Synapse Link für Azure Cosmos DB in Ihrem Azure Synapse Analytics-Arbeitsbereich konfigurieren.
- Schließen Sie im Azure-Portal das Blatt für Ihr Cosmos DB-Konto, falls es noch geöffnet ist, und kehren Sie zur Ressourcengruppe dp203-xxxxxxx zurück.
- Öffnen Sie den Synapse-Arbeitsbereich Synapsexxxxxxx, und wählen Sie auf der Seite Übersicht in der Karte Synapse Studio öffnen die Option Öffnen aus, um Synapse Studio in einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
- Verwenden Sie im linken Bereich von Synapse Studio das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten in Synapse Studio angezeigt.
- Zeigen Sie auf der Seite Daten die Registerkarte Verknüpft an. Ihr Arbeitsbereich sollte bereits einen Link zu Ihrem Azure Data Lake Storage Gen2-Speicherkonto enthalten, aber keinen Link zu Ihrem Cosmos DB-Konto.
-
Wählen Sie im Menü + die Option Mit externen Daten verbinden und dann Azure Cosmos DB for NoSQL aus.
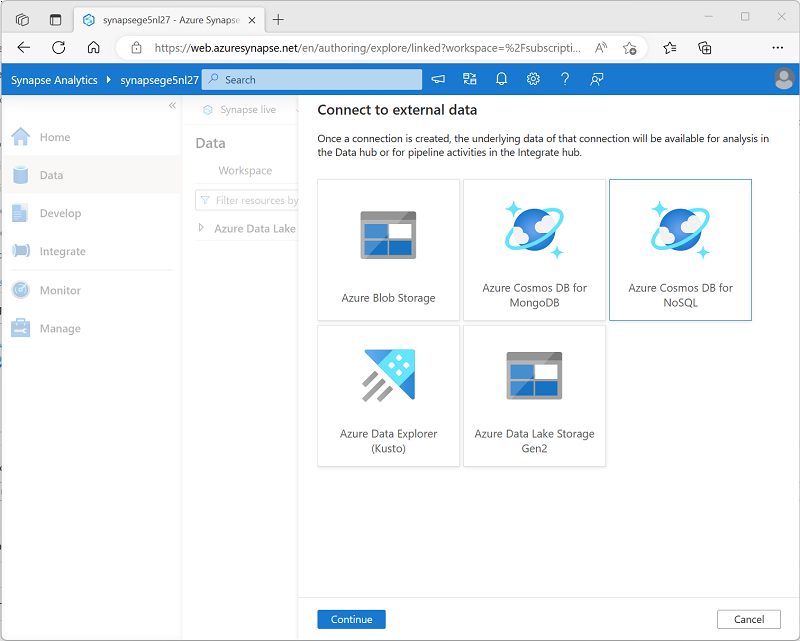
- Fahren Sie fort, und erstellen Sie eine neue Cosmos DB-Verbindung mit den folgenden Einstellungen:
- Name: AdventureWorks
- Beschreibung: AdventureWorks Cosmos DB-Datenbank
- Verbindung über Integration Runtime herstellen: AutoResolveIntegrationRuntime
- Authentifizierungstyp: Kontoschlüssel
- Verbindungszeichenfolge: Ausgewählt
- Kontoauswahlmethode: Aus Abonnement
- Azure-Abonnement: Wählen Sie Ihr Azure-Abonnement aus.
- Azure Cosmos DB-Kontoname: Wählen Sie Ihr cosmosxxxxxxx-Konto aus.
- Datenbankname: AdventureWorks
- Verwenden Sie nach dem Erstellen der Verbindung die Schaltfläche ↻ oben rechts auf der Seite Daten, um die Ansicht zu aktualisieren, bis die Kategorie Azure Cosmos DB im Bereich Verknüpft aufgeführt wird.
-
Erweitern Sie die Kategorie Azure Cosmos DB, um die von Ihnen erstellte Verbindung AdventureWorks und den darin enthaltenen Container Sales anzuzeigen.
