Erstellen einer Datenpipeline in Azure Synapse Analytics
In dieser Übung laden Sie Daten mithilfe einer Pipeline im Azure Synapse Analytics-Explorer in einen dedizierten SQL-Pool. Die Pipeline kapselt einen Datenfluss, der Produktdaten in eine Tabelle in einem Data Warehouse lädt.
Diese Übung dauert ca. 45 Minuten.
Vorbereitung
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Synapse Analytics-Arbeitsbereichs
Sie benötigen einen Azure Synapse Analytics-Arbeitsbereich mit Zugriff auf den Data Lake-Speicher und einen dedizierten SQL-Pool, in dem ein relationales Data Warehouse gehostet wird.
In dieser Übung verwenden Sie eine Kombination aus einem PowerShell-Skript und einer ARM-Vorlage, um einen Azure Synapse Analytics-Arbeitsbereich bereitzustellen.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie rechts neben der Suchleiste oben auf der Seite die Schaltfläche [>_], um eine neue Cloud Shell-Instanz im Azure-Portal zu erstellen. Wählen Sie eine PowerShell-Umgebung aus, und erstellen Sie Speicher, falls Sie dazu aufgefordert werden. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
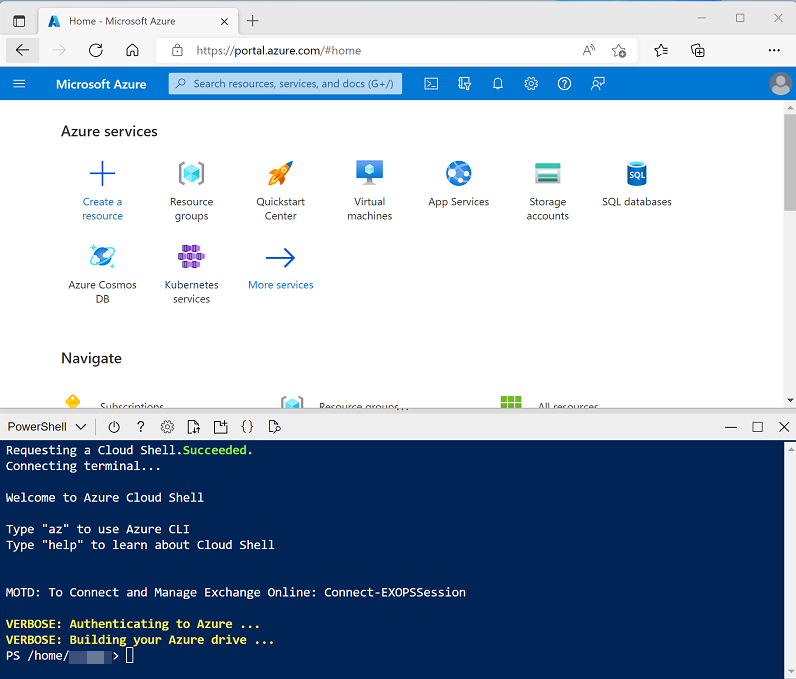
Hinweis: Wenn Sie zuvor eine Cloud Shell erstellt haben, die eine Bash-Umgebung verwendet, ändern Sie diese mithilfe des Dropdownmenüs oben links im Cloud Shell-Bereich zu PowerShell.
-
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern oder den Bereich mithilfe der Symbole „—“, ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Nachdem das Repository geklont wurde, geben Sie die folgenden Befehle ein, um in den Ordner für diese Übung zu wechseln. Führen Sie das darin enthaltene Skript setup.ps1 aus:
cd dp-203/Allfiles/labs/10 ./setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
-
Wenn Sie dazu aufgefordert werden, geben Sie ein geeignetes Kennwort ein, das für Ihren Azure Synapse SQL-Pool festgelegt werden soll.
Hinweis: Merken Sie sich unbedingt dieses Kennwort!
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 10 Minuten, in einigen Fällen kann es jedoch länger dauern. Während Sie warten, lesen Sie den Artikel Datenflüsse in Azure Synapse Analytics in der Dokumentation zu Azure Synapse Analytics.
Anzeigen von Quell- und Zieldatenspeichern
Die Quelldaten für diese Übung sind eine Textdatei, die Produktdaten enthält. Das Ziel ist eine Tabelle in einem dedizierten SQL-Pool. Ihr Ziel ist es, eine Pipeline zu erstellen, die einen Datenfluss kapselt, in dem die Produktdaten in der Datei in die Tabelle geladen werden. Dabei werden neue Produkte eingefügt und vorhandene Produkte aktualisiert.
