Analysieren von Daten in einer Lake-Datenbank
Mit Azure Synapse Analytics können Sie die Flexibilität der Dateispeicherung in einem Data Lake mit den strukturierten Schema- und SQL-Abfragefunktionen einer relationalen Datenbank kombinieren, indem Sie die Möglichkeit haben, eine Lake-Datenbank zu erstellen. Bei einer Lake-Datenbank handelt es sich um ein relationales Datenbankschema, das in einem Data Lake-Dateispeicher definiert ist, mit dem die Datenspeicherung von der zum Abfragen verwendeten Berechnung getrennt werden kann. Lake-Datenbanken kombinieren die Vorteile eines strukturierten Schemas, das Unterstützung für Datentypen, Beziehungen und andere Features enthält, die in der Regel nur in relationalen Datenbanksystemen zu finden sind, mit der Flexibilität, Daten in Dateien zu speichern, die unabhängig von einem relationalen Datenbankspeicher verwendet werden können. Im Wesentlichen überlagert die Lake-Datenbank ein relationales Schema auf Dateien in Ordnern im Data Lake.
Diese Übung dauert ca. 45 Minuten.
Vorbereitung
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Synapse Analytics-Arbeitsbereichs
Um eine Seedatenbank zu unterstützen, benötigen Sie einen Azure Synapse Analytics-Arbeitsbereich mit Zugriff auf den Datenspeicher. Es ist kein dedizierter SQL-Pool erforderlich, da Sie die Lake-Datenbank mithilfe des integrierten serverlosen SQL-Pools definieren können. Optional können Sie auch einen Spark-Pool verwenden, um mit Daten in der Lake-Datenbank zu arbeiten.
In dieser Übung verwenden Sie eine Kombination aus einem PowerShell-Skript und einer ARM-Vorlage, um einen Azure Synapse Analytics-Arbeitsbereich bereitzustellen.
- Melden Sie sich beim Azure-Portal unter
https://portal.azure.coman. -
Verwenden Sie rechts neben der Suchleiste oben auf der Seite die Schaltfläche [>_], um eine neue Cloud Shell-Instanz im Azure-Portal zu erstellen. Wählen Sie eine PowerShell-Umgebung aus, und erstellen Sie Speicher, falls Sie dazu aufgefordert werden. Die Cloud Shell bietet eine Befehlszeilenschnittstelle in einem Bereich am unteren Rand des Azure-Portals, wie hier gezeigt:
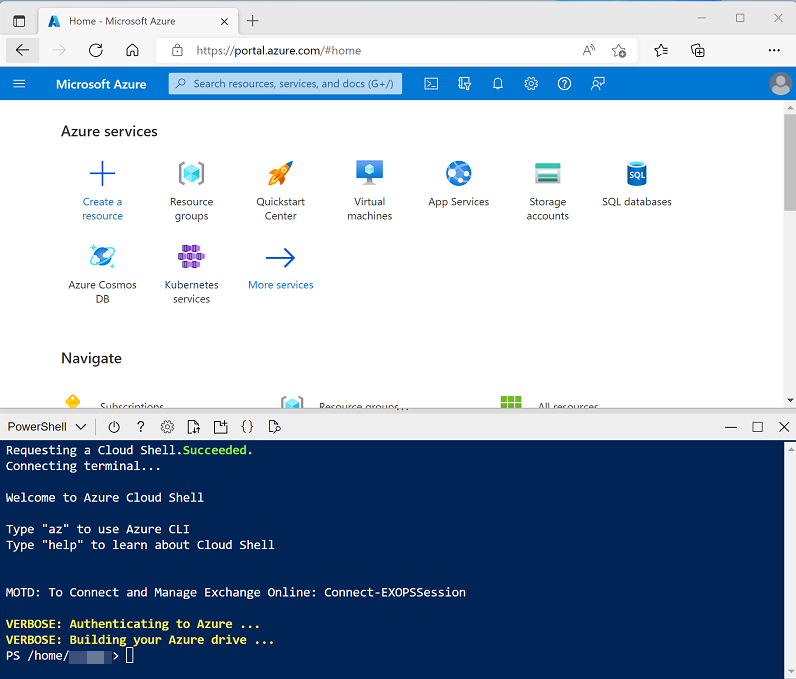
Hinweis: Wenn Sie zuvor eine Cloudshell erstellt haben, die eine Bash-Umgebung verwendet, verwenden Sie das Dropdownmenü links oben im Bereich „Cloudshell“, um sie in PowerShell zu ändern.
-
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern können oder den Bereich mithilfe der Symbole —, ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie im PowerShell-Bereich die folgenden Befehle ein, um dieses Repository zu klonen:
rm -r dp-203 -f git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203 -
Nachdem das Repository geklont wurde, geben Sie die folgenden Befehle ein, um in den Ordner für diese Übung zu wechseln. Führen Sie das darin enthaltene Skript setup.ps1 aus:
cd dp-203/Allfiles/labs/04 ./setup.ps1 - Wenn Sie dazu aufgefordert werden, wählen Sie aus, welches Abonnement Sie verwenden möchten (dies geschieht nur, wenn Sie Zugriff auf mehrere Azure-Abonnements haben).
