探索 Microsoft Fabric 中的数据分析
在本练习中,你将探索 Microsoft Fabric 湖屋中的数据引入和分析。
完成本实验后,你将:
- 了解 Microsoft Fabric 湖屋的概念:** 了解如何创建工作区和湖屋,这是在 Fabric 中组织和管理数据资产的核心。
- 使用管道引入数据:** 使用引导式管道将外部数据引入湖屋,因此无需手动编写代码即可进行查询。
- 使用 SQL 浏览和查询数据:** 使用常用 SQL 查询分析引入的数据,直接在 Fabric 中获取见解。
- 管理资源:了解清理资源的最佳做法,以避免不必要的费用。
纽约出租车数据集背景:
“纽约出租车 - 绿色”数据集包含纽约市出租车行程的详细记录,包括上下车时间、地点、行程距离、费用和乘客人数。 该数据集被广泛应用于数据分析和机器学习,以探索城市交通、需求预测和异常情况检测。 在本实验中,你将使用此真实数据集在 Microsoft Fabric 中练习数据引入和分析。
完成本实验室大约需要 25 分钟。
注意:需要 Microsoft Fabric 许可证才能完成本练习。 有关如何启用免费 Fabric 试用版许可证的详细信息,请参阅 Fabric 入门。 需要 Microsoft 学校或工作帐户才能执行此操作 。 如果没有该帐户,可以注册 Microsoft Office 365 E3 或更高版本的试用版。