- Wechseln Sie nach Abschluss des Skripts im Azure-Portal zur erstellten Ressourcengruppe dp203-xxxxxxx, und wählen Sie Ihren Synapse-Arbeitsbereich aus.
- Wählen Sie auf der Seite Übersicht für Ihren Synapse-Arbeitsbereich in der Karte Synapse Studio öffnen die Option Öffnen aus, um Synapse Studio in einer neuen Browserregisterkarte zu öffnen. Melden Sie sich an, wenn Sie dazu aufgefordert werden.
- Verwenden Sie im linken Bereich von Synapse Studio das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten in Synapse Studio angezeigt, die Sie zur Verwaltung von Ressourcen und zur Durchführung von Datenanalyseaufgaben verwenden werden.
-
Wählen Sie auf der Seite Verwalten auf der Registerkarte SQL-Pools die Zeile für den dedizierten SQL-Pool sqlxxxxxxx aus, und klicken Sie auf das zugehörige Symbol ▷, um ihn zu starten. Bestätigen Sie, dass Sie ihn fortsetzen möchten, wenn Sie dazu aufgefordert werden.
Das Fortsetzen eines Pools kann einige Minuten dauern. Sie können den Status mithilfe der Schaltfläche ↻ Aktualisieren regelmäßig überprüfen. Der Status wird als Online angezeigt, wenn der SQL-Pool bereit ist. Fahren Sie in der Zwischenzeit mit den nachstehenden Schritten fort, um die Quelldaten anzuzeigen.
- Zeigen Sie auf der Seite Daten die Registerkarte Verknüpft an, und stellen Sie sicher, dass Ihr Arbeitsbereich einen Link zu Ihrem Azure Data Lake Storage Gen2-Speicherkonto enthält, dessen Name synapsexxxxxxx (Primary - datalakexxxxxxx) ähneln sollte.
- Erweitern Sie Ihr Speicherkonto, und stellen Sie sicher, dass es einen Dateisystemcontainer mit dem Namen files (primary) enthält.
- Wählen Sie den Dateicontainer aus, und beachten Sie, dass er einen Ordner mit dem Namen data enthält.
- Öffnen Sie den Ordner Daten, der die Datei Product.csv enthält.
- Klicken Sie mit der rechten Maustaste auf Product.csv, und wählen Sie Vorschau aus, um die darin enthaltenen Daten anzuzeigen. Beachten Sie, dass die Datei eine Kopfzeile und einige Datensätze mit Produktdaten enthält.
- Kehren Sie zur Seite Verwalten zurück, und stellen Sie sicher, dass Ihr dedizierter SQL-Pool jetzt online ist. Wenn nicht, warten Sie, bis dies der Fall ist.
- Erweitern Sie auf der Seite Daten auf der Registerkarte Arbeitsbereich das Element SQL-Datenbank, Ihre Datenbank sqlxxxxxxx (SQL) und die zugehörigen Tabellen.
- Wählen Sie die Tabelle dbo.DimProduct aus. Wählen Sie dann im Menü … die Option Neues SQL-Skript > Die ersten 100 Zeilen aus. Dadurch wird eine Abfrage ausgeführt, die die Produktdaten aus der Tabelle zurückgibt. Es sollte eine einzige Zeile vorhanden sein.
Implementieren einer Pipeline
Um die Daten in der Textdatei in die Datenbanktabelle zu laden, implementieren Sie eine Azure Synapse Analytics-Pipeline, die einen Datenfluss mit der die Logik zum Aufnehmen der Daten aus der Textdatei enthält. Dann suchen Sie nach der Ersatzspalte ProductKey für Produkte, die bereits in der Datenbank vorhanden sind, und fügen anschließend Zeilen in die Tabelle entsprechend ein oder aktualisieren sie.
Erstellen einer Pipeline mit einer Datenflussaktivität
- Wählen Sie in Synapse Studio die Seite Integrieren aus. Wählen Sie dann im Menü + die Option Pipeline aus, um eine neue Pipeline zu erstellen.
- Ändern Sie im Bereich Eigenschaften für die neue Pipeline den Namen von Pipeline1 zu Produktdaten laden. Verwenden Sie dann die Schaltfläche Eigenschaften oberhalb des Bereichs Eigenschaften, um sie auszublenden.