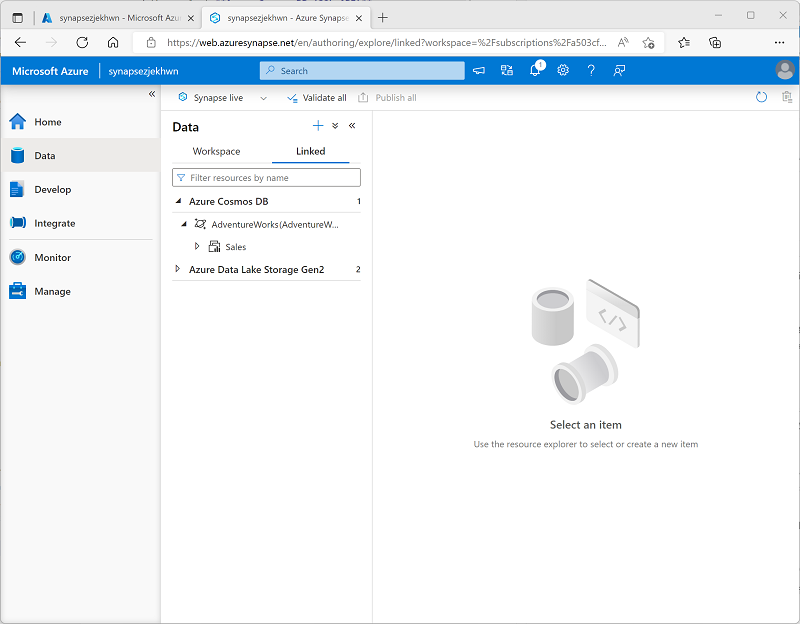
Abfragen von Azure Cosmos DB aus Azure Synapse Analytics
Jetzt können Sie Ihre Cosmos DB-Datenbank aus Azure Synapse Analytics abfragen.
Abfragen von Azure Cosmos DB aus einem Spark-Pool
- Wählen Sie im Bereich Daten den Container Sales und im Menü … die Option Neues Notebook > In DataFrame laden aus.
-
Wählen Sie auf der neuen Registerkarte Notebook 1, die geöffnet wird, in der Liste Anfügen an Ihren Spark-Pool (sparkxxxxxxx) aus. Verwenden Sie dann die Schaltfläche ▷ Alle ausführen, um alle Zellen im Notebook auszuführen (derzeit ist nur eine vorhanden!).
Da Sie Spark-Code zum ersten Mal in dieser Sitzung ausführen, muss der Spark-Pool gestartet werden. Dies bedeutet, dass die erste Ausführung in der Sitzung ein paar Minuten dauern kann. Nachfolgende Ausführungen erfolgen schneller.
-
Während Sie auf die Initialisierung der Spark-Sitzung warten, überprüfen Sie den generierten Code (Sie können die Schaltfläche Eigenschaften verwenden, die 🗏* ähnelt und sich am rechten Ende der Symbolleiste befindet, um den Bereich Eigenschaften zu schließen, damit Sie den Code besser sehen können). Der Code sollte ungefähr so aussehen:
# Read from Cosmos DB analytical store into a Spark DataFrame and display 10 rows from the DataFrame # To select a preferred list of regions in a multi-region Cosmos DB account, add .option("spark.cosmos.preferredRegions", "<Region1>,<Region2>") df = spark.read\ .format("cosmos.olap")\ .option("spark.synapse.linkedService", "AdventureWorks")\ .option("spark.cosmos.container", "Sales")\ .load() display(df.limit(10)) - Wenn der Code ausgeführt wurde, überprüfen Sie dann die Ausgabe unter der Zelle im Notebook. Die Ergebnisse sollten drei Datensätze enthalten: einen für jedes der Elemente, die Sie der Cosmos DB-Datenbank hinzugefügt haben. Jeder Datensatz enthält die Felder, die Sie beim Erstellen der Elemente eingegeben haben, sowie einige der Metadatenfelder, die automatisch generiert wurden.