首次使用任何 Microsoft Fabric 功能时,可能会出现提示。消除这些内容。
创建工作区
在 Fabric 中处理数据之前,创建一个已启用的 Fabric 试用版的工作区。
**** 提示:工作区是所有资产(湖屋、管道、笔记本、报表)的容器。启用 Fabric 容量即可让这些项目运行。
-
在浏览器中,导航到 Microsoft Fabric 主页 (
https://app.fabric.microsoft.com/home?experience=fabric),使用 Fabric 凭据登录。 -
在左侧菜单栏中,选择“工作区”(图标类似于 🗇)。
-
新建一个工作区并为其指定名称,并在“高级”部分选择包含 Fabric 容量(试用版、高级版或 Fabric)的许可模式 。
**** 提示:选择包含 Fabric 的容量可为工作区提供数据工程任务所需的引擎。使用专用工作区可使实验室资源保持独立且易于清理。
-
打开新工作区时,它应为空。
创建湖屋
现在已经有了工作区,可以为数据文件创建湖屋了。
**** 提示:湖屋将文件和表一起放在 OneLake 上。可以存储原始文件,也可以创建能使用 SQL 查询的托管 Delta 表。
-
在左侧菜单上,选择“创建”。 在“新建”页的 “数据工程” 部分下,选择“湖屋”。 为其指定唯一的名称。