-
Wenn Sie dazu aufgefordert werden, geben Sie ein geeignetes Kennwort ein, das für Ihren Azure Synapse SQL-Pool festgelegt werden soll.
Hinweis: Merken Sie sich unbedingt dieses Kennwort!
- Warten Sie, bis das Skript abgeschlossen ist. Dies dauert in der Regel etwa 10 Minuten und in Ausnahmefällen auch länger. Während Sie warten, lesen Sie die Artikel zu Lake-Datenbanken und Lake-Datenbankvorlagen in der Dokumentation zu Azure Synapse Analytics.
Ändern von Containerberechtigungen
- Wechseln Sie nach Abschluss des Bereitstellungsskripts im Azure-Portal zur von ihr erstellten Ressourcengruppe dp203-xxxxx. Beachten Sie, dass diese Ressourcengruppe Ihren Synapse-Arbeitsbereich, ein Speicherkonto für Ihren Data Lake und einen Apache Spark-Pool enthält.
-
Wählen Sie das Speicherkonto für Ihren Data Lake mit dem Namen datalakexxxxx aus.
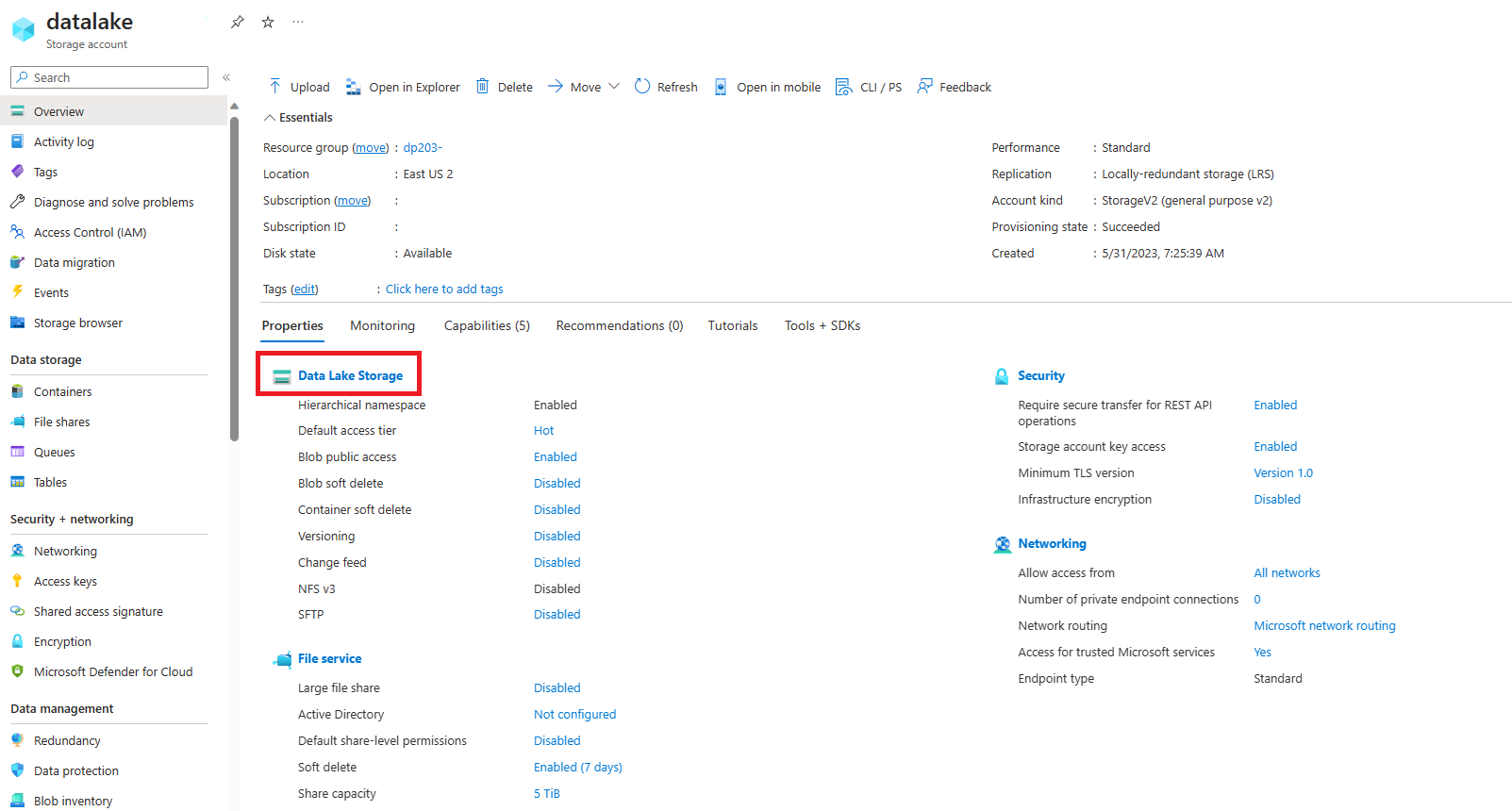
-
Wählen Sie im datalakexxxxxx-Container den Dateien-Ordner aus.