-
Verwenden Sie das Symbol + Code unterhalb der Ergebnisse aus der letzten Zelle, um dem Notebook eine neue Zelle hinzuzufügen, und geben Sie anschließend darin den folgenden Code ein:
customer_df = df.select("customerid", "customerdetails") display(customer_df) -
Verwenden Sie das Symbol ▷ links neben der Zelle, um sie auszuführen, und zeigen Sie die Ergebnisse an. Diese sollten etwa wie folgt sein:
customerid customerdetails 124 ”{“customername”: “Julio Ruiz”,”customeremail”: “julio1@adventure-works.com”}” 125 ”{“customername”: “Emma Brown”,”customeremail”: “emma3@adventure-works.com”}” 123 ”{“customername”: “Christy Zhu”,”customeremail”: “christy12@adventure-works.com”}” Diese Abfrage hat ein neues Dataframe erstellt, das nur die Spalten customerid und customerdetails enthält. Beachten Sie, dass die Spalte customerdetails die JSON-Struktur für die geschachtelten Daten im Quellelement enthält. In der angezeigten Ergebnistabelle können Sie das Symbol ► neben dem JSON-Wert verwenden, um ihn zu erweitern und die darin enthaltenen einzelnen Felder anzuzeigen.
-
Fügen Sie eine weitere neue Codezelle hinzu, und geben Sie den folgenden Code ein:
customerdetails_df = df.select("customerid", "customerdetails.*") display(customerdetails_df) -
Führen Sie die Zelle aus, und überprüfen Sie die Ergebnisse, die customername und customeremail aus dem Wert customerdetails als Spalten enthalten sollten:
customerid customername customeremail 124 Julio Ruiz julio1@adventure-works.com 125 Emma Brown emma3@adventure-works.com 123 Christy Zhu christy12@adventure-works.com Mit Spark können Sie komplexen Code zur Datenbearbeitung ausführen, um die Daten aus Cosmos DB neu zu strukturieren und zu untersuchen. In diesem Fall können Sie mithilfe der Sprache PySpark in der JSON-Eigenschaftenhierarchie navigieren, um die untergeordneten Felder des Felds customerdetails abzurufen.
-
Fügen Sie eine weitere neue Codezelle hinzu, und geben Sie den folgenden Code ein:
%%sql -- Create a logical database in the Spark metastore CREATE DATABASE salesdb; USE salesdb; -- Create a table from the Cosmos DB container CREATE TABLE salesorders using cosmos.olap options ( spark.synapse.linkedService 'AdventureWorks', spark.cosmos.container 'Sales' ); -- Query the table SELECT * FROM salesorders; - Führen Sie die neue Zelle aus, um eine neue Datenbank mit einer Tabelle zu erstellen, die Daten aus dem Cosmos DB-Analysespeicher enthält.
-
Fügen Sie eine weitere neue Codezelle hinzu, und dann geben Sie den folgenden Code ein, und führen Sie ihn aus:
%%sql SELECT id, orderdate, customerdetails.customername, product FROM salesorders ORDER BY id;Die Ergebnisse dieser Abfrage sollten wie folgt aussehen:
id orderdate customername product SO43701 01.07.2019 Christy Zhu Mountain-100 Silver, 44 SO43704 01.07.2019 Julio Ruiz Mountain-100 Black, 48 SO43707 2019-07-02 Emma Brown Road-150 Red, 48 Beachten Sie, dass Sie bei Verwendung von Spark SQL benannte Eigenschaften einer JSON-Struktur als Spalten abrufen können.
- Lassen Sie die Registerkarte Notebook 1 geöffnet. Sie kehren später dorthin zurück.
Abfragen von Azure Cosmos DB aus einem serverlosen SQL-Pool
- Wählen Sie im Bereich Daten den Container Sales aus, und wählen Sie im Menü … die Option Neues SQL-Skript > Die ersten 100 Zeilen auswählen aus.
