Transformieren von Daten mit Spark in Azure Synapse Analytics
Datentechniker verwenden Spark-Notebooks häufig als eines ihrer bevorzugten Tools, um die Aktivitäten Extrahieren, Transformieren und Laden (ETL) oder Extrahieren, Laden und Transformieren (ELT) auszuführen, durch die Daten von einem Format oder einer Struktur in eine andere transformiert werden.
In dieser Übung verwenden Sie einen Spark Notebook in Azure Synapse Analytics, um Daten in Dateien zu transformieren.
Diese Übung dauert ca. 30 Minuten.
Vorbereitung
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Synapse Analytics-Arbeitsbereichs
Sie benötigen einen Azure Synapse Analytics-Arbeitsbereich mit Zugriff auf den Data Lake-Speicher und einen Spark-Pool.
In dieser Übung verwenden Sie eine Kombination aus einem PowerShell-Skript und einer ARM-Vorlage, um einen Azure Synapse Analytics-Arbeitsbereich bereitzustellen.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie rechts neben der Suchleiste oben auf der Seite die Schaltfläche [>_], um eine neue Cloud Shell-Instanz im Azure-Portal zu erstellen. Wählen Sie eine PowerShell-Umgebung aus, und erstellen Sie Speicher, falls Sie dazu aufgefordert werden. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
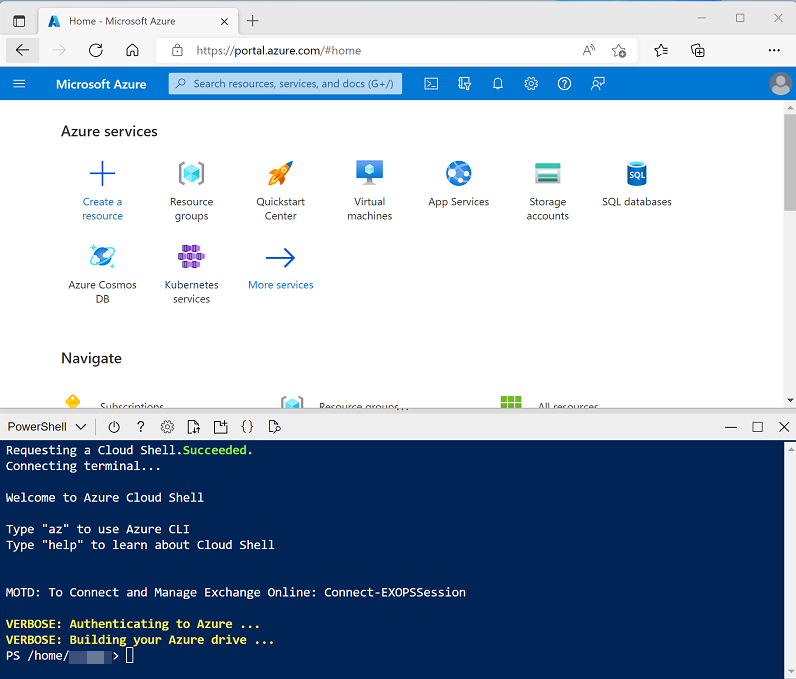
Hinweis: Wenn Sie zuvor eine Cloud Shell erstellt haben, die eine Bash-Umgebung verwendet, ändern Sie diese mithilfe des Dropdownmenüs oben links im Cloud Shell-Bereich zu PowerShell.
-
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern können oder den Bereich mithilfe der Symbole —, ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Nachdem das Repository geklont wurde, geben Sie die folgenden Befehle ein, um in den Ordner für diese Übung zu wechseln. Führen Sie das darin enthaltene Skript setup.ps1 aus:
cd dp-203/Allfiles/labs/06 ./setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
-
Wenn Sie dazu aufgefordert werden, geben Sie ein geeignetes Kennwort ein, das für den Azure Synapse SQL-Pool festgelegt werden soll.
Hinweis: Merken Sie sich unbedingt dieses Kennwort!
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 10 Minuten und in Ausnahmefällen auch länger. Während Sie warten, lesen Sie den Artikel Apache Spark in Azure Synapse Analytics Grundlagen in der Dokumentation zu Azure Synapse Analytics.
Verwenden eines Spark-Notebooks zum Transformieren von Daten
- Wechseln Sie nach Abschluss des Bereitstellungsskripts im Azure-Portal zur von ihr erstellten dp203-xxxxxxx-Ressourcengruppe, und beachten Sie, dass diese Ressourcengruppe Ihren Synapse-Arbeitsbereich, ein Speicherkonto für Ihren Data Lake und einen Apache Spark-Pool enthält.