备注:如果未将“创建”选项固定到边栏,则需要首先选择省略号 (…) 选项。
大约一分钟后,一个新的湖屋创建完成:
-
查看新的湖屋,并注意使用左侧的湖屋资源管理器窗格可浏览湖屋中的表和文件:
- Tables 文件夹包含可以使用 SQL 语义查询的表。 Microsoft Fabric 湖屋中的表基于 Apache Spark 中常用的开源 Delta Lake 文件格式。
- Files 文件夹包含湖屋的 OneLake 存储中未与托管增量表关联的数据文件。 还可以在此文件夹中创建快捷方式,以引用存储在外部的数据。
目前,湖屋中没有表或文件。
**** 提示:对原始数据或临时数据使用文件,对已策展且可供查询的数据集使用表。表由 Delta Lake 提供支持,因此它们支持可靠的更新和高效的查询。
引入数据
引入数据的一种简单方法是使用管道中的“复制数据”活动从源中提取数据并将其复制到湖屋中的文件。
**** 提示:管道提供了一种引导式的可重复方法将数据引入湖屋。它们比从头开始编写代码要容易得多,可以在以后根据需要进行计划。
-
在湖屋的“主页”** 上的“获取数据”** 菜单中选择“新建数据管道”**,并创建名为“引入数据”** 的新数据管道。
-
在复制数据** 向导的“选择数据源”** 页上,选择“示例数据”**,然后选择“NYC Taxi - Green”** 示例数据集。