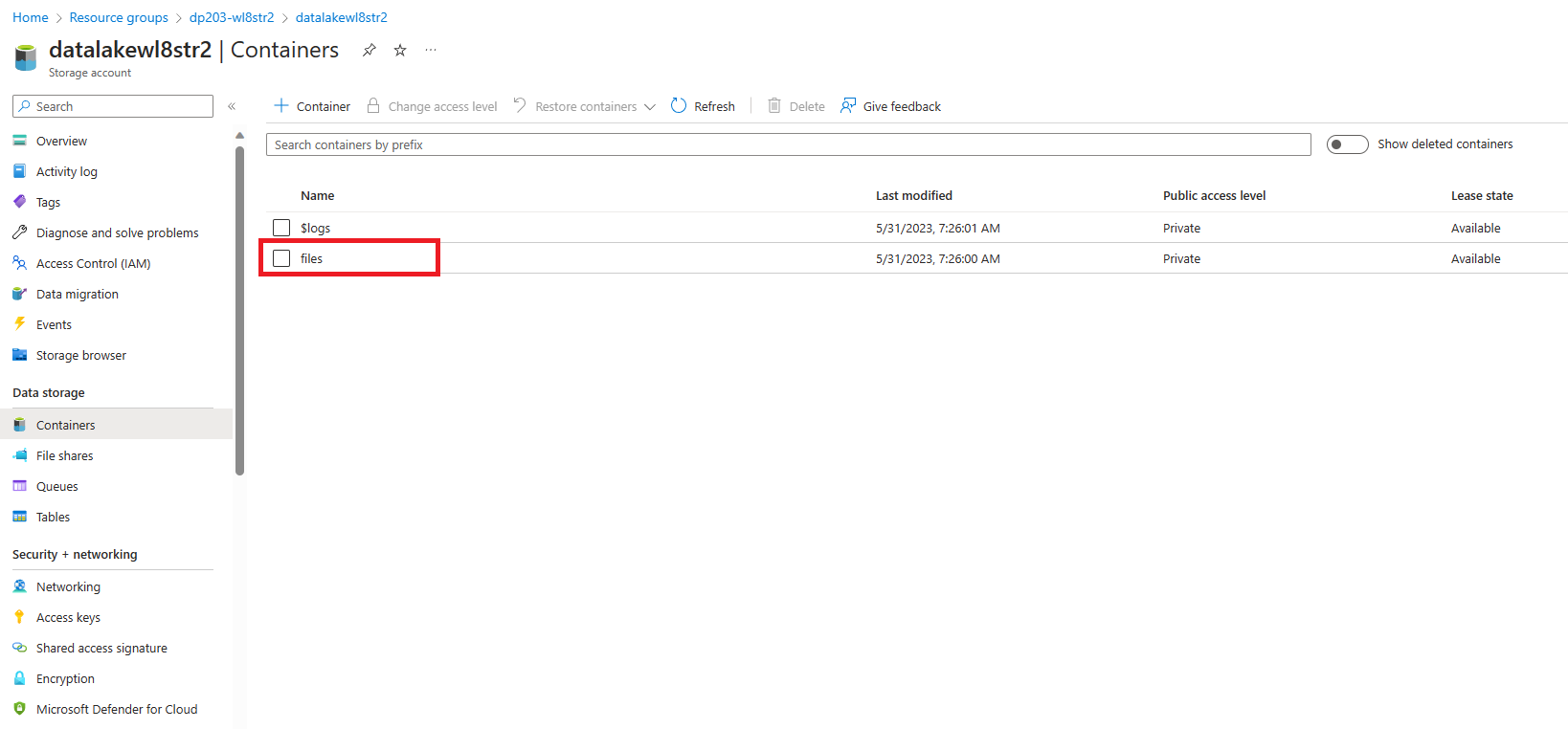
-
Beachten Sie, dass im Dateiordner als Authentifizierungsmethode: die Option Zugriffstaste (Zu Entra-Benutzerkonto wechseln) aufgeführt wird. Wählen Sie sie aus, um zu Entra-Benutzerkonto zu wechseln.