- Wählen Sie Ihren Synapse-Arbeitsbereich aus, und wählen Sie auf der Seite Übersicht in der Karte Synapse Studio öffnen Öffnen aus, um Synapse Studio in einer neuen Browserregisterkarte zu öffnen und sich anzumelden, wenn Sie dazu aufgefordert werden.
- Verwenden Sie auf der linken Seite von Synapse Studio das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten in Synapse Studio angezeigt, die Sie zum Verwalten von Ressourcen und zum Ausführen von Datenanalyseaufgaben verwenden.
- Wählen Sie auf der Seite Verwalten die Registerkarte Apache Spark Pools aus und beachten Sie, dass ein Spark-Pool mit einem Namen der Form sparkxxxxxxx im Arbeitsbereich bereitgestellt wurde.
- Zeigen Sie auf der Seite Daten die Registerkarte Verknüpft an, und stellen Sie sicher, dass Ihr Arbeitsbereich einen Link zu Ihrem Azure Data Lake Storage Gen2-Speicherkonto enthält, dessen Name synapsexxxxxxx (Primary - datalakexxxxxxx) ähneln sollte.
- Erweitern Sie Ihr Speicherkonto, und stellen Sie sicher, dass es einen Dateisystemcontainer mit dem Namen Dateien (Primary) enthält.
- Wählen Sie den Container Dateien aus und beachten Sie, dass er Ordner mit den Namen Daten und Synapse enthält. Der Synapse-Ordner wird von Azure Synapse verwendet, und der Daten-ordner enthält die Datendateien, die Sie abfragen möchten.
- Öffnen Sie den Daten-ordner und beachten Sie, dass er CSV-Dateien für drei Jahre Umsatzdaten enthält.
- Klicken Sie mit der rechten Maustaste auf eine der Dateien, und wählen Sie Vorschau aus, um die darin enthaltenen Daten anzuzeigen. Beachten Sie, dass die Dateien eine Kopfzeile enthalten, damit Sie die Option zum Anzeigen von Spaltenüberschriften auswählen können.
-
Schließen Sie die Vorschau. Laden Sie dann die Spark Transform.ipynb aus Allfiles/labs/06/notebooks herunter