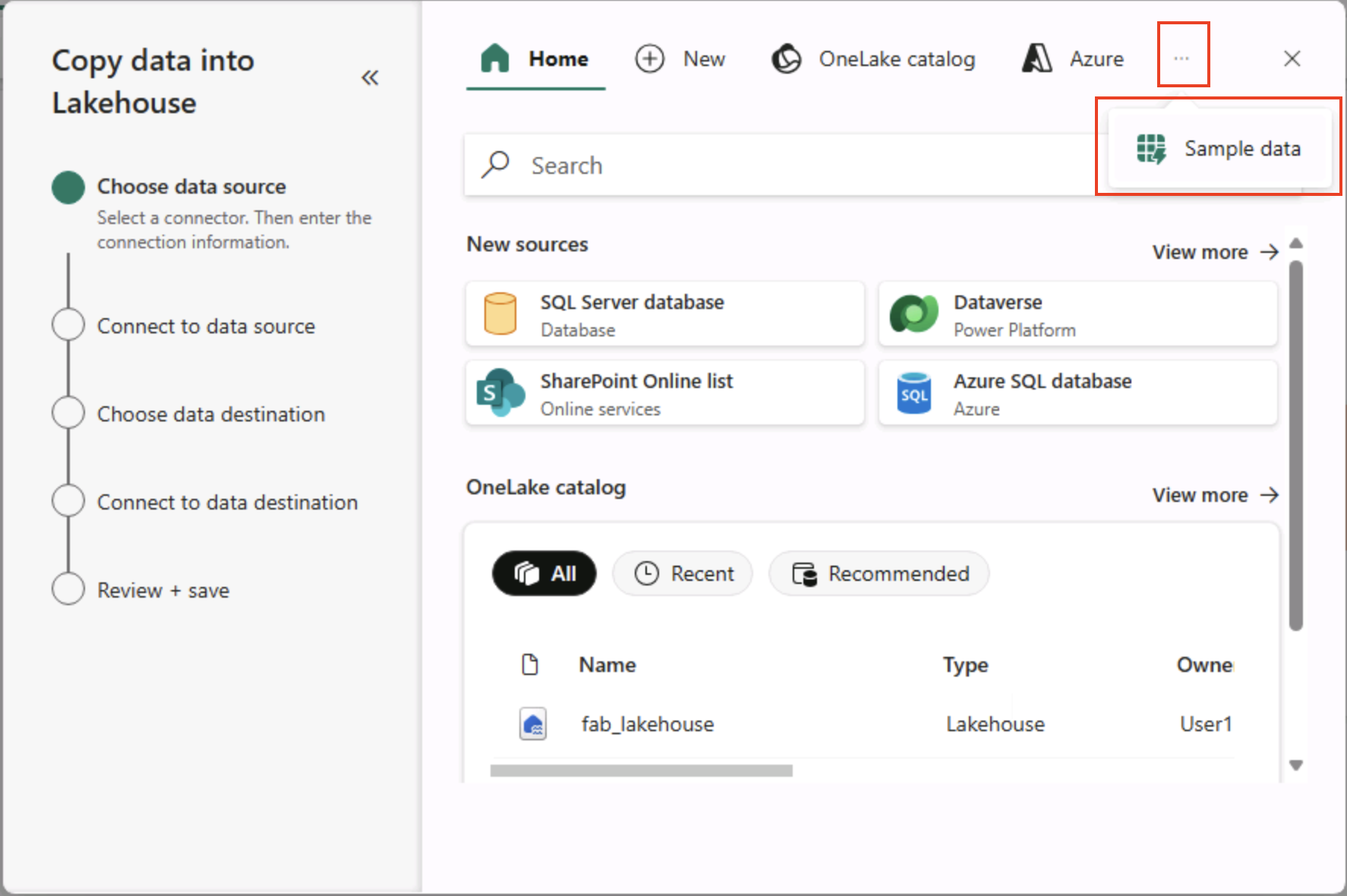
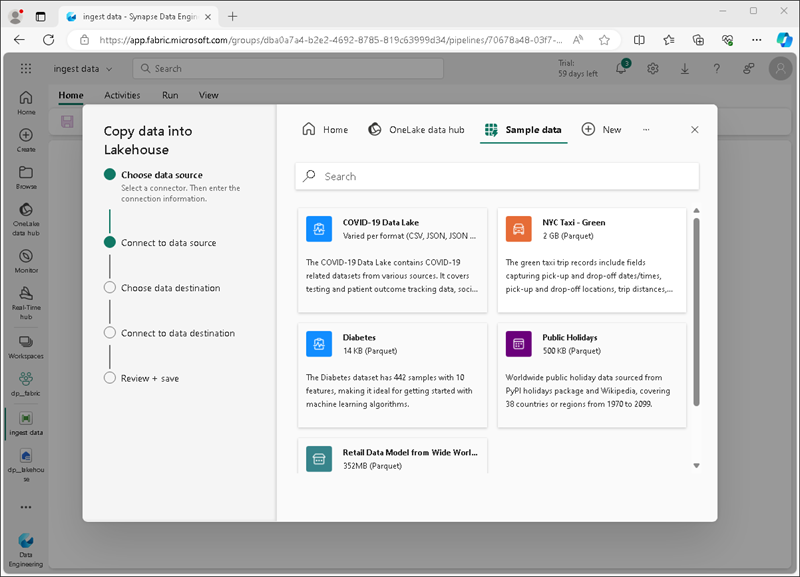
-
在“连接到数据源”** 页上查看数据源中的表。 应该有一个表,其中包含纽约市出租车行程的详细信息。 然后选择“下一步”,跳转至“连接到数据目标”页**。
- 在“连接到数据目标”页上,设置以下数据目标选项,然后选择“下一步”:
- 根文件夹:Tables
- 加载设置:加载到新表
- 目标表名称:taxi_rides (可能需要等待列映射预览显示,然后才能更改此项)
- 列映射:保持默认映射不变
- 启用分区:未选中
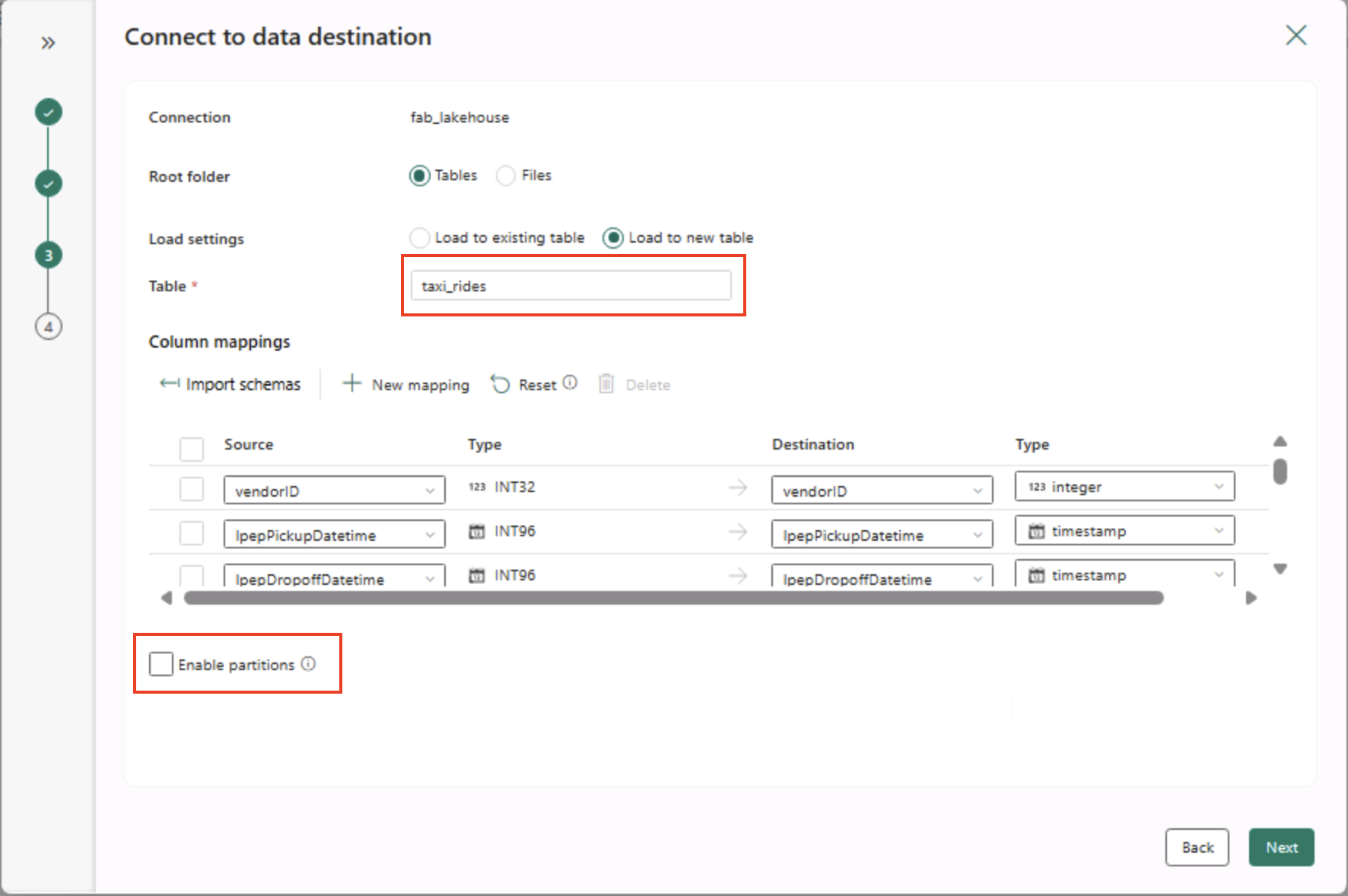
为什么选择这些选项?****
我们首先使用表作为“基础”,这样数据将直接流入一个托管的 Delta 表,你可以立即对其进行查询。** 将其加载到新表,以便此实验室保持自包含状态,并且不会覆盖任何现有表。由于示例数据已符合预期结构(无需自定义映射),我们将沿用默认列映射。** 分区处于关闭状态,以确保此小型数据集简单明了;虽然分区对于大规模数据很有用,但此处不需要。
-
在“查看 + 保存”页上,确保选中“立即开始数据传输”选项,然后选择“保存 + 运行” 。