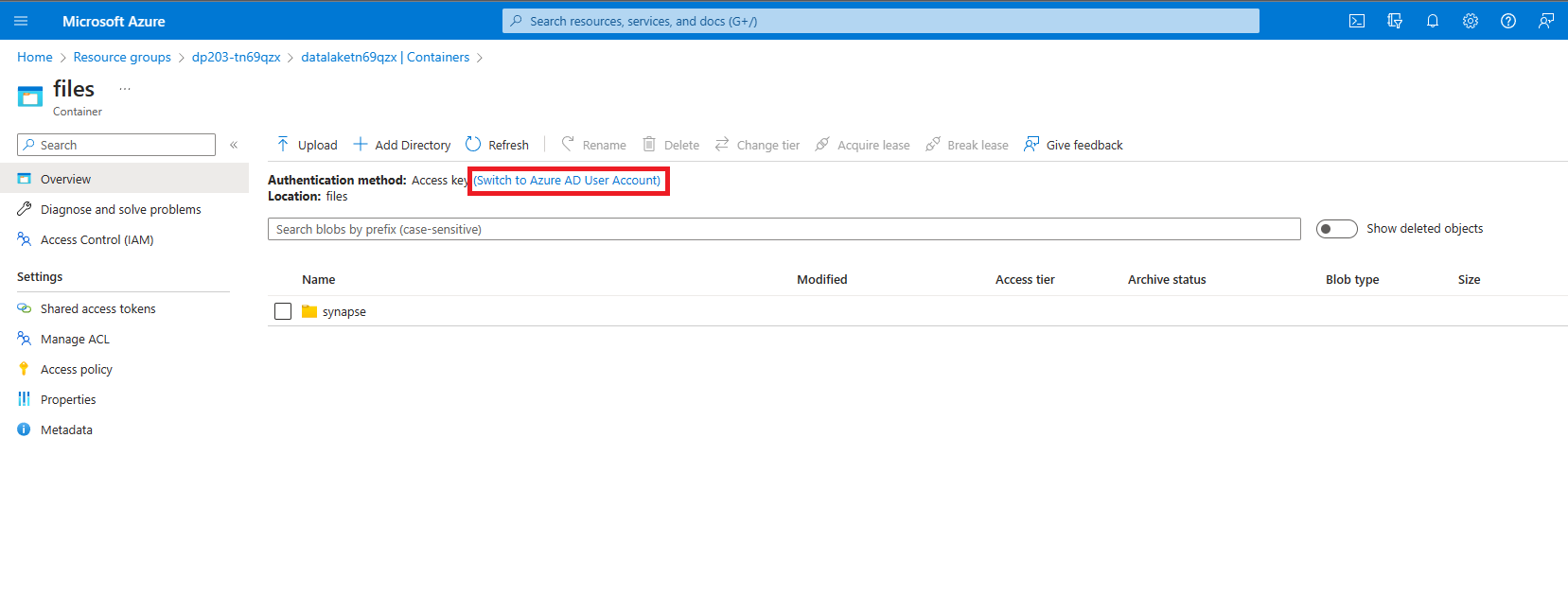
Erstellen einer Lake-Datenbank
Eine Lake-Datenbank ist ein Datenbanktyp, den Sie in Ihrem Arbeitsbereich definieren und mit dem integrierten serverlosen SQL-Pool arbeiten können.
- Wählen Sie Ihren Synapse-Arbeitsbereich aus, und wählen Sie Öffnen auf der Seite Übersicht in der Karte Synapse Studio öffnen aus, um Synapse Studio in einer neuen Browserregisterkarte zu öffnen und sich anzumelden, wenn Sie dazu aufgefordert werden.
- Verwenden Sie auf der linken Seite von Synapse Studio das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten in Synapse Studio angezeigt, die Sie zum Verwalten von Ressourcen und zum Ausführen von Datenanalyseaufgaben verwenden.
- Zeigen Sie auf der Seite Daten die Registerkarte Verknüpft an, und stellen Sie sicher, dass Ihr Arbeitsbereich einen Link zu Ihrem Azure Data Lake Storage Gen2-Speicherkonto enthält.
- Wechseln Sie auf der Seite Daten zurück zur Registerkarte Arbeitsbereich und beachten Sie, dass in Ihrem Arbeitsbereich keine Datenbanken vorhanden sind.
- Wählen Sie im + Menü Lake-Datenbank aus, um eine neue Registerkarte zu öffnen, auf der Sie ihr Datenbankschema entwerfen können (akzeptieren Sie die Verwendungsbedingungen der Datenbankvorlagen, wenn Sie dazu aufgefordert werden).
- Ändern Sie im Eigenschaftenbereich für die neue Datenbank den Namen in RetailDB, und stellen Sie sicher, dass die Eigenschaft des Eingabeordners automatisch auf Dateien/RetailDB aktualisiert wird. Belassen Sie das Datenformat als Durch Trennzeichen getrennter Text (Sie können auch das Parquet-Format verwenden, und Sie können das Dateiformat für einzelne Tabellen außer Kraft setzen – in dieser Übung verwenden wir kommagetrennte Daten.)
- Wählen Sie oben im Bereich RetailDB die Option Veröffentlichen aus, um die Datenbank auf dem bisherigen Stand zu speichern.
- Zeigen Sie im Bereich Daten auf der linken Seite die Registerkarte Verknüpft an. Erweitern Sie dann Azure Data Lake Storage Gen2 und den primären Datalakexxxxxxx-Speicherort für Ihren Synapsexxxxxxx-Arbeitsbereich und wählen Sie das Dateisystem Dateien aus, das aktuell einen Ordner mit dem Namen Synapse enthält.
- Verwenden Sie auf der geöffneten Registerkarte Dateien die Schaltfläche +Neuer Ordner, um einen neuen Ordner namens RetailDB zu erstellen. Dies ist der Eingabeordner für die Datendateien, die von Tabellen in Ihrer Datenbank verwendet werden.