-
Erweitern Sie im Bereich Aktivitäten die Option Verschieben und transformieren, und ziehen Sie dann einen Datenfluss auf die Pipelineentwurfsoberfläche, wie hier gezeigt:
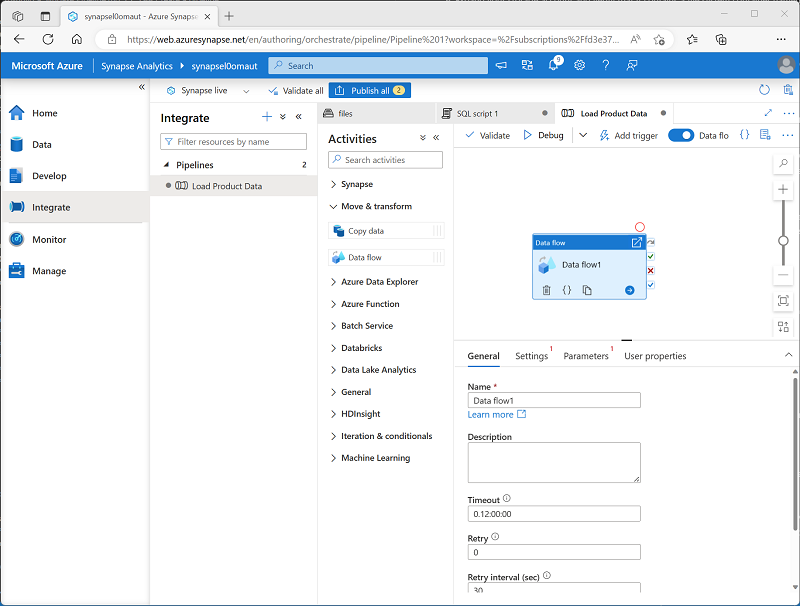
- Legen Sie unter der Pipelineentwurfsoberfläche auf der Registerkarte Allgemein die Eigenschaft Name auf LoadProducts fest.
- Erweitern Sie auf der Registerkarte Einstellungen unten in der Liste der Einstellungen Staging, und legen Sie die folgenden Stagingeinstellungen fest:
- Staging – verknüpfter Dienst: Wählen Sie den verknüpften Dienst synapsexxxxxxx-WorkspaceDefaultStorage aus.
- Staging – Speicherordner: Legen Sie container auf files und Directory auf stage_products fest.
Konfigurieren des Datenflusses
- Wählen Sie oben auf der Registerkarte Einstellungen für den Datenfluss LoadProducts für die Eigenschaft Datenfluss die Option + Neu aus.
-
Legen Sie im Bereich Eigenschaften für die neue Entwurfsoberfläche für den Datenfluss, die geöffnet wird, den Namen auf LoadProductsData fest, und blenden Sie dann den Bereich Eigenschaften aus. Der Datenfluss-Designer sollte wie folgt aussehen:
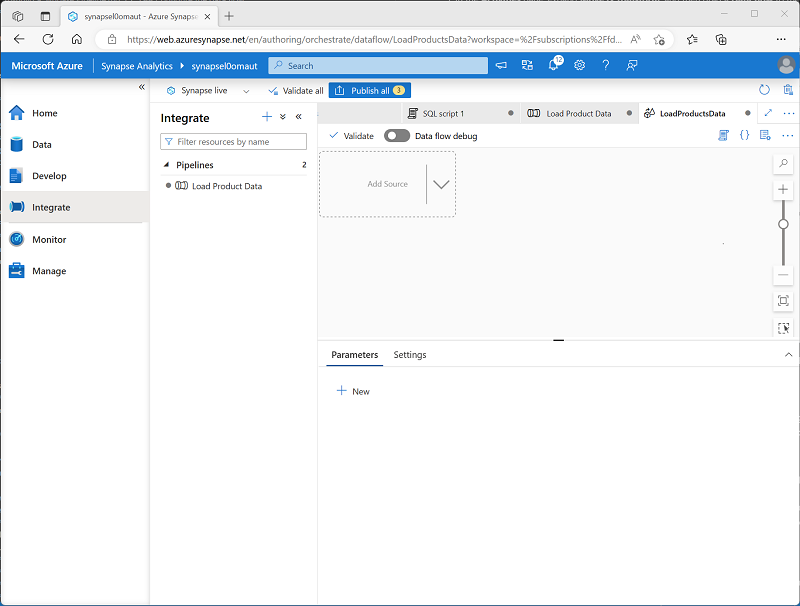
Quellen hinzufügen
- Wählen Sie in der Entwurfsoberfläche des Datenflusses in der Dropdownliste Quelle hinzufügen die Option Quelle hinzufügen aus. Konfigurieren Sie die Quelleinstellungen wie folgt:
- Name des Ausgabedatenstroms: ProductsText
- Beschreibung: Produkttextdaten
- Quelltyp: Integrations-Dataset
- Dataset: Fügen Sie einen neuen Dataset mit den folgenden Eigenschaften hinzu:
- Typ: Azure Data Lake Storage Gen2
- Format: Durch Trennzeichen getrennter Text
- Name: Products_Csv
- Verknüpfter Dienst: synapsexxxxxxx-WorkspaceDefaultStorage
- Dateipfad: files/data/Product.csv
- Erste Zeile ist Überschrift: Ausgewählt
- Schema importieren: Aus Verbindung/Speicher