**** 提示:立即启动可让你监视管道的运行情况,并确认数据到达时无需执行额外的步骤。
将创建一个包含“复制数据”活动的新管道,如下所示:
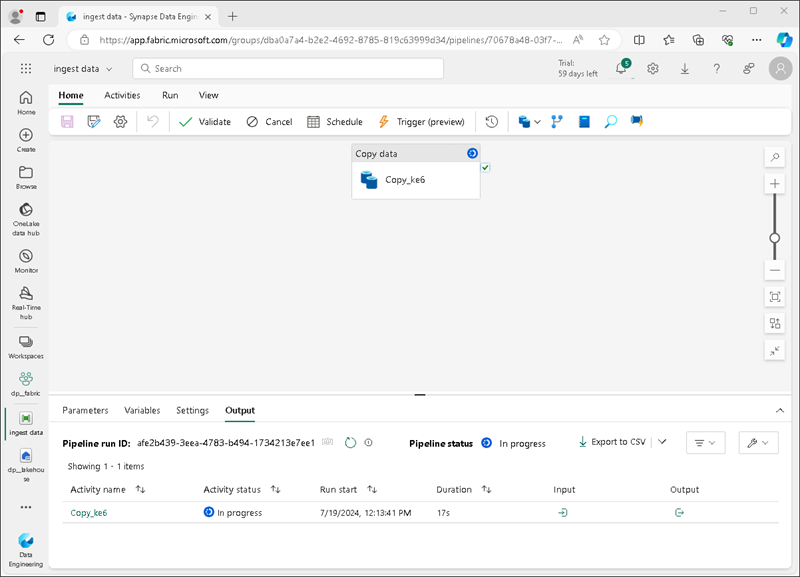
管道开始运行时,可以在管道设计器下的“输出”窗格中监视其状态。 使用 ↻(刷新)图标刷新状态,并等待它成功(可能需要 10 分钟或更长时间)**。 此特定数据集包含超过 7500 万行,存储约 2.5 GB 数据。
-
在左侧的中心菜单栏中,选择你的湖屋。

-
在主页的湖屋资源管理器窗格中的表节点的 … 菜单中,选择刷新,然后展开表以验证是否已创建 taxi_rides 表。
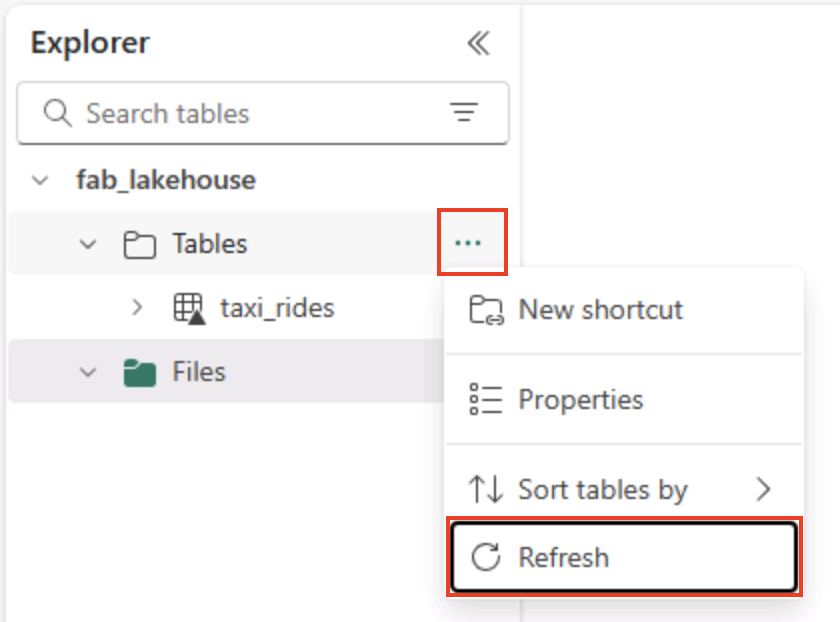
注意:如果新表被列为“无法识别”** 的表,请使用“刷新”** 菜单选项刷新视图。
**** 提示:缓存资源管理器视图。刷新会强制提取最新的表元数据,使新表正确显示。
-
选择 taxi_rides ** 表以查看其内容。
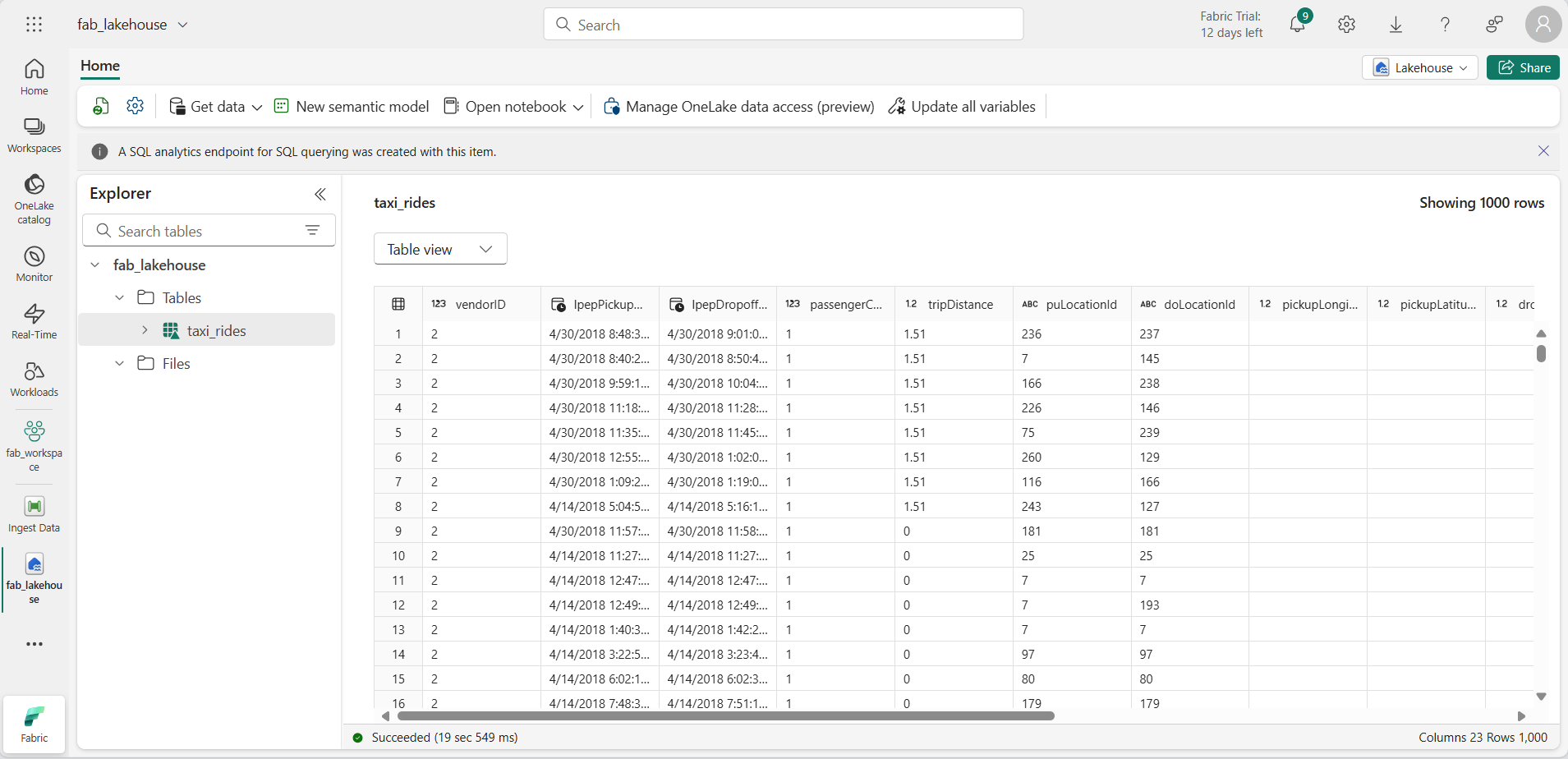
查询湖屋中的数据
将数据引入湖屋中的表后,可以使用 SQL 对其进行查询。
**** 提示:湖屋表支持 SQL。可以立即分析数据,而无需将其移动到另一个系统。
-