Erstellen einer Tabelle
Nachdem Sie nun eine Seedatenbank erstellt haben, können Sie das Schema definieren, indem Sie Tabellen erstellen.
Definieren des Tabellenschemas
- Wechseln Sie zurück zur Registerkarte RetailDB für Ihre Datenbankdefinition, wählen Sie in der Liste +Tabelle die Option Benutzerdefiniert aus, und beachten Sie, dass ihrer Datenbank eine neue Tabelle mit dem Namen Table_1 hinzugefügt wird.
- Wenn Table_1 ausgewählt ist, ändern Sie auf der Registerkarte Allgemein unter dem Canvas Datenbank-Design die Eigenschaft Name in Kunde.
- Erweitern Sie den Abschnitt Speichereinstellungen für Tabelle und beachten Sie, dass die Tabelle als durch Trennzeichen getrennter Text im Ordner Dateien/RetailDB/Customer im standardmäßigen Data Lake-Speicherort für Ihren Synapse-Arbeitsbereich gespeichert wird.
-
Beachten Sie auf der Registerkarte Spalten, dass die Tabelle standardmäßig eine Spalte mit dem Namen Column_1 enthält. Bearbeiten Sie die Spaltendefinition so, dass sie den folgenden Eigenschaften entspricht:
Name Tasten Beschreibung NULL-Zulässigkeit Datentyp Format / Länge CustomerId PK 🗹 Eindeutige Kunden-ID 🗆 long -
Wählen Sie in der Liste +Spalte Neue Spalte aus und ändern Sie die neue Spaltendefinition, um der Tabelle wie folgt eine Spalte FirstName hinzuzufügen:
Name Tasten Beschreibung NULL-Zulässigkeit Datentyp Format / Länge CustomerId PK 🗹 Eindeutige Kunden-ID 🗆 long FirstName PK 🗆 Vorname des Kunden 🗆 Zeichenfolge 256 -
Fügen Sie weitere neue Spalten hinzu, bis die Tabellendefinition wie folgt aussieht:
Name Tasten Beschreibung NULL-Zulässigkeit Datentyp Format / Länge CustomerId PK 🗹 Eindeutige Kunden-ID 🗆 long FirstName PK 🗆 Vorname des Kunden 🗆 Zeichenfolge 256 LastName PK 🗆 Nachname des Kunden 🗹 Zeichenfolge 256 EmailAddress PK 🗆 Kunden-E-Mail 🗆 Zeichenfolge 256 Telefonnummer PK 🗆 Telefonnummer des Kunden 🗹 Zeichenfolge 256 - Wenn Sie alle Spalten hinzugefügt haben, veröffentlichen Sie die Datenbank erneut, um die Änderungen zu speichern.
- Wechseln Sie im Bereich Daten auf der linken Seite zurück zur Registerkarte Arbeitsbereich, um die Lake-Datenbank RetailDB zu sehen. Erweitern Sie diese und aktualisieren Sie den Ordner Tabellen, um die neu erstellte Tabelle Kunde anzuzeigen.
Laden von Daten in den Speicherpfad der Tabelle
- Wechseln Sie im Hauptbereich zurück zur Registerkarte Dateien, die das Dateisystem mit dem Ordner RetailDB enthält. Öffnen Sie dann den Ordner RetailDB und erstellen Sie einen neuen Ordner mit dem Namen Kunde. Von hier bezieht die Tabelle Kunde ihre Daten.
- Öffnen Sie den neuen Ordner Kunde, der leer sein sollte.
-
Laden Sie die Datei customer.csv aus https://raw.githubusercontent.com/MicrosoftLearning/dp-203-azure-data-engineer/master/Allfiles/labs/04/data/customer.csv herunter und speichern Sie sie in einem Ordner auf Ihrem lokalen Computer (egal wo). Verwenden Sie dann im Ordner Customer im Synapse-Explorer die Schaltfläche ⤒ Hochladen, um die Datei customer.csv in den Ordner RetailDB/Customer in Ihren Data Lake hochzuladen.
Hinweis: In einem echten Produktionsszenario würden Sie wahrscheinlich eine Pipeline zum Aufnehmen von Daten in den Ordner für die Tabellendaten erstellen. Wir laden sie in dieser Übung zur Beschleunigung direkt in die Synapse Studio-Benutzeroberfläche hoch.
- Wählen Sie links im Bereich Daten auf der Registerkarte Arbeitsbereich im …-Menü für die Tabelle Kunde die Option Neues SQL-Skript > Erste 100 Zeilen auswählen aus. Stellen Sie dann im neuen geöffneten Bereich SQL-Skript 1 sicher, dass der integrierte SQL-Pool verbunden ist und verwenden Sie die Schaltfläche ▷ Ausführen zum Ausführen des SQL-Codes. Die Ergebnisse sollten die ersten 100 Zeilen aus der Tabelle Kunde enthalten, basierend auf den Daten, die im zugrunde liegenden Ordner im Data Lake gespeichert sind.