- Schemaabweichung zulassen: Ausgewählt
- Legen Sie auf der Registerkarte Projektion für die neue Quelle ProductsText die folgenden Datentypen fest:
- ProductID: Zeichenfolge
- ProductName: Zeichenfolge
- Farbe: Zeichenfolge
- Größe: Zeichenfolge
- ListPrice: Dezimalzahl
- Eingestellt: boolescher Wert
- Fügen Sie eine zweite Quelle mit den folgenden Werten hinzu:
- Name des Ausgabedatenstroms: ProductTable
- Beschreibung: Produkttabelle
- Quelltyp: Integrations-Dataset
- Dataset: Fügen Sie einen neuen Dataset mit den folgenden Eigenschaften hinzu:
- Typ: Azure Synapse Analytics
- Name: DimProduct
- Verknüpfter Dienst: Erstellen Sie einen neuen verknüpften Dienst mit den folgenden Eigenschaften:
- Name: Data_Warehouse
- Beschreibung: Dedizierter SQL-Pool
- Verbindung über Integration Runtime herstellen: AutoResolveIntegrationRuntime
- Version: Alt
- Kontoauswahlmethode: Aus Azure-Abonnement
- Azure-Abonnement: Wählen Sie Ihr Azure-Abonnement aus.
- Servername: synapsexxxxxxx (Synapse-Arbeitsbereich)
- Datenbankname: sqlxxxxxxx
- SQL-Pool: sqlxxxxxxx Authentifizierungstyp: Vom System zugewiesene verwaltete Identität
- Tabellenname: dbo.DimProduct
- Schema importieren: Aus Verbindung/Speicher
- Schemaabweichung zulassen: Ausgewählt
- Überprüfen Sie auf der Registerkarte Projektion für die neue Quelle ProductTable, ob die folgenden Datentypen festgelegt sind:
- ProductKey: Integer
- ProductAltKey: Zeichenfolge
- ProductName: Zeichenfolge
- Farbe: Zeichenfolge
- Größe: Zeichenfolge
- ListPrice: Dezimalzahl
- Eingestellt: boolescher Wert
-
Stellen Sie sicher, dass ihr Datenfluss zwei Quellen enthält, wie hier gezeigt:
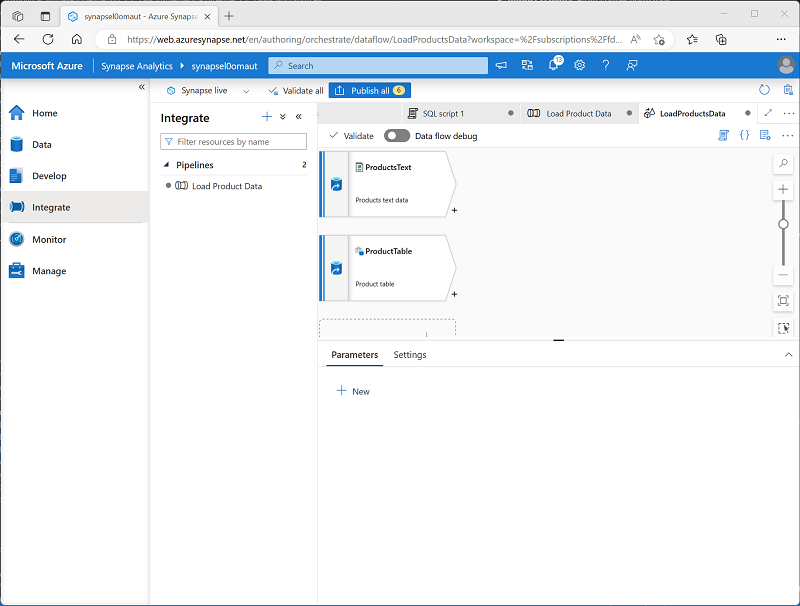
Hinzufügen eines Lookup
- Wählen Sie das Symbol + unten rechts in der Quelle ProductsText aus, und wählen Sie Lookup aus.