在湖屋页面的右上角,从湖屋视图切换到湖屋的 SQL 分析终结点。
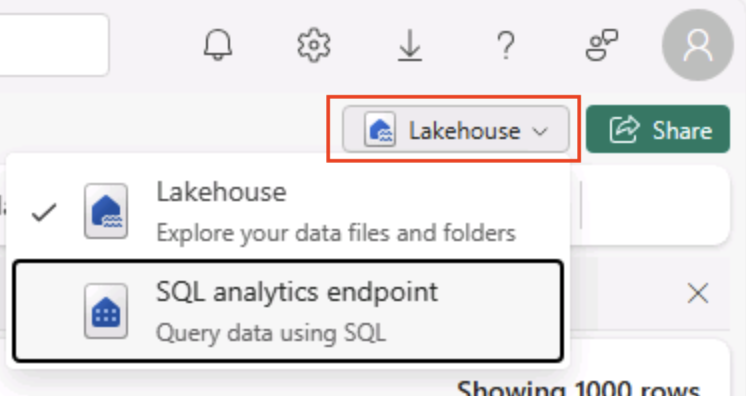
**** 提示:SQL 分析终结点已经过优化,可对湖屋表运行 SQL 查询,并与常用的查询工具集成。
-
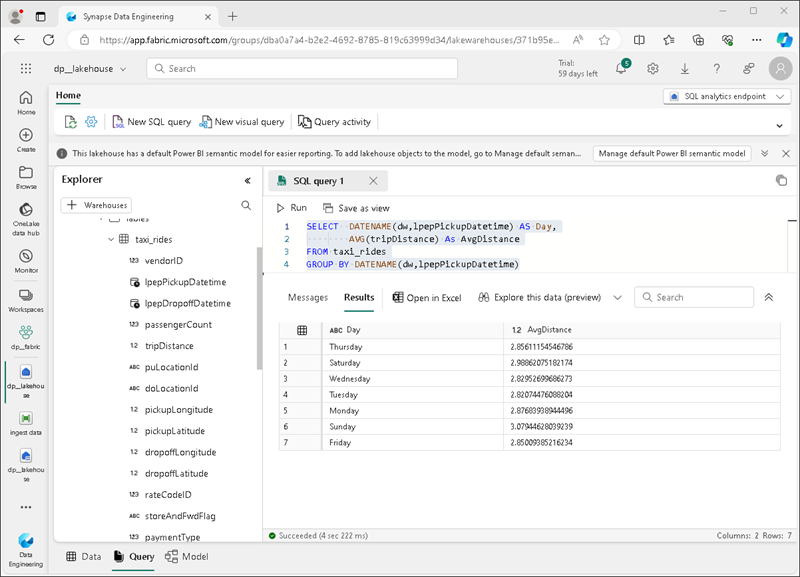
在工具栏中选择“新建 SQL 查询”。 然后在查询编辑器中输入以下 SQL 代码:
SELECT DATENAME(dw,lpepPickupDatetime) AS Day, AVG(tripDistance) As AvgDistance FROM taxi_rides GROUP BY DATENAME(dw,lpepPickupDatetime) -
选择“▷Run”** 按钮运行查询并查看结果,其中应包括每周每一天的平均行程距离。
**** 提示:此查询按日期对行程进行分组并计算平均距离,展示了一个可用于构建的简单聚合示例。
清理资源
如果已完成 Microsoft Fabric 探索,则可以删除为此练习创建的工作区。
**** 提示:删除工作区会移除实验中创建的所有项目,避免持续收费。
-
在左侧栏中,选择工作区的图标以查看其包含的所有项。
-
在工具栏中,选择“工作区设置”。
-
在“常规”部分中,选择“删除此工作区”。****