-
Blenden Sie in der Registerkarte SQL-Skript 1, die geöffnet wird, den Bereich Eigenschaften aus, und zeigen Sie den generierten Code an, der in etwa wie folgt aussehen sollte:
IF (NOT EXISTS(SELECT * FROM sys.credentials WHERE name = 'cosmosxxxxxxxx')) THROW 50000, 'As a prerequisite, create a credential with Azure Cosmos DB key in SECRET option: CREATE CREDENTIAL [cosmosxxxxxxxx] WITH IDENTITY = ''SHARED ACCESS SIGNATURE'', SECRET = ''<Enter your Azure Cosmos DB key here>''', 0 GO SELECT TOP 100 * FROM OPENROWSET(PROVIDER = 'CosmosDB', CONNECTION = 'Account=cosmosxxxxxxxx;Database=AdventureWorks', OBJECT = 'Sales', SERVER_CREDENTIAL = 'cosmosxxxxxxxx' ) AS [Sales]Der SQL-Pool erfordert Anmeldeinformationen für den Zugriff auf Cosmos DB, die auf einem Autorisierungsschlüssel für Ihr Cosmos DB-Konto basieren. Das Skript enthält eine anfängliche
IF (NOT EXISTS(...-Anweisung, die diese Anmeldeinformationen überprüft und einen Fehler auslöst, wenn sie nicht vorhanden sind. -
Ersetzen Sie die
IF (NOT EXISTS(...-Anweisung im Skript durch den folgenden Code, um Anmeldeinformationen zu erstellen, und ersetzen Sie dabei cosmosxxxxxxxx durch den Namen Ihres Cosmos DB-Kontos:CREATE CREDENTIAL [cosmosxxxxxxxx] WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<Enter your Azure Cosmos DB key here>' GODas Formular sollten jetzt in etwa wie folgt aussehen:
CREATE CREDENTIAL [cosmosxxxxxxxx] WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<Enter your Azure Cosmos DB key here>' GO SELECT TOP 100 * FROM OPENROWSET(PROVIDER = 'CosmosDB', CONNECTION = 'Account=cosmosxxxxxxxx;Database=AdventureWorks', OBJECT = 'Sales', SERVER_CREDENTIAL = 'cosmosxxxxxxxx' ) AS [Sales] - Wechseln Sie zur Browserregisterkarte mit dem Azure-Portal (oder öffnen Sie eine neue Registerkarte, und melden Sie sich beim Azure-Portal unter https://portal.azure.com an). Öffnen Sie dann in der Ressourcengruppe dp203-xxxxxxx Ihr Azure Cosmos DB-Konto cosmosxxxxxxxx.
- Wählen Sie im Bereich auf der linken Seite im Abschnitt Einstellungen die Seite Schlüssel aus. Kopieren Sie dann den Wert Primärschlüssel in die Zwischenablage.
-
Wechseln Sie zurück zur Browserregisterkarte mit dem SQL-Skript in Azure Synapse Studio, und fügen Sie den Schlüssel in den Code ein, der den Platzhalter <Enter your Azure Cosmos DB key here> ersetzt, sodass das Skript in etwa wie folgt aussieht:
CREATE CREDENTIAL [cosmosxxxxxxxx] WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '1a2b3c....................................==' GO SELECT TOP 100 * FROM OPENROWSET(PROVIDER = 'CosmosDB', CONNECTION = 'Account=cosmosxxxxxxxx;Database=AdventureWorks', OBJECT = 'Sales', SERVER_CREDENTIAL = 'cosmosxxxxxxxx' ) AS [Sales] -
Verwenden Sie die Schaltfläche ▷ Ausführen, um das Skript auszuführen, und überprüfen Sie die Ergebnisse. Diese sollten drei Datensätze enthalten: einen für jedes der Elemente, die Sie der Cosmos DB-Datenbank hinzugefügt haben.
Nachdem Sie die Anmeldeinformationen erstellt haben, können Sie sie in jeder Abfrage für die Cosmos DB-Datenquelle verwenden.