- Konfigurieren Sie die Lookup-Einstellungen wie folgt:
- Name des Ausgabedatenstroms: MatchedProducts
- Beschreibung: Übereinstimmende Produktdaten
- Primärer Datenstrom: ProductText
- Lookup-Datenstrom: ProductTable
- Mehrere Zeilen abgleichen: Nichtausgewählt
- Abgleiche an: Letzte Zeile
- Sortierbedingungen: ProductKey aufsteigend
- Lookup-Bedingungen: ProductID == ProductAltKey
-
Stellen Sie sicher, dass der Datenfluss wie folgt aussieht:
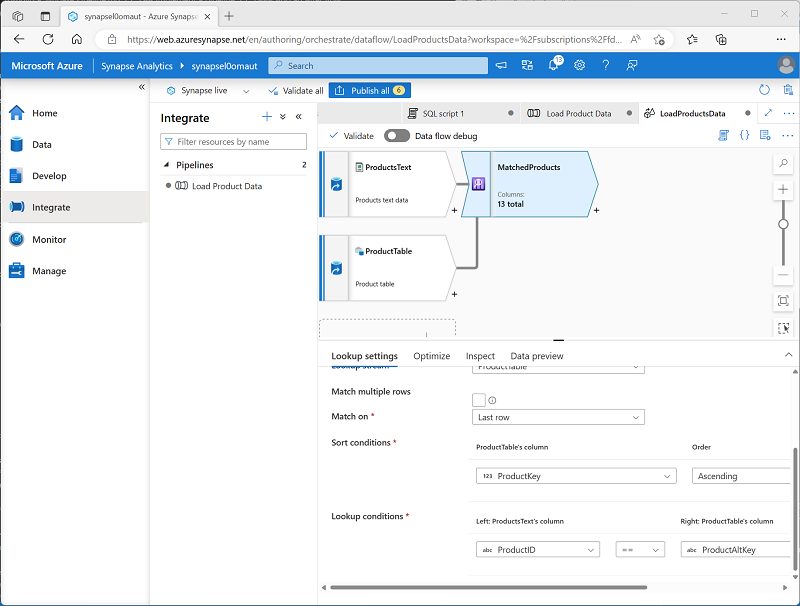
Das Lookup gibt eine Reihe von Spalten aus beiden Quellen zurück, die im Wesentlichen eine äußere Verknüpfung bilden, die die Spalte ProductID in der Textdatei mit der Spalte ProductAltKey in der Data Warehouse-Tabelle abgleicht. Wenn ein Produkt mit dem alternativen Schlüssel bereits in der Tabelle vorhanden ist, enthält das Dataset die Werte aus beiden Quellen. Wenn das Produkt noch nicht im Data Warehouse vorhanden ist, enthält das Dataset NULL-Werte für die Tabellenspalten.
Hinzufügen einer Zeilenänderung
- Wählen Sie das Symbol + unten rechts im Lookup MatchedProducts aus, und wählen Sie Zeilenänderung aus.