- Schließen Sie die Registerkarte SQL Skript 1 und verwerfen Sie Ihre Änderungen.
Erstellen einer temporären Tabelle aus einer Datenbank-Vorlage
Wie Sie gesehen haben, können Sie die in Ihrer Lake-Datenbank benötigten Tabellen von Grund auf erstellen. Azure Synapse Analytics bietet jedoch auch zahlreiche Datenbankvorlagen basierend auf allgemeinen Datenbankworkloads und Entitäten, die Sie als Ausgangspunkt für Ihr Datenbankschema verwenden können.
Definieren des Tabellenschemas
- Wechseln Sie im Hauptbereich zurück zum Bereich RetailDB, der Ihr Datenbankschema enthält (derzeit nur die Tabelle Kunde).
- Wählen Sie im Menü +Tabelle die Option Aus Vorlage aus. Wählen Sie dann auf der Seite Aus Vorlage hinzufügen die Option Einzelhandel aus, und klicken Sie auf Weiter.
- Warten Sie auf der Seite Aus Vorlage hinzufügen (Einzelhandel), bis die Tabellenliste aufgefüllt wird, erweitern Sie anschließend Produkt und wählen Sie RetailProduct aus. Klicken Sie anschließend auf Hinzufügen. Dadurch wird ihrer Datenbank eine neue Tabelle basierend auf der Vorlage RetailProduct hinzugefügt.
- Wählen Sie im Bereich RetailDB die neue Tabelle RetailProduct aus. Ändern Sie dann im Bereich unter dem Design-Canvas auf der Registerkarte Allgemein den Namen in Produkt und vergewissern Sie sich, dass in den Speichereinstellungen für die Tabelle als Eingabeordner files/RetailDB/Product angegeben ist.
- Beachten Sie auf der Registerkarte Spalten für die Tabelle Produkt, dass die Tabelle bereits eine große Anzahl von Spalten enthält, die von der Vorlage geerbt wurden. Es gibt für diese Tabelle mehr Spalten als erforderlich sind, daher müssen Sie einige entfernen.
- Aktivieren Sie das Kontrollkästchen neben Name, um alle Spalten auszuwählen, und heben Siedann die folgenden Spalten auf (die Sie beibehalten müssen):
- ProductId
- ProductName
- IntroductionDate
- ActualAbandonmentDate
- ProductGrossWeight
- ItemSku
-
Wählen Sie auf der Symbolleiste im Bereich Spalten die Option Löschen aus, um die ausgewählten Spalten zu entfernen. Damit sollten die folgenden Spalten übrig sein:
Name Tasten Beschreibung NULL-Zulässigkeit Datentyp Format / Länge ProductId PK 🗹 Eindeutiger Bezeichner des Produkts. 🗆 long ProductName PK 🗆 Der Name des Produkts… 🗹 Zeichenfolge 128 IntroductionDate PK 🗆 Das Datum, an dem das Produkt zum Verkauf eingeführt wurde. 🗹 Datum JJJJ-MM-TT ActualAbandonmentDate PK 🗆 Das tatsächliche Datum, an dem das Marketing des Produkts eingestellt wurde… 🗹 Datum JJJJ-MM-TT ProductGrossWeight PK 🗆 Das Bruttoproduktgewicht 🗹 Decimal 18,8 ItemSku PK 🗆 Die Bezeichner der Lagerhaltungseinheit… 🗹 Zeichenfolge 20 -
Fügen Sie der Tabelle wie hier gezeigt eine neue Spalte mit dem Namen ListPrice hinzu:
Name Tasten Beschreibung NULL-Zulässigkeit Datentyp Format / Länge ProductId PK 🗹 Eindeutiger Bezeichner des Produkts. 🗆 long ProductName PK 🗆 Der Name des Produkts… 🗹 Zeichenfolge 128 IntroductionDate PK 🗆 Das Datum, an dem das Produkt zum Verkauf eingeführt wurde. 🗹 Datum JJJJ-MM-TT ActualAbandonmentDate PK 🗆 Das tatsächliche Datum, an dem das Marketing des Produkts eingestellt wurde… 🗹 Datum JJJJ-MM-TT ProductGrossWeight PK 🗆 Das Bruttoproduktgewicht 🗹 Decimal 18,8 ItemSku PK 🗆 Die Bezeichner der Lagerhaltungseinheit… 🗹 Zeichenfolge 20 ListPrice PK 🗆 Der Produktpreis 🗆 decimal 18,2 - Wenn Sie die Spalten wie oben gezeigt geändert haben, veröffentlichen Sie die Datenbank erneut, um die Änderungen zu speichern.
- Wechseln Sie im Bereich Daten auf der linken Seite zurück zur Registerkarte Arbeitsbereich, um die Lake-Datenbank RetailDB zu sehen. Verwenden Sie dann das Menü … für den Ordner Tabellen, um die Ansicht zu aktualisieren und die neu erstellte Tabelle Produkt anzuzeigen.