-
Ersetzen Sie den gesamten Code im Skript (sowohl die CREATE CREDENTIAL- als auch die SELECT-Anweisungen) durch den folgenden Code (ersetzen Sie cosmosxxxxxxxx durch den Namen Ihres Azure Cosmos DB-Kontos):
SELECT * FROM OPENROWSET(PROVIDER = 'CosmosDB', CONNECTION = 'Account=cosmosxxxxxxxx;Database=AdventureWorks', OBJECT = 'Sales', SERVER_CREDENTIAL = 'cosmosxxxxxxxx' ) WITH ( OrderID VARCHAR(10) '$.id', OrderDate VARCHAR(10) '$.orderdate', CustomerID INTEGER '$.customerid', CustomerName VARCHAR(40) '$.customerdetails.customername', CustomerEmail VARCHAR(30) '$.customerdetails.customeremail', Product VARCHAR(30) '$.product', Quantity INTEGER '$.quantity', Price FLOAT '$.price' ) AS sales ORDER BY OrderID; -
Führen Sie das Skript aus, und überprüfen Sie die Ergebnisse, die mit dem in der
WITH-Klausel definierten Schema übereinstimmen sollten:OrderID OrderDate CustomerID CustomerName CustomerEmail Produkt Menge Preis SO43701 01.07.2019 123 Christy Zhu christy12@adventure-works.com Mountain-100 Silver, 44 1 3399.99 SO43704 01.07.2019 124 Julio Ruiz julio1@adventure-works.com Mountain-100 Black, 48 1 3374.99 SO43707 2019-07-02 125 Emma Brown emma3@adventure-works.com Road-150 Red, 48 1 3578.27 - Lassen Sie die Registerkarte SQL Skript 1 geöffnet. Sie kehren später dorthin zurück.
Überprüfen, ob die Datenänderungen in Cosmos DB in Synapse wiedergegeben werden.
- Lassen Sie die Browserregisterkarte mit Synapse Studio geöffnet, und wechseln Sie zurück zur Registerkarte mit dem Azure-Portal, die auf der Seite Schlüssel für Ihr Cosmos DB-Konto geöffnet sein sollte.
- Erweitern Sie auf der Seite Daten-Explorer die Datenbank AdventureWorks und den zugehörigen Ordner Sales, und wählen Sie dann den Ordner Items aus.
-
Verwenden Sie die Schaltfläche Neues Element, um ein neues Kundenelement basierend auf dem folgenden JSON-Code zu erstellen. Speichern Sie dann das neue Element (einige zusätzliche Metadatenfelder werden hinzugefügt, wenn Sie das Element speichern).
{ "id": "SO43708", "orderdate": "2019-07-02", "customerid": 126, "customerdetails": { "customername": "Samir Nadoy", "customeremail": "samir1@adventure-works.com" }, "product": "Road-150 Black, 48", "quantity": 1, "price": 3578.27 } - Kehren Sie zur Registerkarte mit Synapse Studio zurück, und führen Sie die Abfrage auf der Registerkarte SQL Script 1 erneut aus. Zunächst werden möglicherweise die gleichen Ergebnisse wie zuvor angezeigt. Warten Sie etwa eine Minute, und führen Sie die Abfrage dann erneut aus, bis die Ergebnisse den Verkauf an Samir Nadoy am 02.07.2019 enthalten.
- Wechseln Sie zurück zur Registerkarte Notebook 1, und führen Sie die letzte Zelle im Spark-Notebook erneut aus, um zu überprüfen, ob der Verkauf an Samir Nadoy jetzt in den Abfrageergebnissen enthalten ist.
Löschen von Azure-Ressourcen
Wenn Sie sich mit Azure Synapse Analytics vertraut gemacht haben, sollten Sie die erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden.
- Schließen Sie die Registerkarte mit Synapse Studio, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressourcengruppen aus.
- Wählen Sie die Ressourcengruppe dp203-xxxxxxx für Ihren Synapse Analytics-Arbeitsbereich aus (nicht die verwaltete Ressourcengruppe), und vergewissern Sie sich, dass sie den Synapse-Arbeitsbereich, das Speicherkonto und den Spark-Pool für Ihren Arbeitsbereich sowie Ihr Azure Cosmos DB-Konto enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe dp203-xxxxxxx ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach einigen Minuten werden die Ressourcengruppe in Ihrem Azure Synapse-Arbeitsbereich und die damit verknüpfte Ressourcengruppe im verwalteten Arbeitsbereich gelöscht.