- Konfigurieren Sie die Einstellungen für die Zeilenänderung wie folgt:
- Name des Ausgabedatenstroms: SetLoadAction
- Beschreibung: Einfügen neuer, Upsert vorhandener
- Eingehender Datenstrom: MatchedProducts
- Bedingungen für die Zeilenänderung: Bearbeiten Sie die vorhandene Bedingung, und verwenden Sie die Schaltfläche +, um eine zweite Bedingung wie folgt hinzuzufügen (beachten Sie, dass bei den Ausdrücken die Groß-/Kleinschreibung beachtet wird):
- InsertIf:
isNull(ProductKey) - UpsertIf:
not(isNull(ProductKey))
- InsertIf:
-
Stellen Sie sicher, dass der Datenfluss wie folgt aussieht:
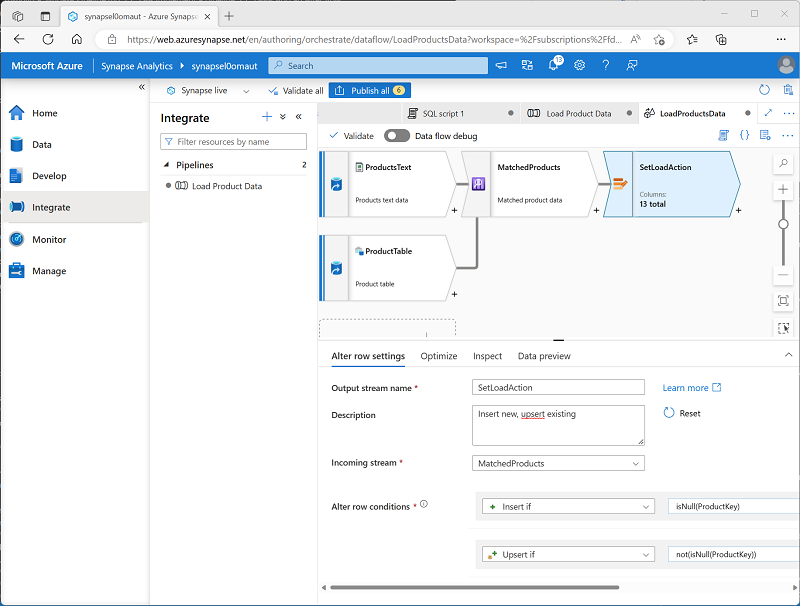
Der Zeilenänderungsschritt konfiguriert die Art der Ladeaktion, die für jede Zeile ausgeführt werden soll. Wenn keine Zeile in der Tabelle vorhanden ist (ProductKey ist NULL), wird die Zeile aus der Textdatei eingefügt. Wenn bereits eine Zeile für das Produkt vorhanden ist, wird ein Upsert ausgeführt, um die vorhandene Zeile zu aktualisieren. Diese Konfiguration wendet im Wesentlichen eine Aktualisierung der langsam veränderlichen Dimension vom Typ 1 an.
Hinzufügen einer Senke
- Wählen Sie das Symbol + unten rechts im Zeilenänderungsschritt SetLoadAction aus, und wählen Sie Senke aus.
- Konfigurieren Sie die Senke wie folgt:
- Name des Ausgabedatenstroms: DimProductTable
- Beschreibung: Tabelle „DimProduct“ laden
- Eingehender Datenstrom: SetLoadAction
- Senkentyp: Integrations-Dataset
- Dataset: DimProduct
- Schemaabweichung zulassen: Ausgewählt
- Geben Sie auf der Registerkarte Einstellungen für die neue Senke DimProductTable die folgenden Einstellungen an:
- Update-Methode: Wählen Sie Einfügen zulassen und Upsert zulassen aus.
- Schlüsselspalten: Wählen Sie Liste der Spalten und dann die Spalte ProductAltKey aus.
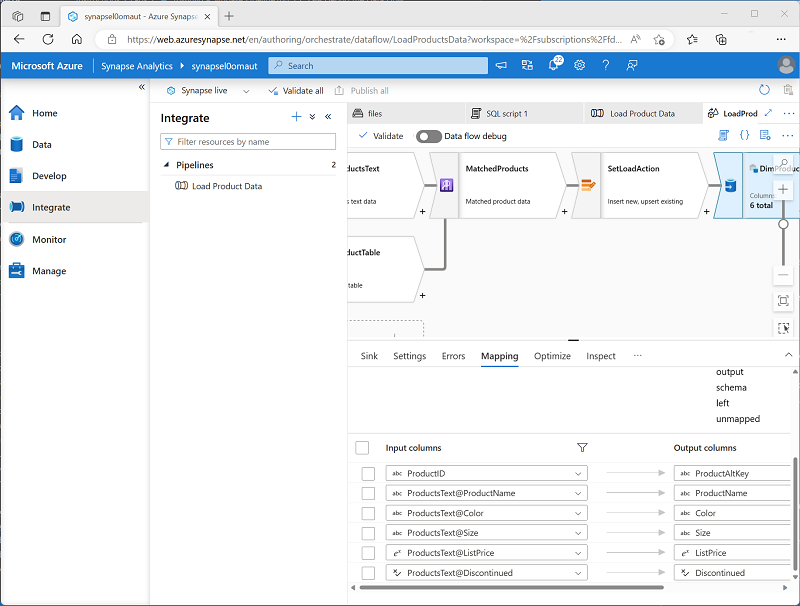
- Deaktivieren Sie auf der Registerkarte Zuordnungen für die neue Senke DimProductTable das Kontrollkästchen Automatische Zuordnung, und geben Sie nur die folgenden Spaltenzuordnungen an:
- ProductID: ProductAltKey
- ProductsText@ProductName: ProductName
- ProductsText@Color: Farbe
- ProductsText@Size: Größe
- ProductsText@ListPrice: ListPrice
- ProductsText@Discontinued: Eingestellt
-
Stellen Sie sicher, dass der Datenfluss wie folgt aussieht:
Debuggen des Datenflusses
Nachdem Sie nun einen Datenfluss in einer Pipeline erstellt haben, können Sie ihn vor der Veröffentlichung debuggen.