Laden von Daten in den Speicherpfad der Tabelle
- Wechseln Sie im Hauptbereich zurück zur Registerkarte Dateien, die das Dateisystem enthält, und navigieren Sie zum Ordner files/RetailDB, der den Ordner Kunde für die zuvor erstellte Tabelle enthält.
- Erstellen Sie im Ordner RetailDB einen neuen Ordner mit dem Namen Produkt. Von hier bezieht die Tabelle Produkt ihre Daten.
- Öffnen Sie den neuen Ordner Produkt, der leer sein sollte.
- Laden Sie die Datei product.csv aus https://raw.githubusercontent.com/MicrosoftLearning/dp-203-azure-data-engineer/master/Allfiles/labs/04/data/product.csv herunter und speichern Sie sie in einem Ordner auf Ihrem lokalen Computer (egal wo). Verwenden Sie dann im Ordner Product im Synapse-Explorer die Schaltfläche ⤒ Hochladen, um die Datei product.csv in den Ordner RetailDB/Product in Ihren Data Lake hochzuladen.
- Wählen Sie links im Bereich Daten auf der Registerkarte Arbeitsbereich im …-Menü für die Tabelle Produkt die Option Neues SQL-Skript > Erste 100 Zeilen auswählen aus. Stellen Sie dann im neuen geöffneten Bereich SQL-Skript 1 sicher, dass der integrierte SQL-Pool verbunden ist, und verwenden Sie die Schaltfläche ▷ Ausführen zum Ausführen des SQL-Codes. Die Ergebnisse sollten die ersten 100 Zeilen aus der Tabelle Produkt enthalten, basierend auf den Daten, die im zugrunde liegenden Ordner im Data Lake gespeichert sind.
- Schließen Sie die Registerkarte SQL Skript 1 und verwerfen Sie Ihre Änderungen.
Erstellen einer Tabelle aus vorhandenen Daten
Bisher haben Sie Tabellen erstellt und dann mit Daten aufgefüllt. In manchen Fällen verfügen Sie möglicherweise bereits über Daten in einem Data Lake, von dem Sie eine Tabelle ableiten möchten.
Hochladen von Daten
- Wechseln Sie im Hauptbereich zurück zur Registerkarte Dateien, die das Dateisystem enthält, und navigieren Sie zum Ordner files/RetailDB, der für die zuvor erstellte Tabelle aktuell die Ordner Kunde und Produkt enthält.
- Erstellen Sie im Ordner RetailDB einen neuen Ordner mit dem Namen SalesOrder.
- Öffnen Sie den neuen Ordner SalesOrder, der leer sein sollte.
- Laden Sie die Datei salesorder.csv aus https://raw.githubusercontent.com/MicrosoftLearning/dp-203-azure-data-engineer/master/Allfiles/labs/04/data/salesorder.csv herunter und speichern Sie sie in einem Ordner auf Ihrem lokalen Computer (egal wo). Verwenden Sie dann im Ordner SalesOrder im Synapse-Explorer die Schaltfläche ⤒ Hochladen, um die Datei salesorder.csv in den Ordner RetailDB/SalesOrder in Ihren Data Lake hochzuladen.
Erstellen einer Tabelle
- Wechseln Sie im Hauptbereich zurück zum Bereich RetailDB, der Ihr Datenbankschema enthält (derzeit nur die Tabellen Kunde und Produkt).
- Wählen Sie im Menü +Tabelle die Option Aus Data Lake aus. Geben Sie dann im Bereich Externe Tabelle aus Data Lake erstellen die folgenden Optionen an:
- Name der externen Tabelle: SalesOrder
- Verknüpfter Dienst: Wählen Sie synapsexxxxxxx-WorkspaceDefautStorage(datalakexxxxxxx aus)
- Eingabedatei des Ordners: files/RetailDB/SalesOrder
- Fahren Sie mit der nächsten Seite fort, und erstellen Sie dann die Tabelle mit den folgenden Optionen:
- Dateityp: CSV
- Feldabschlusszeichen: Standard (Komma ,)
- Erste Zeile: Lassen Sie Spaltennamen ableiten nichtausgewählt.
- Zeichenfolgentrennzeichen: Standard (leere Zeichenfolge)
- Standardtyp verwenden: Standardtyp (true,false)
- Max. Zeichenfolgenlänge: 4000
-
Wenn die Tabelle erstellt wurde, beachten Sie, dass sie Spalten mit dem Namen C1, C2 usw. enthält und dass die Datentypen aus den Daten im Ordner abgeleitet wurden. Ändern Sie die Spaltendefinitionen wie folgt:
Name Tasten Beschreibung NULL-Zulässigkeit Datentyp Format / Länge SalesOrderid PK 🗹 Der eindeutige Bezeichner einer Bestellung 🗆 long OrderDate PK 🗆 Das Datum der Bestellung 🗆 Zeitstempel JJJJ-MM-TT LineItemId PK 🗹 Die ID eines bestimmten Einzelpostens 🗆 long CustomerId PK 🗆 Der Kunde 🗆 long ProductId PK 🗆 Das Produkt 🗆 long Menge PK 🗆 Die Bestellmenge 🗆 long Hinweis: Die Tabelle enthält einen Datensatz für jeden einzelnen sortierten Artikel und enthält einen zusammengesetzten Primärschlüssel, der aus SalesOrderId und LineItemId besteht.