Hinweis: Es ist am besten, diesen Text mit STRG+A und STRG+C zu kopieren und mit STRG+V in ein Tool wie Notepad einzufügen und die Datei anschließend als Spark Transform.ipynb mit einem Dateityp Alle Dateien zu speichern. Sie können die Datei auch herunterladen, indem Sie darauf klicken, die Auslassungspunkte (…) auswählen und die Datei dann herunterladen. Merken Sie sich dabei, wo Sie die Datei gespeichert haben.
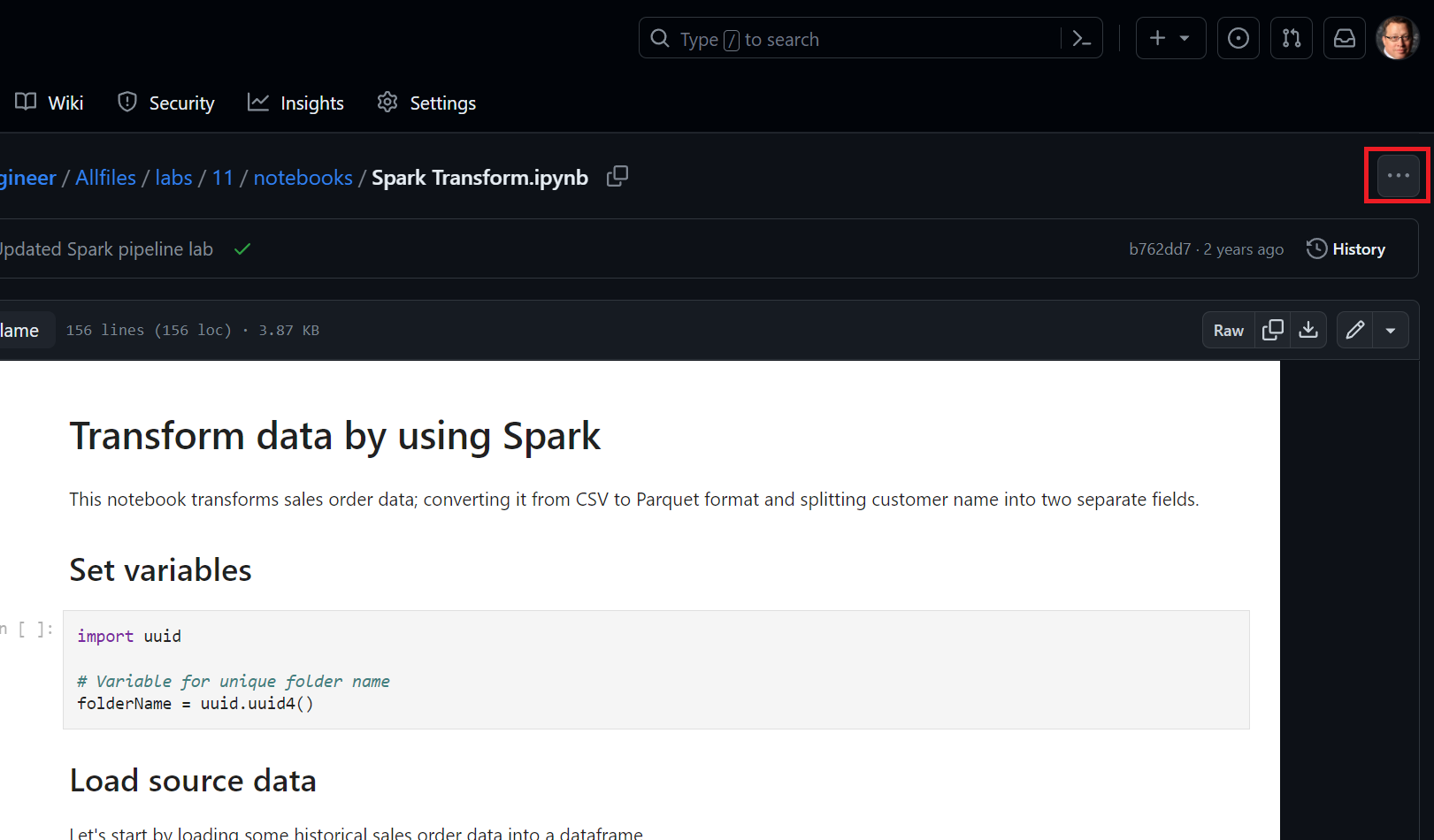
-
Erweitern Sie dann auf der Seite Entwickeln Notebooks und klicken Sie auf +Import-Optionen.
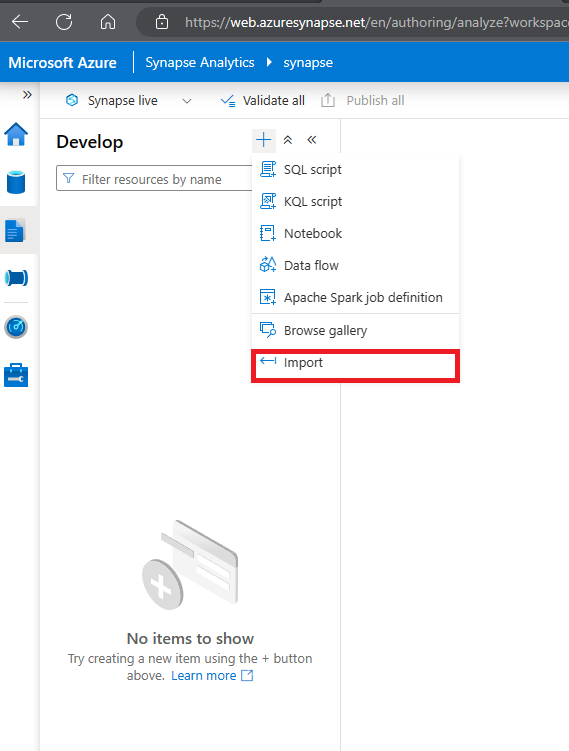
- Wählen Sie die Datei aus, die Sie gerade heruntergeladen und als Spark Transfrom.ipynb gespeichert haben.
- Fügen Sie das Notebook an Ihren Sparkxxxxxxx Spark-Pool an.
-
Überprüfen Sie die Notizen im Notebook, und führen Sie die Codezellen aus.
Hinweis: Die erste Codezelle dauert ein paar Minuten, da der Spark-Pool gestartet werden muss. Nachfolgende Zellen werden schneller ausgeführt.
Löschen von Azure-Ressourcen
Wenn Sie sich mit Azure Synapse Analytics vertraut gemacht haben, sollten Sie die erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden.
- Schließen Sie die Registerkarte mit Synapse Studio, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressourcengruppen aus.
- Wählen Sie die Ressourcengruppe dp203-xxxxxxx für Ihren Synapse Analytics-Arbeitsbereich aus (nicht die verwaltete Ressourcengruppe), und vergewissern Sie sich, dass sie den Synapse-Arbeitsbereich, das Speicherkonto und den Spark-Pool für Ihren Arbeitsbereich enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe dp203-xxxxxxx ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach einigen Minuten werden die Ressourcengruppe in Ihrem Azure Synapse-Arbeitsbereich und die damit verknüpfte Ressourcengruppe im verwalteten Arbeitsbereich gelöscht.