- Aktivieren Sie oben im Datenfluss-Designer Datenfluss debuggen. Überprüfen Sie die Standardkonfiguration, wählen Sie OK aus, und warten Sie dann, bis der Debugcluster gestartet wird (was einige Minuten dauern kann).
- Wählen Sie im Datenfluss-Designer die Senke DimProductTable aus, und zeigen Sie die Registerkarte Datenvorschau an.
- Verwenden Sie Schaltfläche ↻ Aktualisieren, um die Vorschau zu aktualisieren und dadurch Daten den Datenfluss durchlaufen zu lassen, um sie zu debuggen.
- Überprüfen Sie die Vorschaudaten und beachten Sie, dass eine Upserting-Zeile (für das vorhandene Produkt AR5381), gekennzeichnet durch das Symbol *+, und zehn eingefügte Zeilen, gekennzeichnet durch das Symbol +, angezeigt werden.
Veröffentlichen und Ausführen der Pipeline
Nun können Sie die Pipeline veröffentlichen und ausführen.
- Verwenden Sie die Schaltfläche Alle veröffentlichen, um die Pipeline (und alle anderen nicht gespeicherten Ressourcen) zu veröffentlichen.
- Wenn die Veröffentlichung abgeschlossen ist, schließen Sie den Datenflussbereich LoadProductsData, und kehren Sie zum Pipelinebereich Produktdaten laden zurück.
-
Wählen Sie oben im Pipeline-Designerbereich im Menü Trigger hinzufügen die Option Jetzt auslösen aus. Wählen Sie dann OK aus, um zu bestätigen, dass Sie die Pipeline ausführen möchten.
Hinweis: Sie können auch einen Trigger erstellen, um die Pipeline zu einem geplanten Zeitpunkt oder als Reaktion auf ein bestimmtes Ereignis auszuführen.
-
Wenn die Pipeline gestartet wurde, zeigen Sie auf der Seite Überwachen die Registerkarte Pipelineausführungen an, und überprüfen Sie den Status der Pipeline Produktdaten laden.
Es kann fünf Minuten oder länger dauern, bis die Pipeline abgeschlossen ist. Sie können die Schaltfläche ↻ Aktualisieren in der Symbolleiste verwenden, um den Status zu überprüfen.
- Wenn die Pipelineausführung erfolgreich war, verwenden Sie auf der Seite Daten das Menü … für die Tabelle dbo.DimProduct in Ihrer SQL-Datenbank zum Ausführen einer Abfrage, die die ersten 100 Zeilen auswählt. Die Tabelle sollte die von der Pipeline geladenen Daten enthalten.
Löschen von Azure-Ressourcen
Wenn Sie sich mit Azure Synapse Analytics vertraut gemacht haben, sollten Sie die erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden.
- Schließen Sie die Registerkarte mit Synapse Studio, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressourcengruppen aus.
- Wählen Sie die Ressourcengruppe dp203-xxxxxxx für Ihren Synapse Analytics-Arbeitsbereich aus (nicht die verwaltete Ressourcengruppe), und vergewissern Sie sich, dass sie den Synapse-Arbeitsbereich, das Speicherkonto und den dedizierten SQL-Pool für Ihren Arbeitsbereich enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe dp203-xxxxxxx ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach einigen Minuten werden die Ressourcengruppe in Ihrem Azure Synapse-Arbeitsbereich und die damit verknüpfte Ressourcengruppe im verwalteten Arbeitsbereich gelöscht.