-
Wählen Sie auf der Registerkarte Beziehungen für die Tabelle SalesOrder in der Liste +Beziehung die Option Zu Tabelle aus und definieren Sie dann die folgende Beziehung:
From-Tabelle From-Spalte Zu Tabelle Zu Spalte Kreditor CustomerId Verkaufsauftrag CustomerId -
Fügen Sie eine zweite Beziehung Zu Tabelle mit den folgenden Einstellungen hinzu:
From-Tabelle From-Spalte Zu Tabelle Zu Spalte Produkt ProductId Verkaufsauftrag ProductId Die Möglichkeit zum Definieren von Beziehungen zwischen Tabellen hilft beim Erzwingen der referenziellen Integrität zwischen verwandten Datenentitäten. Dies ist ein gemeinsames Merkmal relationaler Datenbanken, die andernfalls schwer auf Dateien in einem Data Lake angewendet werden können.
- Veröffentlichen Sie die Datenbank erneut, um die Änderungen zu speichern.
- Wechseln Sie im Bereich Daten auf der linken Seite zurück zur Registerkarte Arbeitsbereich, um die Lake-Datenbank RetailDB zu sehen. Verwenden Sie dann das Menü … für den Ordner Tabellen, um die Ansicht zu aktualisieren und die neu erstellte Tabelle SalesOrder anzuzeigen.
Arbeiten mit Lake-Datenbank-Tabellen
Nachdem Sie nun über einige Tabellen in Ihrer Datenbank verfügen, können Sie sie verwenden, um mit den zugrunde liegenden Daten zu arbeiten.
Abfragen von Tabellen mit SQL
- Wählen Sie in Synapse Studio die Seite Entwickeln aus.
- Wählen Sie im Bereich Entwickeln im +-Menü SQL-Skript aus.
- Stellen Sie im neuen Bereich SQL-Skript 1 sicher, dass das Skript mit dem integrierten SQL-Pool verbunden ist, und wählen Sie in der Liste Benutzerdatenbank RetailDB aus.
-
Geben Sie den folgenden SQL-Code ein:
SELECT o.SalesOrderID, c.EmailAddress, p.ProductName, o.Quantity FROM SalesOrder AS o JOIN Customer AS c ON o.CustomerId = c.CustomerId JOIN Product AS p ON o.ProductId = p.ProductId -
Führen Sie mithilfe der Schaltfläche ▷ Ausführen den SQL-Code aus.
Die Ergebnisse zeigen Bestelldetails mit Kunden- und Produktinformationen an.
- Schließen Sie den Bereich SQL-Skript 1 und verwerfen Sie Ihre Änderungen.
Einfügen von Daten mit Spark
- Wählen Sie im Bereich Entwickeln im +-Menü Notebook aus.
- Fügen Sie im neuen Bereich Notebook 1 das Notebook an den Spark-Pool sparkxxxxxxx* an.
-
Führen Sie den folgenden Code in einer leeren Zelle des Notebooks aus:
%%sql INSERT INTO `RetailDB`.`SalesOrder` VALUES (99999, CAST('2022-01-01' AS TimeStamp), 1, 6, 5, 1) - Führen Sie den Code mit dem Symbol [▷] links neben der Codezelle aus, und warten Sie, bis er fertig ausgeführt ist. Beachten Sie, dass das Starten des Spark-Pools einige Zeit in Anspruch nimmt.
- Verwenden Sie die Schaltfläche +Code, um dem Notebook eine neue Zelle hinzuzufügen.
-
Geben Sie in der neuen Zelle den folgenden Code ein:
%%sql SELECT * FROM `RetailDB`.`SalesOrder` WHERE SalesOrderId = 99999 - Führen Sie den Code mit dem Symbol ▷ auf der linken Seite der Zelle aus und vergewissern Sie sich, dass eine Zeile für den Auftrag 99999 in die Tabelle SalesOrder eingefügt wurde.
- Schließen Sie den Bereich Notebook 1, beenden Sie die Spark-Sitzung und verwerfen Sie Ihre Änderungen.
Löschen von Azure-Ressourcen
Wenn Sie sich mit Azure Synapse Analytics vertraut gemacht haben, sollten Sie die erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden.
- Schließen Sie die Registerkarte mit Synapse Studio, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressourcengruppen aus.
- Wählen Sie die Ressourcengruppe dp203-xxxxxxx für Ihren Synapse Analytics-Arbeitsbereich aus (nicht die verwaltete Ressourcengruppe), und vergewissern Sie sich, dass sie den Synapse-Arbeitsbereich, das Speicherkonto und den Spark-Pool für Ihren Arbeitsbereich enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe dp203-xxxxxxx ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach einigen Minuten werden die Ressourcengruppe in Ihrem Azure Synapse-Arbeitsbereich und die damit verknüpfte Ressourcengruppe im verwalteten Arbeitsbereich gelöscht.